数据库中间件监控实战,MySQL中哪些指标比较关键以及如何采集这些指标了。帮助提早发现问题,提升数据库可用性。
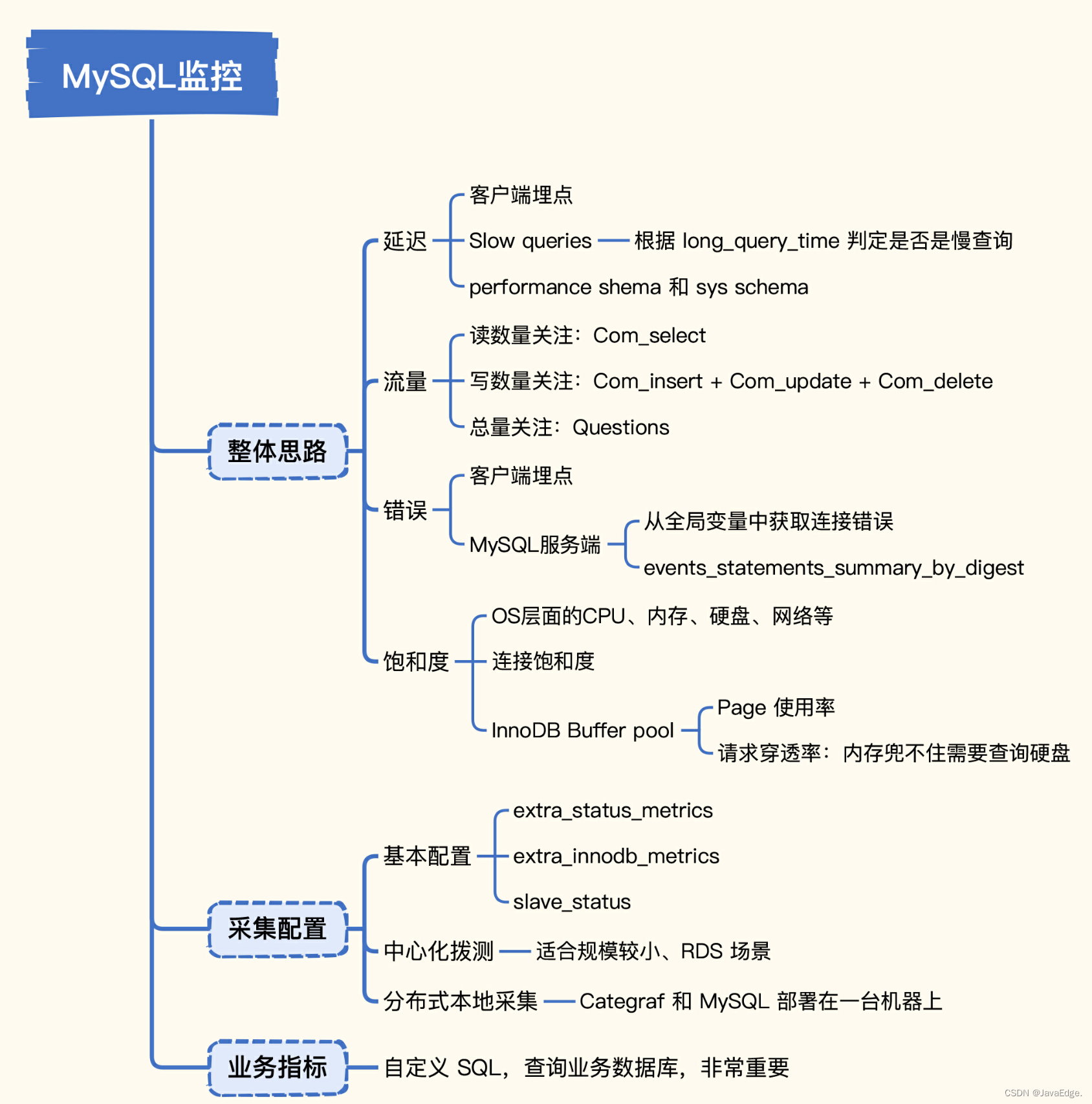
