版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/wolf1132/article/details/82789715
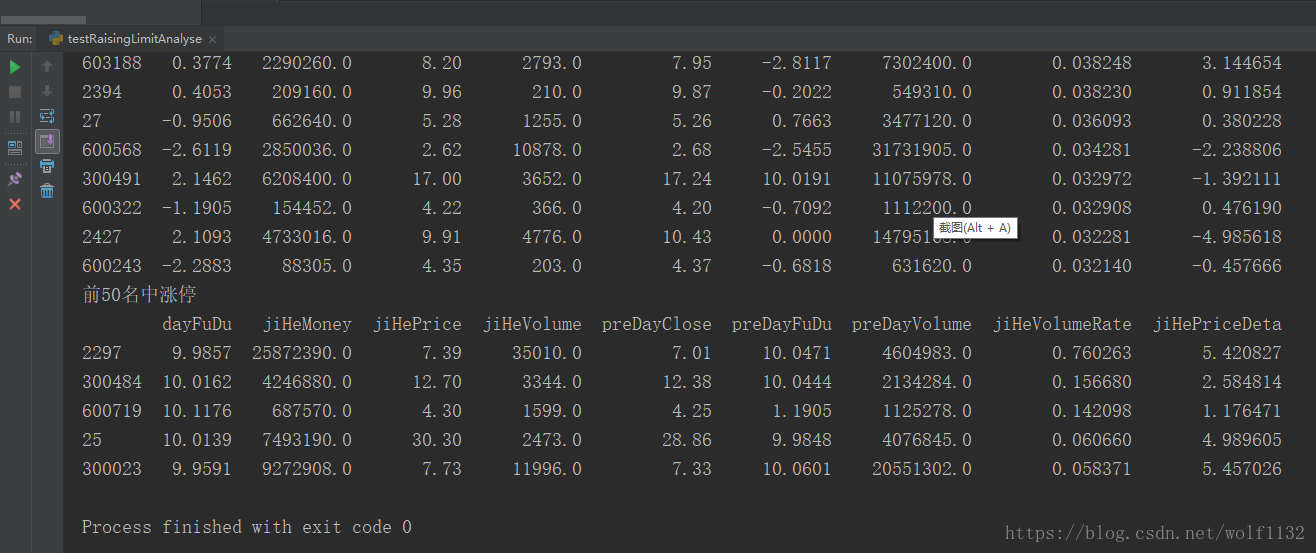
<!--一个博主专栏付费入口结束--><link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-4a3473df85.css"><link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-4a3473df85.css"><div class="htmledit_views" id="content_views"><p>pandas是python提供的非常好用的数据分析模块,但是在使用pandas进行数据分析时,有时候需要查看打印的结果,当dataframe行数或者列数比较多的时候,打印结果总是有一些省略号,不能完整的看到数据的大致分布,比如最大值,最小值,等等,了解数据分布的区间有助于进行可视化和进一步分析。</p>
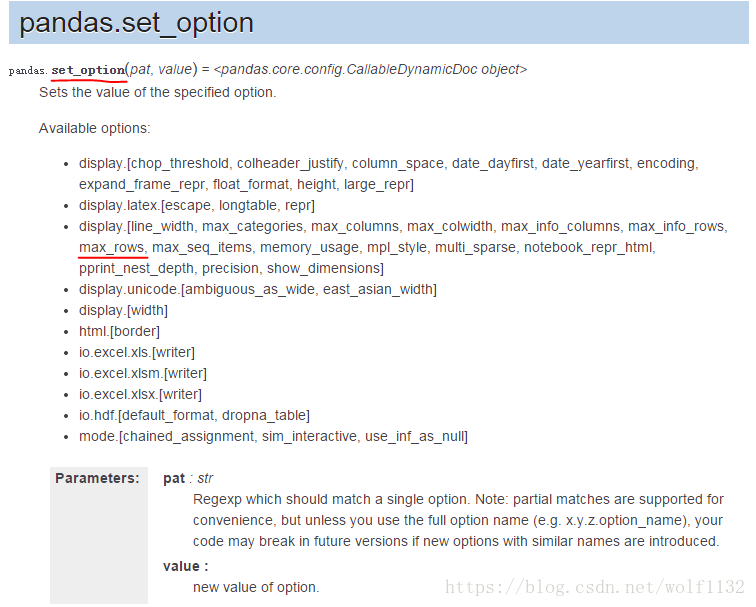
查看pandas的文档,这个问题可以通过pandas内置的set_option()方法解决,从上面的属性设置中可以看到,与显示的行数列数有关的选项主要是【display】中的【max_columns,max_rows,max_colwidth,line_width】等这几项,只需要将这几项属性值设置得大一些就可以解决
- import numpy as np
- import pandas as pd
- pd.set_option('display.max_columns',1000)
- pd.set_option('display.width', 1000)
- pd.set_option('display.max_colwidth',1000)
-
-
-