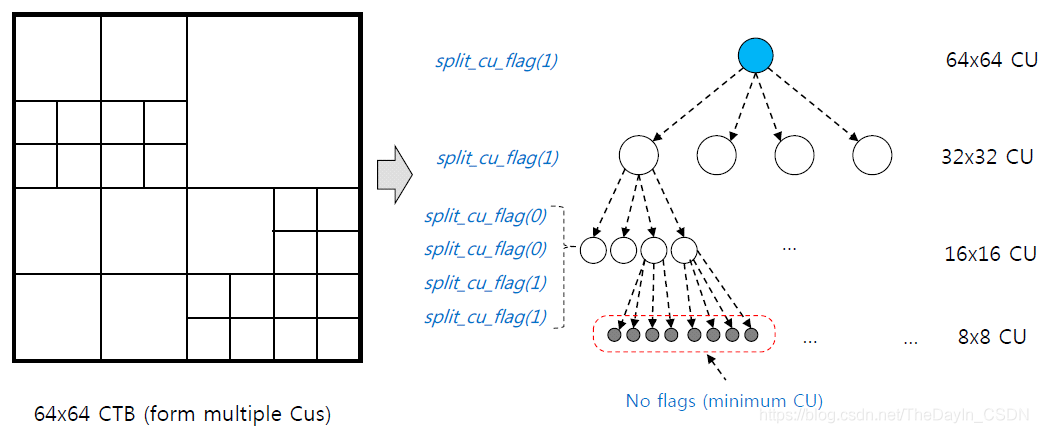
视频监控与视频编解码技术
参考文献链接
https://mp.weixin.qq.com/s/UW4Z0vu_Wypc0ddymrOkpg
https://mp.weixin.qq.com/s/RfsTTNekpJeIX5DH4ViAqg
https://mp.weixin.qq.com/s/smj5bsqXgKuz7RvoLqFKjg
https://mp.weixin.qq.com/s/p5gB7q03YfhN-0N7LvQ43g
安防智能视频监控系统

智能化网络安防视频监控系统所需要的必备功能应该有下列几个方面。
相应防区的安全防范设备,从而实现综合化的安全防范功能
安防智能视频监控系统除主要的视频监控系统外,必须要能联动相应防区的安全防范设备,如出入口控制系统,防火防盗报警系统等,即门禁探测器、防火与防盗及煤气与放射线等泄漏等安全的报警探测器等,以达到综合化的安全防范的目的。例如,当接收到门禁探测器或防火、防盗及煤气与放射线等泄漏的报警信号时,相应位置的网络摄像机应能通过可预置云台自动转到相应的预置位,以自动进行录像,并触发警铃与警灯,进行声光报警,从而实现综合化的安全防范功能。
充分保证智能监控系统的安全与可靠性
智能化网络安防监控系统也是基于计算机网络的安防监控系统,因而系统应对网络中的非法访问、非法入侵等具有抵御能力,从而充分保证视频监控系统的安全性,如访问安全性、传输安全性等。此外,智能监控系统还应经过可靠性设计,EMC设计,以提高系统的抗干扰能力,充分保证系统工作的可靠性,以真正做到保平安。
应有简单而基本的智能功能
(1)有视频遮挡与视频丢失侦测的识别与预/报警功能。在一个大型的安防监控系统中,监控中心的值班人员所能顾及或者查看的最大可能是几十路视频图像。如果系统中某一路视频图像被遮挡或丢失时,大多是因为这一路摄像机被人为遮挡或破坏或本身故障等,而值班人员很难在第一时间发现,这有可能会带来重大的安全隐患。但当系统具有视频遮挡或视频丢失侦测感知的智能识别与预/报警功能时,值班人员则能第一时间根据声光报警进行查看与处理,从而可消除视频图像被遮挡或丢失所造成的安全隐患。(2)有视频变换侦测的识别与预/报警功能。在一般的网络安防监控系统中,当其中某一路视频图像变换了(即不是原定的设防点的视频图像范围)时,这多半是罪犯想对原设防点实施犯罪而移动了摄像机或摄像机受到较大的震动而移动等,值班人员在第一时间也很难发现。当系统具有视频变换侦测感知的识别与预/报警的智能功能时,值班人员则能第一时间根据声光报警进行查看与处理,从而可消除视频变换所造成的安全隐患。(3)有视频模糊与对火灾、雾灾、风沙灾侦测的识别与预/报警功能。在智能安防监控系统中,当侦测到其中某一路视频图像模糊,可能是因为摄像机镜头被移动(即焦距丢失),或者是因为火灾前的烟雾,或大雾天气,或风沙灾(即大风或沙尘)引起的原设定的视频图像模糊不清等时,即可自动启动录像、定点显示与预/报警。这样,值班人员就能第一时间根据声光报警的指示位置去进行查看与处理,并且还可参考气象台当天的预报,以判别是天灾还是人祸。(4)有对水灾、危房、桥梁、山石崩、雪崩、地震侦测的识别与预/报警功能。在智能安防监控系统中,还必须有对城市水灾的水位、危房、桥梁易断处、道路危险路段或铁路公路旁易发生山石崩、雪崩,以及地震站侦测地震等的地方,进行智能检测与识别。为检测方便易行,最好安置带十字刻度标尺的摄像机加上这种智能软件模块去进行监视。当视频设防点的视频图像移动到十字标尺的某一警告刻度时,经智能软件识别即能自动启动录像、定点显示与预/报警,从而使值班人员能第一时间根据声光报警去进行查看与处理。(5)有视频移动侦测的识别与预/报警功能。在在智能安防监控系统中,必须至少有视频移动侦测的预/报警功能,这尤其在银行、珠宝店、商店、仓库、财会室、军械室、保密室、博物馆、油库,以及一切重要的监控的场所对安全性要求比较高的地方均需设置。当然,这一功能必须要滤除老鼠、猫、狗等小动物,以及由光线变化等环境带来的干扰,尤其在如雨雪、大雾、大风等复杂的天气环境中,要能精确地侦测和识别单个物体或多个物体的运动情况,包括其运动方向、运动特征等。还需指出的是,较好的视频移动侦测可设置不同的检测方式,在定义区域内的任何变化均可触发报警的标准方式;允许在某个方向发生变化而不报警,但如果往另一相反方向的变化则发生报警的方向方式;存储一幅图像并与活动图像进行比较,只有当这幅图像发生变化或观察被阻碍时才发生报警的防守方式。此外,视频移动的检测区域还可单独地进行开或关,以适应特殊时间段各出入口、大厅、停车场等的要求,以及有标定监视区域各位置的物体大小容差的透射补偿校正功能等。当侦测与识别到是不认识的移动人体侵入时,即自动启动录像、定点显示与预/报警,使值班人员能第一时间根据声光报警进行查看与处理。在侦测到移动人体之后,要能根据其运动情况,自动发送PTZ控制指令,使带云台的摄像机能够自动跟踪物体。如人体超出该摄像机监控范围之后,能自动通知人体所在区域的其他摄像机继续进行追踪,直到抓捕罪犯为止。(6)出入口人数统计功能。该项智能化功能能够通过视频监控设备对监控画面的分析,自动统计计算穿越国家重要部门、重要出入口或指定区域的人或物体的数量。这一智能化功能的应用还可广泛用在商业用途,如服务、零售等行业用来协助管理者分析营业情况,或提高服务质量,如为业主计算某天光顾其店铺的顾客数量等。上述的智能化功能,较简单而基本,因而可安置于安防监控系统的前端网络摄像机或网络DVS与网络DVR中。
应拥有的高端的智能功能
(1)有对电子警察联动与车牌识别的检测、处理、识别、跟踪的预/报警功能。在平安城市的安防监控系统中,还必须要有与电子警察联动及与车牌识别的检测、处理、识别、跟踪的预/报警功能。在电子警察系统中,有车辆闯红灯、压黄线、逆向行驶、超速等违章行为的检测,并检测识别违章车辆的车牌,除存储打印该车及违章时间外,同时预/报警并跟踪该车。欲知详情,可参阅作者撰写于AS(安防工程商)中的“智能交通中的视频检测的电子警察系统”一文。(2)有对智能交通的联动功能,如车型、车速、车辆拥堵与疏导等的检测、处理、识别、跟踪的预/报警功能。在平安城市的安防监控系统中,还必须要有对智能交通的联动功能,如车型、车速、车辆拥堵与疏导等的检测、处理、识别、跟踪的预/报警功能。智能安防监控系统可对从前端接收的视频进行智能分析,并在此基础上实现所需要的智能交通中的各种应用,如对道路车辆视频进行分析,从而实现车速的视频检测、车型与车辆拥堵与疏导等的视频检测、识别等功能。欲知详情,可参阅作者撰写于AS(安防工程商)中的“平安城市中的智能交通系统”一文,与刊于ITS中的“视频检测技术在智能交通中的应用”文章。(3)有对人体生物特征如面像、步态、声音检测、处理、识别、跟踪的预/报警功能。通常,智能安防监控系统必须要在城市出入口(民航、铁路与公路站口、轮船码头等)、过道,以及军事、公安、政府、银行、博物馆、珠宝店等重要机密与财产的地方,设置面像,或步态,或声音等人体生物特征识别。尤其面像与步态识别,不像指纹识别与眼虹膜识别等那样需要人的配合,它可以在离摄像头有相当远的距离内在人群中识别出特定的个体。