1 整体思路
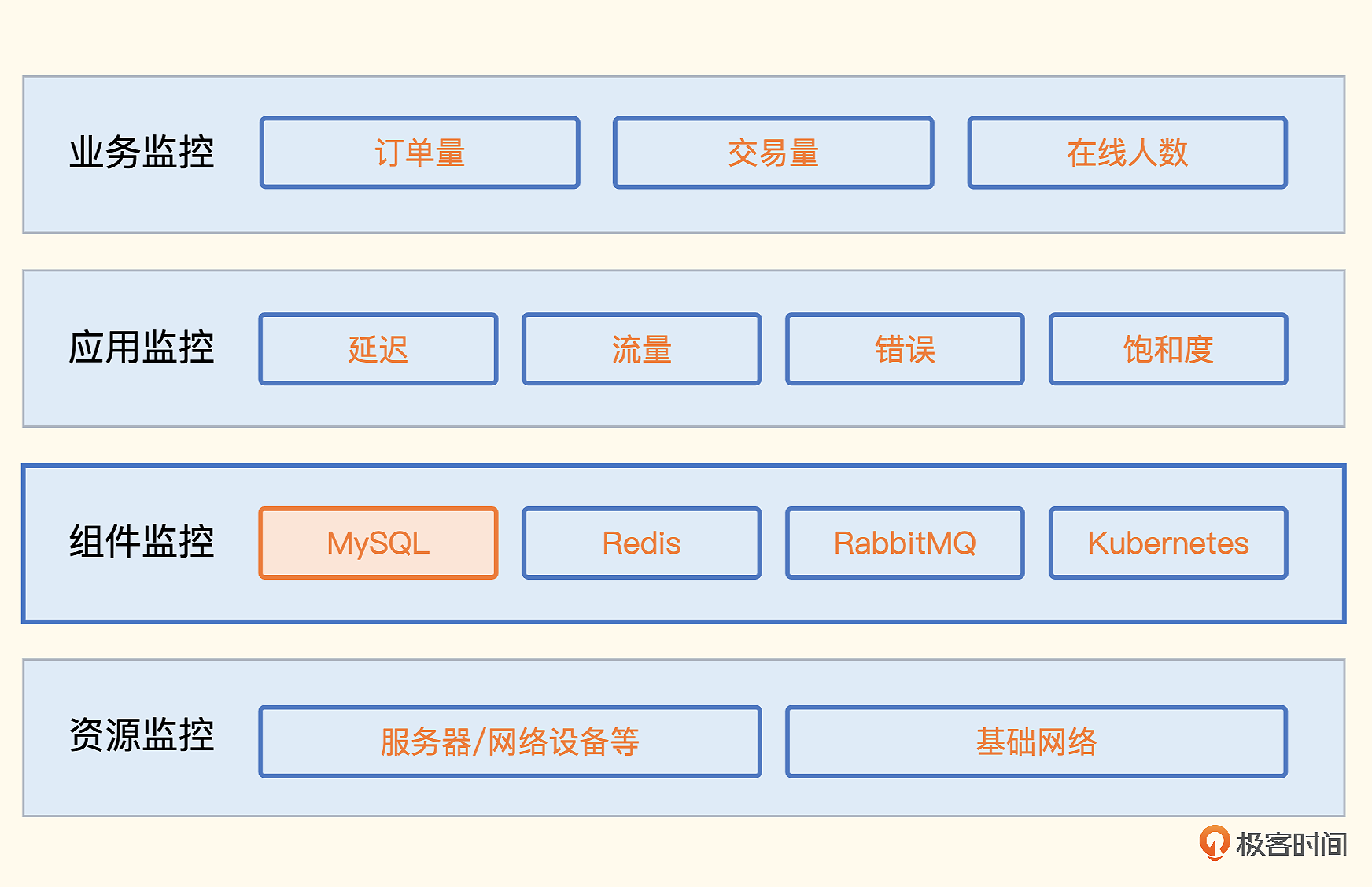
监控哪类指标?
如何采集数据?
第10讲监控方法论如何落地?
