Subjects: cs.CV
1.End-to-End Spatio-Temporal Action Localisation with Video Transformers

标题:使用视频转换器进行端到端时空动作定位
作者:Alexey Gritsenko, Xuehan Xiong, Josip Djolonga, Mostafa Dehghani, Chen Sun, Mario Lučić, Cordelia Schmid, Anurag Arnab
文章链接:https://arxiv.org/abs/2304.12160
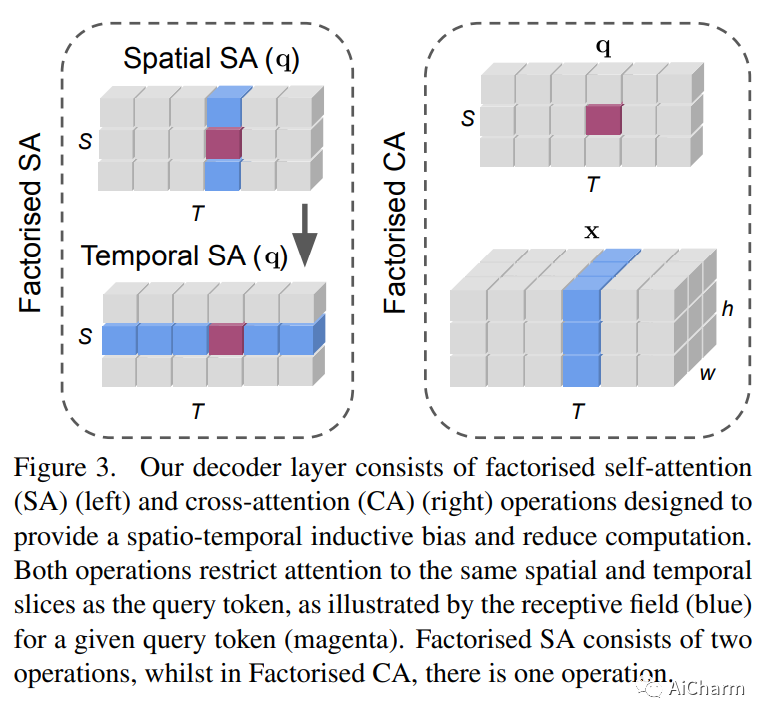
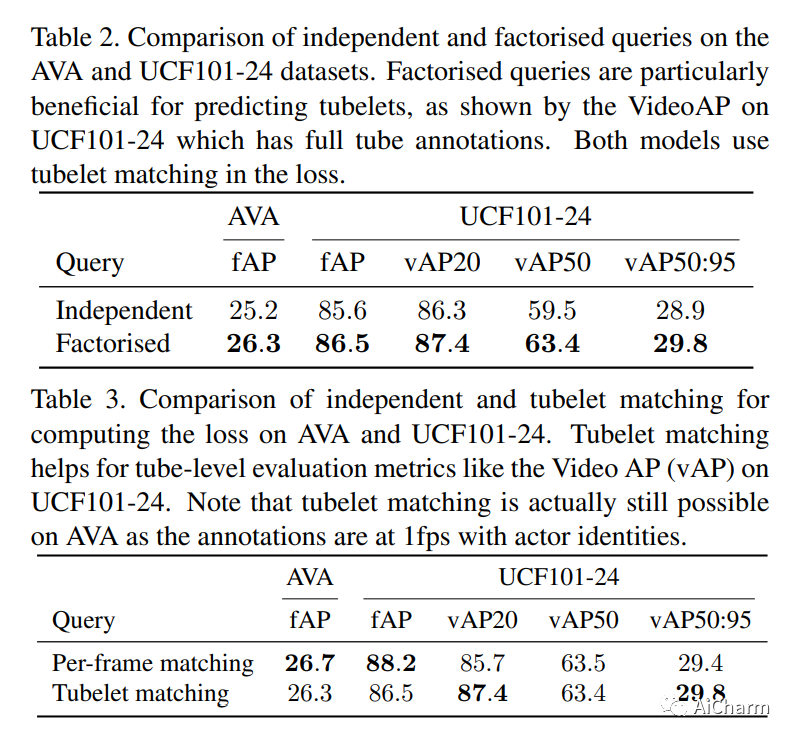
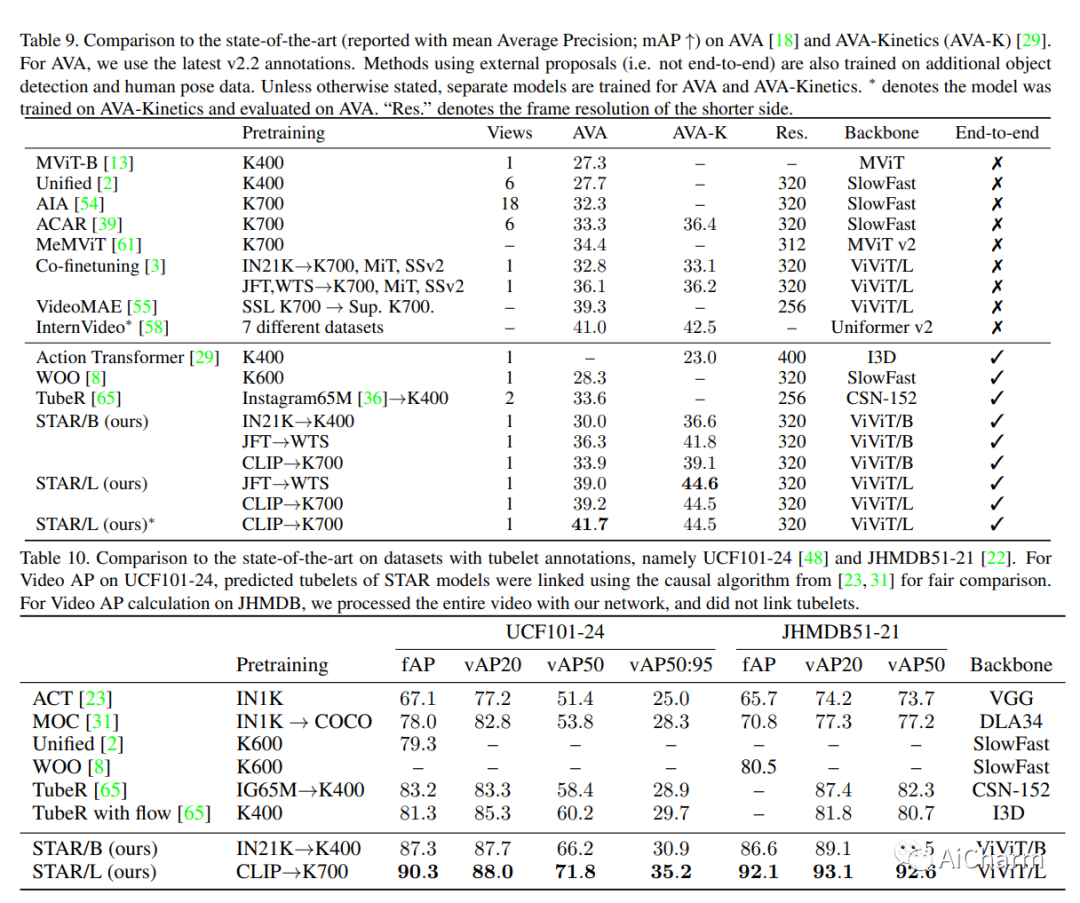
摘要:
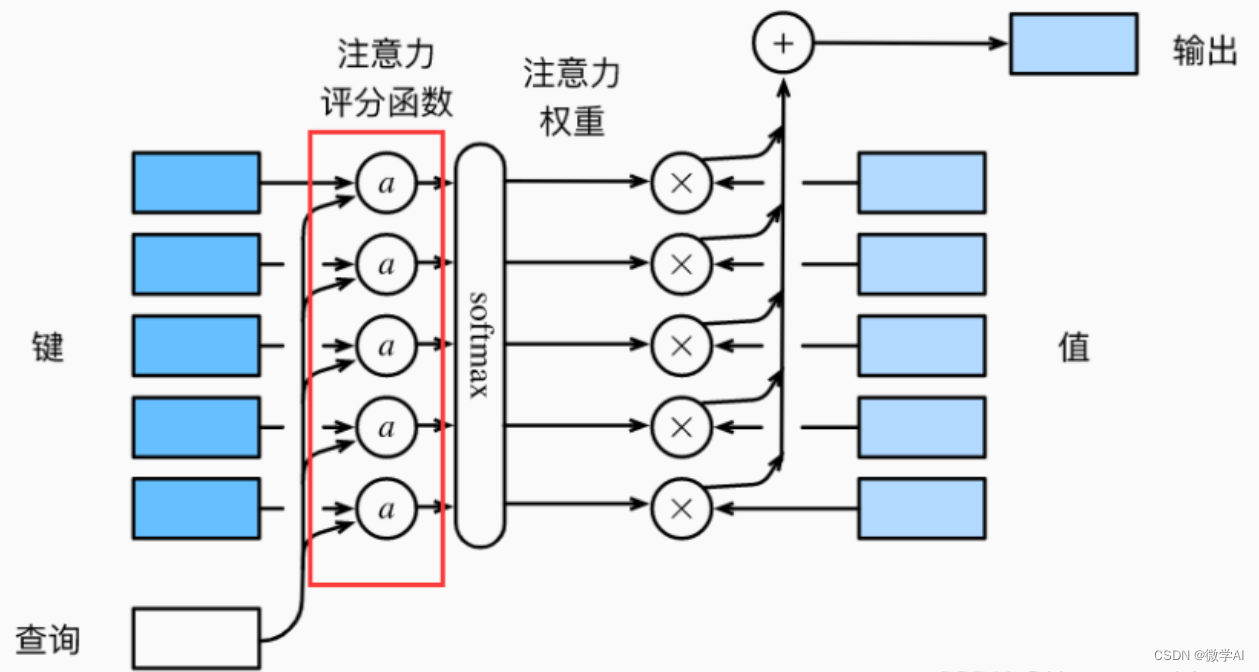
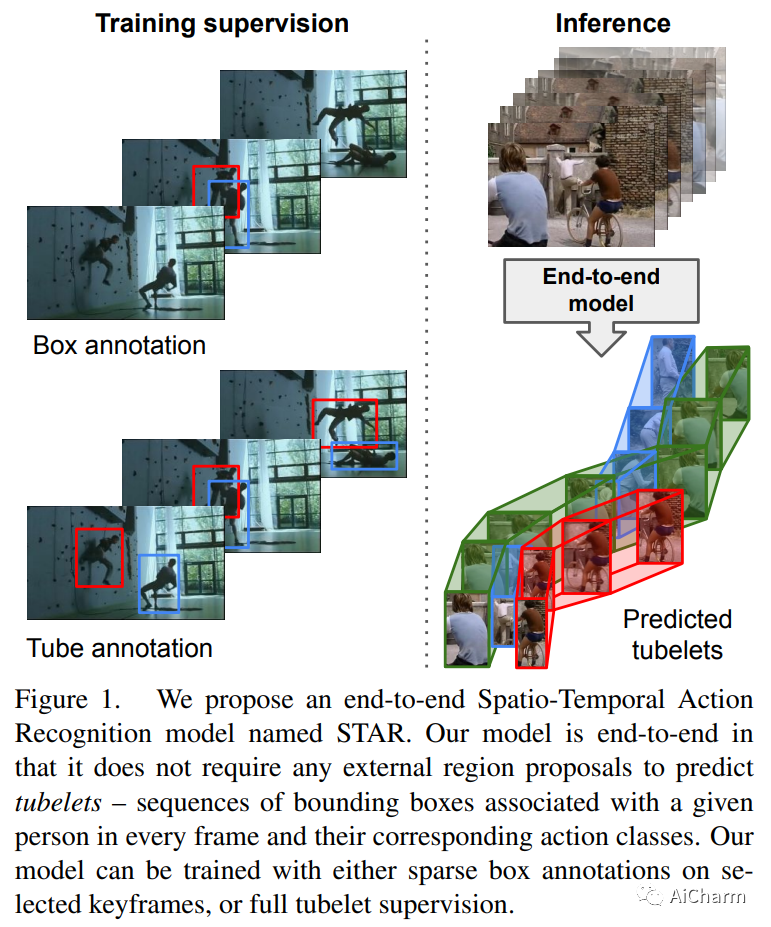
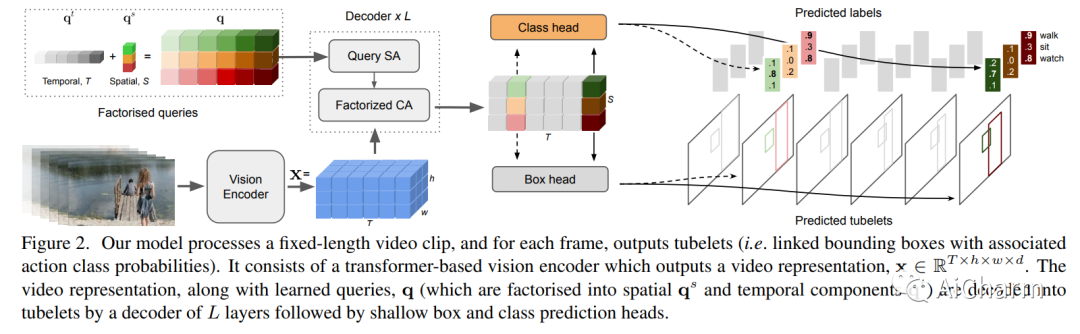
性能最高的时空动作定位模型使用外部人员建议和复杂的外部记忆库。我们提出了一个完全端到端的、纯基于变压器的模型,它直接摄取输入视频,并输出小管——一系列边界框和每帧的动作类。我们的灵活模型可以通过对单个帧的稀疏边界框监督或完整的小管注释进行训练。在这两种情况下,它都预测连贯的小管作为输出。此外,我们的端到端模型不需要以建议的形式进行额外的预处理,也不需要在非最大抑制方面进行后处理。我们进行了广泛的消融实验,并在具有稀疏关键帧和完整小管注释的四种不同时空动作定位基准上显着提高了最先进的结果。
2.Total-Recon: Deformable Scene Reconstruction for Embodied View Synthesis