因为它可将捕捉到的面像与步态的视频或声音,与数据库档案中的面像、步态或声音的资料进行比对识别,如识别是通揖等逃犯与其他疑犯,则会立即自动启动录像与预/报警,并进行跟踪,直到抓捕罪犯为止。(4)有对人与物异常行为的检测、处理、识别、跟踪的预/报警功能。智能安防监控系统,还必须要有对人与物异常行为的检测、处理、识别、跟踪的预/报警功能。有了这一功能后,即可对公共场所视频进行分析处理,实现人与物的异常动作捕捉。如对持刀或枪抢劫、绑架杀人、翻越院墙、栏杆,机动车开进绿化草地、撞人逃跑,以及可疑滞留物体(如化学与縻炸物体)超过预定时间段等异常行为,进行分析处理、识别、并锁定跟踪与预/报警,从而保障人民生命和财产的安全。(5)人群及其注意力的检测控制、识别与预/报警。该项智能化功能,能识别人群的整体运动特征,包括速度、方向等,用以避免形成拥塞,或者及时发现可能有打群架等异常情况,其典型的应用场景包括超级市场、火车站、娱乐场所等人员聚集的地方。此外,还可统计人们在某物体前面停留的时间,据此还可以用来评估新产品或新促销策略的吸引力,也可以用来计算为顾客提供服务所用的时间等。(6)有自动开关灯光、调整光强与监控有无外人侵入的智能功能。在党政机关、学校、企业和大型家居环境,视频分析技术还可用来消除巨大的电能浪费与安全隐患,如能视天气情况等自动关闭不必要的灯或调整灯光的强度,以及自动监控有无外人入侵等。因为智能安防视频监控系统可随时计算出在一定的环境中什么位置有人走动或办公,能自动打开或增强相应位置的灯光,自动关闭或减弱其他位置的灯光。在单位或家庭有存入本单位或家庭人员情况的数据库时,还可用来自动分析与识别这些环境中的人是否与数据库中己有的一致,如发现不同时,能及时进行预/报警等。(7)有与GPS、GIS等集成的联动功能。智能安防监控系统,还必须要有与GPS、GIS等集成的联动功能。系统在后端服务器,视频管理平台将资源集中于系统集成性上,以实现视频监控系统与GPS、GIS电子地图系统、警务管理系统,.以及办公管理系统、电话系统的无缝集成。当发生前端视频异常需预/报警时,通过Outlook向相关人员发送电子邮件,上传图像,同时通过GPS、GIS电子地图实现地点精确定位,并联动警务系统查找相关区域负责警员,再由电话系统自动拨打警员电话,通知其迅速响应。(8)有与微波雷达、THz波雷达等的联动功能。在大中城市的大型智能安防监控系统中,最好还要有与微波雷达、THz波雷达等的联动功能。这一功能主要是防止类似美国“9・11”事件的发生,因为雷达可监视天空,尤其将要诞生的新的THz波雷达,其监视距离远、精度高。只要发现在某一空域出现非计划中飞行的飞机与飞行物,即可触发预/报警,监控中心核实无误后,即实施打击,以确保城市安全。
400多路视频监控系统的方案设计
项目共计438路视频:130万像素高清红外高速球机96台,130万像素高清红外枪机256台、130万像素高清红外半球86台。后端电视墙采用16块46寸拼接屏,30天24小时主码流不间断存储。
项目分析
视频采集系统、视频传输系统、视频切换管理系统、视频显示系统、视频录像系统这五个大部分组成了一个标准的视频监控系统。视频采集系统主要是完成对前端图像信号的获取;
视频传输控制系统完成对前端图像信号的传送和控制通信;
视频切换管理系统完成对图像信号的切换控制和资源分配;
视频显示系统完成对前端图像信号的终端设备输出;
视频录像系统完成对前端图像信号的长延时存储和回放。
在系统工程中,良好的视频传输设计是监控系统非常重要的一部分。如果建设一套好的系统,选用的都是高指标、高画质的摄像机、监视器、录像机,但是没有良好的传输系统,最终在监视器上看到的图像将无法令人满意。
在一个大型网络监控系统中,如何走线布线,交换机如何选型,如何保证整个网络传输系统视频流畅以及项目后期维护管理更方便。在很多网络视频监控项目中往往会因为交换机的配置不够合理、选型不到位、带宽不足, 我们经常能听到客户很多的抱怨,比如网线支持距离不够,图像出现掉帧、卡顿、延迟现象,IP地址理解、理解规划困难,网管人员奇缺等。特别是工程们对这块的体会是最深的。针对以上的情形为例来讲下整个项目的配置过程。
项目情况
1、项目情况:
项目共计438路视频:130万像素高清红外高速球机96台,130万像素高清红外枪机256台、130万像素高清红外半球86台。后端电视墙采用16块46寸拼接屏,30天24小时主码流不间断存储。
视频传输部分:考虑到本项目各个视频点比较分散,为了方便布线及后期系统维护管理,交换机我们给客户推荐采用了300米传输的专业工程交换机,前端视频通过网络传输到接入层接换机在通过光纤传输监控中心。
2、1交换机的优势
1)、300米网络传输:
高度解决了摄像头比较分散的问题,可以将同义聚集点更远的视频传输到一起同时传到监控中心,也间接节约了交换机的数量及整个系统成本。
2)、拓扑功能:
组网完成后,整个系统整个项目的所以的视频链接在拓扑图上可以一目了然。如下图:
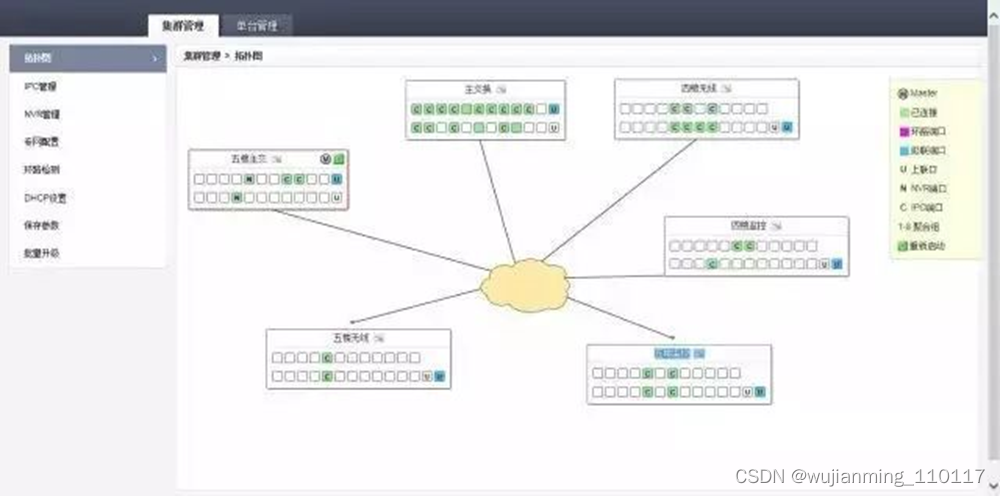
每个交换机可以按相应的交换机地方备注名字,比如:(1楼1层交换机)以此类推,形成有效的集群管理。
3、固定端口识别IP功能:
对于支持ONVIF协议的NVR、IP Camera能够自动识别出来,并表明设备厂商、型号、地点等信息。
并且标明NVR和IP Camera之间的关系,即哪些IP Camera是受哪台NVR所管理的。如下图:我们可以看到几个字母和按钮:U表示上联口(交换机与交换机连接用),C表示IPC(即摄像头),N表示NVR(网络硬盘录像机)

鼠标停留在“C"位置可以看到IPC的IP地址和相关信息.鼠标停留在"N"位置可以看到NVR的IP地址和相关信息
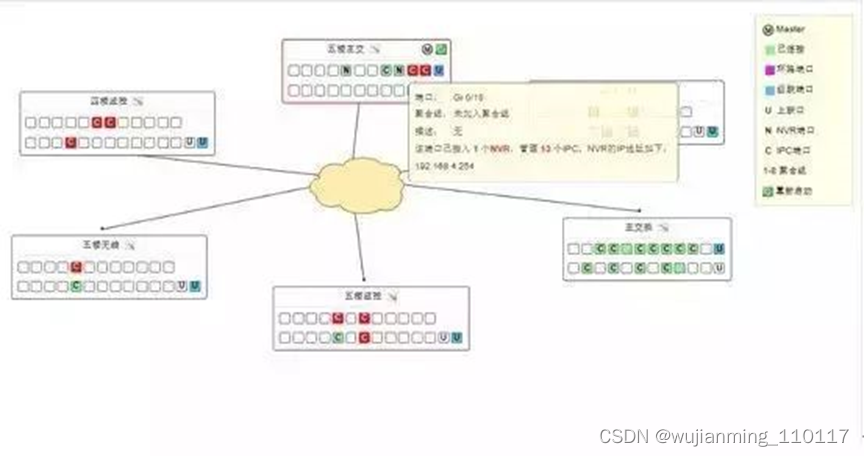
将鼠标停留在N字母标识上,不仅可以看到NVR的IP地址还会使连接NVR上的所有IPC闪烁,无论连接在哪个交换机,只要是连接到同一台NVR,便会闪烁。
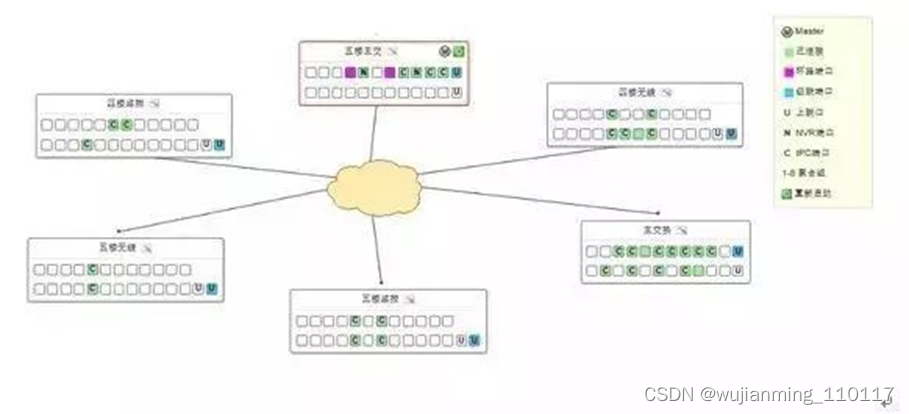
4、环路检测功能:
在网络中Netis Vision交换机之间能自动识别出端口之间的环路后屏蔽并标记出来,任意插线造成环路后也不会对网络产生影响,在拓扑中标记成紫色后方便维护和故障排除,如图片:
5、通断报警、专网配置等等,这里不一一介绍。
此项目中了有这款专业视频监控交换机,布线、故障排查,维护等变得非常简单方便。
解码上墙
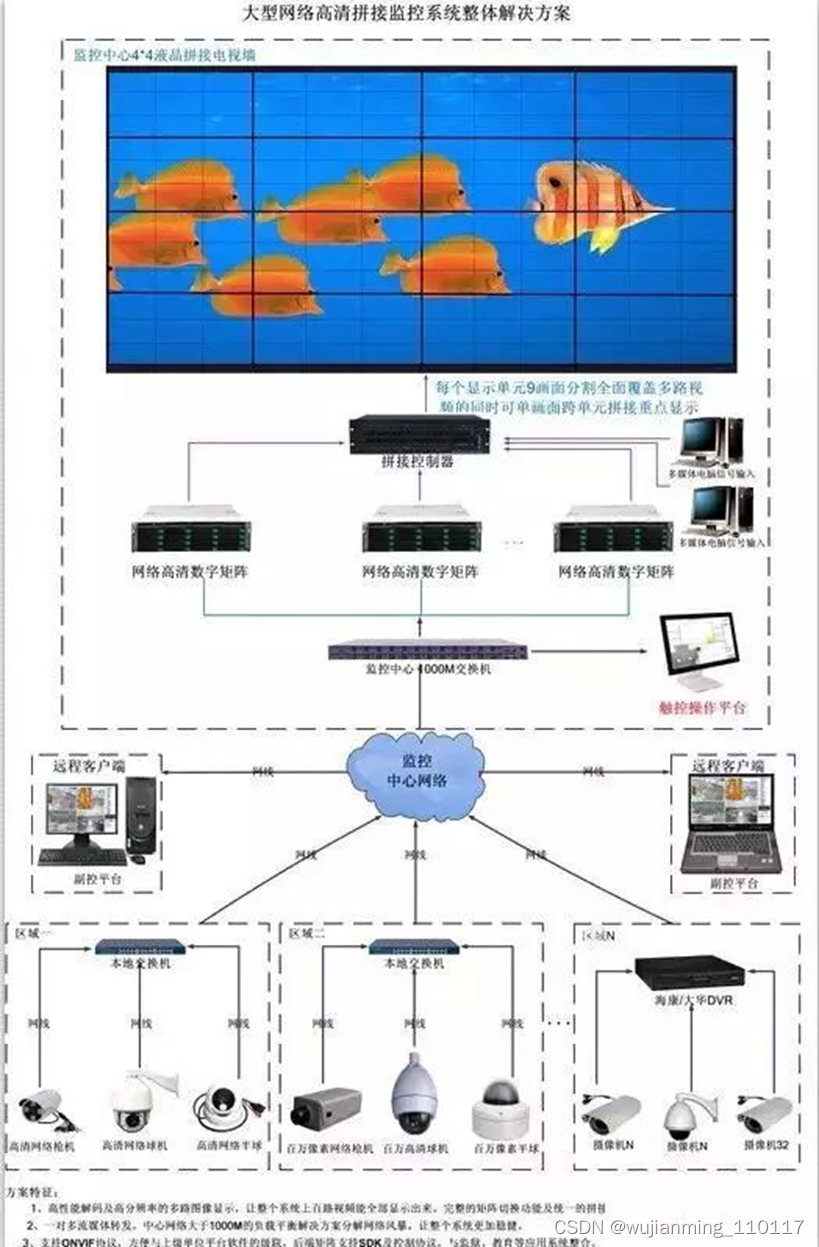
接下来解码上墙这块:438路视频按4M兆码流算,存储一个月,差不多得190块3TB硬盘,为了考虑成本,我们向客户推荐了24盘位的存储矩阵。网络高清数字矩阵拥有监控行业多个产品的功能,其中包括平台软件管理,网络高清解码,网络存储,及视频矩阵切换控制、(拼接服务器)的功能,报警联动,电子地图、门禁接入,消防报警接入。
结束语
在任何大规模系统中,中心机房的大小、产品的数量甚至能耗等,已经成为一个系统性的难题。视频监控系统同样需要在监控中心,通过由单机具备更多功能更高性能的设备来构成,这是一个重要的考虑因素。存储产品如果在保障高性能的基础上,将存储之外的一些相关功能集成到存储产品中,将会是一个适应小机房、大应用发展趋势的必然选择。整体的方案设计拓扑图如下:
视频编码复杂度持续增加,云端硬编码方案优势凸显
过去十年,基于H.264/AVC的视频编解码器一直在流媒体应用领域占主导地位,但随着Apple在iOS 11中采用H.265/HEVC以及Google在Android上力推VP9,形势悄然发生变化。明年Open Media联盟将会发布性能更高的AV1视频编解码器。视频内容提供商不久就要决定除了H.264之外是否需要进一步支持H.265和VP9,带来的结果就是视频编解码器市场将会变得支离破碎。
A. 视频编码复杂度增加:
随着视频编解码器市场的风云变幻以及消费者对更高质量视频的需求,视频内容提供商,广播服务商和OTT(Over The Top)提供商正面临视频编码的巨大开销。新的编解码器如H.265和VP9因为复杂度的增加需要5倍左右的服务器开销。当前,AV1需要超过20倍的服务器开销。此外,SD、HD和UHD视频进一步转向更高的质量,例如HDR,10bit,更高的帧率。将1080p SDR视频转成4K HDR视频需要5倍左右的服务器编码开销。目前360视频和Facebook的6DoF (Degrees of Freedom)视频需求越来越多,服务器编码开销增加了至少4倍。
综合一些因素不难看出,随着未来几年新的视频编解码器出现、更高质量视频以及360视频需求的增加,编码开销可能会增加至500倍:
• 5x 相对于当前的编码时间
• 5x 相对于H.264的编码开销(新的Codec如VP9,HEVC)
• 5x 更高分辨率,更高帧率,HDR视频(4Kp60的像素数是1080p60的5倍)
• 2x 现在起需要支持至少两种编解码器(H.264 & HEVC或VP9)
• 2x 如果需要支持360视频和Facebook的6DoF视频
B. 云端硬编码方案更具优势:
随着编码复杂度持续增加,过去一年一种新类型的云端加速器(FPGA)如雨后春笋般在市场上出现。与通过使用一种指令集进行编程的CPU或GPU不同,FPGA通过电路布线实现。这种方式与传统的专用集成电路(ASIC, Application SpecificIntegrated Circuits)类似,但最大的区别就是FPGA能够“现场编程”。这就意味着FPGA能够在云端按需编程,就像CPU和GPU一样。幸运的是,客户只需要改变一行代码就能将一个软件编码器换成FPGA编码器,并依旧使用之前的工具如FFmpeg。
x265编码器包含许多档(preset)允许用户自定义编码器配置以此平衡整体计算资源和编码需求。x265能在”very slow” 档下编出非常高的质量。在较低的编码速率下能够达到较好的压缩性能,但同时消耗的编码资源也很多。在AWS EC2 c4.8xlarge服务器上跑x265,1080p视频每秒只能编3帧,而编60fps的视频需要20倍c4.8xlarge的性能,每小时会花费33美元。
可以比较的是,视频压缩服务商NGCodec的编码器在AWS EC2 f1.2xlarge FPGA配置下能编出比x264 ”very slow” 档更高的视觉质量,并且在单台f1.2xlarge上能编出超过60fps的视频。总共的花费包括f1服务器和Codec大概只有3美元。与使用多个c4服务器相比,节省了10倍左右的开销并且避免了并行多路直播视频产生过高的复杂度。这在很大程度上得益于公有云提供商如Amazon、Baidu、Nimbix以及OVH早已在云端部署了FPGA,用户可以按需使用。此外,许多数据中心提供商也正在大力发展FPGA云硬件。
http://blog.streamingmedia.com/2017/08/cloud-hardware-acceleration.html
Stream 初步认识
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对 集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。 使用 Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数 据库查询。也可以使用 Stream API 来并行执行操作。简而言之, Stream API 提供了一种高效且易于使用的处理数据的方式。
流(Stream)到底是什么?
**是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。 ,“集合讲的是数据,流讲的是计算! ” **注:java.util.Stream表示了某一种元素的序列,在这些元素上可以进行各种操作。Stream操作可以是中间操作,也可以是完结操作。完结操作会返回一个某种类型的值,而中间操作会返回流对象本身,并且你可以通过多次调用同一个流操作方法来将操作结果串起来(就像StringBuffer的append方法一样————译者注)。Stream 是在一个源的基础上创建出来的,例如 java.util.Collection 中的 list 或者 set(map 不能作为 Stream 的源)。Stream 操作往往可以通过顺序或者并行两种方式来执行。
注意:
-
Stream关注的是对数据的运算,与CPU打交道集合关注的是数据的存储,与内存打交道
-
①Stream 自已不会储存元素。 ②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行(类似于懒加载)
Stream 操作
stream 操作步骤 -
创建 Stream:一个数据源(如:集合,数组,Map不可以作为数据源)获取一个流
-
中间操作:一个中间操作链,对数据源的数据进行操作处理(过滤、映射…)
-
终止操作(终端操作):一个终止操作,执行中间操作链,并产生结果(一旦执行终止操作,就执行中间操作链,并产生结果。之后的,不会再被使用)
操作流程如下图:

Stream 实例化的方式
• 通过集合
• 通过数组
• 通过 Stream 的 of()
• 通过无限流 下面我们一一通过代码示例进行详细解析:
公共代码(测试使用)
公共集合
List javaProgrammers = new ArrayList() {
{
add(new Person(“Elsdon”, “Jaycob”, “Java programmer”, “male”, 2000, 18));
add(new Person(“Tamsen”, “Brittany”, “Java programmer”, “female”, 2371, 55));
add(new Person(“Floyd”, “Donny”, “Java programmer”, “male”, 3322, 25));
add(new Person(“Sindy”, “Jonie”, “Java programmer”, “female”, 35020, 15));
add(new Person(“Vere”, “Hervey”, “Java programmer”, “male”, 2272, 25));
add(new Person(“Maude”, “Jaimie”, “Java programmer”, “female”, 2057, 87));