这些就可以在MySQL中应用起来。MySQL是个服务,所以可借用Google四个黄金指标解决问题:
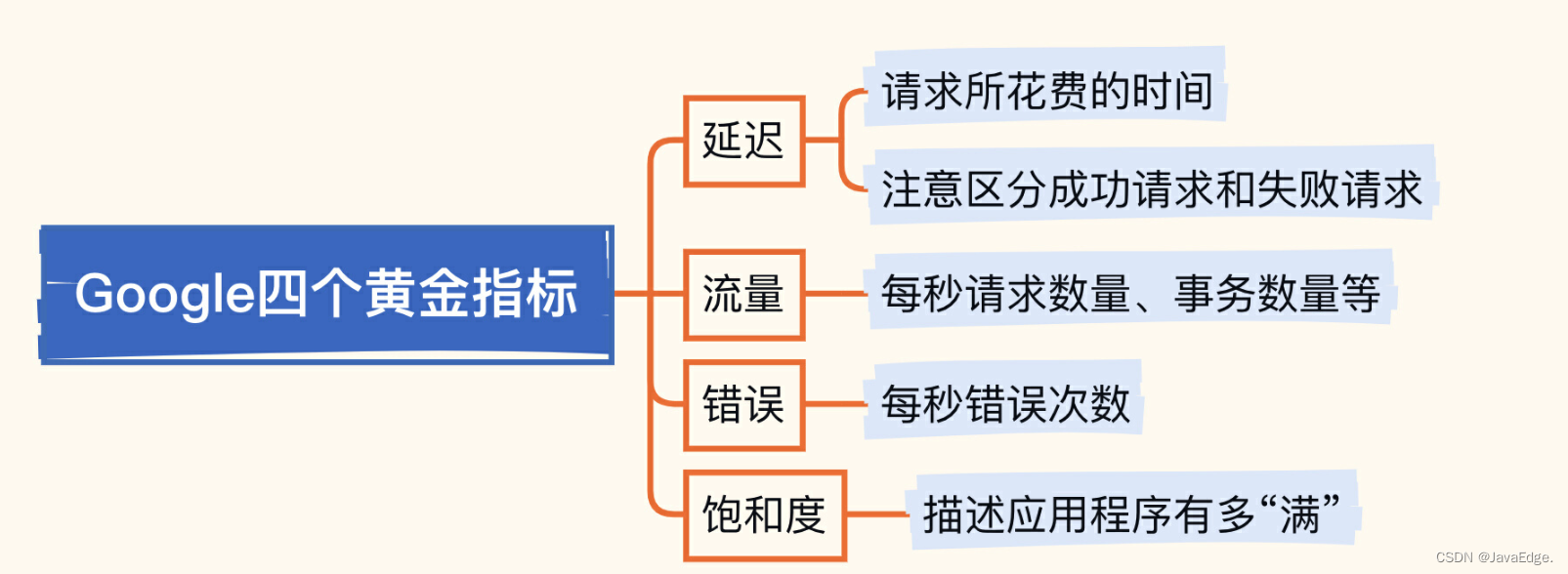
1.1 延迟
应用程序会向MySQL发起SELECT、UPDATE等操作,处理这些请求花费多久很关键,甚至还想知道具体是哪个SQL最慢,这样就可以有针对性地调优。
1.1.1 采集延迟数据
在客户端埋点
上层业务程序在请求MySQL的时候,记录每个SQL请求耗时,把这些数据统一推给监控系统,监控系统就可以计算出平均延迟、95分位、99分位的延迟数据了。要埋点,对业务代码有侵入性。
Slow queries
MySQL提供慢查询数量的统计指标,通过如下命令拿到:
show global status like 'Slow_queries';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Slow_queries | 107 |
+---------------+-------+
1 row in set (0.000 sec)
这指标是Counter型,即单调递增,若想知道最近1min有多少慢查询,需要使用increase函数做二次计算。
慢查询标准
全局变量long_query_time,默认10s,可调整。每当查询时间超过 long_query_time 指定时间,Slow_queries 就会 +1。
获取 long_query_time 值:
SHOW VARIABLES LIKE 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
通过 performance schema、sys schema 拿到统计数据。若performance schema的 events_statements_summary_by_digest 表,该表捕获很多关键信息,如延迟、错误量、查询量。
如下案例,SQL执行2次,平均执行时间325ms,表里的时间度量指标都是以皮秒为单位:
*************************** 1. row ***************************SCHEMA_NAME: employeesDIGEST: 0c6318da9de53353a3a1bacea70b4fceDIGEST_TEXT: SELECT * FROM `employees` WHERE `emp_no` > ?COUNT_STAR: 2SUM_TIMER_WAIT: 650358383000MIN_TIMER_WAIT: 292045159000AVG_TIMER_WAIT: 325179191000MAX_TIMER_WAIT: 358313224000SUM_LOCK_TIME: 520000000SUM_ERRORS: 0SUM_WARNINGS: 0SUM_ROWS_AFFECTED: 0SUM_ROWS_SENT: 520048SUM_ROWS_EXAMINED: 520048
...SUM_NO_INDEX_USED: 0SUM_NO_GOOD_INDEX_USED: 0FIRST_SEEN: 2016-03-24 14:25:32LAST_SEEN: 2016-03-24 14:25:55
针对即时查询、诊断问题,还可使用 sys schema。sys schema提供一种组织良好、易读的指标查询方式,查询更简单。如下方法找到最慢的SQL。这个数据在 statements_with_runtimes_in_95th_percentile 表中。
SELECT * FROM sys.statements_with_runtimes_in_95th_percentile;
更多例子查看 sys schema 文档。不过要注意的是,MySQL 5.7.7开始才包含sys schema,5.6 版本开始可手工安装。
1.2 流量
最熟的就是统计 SELECT、UPDATE、DELETE、INSERT 等语句执行数量。若流量太高,超过硬件承载能力,显然需监控、扩容。这些类型指标在 MySQL 全局变量中都能拿到:
show global status where Variable_name regexp 'Com_insert|Com_update|Com_delete|Com_select|Questions|Queries';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| Com_delete | 2091033 |
| Com_delete_multi | 0 |
| Com_insert | 8837007 |
| Com_insert_select | 0 |
| Com_select | 226099709 |
| Com_update | 24218879 |
| Com_update_multi | 0 |
| Empty_queries | 25455182 |
| Qcache_queries_in_cache | 0 |
| Queries | 704921835 |
| Questions | 461095549 |
| Slow_queries | 107 |
+-------------------------+-----------+
这些指标都是 Counter 型。Com_ 是 Command 的前缀,即各类命令的执行次数。 整体吞吐量主要是看 Questions 指标,但Questions 很容易和它上面的Queries混淆。从例子里我们可以明显看出 Questions 的数量比 Queries 少。Questions 表示客户端发给 MySQL 的语句数量,而Queries还会包含在存储过程中执行的语句,以及 PREPARE 这种准备语句,所以监控整体吞吐一般是看 Questions。
流量方面的指标,一般我们会统计写数量(Com_insert + Com_update + Com_delete)、读数量(Com_select)、语句总量(Questions)。
错误
错误量这类指标有多个应用场景,比如客户端连接 MySQL 失败了,或者语句发给 MySQL,执行的时候失败了,都需要有失败计数。典型的采集手段有两种。
- 在客户端采集、埋点,不管MySQL问题 or 网络问题或中间负载均衡问题或DNS解析问题,只要连接失败,都能发现。但有代码侵入性。
- 从 MySQL 采集相关错误,如连接错误通过 Aborted_connects、Connection_errors_max_connections拿
show global status where Variable_name regexp 'Connection_errors_max_connections|Aborted_connects';
+-----------------------------------+--------+
| Variable_name | Value |
+-----------------------------------+--------+
| Aborted_connects | 785546 |
| Connection_errors_max_connections | 0 |
+-----------------------------------+--------+
只要连接失败,不管啥原因,Aborted_connects 都 +1,而更常用的是 Connection_errors_max_connections ,表示超过了最大连接数,所以 MySQL 拒绝连接。MySQL默认最大连接数151,在现在这样硬件条件下,实在太小,因此出现这种情况的频率较高,要多关注,及时发现。
SHOW VARIABLES LIKE 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
可通过如下命令调整最大连接数:
SET GLOBAL max_connections = 2048;
虽可通过命令临时调整最大连接数,但一旦重启话就失效。为永久修改该配置,需调整 my.cnf 加一行:
max_connections = 2048
events_statements_summary_by_digest 表也能拿到错误数量。