标题:Total-Recon:用于具体视图合成的可变形场景重建
作者:Chonghyuk Song, Gengshan Yang, Kangle Deng, Jun-Yan Zhu, Deva Ramanan
文章链接:https://arxiv.org/abs/2304.12317
项目代码:https://andrewsonga.github.io/totalrecon




摘要:
我们从可变形场景的单目视频中探索具身视图合成的任务。给定一分钟长的人与宠物互动的 RGBD 视频,我们根据演员在场景中的运动得出的新颖摄像机轨迹渲染场景:(1) 模拟目标演员视角的以自我为中心的摄像机和 (2)跟随演员的第三人称摄像机。构建这样一个系统需要重建场景中每个演员的根体和关节运动,以及支持自由视点合成的场景表示。较长的视频更有可能从不同的角度捕捉场景(这有助于重建),但也更有可能包含更大的运动(这使重建复杂化)。为了应对这些挑战,我们提出了 Total-Recon,这是第一种从长单眼 RGBD 视频中逼真地重建可变形场景的方法。至关重要的是,为了扩展到长视频,我们的方法将场景运动分层分解为每个对象的运动,对象本身又分解为全局根体运动和局部关节。为了量化这种“野外”重建和视图合成,我们从专门的立体 RGBD 捕获装置收集了 11 个具有挑战性的视频的地面实况数据,明显优于现有技术。可以在此 https URL 中找到代码、视频和数据。
3.Spatial-Language Attention Policies for Efficient Robot Learning

标题:高效机器人学习的空间语言注意策略
作者:Priyam Parashar, Jay Vakil, Sam Powers, Chris Paxton
文章链接:https://arxiv.org/abs/2304.11235