add(new Person(“Shawn”, “Randall”, “Java programmer”, “male”, 3120, 99));
add(new Person(“Jayden”, “Corrina”, “Java programmer”, “female”, 345, 25));
add(new Person(“Palmer”, “Dene”, “Java programmer”, “male”, 3375, 14));
add(new Person(“Addison”, “Pam”, “Java programmer”, “female”, 3426, 20));
add(new Person(“Addison”, “Pam”, “Java programmer”, “female”, 3422, 20));
add(new Person(“Addison”, “Pam”, “Java programmer”, “female”, 3429, 20));
// add(new Person(“Addison”, “Pam”, “Java programmer”, null, 3422, 20));
}
};
公共实体类
package com.zy.stream.model;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@Builder(toBuilder = true)
@AllArgsConstructor
@NoArgsConstructor
public class Person {
private String firstName, lastName, job, gender;
private int salary,age;
}
通过集合创建 Stream 流
//1.1 通过集合创建Stream流------> default Stream stream:返回一个顺序流
Stream stream=javaProgrammers.stream();
//1.2 通过集合创建Stream流------> default Stream parallelStream:返回一个并行流
Stream parallelStream = javaProgrammers.parallelStream();
我们通过集合javaProgrammers创建了 Stream 流,那么为什么会返回一个流呢? 我们看Collection集合类的源码:
//1.1 当集合集合调用stream()时,return一个Stream
default Stream stream() {
return StreamSupport.stream(spliterator(), false);
}
//1.2 同理
default Stream parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
通过数组创建 Stream 流
//2.1 通过数组创建Stream流-------> 调用Arrays类的static Stream Stream<T[] array> :返回一个流
Person[] arrPerson = new Person[]{javaProgrammers.get(0),javaProgrammers.get(1)};
Stream streamObj = Arrays.stream(arrPerson);
通过静态类Arrays调用 Stream 中的静态Stream方法,即可返回一个流。 静态 Stream 方法源码:
//入参Array数组,返参 Stream流
public static Stream stream(T[] array) {
return stream(array, 0, array.length);
}
public static Stream stream(T[] array, int startInclusive, int endExclusive) {
return StreamSupport.stream(spliterator(array, startInclusive, endExclusive), false);
}
通过 Stream 的 of 方法创建流
//3.1 通过of创建Stream
Stream streamOf = Stream.of(1, 2, 3, 4, 5, 6);Stream<Person> streamOfs = Stream.of(javaProgrammers.get(0),javaProgrammers.get(1));
of 方法源码:
@SafeVarargs
@SuppressWarnings(“varargs”) // Creating a stream from an array is safe
public static Stream of(T… values) {
//通过of源码我们可以看到,其实of方法任然是使用的是数组的创建的方式,只是外部有包了一层
return Arrays.stream(values);
}
通过无线流的创建 Stream 流
//4.1 通过无限流的方式创建Stream流
/*4.1.1 迭代—>*public static Stream iterate(final T seed,final UnaruOperator f)
* 遍历前10个偶数
* 无限流,无限反复操作使用,所有一般都会配合limit使用
*/
Stream.iterate(0,t->t+2).limit(10).forEach(System.out::println); //seed是起始数值,limit代表循环前10次
//4.1.2 生成----》public static<T> Stream<T> generate(Supplier<T> s)Stream.generate(Math::random).limit(10).forEach(System.out::println);
小结
(1)Java8 中的 Collection 接口被扩展,提供了 两个获取流的方法:
default Streamstream() : 返回一个顺序流 default StreamparallelStream() : 返回一个并行流
(2)Java8 中的 Arrays 的静态方法 stream() 可 以获取数组流:
staticStreamstream(T[] array): 返回一个流
重载形式,能够处理对应基本类型的数组:
public static IntStream stream(int[] array) public static LongStream stream(long[] array) public static DoubleStream stream(double[] array)
(3)可以使用静态方法 Stream.of(), 通过显示值 创建一个流。它可以接收任意数量的参数。
public staticStreamof(T… values) : 返回一个流
可以使用静态方法 Stream.iterate() 和 Stream.generate(), 创建无限流。 1.** 迭代**
