通常报告两种错误率:top-1和top-5,其中top-5错误率是测试图像中正确标签不在模型认为最有可能的五个标签中的部分。
20220405
sklearn中使用r2_score评价回归模型_#HereWeGo的博客-CSDN博客_python r2score
判定系数R2
20201225
分类报告输出到csv
from sklearn.metrics import classification_report
report = classification_report(y_test, y_pred, output_dict=True)
df = pd.DataFrame(report).transpose()
df.to_csv("result.csv", index= True)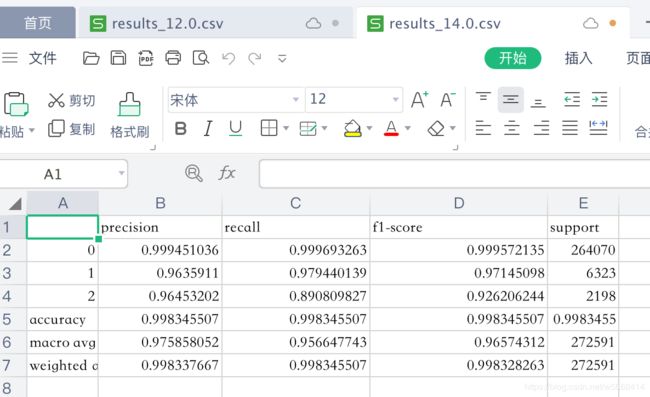
使用说明
参数
sklearn.metrics.classification_report(y_true, y_pred, labels=None, target_names=None, sample_weight=None, digits=2, output_dict=False)
y_true:1 维数组,真实数据的分类标签y_pred:1 维数组,模型预测的分类标签labels:列表,需要评估的标签名称target_names:列表,指定标签名称sample_weight:1 维数组,不同数据点在评估结果中所占的权重digits:评估报告中小数点的保留位数,如果output_dict=True,此参数不起作用,返回的数值不作处理output_dict:若真,评估结果以字典形式返回
返回
字符串或字典。
每个分类标签的精确度,召回率和 F1-score。
- 精确度:precision,正确预测为正的,占全部预测为正的比例,TP / (TP+FP)
- 召回率:recall,正确预测为正的,占全部实际为正的比例,TP / (TP+FN)
- F1-score:精确率和召回率的调和平均数,2 * precision*recall / (precision+recall)
同时还会给出总体的微平均值,宏平均值和加权平均值。
- 微平均值:micro average,所有数据结果的平均值
- 宏平均值:macro average,所有标签结果的平均值
- 加权平均值:weighted average,所有标签结果的加权平均值
在二分类场景中,正标签的召回率称为敏感度(sensitivity),负标签的召回率称为特异性(specificity)。
鸢尾花数据集的随机森林结果评估
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split# 鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target# [0, 1, 2] 标签转换为名称 ['setosa' 'versicolor' 'virginica']
y_labels = iris.target_names[y]# 数据集拆分为训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_labels, test_size=0.2)# 使用训练集训练模型
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)# 使用测试集预测结果
y_pred = clf.predict(X_test)# 生成文本型分类报告
print(classification_report(y_test, y_pred))
"""precision recall f1-score supportsetosa 1.00 1.00 1.00 10versicolor 0.83 1.00 0.91 10virginica 1.00 0.80 0.89 10micro avg 0.93 0.93 0.93 30macro avg 0.94 0.93 0.93 30
weighted avg 0.94 0.93 0.93 30
"""# 生成字典型分类报告
report = classification_report(y_test, y_pred, output_dict=True)
for key, value in report["setosa"].items():print(f"{key:10s}:{value:10.2f}")
"""
precision : 1.00
recall : 1.00
f1-score : 1.00
support : 10.00
"""
Reference
- sklearn.metrics.classification_report
- 准确率、精确率、召回率、F1值、ROC/AUC整理笔记
20201207
precision recall f1-score support
0 0.94 0.98 0.96 5259
1 0.06 0.02 0.03 307
accuracy 0.93 5566
macro avg 0.50 0.50 0.49 5566
weighted avg 0.90 0.93 0.91 5566
precision 是精准率
准确率是所有预测正确处于总数
![[JS] HEX颜色转换成RGBA](/images/no-images.jpg)

![[JS] 什么是浮动,clear:both的使用](https://img-blog.csdnimg.cn/e53b5e07881b48fc934115294321ceb2.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAQ04tRHVzdA==,size_20,color_FFFFFF,t_70,g_se,x_16)