python爬取电影天堂dytt8的下载链接
- 电影天堂下载链接都是magnet的,搞下来想下就下没有广告
- 建一个main.py
- 一个一个挨着去爬肯定慢啊,建一个多线程的去爬 mui.py
- 多线程有可能会发生WinError 10060报错,使用time.sleep(1)避免
电影天堂下载链接都是magnet的,搞下来想下就下没有广告
建一个main.py
# coding=utf-8
import urllib.request
#import requests
import re
import random
import json#爬取电影天堂电影下载链接
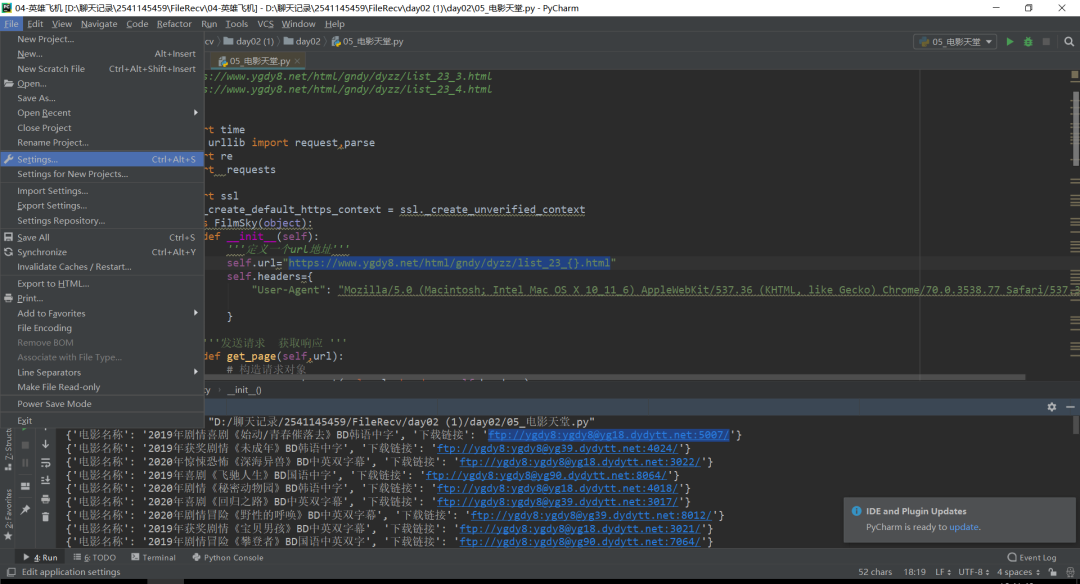
def get_film(url):#设定模拟浏览器抬头ua_list = ["Mozilla/5.0 (Windows NT 6.1; ) Apple.... ","Mozilla/5.0 (X11; CrOS i686 2268.111.0)... ","Mozilla/5.0 (Macintosh; U; PPC Mac OS X.... ","Mozilla/5.0 (Macintosh; Intel Mac OS... "]user_agent = random.choice(ua_list)#构建请求myRequest = urllib.request.Request(url)#也可以通过调用Request.add_header() 添加/修改一个特定的headermyRequest.add_header("Connection", "keep-alive")#也可以通过调用Request.add_header() 添加/修改一个特定的headermyRequest.add_header("User-Agent", user_agent)#第一个字母大写,后面的全部小写myRequest.get_header("User-agent")#请求响应response = urllib.request.urlopen(myRequest)#读取并转码为GBK的字符串try:encodeHtml = response.read()#使用"ignore"忽略错误html = encodeHtml.decode("GB18030","ignore")detail_list=re.findall('<a href="(.*?)" class="ulink',html) for m in detail_list:b_url = 'http://www.dytt8.net/%s'%m#html_2=requests.get(b_url)#构建请求request2 = urllib.request.Request(b_url)#也可以通过调用Request.add_header() 添加/修改一个特定的headerrequest2.add_header("Connection", "keep-alive")#也可以通过调用Request.add_header() 添加/修改一个特定的headerrequest2.add_header("User-Agent", user_agent)#第一个字母大写,后面的全部小写request2.get_header("User-agent")#请求响应response2 = urllib.request.urlopen(request2)#html_2 = response2.read().decode("GBK") 这个可能报错 用下面的html_2 = response2.read().decode("GB18030","ignore")#print(html_2)#新建一个字典movieInfo = {'name':'','ftp':'','magnet':'','info':'','originalName':'','grade':''}ftp = re.findall('<a href="(.*?)">ftp.*?</a></td>',html_2)if ftp != []:#print (ftp[0])movieInfo['ftp']=ftp[0]name = re.findall('com.*?.m',ftp[0])if name != []:#print ('电影名称:'+name[0].split('.')[1])movieInfo['name']=name[0].split('.')[1]magnet = re.findall('<a href="magnet:(.*?)"><strong><font style="BACKGROUND-COLOR: #ff9966"><font color="#0000ff"><font size="4">磁力链下载点击这里</font></font></font></strong></a>',html_2)if magnet != []:#print (magnet[0])movieInfo['magnet']='magnet:'+magnet[0]Info = re.findall(' /> <br /><br />.*?<br /><br /><img',html_2)if Info != []:tmpInfo = Info[0].split('/>',1)[1].split('<img',1)[0]#print (tmpInfo)movieInfo['info']= tmpInfo#原始片名originalNameList = re.findall('◎片 名.*?<br />',tmpInfo)if originalNameList !=[]:movieInfo['originalName'] = originalNameList[0].split('◎片 名',1)[1].split('<br />',1)[0]#IMDb评分 满分10分 这里截取我写的差 还是大家自己去匹配把gradeList = re.findall('◎IMDb评分.*?<br />',tmpInfo)if gradeList !