有s表示加密的访问方式

一、初识爬虫
什么是爬虫
网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本。由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取相关网页并分析已成为如今主流的爬取策略
爬虫可以做什么
你可以爬取图片,爬取自己想看的视频等等,只要你能通过浏览器访问的数据都可以通过爬虫获取。
爬虫的本质是什么
模拟浏览器打开网页,获取网页中我们想要的那部分数据.
二、爬虫的基本流程
爬虫是通过链接去模拟浏览器去获得网页,之所以可以获取数据,是因为服务器可以通过我们给他发送的路径给我们响应;
服务器将数据发给网页,浏览器将数据解析为我们所看到的,所以爬虫爬的不仅仅是网页,还是网页的源代码,所以我们还要通过re正则等方法将所需要的数据提取出来。
响应头是我们发给服务器的
服务器发给我们的是“响应"里的数据;
如果我们不给服务器发送头部,服务器是不会给我们响应的;


三、编程规范
这一行代码可以控制多个代码之间了执行顺序
def text1(a):print('hello', a) text1(1)if __name__ == "__main__":text1(2)
可以看到先执行了text(1),因为py文件它是从上开始执行的,但是有了if __name__ == "__main__"之后,就不用再写text()了,直接在if里写,可以更好的控制执行流程;它相当于整个程序的执行入口。


四、引入自定义的模块
引入模块简单来说就是把别人写好的代码中的某个函数拿过来应用在我们需要的地方
【举个栗子】
其中text1相当于一个包,test1.py是其中的一个模块,在text2中的text2.py中我们引用了text1包中的text1.py模块中的add函数。


五、requests库
下面使用 Python 内置的 requests 模块,该模块主要用来发送 HTTP 请求,requests 模块比 urllib 模块更简洁。
使用 requests 发送 HTTP 请求需要先导入 requests 模块:
import requests
导入后就可以发送 HTTP 请求,使用 requests 提供的方法向指定 URL 发送 HTTP 请求,例如:
# 导入 requests 包 import requests# 发送请求 x = requests.get('https://www.runoob.com/')# 返回网页内容 print(x.text)
每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息,如状态码、响应头、响应内容等:
print(response.status_code) # 获取响应状态码 print(response.headers) # 获取响应头 print(response.content) # 获取响应内容
更多响应信息如下:
属性或方法 说明 apparent_encoding 编码方式 close() 关闭与服务器的连接 content 返回响应的内容,以字节为单位 cookies 返回一个 CookieJar 对象,包含了从服务器发回的 cookie elapsed 返回一个 timedelta 对象,包含了从发送请求到响应到达之间经过的时间量,可以用于测试响应速度。比如 r.elapsed.microseconds 表示响应到达需要多少微秒。 encoding 解码 r.text 的编码方式 headers 返回响应头,字典格式 history 返回包含请求历史的响应对象列表(url) is_permanent_redirect 如果响应是永久重定向的 url,则返回 True,否则返回 False is_redirect 如果响应被重定向,则返回 True,否则返回 False iter_content() 迭代响应 iter_lines() 迭代响应的行 json() 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) links 返回响应的解析头链接 next 返回重定向链中下一个请求的 PreparedRequest 对象 ok 检查 "status_code" 的值,如果小于400,则返回 True,如果不小于 400,则返回 False raise_for_status() 如果发生错误,方法返回一个 HTTPError 对象 reason 响应状态的描述,比如 "Not Found" 或 "OK" request 返回请求此响应的请求对象 status_code 返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) text 返回响应的内容,unicode 类型数据 url 返回响应的 URL
1)requests 方法
requests 方法如下表:
方法 描述 delete(url, args) 发送 DELETE 请求到指定 url get(url, params, args) 发送 GET 请求到指定 url head(url, args) 发送 HEAD 请求到指定 url patch(url, data, args) 发送 PATCH 请求到指定 url post(url, data, json, args) 发送 POST 请求到指定 url put(url, data, args) 发送 PUT 请求到指定 url request(method, url, args) 向指定的 url 发送指定的请求方法
六、设置超时
如果服务器有排斥,不想给你回应,这时候你可能会处于一直等待状态,但你又不可能一直等待,这时候就要设置超时时间;
import requestsreponse = requests.get('https://b2.faloo.com/y_0_1.html',timeout=0.01)

七、超时处理
为了让代码更健壮需要对超时进行检测;
import requeststry:reponse = requests.get('https://b2.faloo.com/y_0_1.html',timeout=0.01) except requests.exceptions.ConnectTimeout as a:print('time out!')# except是检测内容,只要遇到"requests.exceptions.ConnectTimeout"就输出"time out!"