SELECT schema_name, SUM(sum_errors) err_countFROM performance_schema.events_statements_summary_by_digestWHERE schema_name IS NOT NULLGROUP BY schema_name;+--------------------+-----------+
| schema_name | err_count |
+--------------------+-----------+
| employees | 8 |
| performance_schema | 1 |
| sys | 3 |
+--------------------+-----------+
饱和度
MySQL用什么指标反映资源有多“满”?先关注 MySQL 所在机器 CPU、内存、硬盘I/O、网络流量这些基础指标。
MySQL本身也有一些指标反映饱和度,如连接数,当前连接数(Threads_connected)除以最大连接数(max_connections)可得 连接数使用率,需重点监控的饱和度指标。
InnoDB Buffer pool 相关指标:
- Buffer pool 的使用率
- Buffer pool 的内存命中率
Buffer pool内存专门用来缓存 Table、Index 相关数据,提升查询性能。
查看Buffer pool相关指标:
MariaDB [(none)]> show global status like '%buffer%';
+---------------------------------------+--------------------------------------------------+
| Variable_name | Value |
+---------------------------------------+--------------------------------------------------+
| Innodb_buffer_pool_dump_status | |
| Innodb_buffer_pool_load_status | Buffer pool(s) load completed at 220825 11:11:13 |
| Innodb_buffer_pool_resize_status | |
| Innodb_buffer_pool_load_incomplete | OFF |
| Innodb_buffer_pool_pages_data | 5837 |
| Innodb_buffer_pool_bytes_data | 95633408 |
| Innodb_buffer_pool_pages_dirty | 32 |
| Innodb_buffer_pool_bytes_dirty | 524288 |
| Innodb_buffer_pool_pages_flushed | 134640371 |
| Innodb_buffer_pool_pages_free | 1036 |
| Innodb_buffer_pool_pages_misc | 1318 |
| Innodb_buffer_pool_pages_total | 8191 |
| Innodb_buffer_pool_read_ahead_rnd | 0 |
| Innodb_buffer_pool_read_ahead | 93316 |
| Innodb_buffer_pool_read_ahead_evicted | 203 |
| Innodb_buffer_pool_read_requests | 8667876784 |
| Innodb_buffer_pool_reads | 236654 |
| Innodb_buffer_pool_wait_free | 5 |
| Innodb_buffer_pool_write_requests | 533520851 |
+---------------------------------------+--------------------------------------------------+