public staticStreamiterate(final T seed, final UnaryOperatorf)
2.生成
public staticStreamgenerate(Suppliers)
Stream 流的中间操作
中间操作有:
-
筛选和切片
⚪filter(Predicate p)–接受 Lambda,从流中排除某些元素
⚪limit(n)–截断流,使其元素不超过给定数量
⚪skip(n)–跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n)互补
⚪distinct–筛选,通过流所生成的元素的 hashCode() 和 equals() 去除重复元素 -
映射
⚪map(Function f)–接受一个函数作为参数,将元素转换成其他形式或提取信息,该函数会被应用到每个元素上,并将其映射成一个新的元素。
⚪flatMap(Function f)–接受一个函数作为参数,将流中的每个值都转换成另一个流,然后把所有流连成一个流 -
** 排序**
⚪sorted()–自然排序,产生一个新流,其中按自然顺序排序
⚪sorted(Comparator com)–定制排序,产生一个新流,其中按比较器顺序排序
下面我们通过代码实现来分析这些方法:
筛选和切片
filter()方法
Filter接受一个predicate接口类型(断言型函数式接口)的变量,并将所有流对象中的元素进行过滤。该操作是一个中间操作,因此它允许我们在返回结果的基础上再进行其他的流操作(比如:forEach)。ForEach 接受一个 function 接口类型的变量,用来执行对每一个元素的操作。ForEach是一个中止操作。它不返回流,所以我们不能再调用其他的流操作。
@Test
public void testFilter() {
//1.1filter(Predicate p)–接受Lambda,从流中排除某些元素
//1.1.1 原生方式 所有的中间操作不会做任何的处理
Stream stream = javaProgrammers.stream()
.filter((e) -> {
System.out.println(“测试中间操作”);
return e.getAge() < 20;
});
stream.forEach(System.out::println);//只有当做终止操作时,所有的中间操作会一次性的全部执行,称为“惰性求值”//1.1.2 使用lambdas表达式优化 javaProgrammers.stream().filter(e->{System.out.println("测试中间操作");return e.getAge() <20; }).forEach(System.out::println);}
Limit(N)和 Skip(N)方法
@Test
public void testLimitAndSkip() {
// 1.2limit(n)–截断流,使其元素不超过给定数量 类似于mysql中的limit,但这里只有最大值
//1.3skip(n)–跳过元素,返回一个扔掉了前n个元素的流。若流中元素不足n个,则返回一个空流。与limit(n)互补
//通过无限流创建一个无限流,如果不使用Limit方法进行限制阶段,无限流将会形成一个类似于死循环的操作
//当使用skip()将会跳过前5个数据从第6个参数返回
Stream.iterate(0,t->t+1).limit(10).skip(5).forEach(System.out::println); //seed是起始数值,limit代表循环前10次
}
distinct()方法*
distinct()返回由该流的不同元素组成的流。distinct()是 Stream 接口的方法。distinct()使用hashCode()和equals()方法来获取不同的元素。我们的类必须实现 hashCode()和 equals()。如果 distinct()正在处理有序流,那么对于重复元素,将保留以遭遇顺序首先出现的元素,并且以这种方式选择不同元素是稳定的。在无序流的情况下,不同元素的选择不一定是稳定的,是可以改变的。distinct()执行有状态的中间操作。在有序流的并行流的情况下,保持 distinct()的稳定性是需要很高的代价的,因为它需要大量的缓冲开销。如果我们不需要保持遭遇顺序的一致性,那么我们应该可以使用通过 BaseStream.unordered()方法实现的无序流。
distinct 对集合中的对象进行去重
//1.4distinct–筛选,通过流所生成的元素的 hashCode() 和 equals() 去除重复元素//1.4.1 distinct取出集合中对象信息完全重复的对象 javaProgrammers.stream().distinct().forEach(System.out::println);
打印结果(对集合后三条重复的数据进行了去重操作):
Person(firstName=Elsdon, lastName=Jaycob, job=Java programmer, gender=male, salary=2000, age=18)
Person(firstName=Tamsen, lastName=Brittany, job=Java programmer, gender=female, salary=2371, age=55)
Person(firstName=Floyd, lastName=Donny, job=Java programmer, gender=male, salary=3322, age=25)
Person(firstName=Sindy, lastName=Jonie, job=Java programmer, gender=female, salary=3502, age=15)
Person(firstName=Vere, lastName=Hervey, job=Java programmer, gender=male, salary=2272, age=25)
Person(firstName=Maude, lastName=Jaimie, job=Java programmer, gender=female, salary=2057, age=87)
Person(firstName=Shawn, lastName=Randall, job=Java programmer, gender=male, salary=3120, age=99)
Person(firstName=Jayden, lastName=Corrina, job=Java programmer, gender=female, salary=345, age=25)
Person(firstName=Palmer, lastName=Dene, job=Java programmer, gender=male, salary=3375, age=14)
Person(firstName=Addison, lastName=Pam, job=Java programmer, gender=female, salary=3422, age=20)
