好好谈谈共线性问题
共线性,即同线性或同线型。统计学中,共线性即多重共线性。
多重共线性(Multicollinearity)是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。
一般来说,由于经济数据的限制使得模型设计不当,导致设计矩阵中解释变量间存在普遍的相关关系。完全共线性的情况并不多见,一般出现的是在一定程度上的共线性,即近似共线性。
1、先谈谈共线性的一般性的影响,
太多相关度很高的特征并没有提供太多的信息量,并没有提高数据可以达到的上限,相反,数据集拥有更多的特征意味着更容易收到噪声的影响,更容易收到特征偏移的影响等等,简单举个例子,N个特征全都不受到到内在或者外在因素干扰的概率为k,则2N个特征全部不受到内在或外在因素干扰的概率必然远小于k。这个问题实际上对于各类算法都存在着一定的不良影响;
2、然后谈谈线性回归和逻辑回归是怎么受到共线性影响的。
逻辑回归的梯度更新公式:
转为代码:
weights = weights - alpha * dataMatrix.transpose()* error其中alpha为学习率,dataMatrix.transpose()为原始数据的矩阵,error=y_pred-y_true.
从这里可以看出,共线性问题对于逻辑回归损失函数的最优化没影响,参数都是一样更新,一样更新到收敛为止。所以对于预测来说没什么影响。
那共线性会引发什么问题。。。。:
1、模型参数估计不准确,有时甚至会出现回归系数的符号与实际情况完全相反的情况,比如逻辑上应该系数为正的特征系数 算出来为负。
2、本应该显著的自变量不显著,本不显著的自变量却呈现出显著性(也就是说,无法从p-值的大小判断出变量是否显著——下面会给一个例子)
3、多重共线性使参数估计值的方差增大,模型参数不稳定,也就是每次训练得到的权重系数差异都比较大。
其实多重共线性这样理解会简单很多:
假设原始的线性回归公式为:
y=w1*x1+w2*x2+w3*x3
训练完毕的线性回归公式为:
y=5x1+7x2+10x3,
此时加入一个新特征x4,假设x4和x3高度相关,x4=2x3,则
y=w1*x1+w2*x2+w3*x3+w4*x4=w1*x1+w2*x2+(w3+2w4)*x3
因为我们之前拟合出来的最优的回归方程为:
y=5x1+7x2+10x3
显然w3+2w4可以合并成一个新的权重稀疏 w5,则
y=w1*x1+w2*x2+w5*x3,显然:
y=w1*x1+w2*x2+w3*x3和y=w1*x1+w2*x2+w5*x3是等价的。。。。
那么最终最优的模型应该也是 y=5x1+7x2+10x3
但是考虑到引入了x4,所以w4和w3的权重是分开计算出来的,这就导致了
w5=10=w3+2w4,显然这个方程有无穷多的解,比如w3=4,w4=3,或者w4=-1,w3=12等,因此导致了模型系数估计的不稳定并且可能会出现负系数的问题。
下面的图和链接都不错。
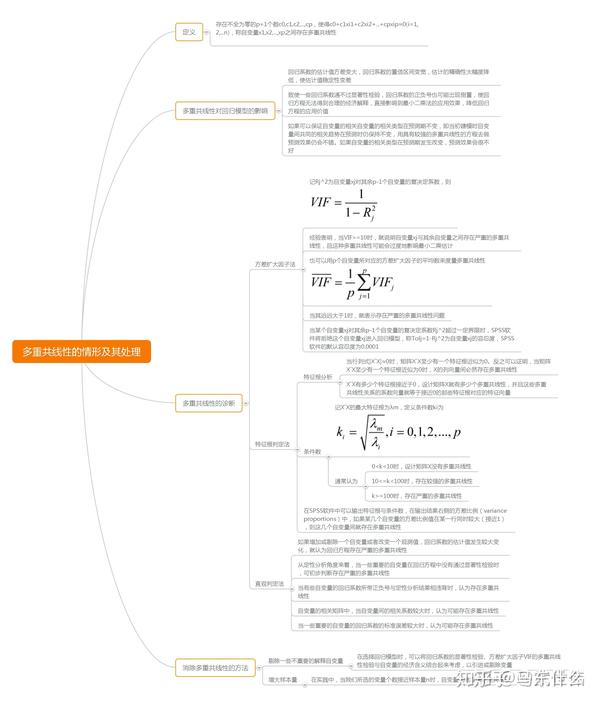

glfkuan:模型中存在共线性问题,该怎么破?

先从线性回归说起。
关于statsmodel,这里也介绍了每个指标的含义:
https://blog.csdn.net/zm147451753/article/details/83107535这一篇已经解释的非常好了。做一些补充吧。打比赛的时候线性回归的这些检验基本没什么人做,但是业务上经常要求做各种各样的检验。statsmodel的检验项目比较全面,实际上逻辑回归与线性回归比我们想象的要复杂。

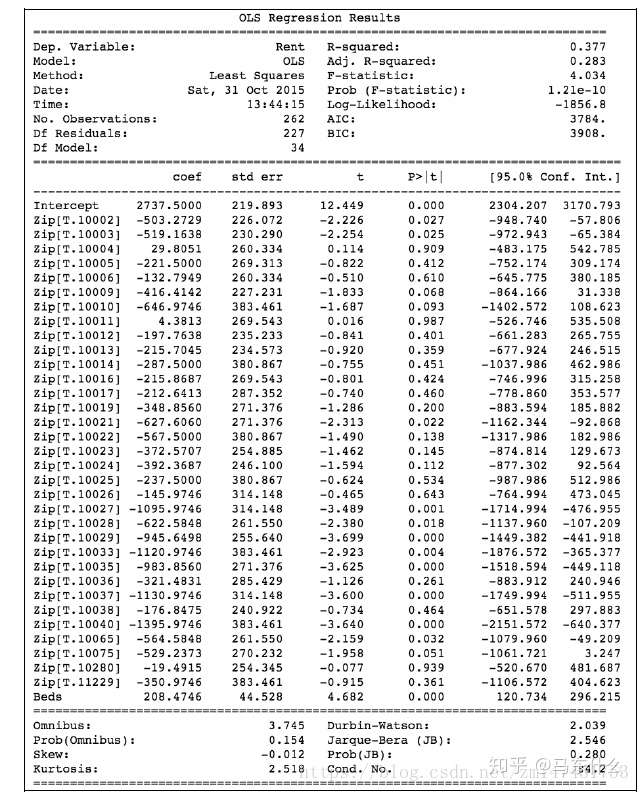
DF Residuals:
残差的自由度(等于 观测数也就是样本数(No. Observations)-参数数目(Df Model+1(常量参数,权重加上偏置的数量)))
Df Model:
模型参数个数(不包含常量参数)
R-squared:可决系数:


上面分子就是我们训练出的模型预测的所有误差。
下面分母就是不管什么我们猜的结果就是y的平均数。(瞎猜的误差)
adj-R-squared:修正可决系数:

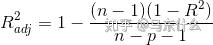
右边式子的R就是原始的R-sqaure,n是样本数量,p是特征的数量。
F-statistic:
Prob:p-value
统计显著性值,
还是系统性的回顾一下回归统计学方面的知识吧,好多细节都忘记了。
相关文章
什么是云开发?小程序实例超详细演示~

什么是高/低方差、高/低偏差、(推荐阅读)

LeetCode简单题之统计数组中相等且可以被整除的数对

LeetCode简单题之统计各位数字之和为偶数的整数个数

残差复合正态分布的重要性

分享几个免费设计生成及参考工具 (第四期)
