本节将介绍如何使用perf工具的perf record对C++代码进行性能分析,一切操作都是在ubuntu 20下进行。
perf工具安装
由于perf工具和内核版本有关,因此直接安装容易出错,建议直接通过如下指令安装:
sudo apt-get install linux-tools-common linux-tools-generic linux-tools-`uname -r`C++程序解析实例
首先,给出需要解析的C++代码testPerf.cpp :
#include <iostream>
using namespace std;
void delay()
{ int i,j; for(i = 0; i < 1000000; i++) j=i;//std::cout << " j is " << j << std::endl;
} void test1()
{ int i; for(i=0 ; i < 20; i++) delay();
} void test2()
{ int i; for(i = 0; i< 50; i++) delay();
} int main(void)
{ std::cout << "begin: " << std::endl;test1(); test2(); std::cout << "finish!" << std::endl;
}编译生成可执行程序:
g++ testPerf.cpp -o testPerf分析1
执行指令:
sudo perf record ./testPerf结果如下:

目录下会生成perf.data文件:
![]()
输入perf report 查看分析结果:
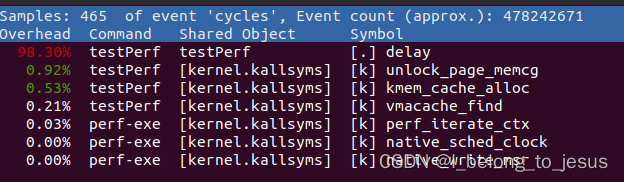
分析2
sudo perf record -g ./testPerf-g表示在用户空间和内核空间使能call-graph。
重新执行之后,我们来看一下效果图:

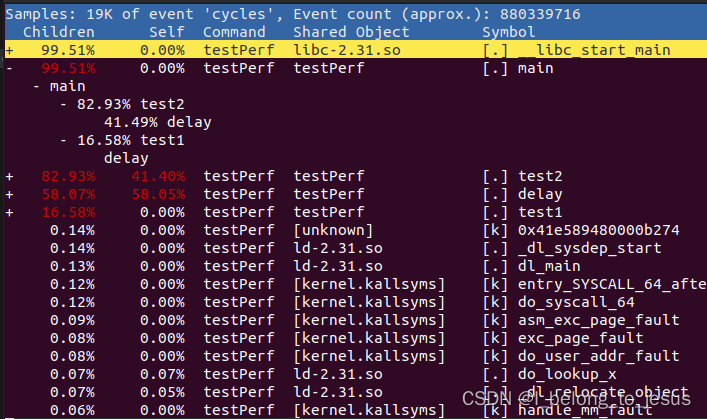
可以看到,Children列表示当前这个函数的CPU占用,Self函数表示这个函数本身的CPU占用(不包含其调用的函数),显然可以看到delay的调用占用了大部分CPU资源,进一步通过回车选择某个函数,选择:
可以找到整个函数的堆栈调用关系,一直向下扩展,如图所示:

可以看到test2和test1的耗时接近5:2,这是一个合理的结果,并且可以看的很清楚耗时到底在哪里。
分析3
为了进一步简化可以只考虑用户空间的call-graph:
perf record -F max --call-graph fp -- ./testPerf结果是类似的。
分析4
为了进一步说明情况,我们修改代码:
#include <iostream>
using namespace std;
void delay()
{ int i,j; for(i = 0; i < 1000000; i++) j=i;//std::cout << " j is " << j << std::endl;
} void test1()
{ int i; for(i=0 ; i < 20; i++) delay();
} void test2()
{ int i,k;for(i = 0; i< 50000000; i++)k = i;for(i = 0; i< 50; i++) delay();
} int main(void)
{ std::cout << "begin: " << std::endl;test1(); test2(); std::cout << "finish!" << std::endl;
}分析效果图如下:
可以看到,由于test2内部增加延时,其self消耗cpu不再是0,还是对应的比例。



![P3029 [USACO11NOV]Cow Lineup S 双指针 单调队列](https://img-blog.csdnimg.cn/6af1894944f542299edaa735404b58a3.png)