distinct 对集合中对象的某一属性进行去重
distinct()不提供按照属性对对象列表进行去重的直接实现。它是基于 hashCode()和 equals()工作的。如果我们想要按照对象的属性,对对象列表进行去重,我们可以通过其它方法来实现。如下代码段所示:
static Predicate distinctByKey(Function<? super T, ?> keyExtractor) {
Map<Object,Boolean> seen = new ConcurrentHashMap<>();
return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null;
}
上面的方法可以被 Stream 接口的 filter()接收为参数,如下所示:
//1.4.2 distinct对集合中对象的某一属性进行去重
javaProgrammers.stream().filter(distinctByKey(e->e.getAge())).distinct().forEach(System.out::println);
distinctByKey()方法返回一个使用 ConcurrentHashMap 来维护先前所见状态的 Predicate 实例,如下是一个完整的使用对象属性来进行去重的示例。 打印结果(以去除年龄相同的人的信息):
Person(firstName=Elsdon, lastName=Jaycob, job=Java programmer, gender=male, salary=2000, age=18)
Person(firstName=Tamsen, lastName=Brittany, job=Java programmer, gender=female, salary=2371, age=55)
Person(firstName=Floyd, lastName=Donny, job=Java programmer, gender=male, salary=3322, age=25)
Person(firstName=Sindy, lastName=Jonie, job=Java programmer, gender=female, salary=3502, age=15)
Person(firstName=Maude, lastName=Jaimie, job=Java programmer, gender=female, salary=2057, age=87)
Person(firstName=Shawn, lastName=Randall, job=Java programmer, gender=male, salary=3120, age=99)
Person(firstName=Palmer, lastName=Dene, job=Java programmer, gender=male, salary=3375, age=14)
Person(firstName=Addison, lastName=Pam, job=Java programmer, gender=female, salary=3422, age=20)
映射
这个类似于 list 集合中的 add 和 addAll 的区别,add 添加一个集合是把集合当成一个元素,addAll 添加一个集合是把集合中的每个元素当成一个元素
map(Function f)和 flatMap(Function f)方法
map 相当于 add,flatMap 相当于 addAll
@Test
public void testMapAndFlatMap(){
/*2.1 map(Function f)–接受一个函数作为参数,将元素转换成其他形式或提取信息,该函数会被应用到每个元素上,并将其映射成一个新的元素。
*
* 这个类似于list集合中的add和addAll的区别,add添加一个集合是把集合当成一个元素,addAll添加一个集合是把集合中的每个元素当成一个元素
* map相当于add,flatMap相当于addAll
*/
//map(Function f)--接受一个函数作为参数,将元素转换成其他形式或提取信息,该函数会被应用到每个元素上,并将其映射成一个新的元素。List<String> list = Arrays.asList("测试", "bb", "cc", "dd","dsf","dsf");list.stream().map(s -> s.toUpperCase()).forEach(System.out::println);//练习2.1.1 获取集合中年龄大于20的人javaProgrammers.stream().map(Person::getAge).filter(e->e>20).forEach(System.out::println);//练习2.1.2 将字符串中的多个字符构成的集合转换为对应的Stream的实例Stream<Stream<Character>> streamStream = list.stream().map(SteamApiTest::fromStringToStream);//有点麻烦streamStream.forEach(s->s.forEach(System.out::println));// 2.2 `flatMap(Function f)`–接受一个函数作为参数,将流中的每个值都转换成另一个流,然后把所有流连成一个流Stream<Character> characterStream = list.stream().flatMap(SteamApiTest::fromStringToStream);characterStream.forEach(System.out::println);javaProgrammers.stream().flatMap(e->Stream.of(e).filter(x->x.getAge()>20)).forEach(System.out::println);}//将字符串中的多个字符构成的集合转换为对应的Stream的实例
public static Stream<Character> fromStringToStream(String str){ArrayList<Character> list = new ArrayList<>();for (Character c:str.toCharArray()){list.add(c);}return list.stream();
}
排序
自然排序的对象是需要实现 Comparable 接口的
sorted()方法
@Test
public void testStore(){
//3.1 sorted()–自然排序,产生一个新流,其中按自然顺序排序 sorted()参数可选,有两个重载一个有参Comparator,一个无参