Innodb_buffer_pool_pages_total :InnoDB Buffer pool 页总量,页(page)是 Buffer pool 的一个分配单位,默认page size=16KiB,可通过 show variables like "innodb_page_size"看。
Innodb_buffer_pool_pages_free :剩余页数量,通过 total 和 free 可得 used,used/total=使用率。使用率高不是说有问题,因为InnoDB有 LRU 缓存清理机制,只要响应够快,高使用率也不是问题。
Innodb_buffer_pool_read_requests 和 Innodb_buffer_pool_reads :read_requests 表示向 Buffer pool 发起的查询总量,若Buffer pool缓存了相关数据直接返回,没有就得穿透内存去查询硬盘。
有多少请求满足不了,需查硬盘?得看 Innodb_buffer_pool_reads 指标统计数量。
reads指标 / read_requests = 穿透比例
比例越高,性能越差,可调整 Buffer pool 大小解决。
根据 Google 四个黄金指标方法论,梳理 MySQL 相关指标,这些指标大多可通过 global status 和 variables 拿到。performance schema、sys schema 相对难搞:
- sys schema 需要较高版本才能支持
- 这两个 schema 的数据不太适合放到 metrics 库
常见做法通过一些偏全局统计指标,如Slow_queries,先发现问题,再通过这俩 schema 的数据分析细节。
不同的采集器采集的指标,命名方式会有差别,不过大同小异,关键理解思路、原理。
利用 Categraf 配置采集,演示整个过程。
2 采集配置
Categraf 针对 MySQL 的采集插件配置,在 conf/input.mysql/mysql.toml 里。我准备了一个配置样例,你可以参考。
[[instances]]
address = "127.0.0.1:3306"
username = "root"
password = "1234"extra_status_metrics = true
extra_innodb_metrics = true
gather_processlist_processes_by_state = false
gather_processlist_processes_by_user = false
gather_schema_size = false
gather_table_size = false
gather_system_table_size = false
gather_slave_status = true# # timeout
# timeout_seconds = 3# labels = { instance="n9e-dev-mysql" }
最关键的配置是 数据库连接地址和认证信息,具体采集哪些由一堆开关控制。建议把
- extra_status_metrics
- extra_innodb_metrics
- gather_slave_status
置true,其他都不太需采集。labels推荐加instance标签,给这数据库取表意性更强名称,收到告警消息可一眼知道是哪个数据库问题。instances部分是数组,若要监控多个数据库,就配置多个 instances。
Categraf作为采集探针,采集 MySQL 时,有两种方案:
2.1 中心化探测
找一台机器作为探针机器,部署一个单独 Categraf,只采集 MySQL 相关指标,同时采集所有的 MySQL 实例,即这个 Categraf 的 mysql.toml 中有很多 instances 配置段。
2.1.1 适用
- MySQL 实例数量较少
- 云上 RDS 服务
相对不太方便做自动化,如新建一个MySQL,还需要到这个探针机器里配置相关的采集规则,麻烦。
2.2 分布式本地采集(推荐)
把 Categraf 部署到部署 MySQL 的那台机器上,让 Categraf 采集 127.0.0.1:3306 实例。
