导入数据
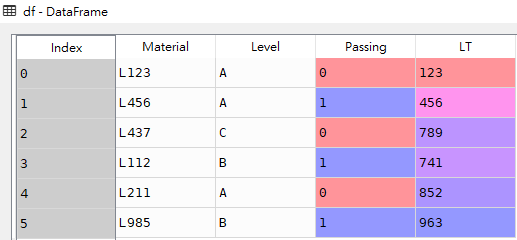
import pandas as pddf = pd.DataFrame([['L123','A',0,123],['L456','A',1,456],['L437','C',0,789],['L112','B',1,741],['L211','A',0,852],['L985','B',1,963]],columns=['Material','Level','Passing','LT'])df
1.dtypes: 查看DataFrame中各列的数据类型
df.dtypes会返回每个字段的数据类型及DataFrame整体的类型
# 查看各字段的数据类型
df.dtypes结果如下
Material object
Level object
Passing int64
LT int64
dtype: object
可以看到,字段'Material'和'Level'为object,其他字段都是int64
2.values: 返回DataFrame中的数值
# array(<所有值的列表矩阵>)
df.values结果如下
array([['L123', 'A', 0, 123],
['L456', 'A', 1, 456],
['L437', 'C', 0, 789],
['L112', 'B', 1, 741],
['L211', 'A', 0, 852],
['L985', 'B', 1, 963]], dtype=object)
3.size: 返回DataFrame中元素的个数
# 元素个数 = 行数 * 列数
df.size结果如下
24
4.shape: 返回DataFrame的行数与列数
执行df.shape会返回一个元组,该元组的第一个元素代表行数,第二个元素代表列数
# 返回一个元组(行数,列数)
df.shape结果如下
(6, 4)
可以看到,上述数据框df有6行4列的数据
5.ndim: 返回DataFrame的维度数
df.ndim结果如下
2
6.index: 返回DataFrame中的行索引
df.index结果如下
RangeIndex(start=0, stop=6, step=1)
7.columns: 返回DataFrame中的列索引
df.columns结果如下
Index(['Material', 'Level', 'Passing', 'LT'], dtype='object')
8.info: 返回DataFrame中的基本信息
执行df.info会显示所有数据的类型、索引情况、行列数、各字段数据类型、内存占用等
df.info结果如下
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 4 columns):
Material 6 non-null object
Level 6 non-null object
Passing 6 non-null int64
LT 6 non-null int64
dtypes: int64(2), object(2)
memory usage: 272.0+ bytes
9.查看DataFrame部分样本信息
df.head(): 显示DataFrame头部几行数据,默认5条,可指定条数
# 默认查看DataFrame前5条数据
df.head()结果如下
Material Level Passing LT
0 L123 A 0 123
1 L456 A 1 456
2 L437 C 0 789
3 L112 B 1 741
4 L211 A 0 852
# 查看DataFrame前3条数据
df.head(3)结果如下
Material Level Passing LT
0 L123 A 0 123
1 L456 A 1 456
2 L437 C 0 789
df.tail(): 显示DataFrame尾部几行数据,默认5条,可指定条数
# 默认查看DataFrame后5条数据
df.tail()结果如下
Material Level Passing LT
1 L456 A 1 456
2 L437 C 0 789
3 L112 B 1 741
4 L211 A 0 852
5 L985 B 1 963
# 查看DataFrame后3条数据
df.tail(3)结果如下
Material Level Passing LT
3 L112 B 1 741
4 L211 A 0 852
5 L985 B 1 963
df.sample(): 显示DataFrame一条随机数据,可指定条数
# 随机查看一条数据
df.sample()结果如下
Material Level Passing LT
4 L211 A 0 852
# 随机查看3条数据
df.sample(3)结果如下
Material Level Passing LT
5 L985 B 1 963
1 L456 A 1 456
0 L123 A 0 123
10.查看DataFrame的统计信息
df.describe()显示DataFrame的统计信息(只能统计数值类型的列)
'''
count:这一组数据中包含数据的个数(数量)
mean:这一组数据的平均值(平均数)
std:标准差
min:最小值
max:最大值
25%,50%,75%:百分位数,其中50%是中位数
'''
df.describe()百分位数
如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数,以Pk表示第k百分位数
Pk表示至少有k%的资料小于或等于这个数,而同时也有(100-k)%的资料大于或等于这个数以身高为例,身高分布的第五百分位数表示有5%的人的身高小于或等于此测量值,95%的身高大于或等于此测量值
结果如下
Passing LT
count 6.000000 6.000000
mean 0.500000 654.000000
std 0.547723 310.368813
min 0.000000 123.000000
25% 0.000000 527.250000
50% 0.500000 765.000000
75% 1.000000 836.250000
max 1.000000 963.000000
df.describe()会返回一个有多行的所有数字列的统计表,每一行对应一个统计指标
提示Tips: 如果DataFrame没有数字列,则会输出与字符相关的统计数据
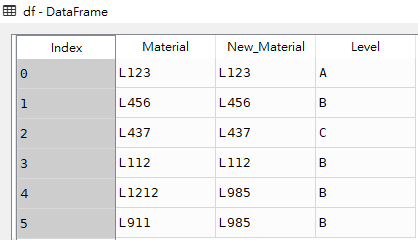
import pandas as pddf = pd.DataFrame([['L123','L123','A'],['L456','L456','B'],['L437','L437','C'],['L112','L112','B'],['L1212','L985','B'],['L911','L985','B']],columns=['Material','New_Material','Level'])df
'''
count:这一组数据中包含数据的个数(数量)
unique:表示有多少种不同的值(不重复值数)
top:最大值(按首字母排序)
freq:最大值(top)的出现频率
'''
df.describe()结果如下
Material New_Material Level
count 6 6 6
unique 6 5 3
top L911 L985 B
freq 1 2 4