List<Integer> list = Arrays.asList(12, 43, 65, 3, 4, 0,01, -98);list.stream().sorted().forEach(System.out::println);//3.1.1 抛异常,原因:Person没有实现Comparable接口//javaProgrammers.stream().sorted().forEach(System.out::println);//3.2 sorted(Comparator com)–定制排序,产生一个新流,其中按比较器顺序排序,根据条件排序//多集合中对象根据年龄进行排序javaProgrammers.stream().sorted((e1,e2)->Integer.compare(e1.getAge(),e2.getAge())).forEach(System.out::println);}
Stream 的终止操作(常用方法)
终止操作有:
-
匹配与查找
⚪allMatch(Predicate p):检查是否匹配所有元素
⚪anyMatch(Predicate p):检查是否至少匹配一个元素
⚪noneMatch(Predicate p):检查是否没有匹配的元素
⚪findFirst():返回第一个元素
⚪findAny():返回当前流中的任意元素
⚪count():返回流中元素的总数
⚪max(Comparator c):返回流中最大值
⚪min(Comparator c):返回流中最小值
⚪forEach(Consumer c):内部迭代 -
规约
⚪reduce(T identity,BinaryOperator accumulator):可以将流中元素反复结合起来,得到一个值。返回 T
⚪reduce(BinaryOperator accumulator):可以将流中元素反复结合起来,得到一个值。返回 Optional -
收集
⚪collect(Collector c):将流转换成其他形式。接受一个 Collector 接口的实现,用于给 Stream 中元素做汇总的方法
匹配与查找
方法都比较简单易于理解。
@Test
public void testMatchAndFind() {
/**
* 1. 匹配与查找
* allMatch(Predicate p):检查是否匹配所有元素
* anyMatch(Predicate p):检查是否至少匹配一个元素
* noneMatch(Predicate p):检查是否没有匹配的元素
* findFirst():返回第一个元素
* findAny():返回当前流中的任意元素
* count():返回流中元素的总数
* max(Comparator c):返回流中最大值
* min(Comparator c):返回流中最小值
* forEach(Consumer c):内部迭代
**///1.1 allMatch()相当于制定一个规则,将集合中的对象一一与规则进行对象,判断是否所有的集合对象都符合该规则, true/false boolean allMatch = javaProgrammers.stream().allMatch(e -> e.getAge()>18); System.out.println("测试Stream流的终止操作----allMatch()--->"+allMatch);//1.2 anyMatch(Predicate p):检查是否至少匹配一个元素 类似于多选一即可 boolean anyMatch = javaProgrammers.stream().anyMatch(e -> e.getSalary()>1000); System.out.println("检查是否至少匹配一个元素----anyMatch()--->"+anyMatch);//1.3 noneMatch(Predicate p):检查是否没有匹配的元素 没有返回true,反之false boolean noneMatch = javaProgrammers.stream().noneMatch(e -> e.getSalary() > 10000); System.out.println("检查是否没有匹配的元素----noneMatch()--->"+noneMatch);//1.4 findFirst():返回第一个元素 Person person = javaProgrammers.stream().findFirst().get(); System.out.println("返回第一个元素----findFirst()--->"+person.toString());for (int i = 0; i <1000 ; i++) {//1.5 findAny():返回当前流中的任意元素Optional<Person> AnyPerson = javaProgrammers.stream().findAny();//System.out.println("返回当前流中的任意元素----findAny()--->"+AnyPerson.toString()+"--------->"+i); }//1.6 count():返回流中元素的总数 long count = javaProgrammers.stream().count(); System.out.println("返回流中元素的总数----count()--->"+count);//1.7 max(Comparator c):返回流中最大值 Optional<T> max(Comparator<? super T> comparator); Person maxPersonSalary = javaProgrammers.stream().max(Comparator.comparing(Person::getSalary)).get(); System.out.println("返回流中最大值----max()--->"+maxPersonSalary);//1.8 min(Comparator c):返回流中最小值 Person minPersonSalary = javaProgrammers.stream().min(Comparator.comparing(Person::getSalary)).get(); System.out.println("返回流中最小值----max()--->"+minPersonSalary);}
打印结果:
测试Stream流的终止操作----allMatch()—>false
检查是否至少匹配一个元素----anyMatch()—>true
检查是否没有匹配的元素----noneMatch()—>false
返回第一个元素----findFirst()—>Person(firstName=Elsdon, lastName=Jaycob, job=Java programmer, gender=male, salary=2000, age=18)
返回流中元素的总数----count()—>12
返回流中最大值----max()—>Person(firstName=Sindy, lastName=Jonie, job=Java programmer, gender=female, salary=35020, age=15)