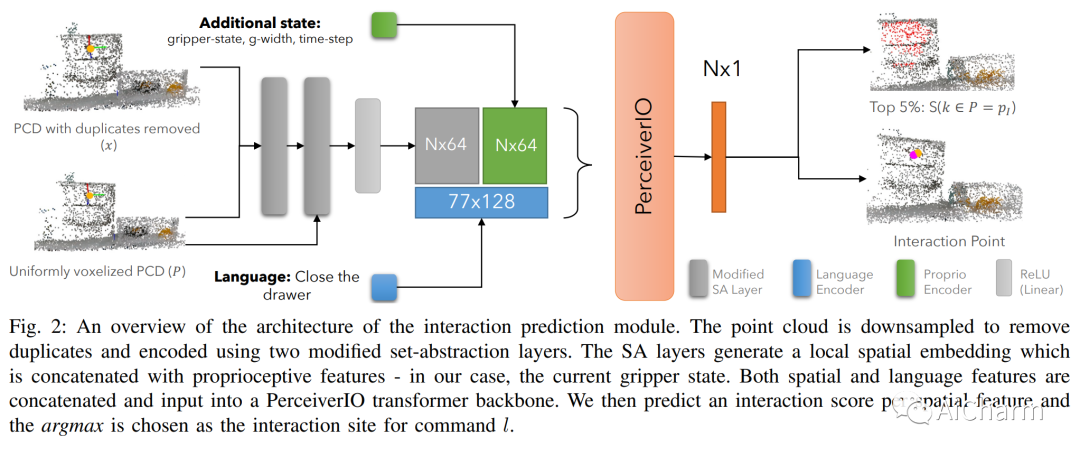
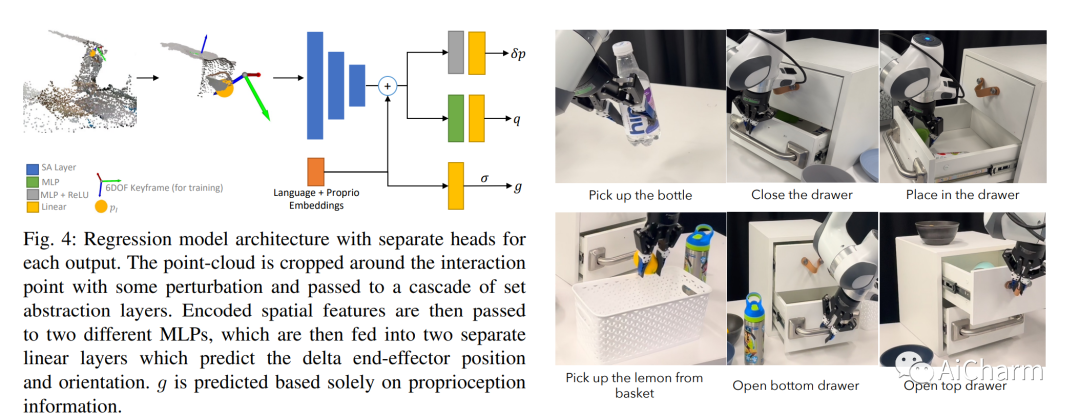
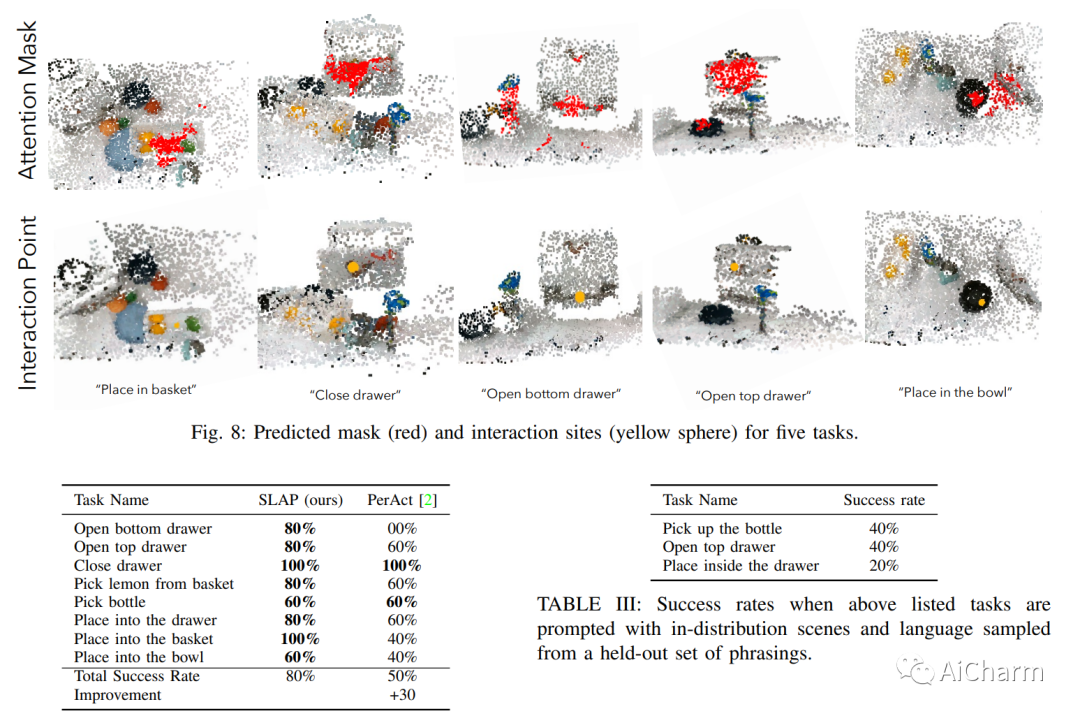

摘要:
我们研究如何使用 Transformers 构建和训练用于机器人决策的空间表示。特别是,对于在各种环境中运行的机器人,我们必须能够快速训练或微调机器人感觉运动策略,这些策略对杂波具有鲁棒性、数据效率高,并且可以很好地泛化到不同的环境。作为解决方案,我们提出了空间语言注意策略(SLAP)。SLAP 使用三维标记作为输入表示来训练单个多任务、语言条件动作预测策略。我们的方法在现实世界中使用单个模型在八个任务中显示了 80% 的成功率,并且在引入看不见的杂乱和看不见的对象配置时成功率为 47.5%,即使每个任务只有少数示例。这表示比之前的工作提高了 30%(考虑到看不见的干扰因素和配置,提高了 20%)。