=[]:#print (gradeList[0].split('/',1)[0])if len(gradeList[0].split('/',1)[0].split(' ',1))>1:#print (gradeList[0].split('/',1)[0].split(' ',1)[1])movieInfo['grade'] = gradeList[0].split('/',1)[0].split(' ',1)[1]if len(gradeList[0].split('/',1)[0].split(' ',1))>1:#print (gradeList[0].split('/',1)[0].split(' ',1)[1])movieInfo['grade'] = gradeList[0].split('/',1)[0].split(' ',1)[1]for key in movieInfo:print (key, ' value : ', movieInfo[key])'''#将数据保存到本地 #jsonStr = json.dumps(movieInfo)#print (jsonStr)with open('d:\movieList.txt','a',encoding='utf-8') as f:#写文本write到本地f.write(jsonStr+',')'''#发送到java服务器postDaa = urllib.parse.urlencode(movieInfo).encode('utf-8')header_dict = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko'}#我的地址就不贴了url3='https://www.xxx.xxxPython.json'req3 = urllib.request.Request(url=url3,data=postDaa,headers=header_dict,method = 'POST')res3 = urllib.request.urlopen(req3)res3 = res3.read()print(res3)#print(res3.decode(encoding='utf-8'))except Exception as e:print('发生了异常:',e)'''
这里是单线程的
for n in range(1,110):#goUrl = 'http://www.dytt8.net/html/gndy/dyzz/list_23_'+str(n)+'.html'goUrl = 'http://www.dytt8.net/html/gndy/china/list_4_'+str(n)+'.html'print(goUrl)get_film(goUrl)
''' 一个一个挨着去爬肯定慢啊,建一个多线程的去爬 mui.py
这个是参照了 AutomationTesting的博客内容,很多字段我也没改。
# -*-coding:utf-8-*-
import threading;
import main;
mutex_lock = threading.RLock(); # 互斥锁的声明
ticket = 180; # 总页码
start = 1; # 起始页码
# 用于统计各个线程的得票数
ticket_stastics=[];class myThread(threading.Thread): # 线程处理函数def __init__(self, name): threading.Thread.__init__(self); # 线程类必须的初始化self.thread_name = name; # 将传递过来的name构造到类中的namedef run(self):# 声明在类中使用全局变量global mutex_lock;global ticket; global start; while 1: if ticket > start: start += 1;goUrl = 'http://www.dytt8.net/html/gndy/dyzz/list_23_'+str(start)+'.html'print (goUrl)#调用你写的那个类main.get_film(goUrl) ticket_stastics[self.thread_name]+=1; else: break;mutex_lock.release(); # python在线程死亡的时候,不会清理已存在在线程函数的互斥锁,必须程序猿自己主动清理print ("%s被销毁了!" % (self.thread_name)); # 初始化线程
threads = [];#存放线程的数组,相当于线程池
for i in range(0,50):#线程数量,电脑好可以多设点2333thread = myThread(i);#指定线程i的执行函数为myThreadthreads.append(thread);#先讲这个线程放到线程threadsticket_stastics.append(0);# 初始化线程的得票数统计数组
for t in threads:#让线程池中的所有数组开始t.start();
for t in threads:t.join();#等待所有线程运行完毕才执行一下的代码
print ("录入完毕!");
print ("=========统计=========");
for i in range(0,len(ticket_stastics)):print ("线程%d:%d页" % (i,ticket_stastics[i]));
这两个运行一下就可以爬了;平常替换下goUrl就可以了~
多线程有可能会发生WinError 10060报错,使用time.sleep(1)避免
发生了异常: <urlopen error [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。>
这是由于连接数太多被对方防火墙ban了… 发生这类错误就暂停一下再继续应该就好了,估计是防DDoS攻击?