返回流中最小值----max()—>Person(firstName=Jayden, lastName=Corrina, job=Java programmer, gender=female, salary=345, age=25)
规约
@Test
public void testStatute(){
/*
* 2. 规约
* reduce(T identity,BinaryOperator accumulator):可以将流中元素反复结合起来,得到一个值。返回T
* reduce(BinaryOperator accumulator):可以将流中元素反复结合起来,得到一个值。返回Optional
*
* reduce()这个方法经常用到很方便,也更总要,我会再详细的分析总结,这里只做简单认识即可。
*///2.1 reduce(T identity,BinaryOperator accumulator):可以将流中元素反复结合起来,得到一个值。返回T //2.1.1 练习1:计算1-10的自然数的和 List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); Integer sum = list.stream().reduce(0, Integer::sum); System.out.println("计算1-10的自然数的和-------reduce(T identity,BinaryOperator accumulator)------>"+sum);//2.2 reduce(BinaryOperator accumulator):可以将流中元素反复结合起来,得到一个值。返回Optional Integer integers = javaProgrammers.stream().map(Person::getSalary).reduce((e1, e2) -> e1 + e2).get();//lambda表达式 Integer integer = javaProgrammers.stream().map(Person::getSalary).reduce(Integer::sum).get();//使用引用 System.out.println("工资和-------reduce(BinaryOperator accumulator)使用引用------>"+integer); System.out.println("工资和-------reduce(BinaryOperator accumulator)lambda表达式------>"+integers);}
打印结果:
计算1-10的自然数的和-------reduce(T identity,BinaryOperator accumulator)------>55
工资和-------reduce(BinaryOperator accumulator)使用引用------>64148
工资和-------reduce(BinaryOperator accumulator)lambda表达式------>64148
收集
Collector接口中方法的实现决定了如何对流执行收集的操作(如收集到List、Set、Map)Collector需要使用Collectors提供实例。
@Test
public void testSalary(){
/*
* 3. 收集
* collect(Collector c):将流转换成其他形式。接受一个Collector接口的实现,用于给Stream中元素做汇总的方法
* Collector接口中方法的实现决定了如何对流执行收集的操作(如收集到List、Set、Map)。
* Collector需要使用Collectors提供实例。另外, Collectors实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下:
⚪toList:返回类型List< T>,作用是把流中元素收集到List
⚪toSet:返回类型Set< T>,作用是把流中元素收集到Set
⚪toCollection:返回类型Collection< T>,作用是把流中元素收集到创建的集合
*
*///3.1 collect(Collector c):将流转换成其他形式。返回一个set System.out.println("将流转换成其他形式。返回一个set-------toSet()------>:"); javaProgrammers.stream().filter(e -> e.getSalary() > 3000).collect(Collectors.toSet()).forEach(System.out::println);//3.2 collect(Collector c):将流转换成其他形式。返回一个list System.out.println("将流转换成其他形式。返回一个list-------toList()------>:"); javaProgrammers.stream().filter(e -> e.getSalary() > 3000).limit(2).collect(Collectors.toList()).forEach(System.out::println);//3.2 collect(Collector c):将流转换成其他形式。返回一个map System.out.println("将流转换成其他形式。返回一个map-------toMap()------>:"); javaProgrammers.stream().filter(e -> !e.getFirstName().equals("测试"))// 注意:key不能重复 toMap()参数一:key 参数二:value 参数三:对key值进行去重,当有重复的key,map中保留第一条重复数据.collect(Collectors.toMap(Person::getAge,person -> person,(key1, key2) -> key1)) //value 为对象 student -> student jdk1.8返回当前对象,也可以为对象的属性.forEach((key, value) -> System.out.println("key--"+key+" value--"+value.toString()));}
结束语
完毕!搞明白,读懂,敲会,致此对 Stream 流也算是有了初步的认识。接下来就慢慢的挖掘吧,打工人。
推荐参考博客:
https://blog.csdn.net/hhq12/article/details/81169145 https://blog.csdn.net/weixin_46744534/article/details/108039064
参考文献链接
https://mp.weixin.qq.com/s/UW4Z0vu_Wypc0ddymrOkpg
https://mp.weixin.qq.com/s/RfsTTNekpJeIX5DH4ViAqg
https://mp.weixin.qq.com/s/smj5bsqXgKuz7RvoLqFKjg
https://mp.weixin.qq.com/s/p5gB7q03YfhN-0N7LvQ43g