MySQL服务建议不要混部,一台宿主机就部署一个 MySQL,InnoDB Buffer pool设置大些,80%物理内存,性能杠杠。
DBA 管理 MySQL经常创建集群,通常沉淀一些自动化工具,在自动化工具里把部署 Categraf、配置 Categraf 的 mysql.toml 的逻辑都加上,一键搞定。监控只需读权限,建议为监控系统创建一个单独的数据库账号,统一账号、统一密码、统一授权,这样 mysql.toml 配置也一致。
采用这种部署方式一般就用机器名做标识,不太需单独instance标签。Categraf 内置一个 夜莺监控大盘,大盘变量使用机器名来做过滤。如用Grafana,去 Grafana 官网搜 Dashboard,大同小异。刚提到的那些关键指标最好都放Dashboard。
效果图:
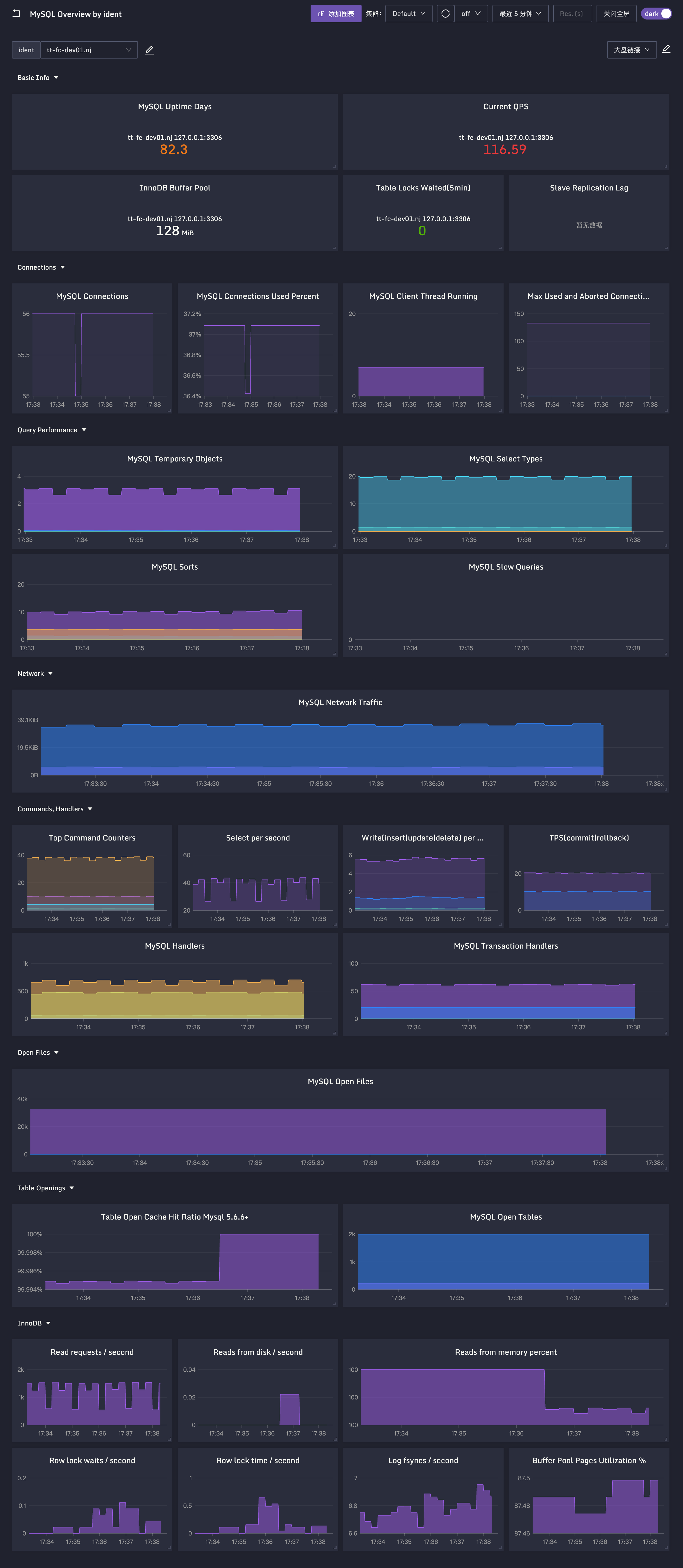
3 业务指标
MySQL指标采集核心原理:连上MySQL执行一些 SQL,查询性能数据。
Categraf 内置一些查询 SQL,能否自定义SQL查询一些业务指标?如查询一下业务系统的用户量,把用户量作为指标上报到监控系统。可使用 Categraf 的 MySQL 采集插件实现,查看 mysql.toml 里的默认配置:
[[instances.queries]]
# 作为 metric name 的前缀
mesurement = "users"
# 查询返回的结果,可能有多列是数值,指定哪些列作为指标上报
metric_fields = [ "total" ]
# 查询返回的结果,可能有多列是字符串,指定哪些列作为标签上报
label_fields = [ "service" ]
# 指定某一列的内容作为 metric name 的后缀
field_to_append = ""
# 语句执行超时时间
timeout = "3s"
# 查询语句,连续三个单引号,和Python的三个单引号语义类似,里边内容就不用转义
request = '''
select 'n9e' as service, count(*) as total from n9e_v5.users
'''
自定义SQL的配置,想查询哪个数据库实例,就在对应 [[instances]] 下面增加 [[instances.queries]] 。
MySQL 相关的监控实践,包括性能监控和业务监控,核心就是上面我们说的这些内容,下面我们做一个总结。
4 总结
Google 四个黄金指标方法论指导MySQL 监控数据采集,从延迟、流量、错误、饱和度分别讲解了具体指标是什么及如何获取。
采集器部署还有一种就是容器环境 Sidecar 模式。因为生产环境里 MySQL 一般很少放容器,所以没提。
由于 MySQL 存储很多业务数据,是业务指标重要来源,通过自定义 SQL可以获取很多业务指标,推荐试用这种监控方式。
5 FAQ
MySQL的监控大盘已给出,一些关键指标也点出,告警规则怎么配置?常见的告警 PromQL 哪些?
对于MySQL监控大盘中的关键指标,我们可以根据业务需求设置相应的告警规则。一些常见的告警PromQL表达式如下:
-
监控服务器运行状态:如果服务器停止响应或CPU使用率超过阈值,则发出告警。
up == 0 or (100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)) > 90 -
监控MySQL数据库性能:例如,监听可用连接数是否已达到最大连接数并进行告警。
mysql_global_status_threads_connected / mysql_global_variables_max_connections * 100 > 80 -
监控MySQL数据库存储空间:配置阈值,并在使用率超过预设值后触发告警。
mysql_info_schema_data_length_bytes / mysql_info_schema_data_free_bytes * 100 > 80
除以上这些例子外,还可以根据具体业务情况自定义更多的告警规则。提示:为了实现更精细化的告警,建议对不同种类的监控数据,针对不同的告警级别进行区分,制定更加明确的告警策略。