八、获取状态码,获取响应头
import requestsresponse = requests.get('https://b2.faloo.com/y_0_1.html') print(response.status_code) # 获取状态码 print(response.headers) # 获取响应头

九、如何解决爬取网页时无报错却没有内容的问题
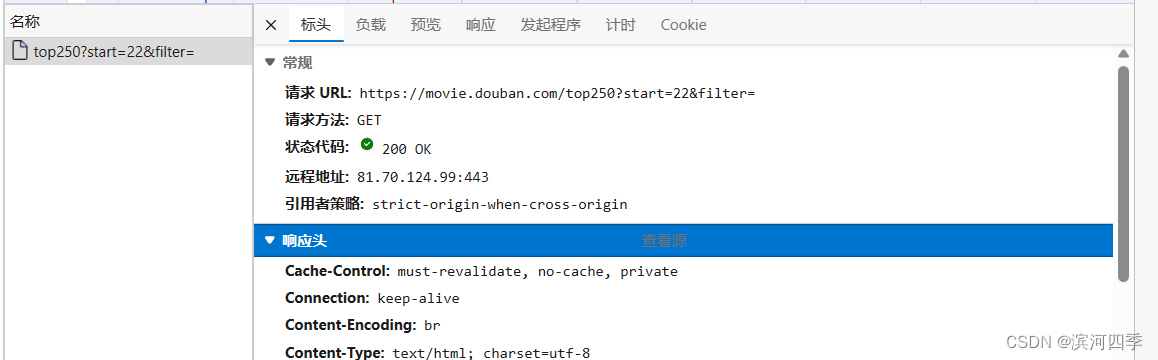
有时候,我们爬取一个网页,发现没有报错,但是没有任何内容显示,可能是因为访问的网站有反爬虫机制,而解决方法就是通过模拟浏览器来访问。
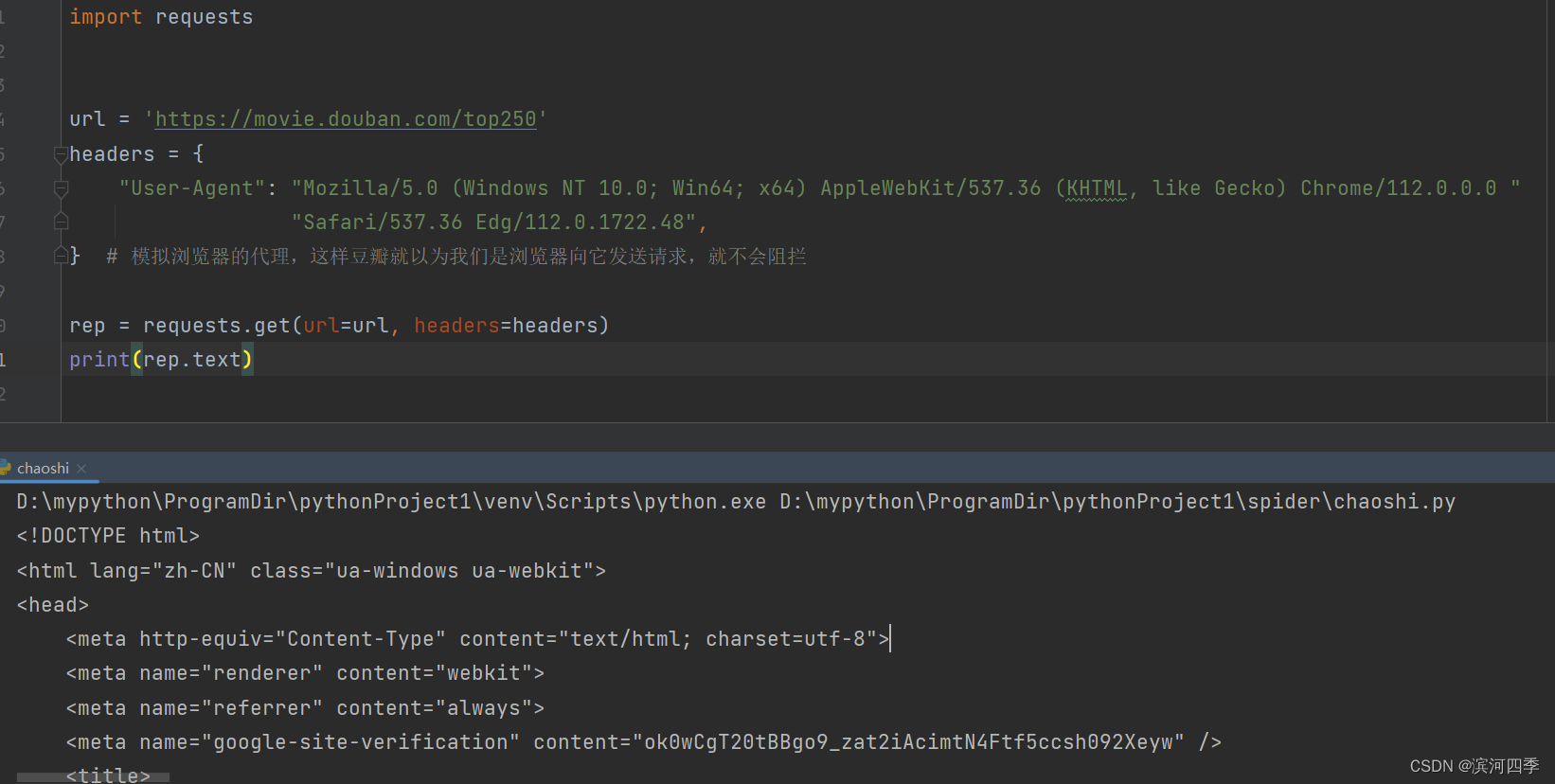
我们直接爬取豆瓣电影网页,发现没有报错,但是没有任何内容显示;
想要解决这个问题,首先我们要通过下面的方法获得header中user-agent的内容。
requests.get(url=, headers=)
其中最重要的参数是url,headers
import requestsurl = 'https://movie.douban.com/top250' headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 ""Safari/537.36 Edg/112.0.1722.48", } # 模拟浏览器的代理,这样豆瓣就以为我们是浏览器向它发送请求,就不会阻拦rep = requests.get(url=url, headers=headers) print(rep.text)可以看到页面显示成功:

十、爬虫实例
爬取的网页:飞卢小说网
链接:原创小说排行榜_免费小说下载排行榜_飞卢小说网 (faloo.com)
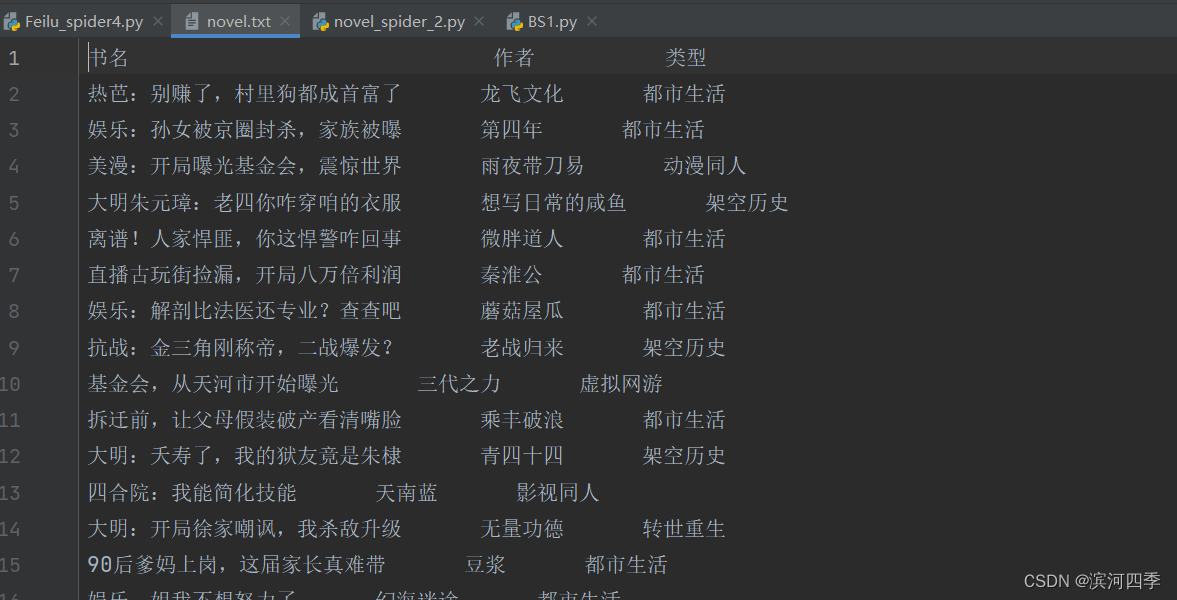
import re import requests# 爬取网页 reponse = requests.get('https://b2.faloo.com/y_0_1.html')# 标题 div_text1 = re.findall(re.compile(r'<div class="TwoBox02_08">(.*?)</div>'), reponse.text) title_list = [] for i in div_text1:title_list.append(re.findall(re.compile(r'<h1 class="fontSize17andHei" title="(.*?)">'), i)[0]) # 加下标是为了去掉括号[],因为使用?取消贪婪匹配后每一个符合条件的都是列表形式,使用下标可以将每一个小列表中的字符串取出来,方便之后的拼接 print(title_list)# 作者 div_text2 = re.findall(re.compile(r'<div class="TwoBox02_09">(.*?)</div>'), reponse.text) author_list = [] for i in div_text2:author_list.append(re.findall(re.compile(r'<a href="//b2.faloo.com/.* title="(.*?)"'), i)[0]) print(author_list)# 类型 div_text3 = re.findall(re.compile(r'<span class="fontSize14andHui">(.*?)</a>'), reponse.text) model_list = [] for i in div_text3:model_list.append(re.findall(re.compile(r'<a href="//b2.faloo.com/l.*" title="(.*?)" target="_blank">'), i)[0]) # 加下标是为了去掉括号[],因为使用?取消贪婪匹配后每一个符合条件的都是列表形式,使用下标可以将每一个小列表中的字符串取出来 print(model_list)# 将爬取到的内容合并 multi_list = map(list, zip(title_list, author_list, model_list)) all_list = list(multi_list) print(all_list) with open('./novel.txt', 'w', encoding='utf-8') as fw:fw.write('书名 作者 类型\n')for i in all_list:fw.write(' '.join(i) +'\n')执行成功效果图: