这是bert的pytorch版本(与tensorflow一样的,这个更简单些,这个看懂了,tf也能看懂),地址:https://github.com/huggingface/pytorch-pretrained-BERT 主要内容在pytorch_pretrained_bert/modeling文件中。
讲解之前,有必要先了解一下torch.nn.CrossEntropyLoss函数
#这是一个交叉熵损失函数,但又和传统的交叉熵函数不是太一样。由于在源码中出现的次数较多,因此先讲解一下。
#以下全是我的个人理解!!!!(真的不一定是正确的,欢迎指正)
#我只讲可能用到的参数。
class torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
#weight:权重。这个参数是针对训练文件不平衡设置的。例如,训练一个C分类问题,但是训练数据中C中各种类别所占的比例不一样,这是就需要一个weight参数,也因此weight也必须是C维度的
#ignore_index:忽略的值。如果target中出现和ignore_index一样的值,则此值的损失不参与计算
#input_size : [(batch_size*seq_length), vocab_size]
#对于输入,我的理解是,每个单词对应一个vocab_size向量,此向量上的每个值就是对该词的预测。例如 x = [23,45,...,65],x[0]=23就是预测x单词是0号单词的评分为23
#target,为一个[batch_size*seq_length]的一维向量,此向量的值,必须在0-vocab_size中选择(因为每个词都属于词表)
#output:一个标量(reduce默认为true的情况下)
#损失函数如下,class代表target中真实的标签
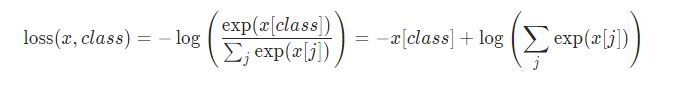
BertForMaskedLM
BERT Transformer with the pre-trained masked language modeling head on top
#masked language model(参考论文)
#相当于针对一个C分类问题做损失函数。对于masked的单词,预测他是什么,相当于预测这个单词属于每个单词的概率(总共有vocab_size个单词),所以是一个
#vocab_size分类问题
#下面详细讲解如何构造这个损失函数def forward(self, input_ids, token_type_ids=None, attention_mask=None, masked_lm_labels=None):#我们只要最后一层的输出,其形状为[batch_size, seq_length, hidden_size]sequence_output, _ = self.bert(input_ids, token_type_ids, attention_mask,output_all_encoded_layers=False)#计算预测分数,形状为[batch_size, seq_length, vocab_size],每一个值都是对该词语是否是某个词语的打分(好绕……)#具体的我不详细解释,其实很简单,经过一个全连接层,激活层,layer_norm层,一个decoder层(改变形状),就得到结果#代码很简单,自己去看prediction_scores = self.cls(sequence_output)#如果mask_lm_label不等于None,则返回预测与真实的loss。#否则,直接返回预测if masked_lm_labels is not None:#交叉熵损失函数,上面讲过,其中需要注意的是ignore_index为-1,意味着target中值为-1的不需要参与loss计算#什么时候值为-1,其实就是那些没有被masked的单词,无需预测,也就无需参与loss计算#(to be completed)loss_fct = CrossEntropyLoss(ignore_index=-1)#预测值更改为[(batch_size*seq_length), vocab_size],target为[(batch_size*seq_length)]masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), masked_lm_labels.view(-1))return masked_lm_losselse:return prediction_scores
BertForNextSentencePrediction
BERT model with next sentence prediction head
#看懂了上面的那个model,下面的这些就很简单了,无非就是将输出结果更更改改换成所需要的格式
#下一句预测,实则是一个二分类问题,是下一句 or 不是下一句def forward(self, input_ids, token_type_ids=None, attention_mask=None, next_sentence_label=None):#注意这里用的是所有层的输出[12,batch_size,seq_length,hidden_size](假设总共有12层)_, pooled_output = self.bert(input_ids, token_type_ids, attention_mask,output_all_encoded_layers=False)#将形状改变为[12,batch_size,seq_length,2]:更改了形状seq_relationship_score = self.cls( pooled_output)#下面这些就和上面的一样了,不详细讲解if next_sentence_label is not None:loss_fct = CrossEntropyLoss(ignore_index=-1)next_sentence_loss = loss_fct(seq_relationship_score.view(-1, 2), next_sentence_label.view(-1))return next_sentence_losselse:return seq_relationship_score
BertForSequenceClassification
BERT model for classification
#和BertForNextSentencePrediction一样,只不过BertForNextSentencePrediction是一个二分类问题,而这个model是一个num_labels的分类问题
#不解释