来源:投稿 作者:小灰灰
编辑:学姐
论文标题:CSI-based Positioning in Massive MIMO systems using Convolutional Neural Networks
摘要
研究了使用大规模MIMO(MaMIMO)系统的信道状态信息(CSI)的用户定位系统的性能。为了从CSI中推断用户的位置,设计了一个卷积神经网络,并通过一个新的数据集进行评估。该数据集包含使用三种不同天线拓扑的室内MaMIMO CSI测量,覆盖2.5米×2.5米的室内区域。我们表明,我们可以训练卷积神经网络(CNN)模型来估计用户在该区域内的位置,平均误差小于半个波长。此外,一旦对模型进行了给定场景和天线拓扑的训练,转移学习将用于将获得的知识重新用于天线拓扑和配置显著不同的另一个场景。我们的结果表明,对于新的拓扑结构,只需使用少量额外标记的样本,就可以进一步训练CNN。这种转移学习方法能够获得准确的结果,为CNN驱动的基于CSI的实用定位系统铺平了道路。
介绍
大规模MIMO(MaMIMO)是5G通信网络中使用的一种新兴技术,可大大提高无线系统的频谱效率。它通过将大量基站(BS)天线与基于测量信道状态信息(CSI)的信号处理相结合来实现。该CSI在上行传输期间使用导频序列进行估计。大量天线和精确CSI的组合允许BS在空间域中复用用户。理论表明,随着基站天线数量的增加,系统的性能仅受信道状态信息的准确性的限制。如果这种准确的信道状态信息可用,那么问题就出现了,该信息是否可以用于推断环境的其他上下文信息。
CSI包含空间信息,BS使用这些信息在空间域中复用用户。因此,它可以被提取并用于在空间中定位用户。无线终端的本地化对于室内和室外网络都有许多有趣的应用。例如,室内导航系统可用于引导用户通过建筑物,在无法检测到GPS信号的覆盖区域启用自动驾驶[2]。此外,MaMIMO系统已经需要CSI来进行通信,因此使用CSI来定位用户没有额外的成本。
Savic和Larsson在MaMIMO系统中引入了基于指纹的位置服务通知[3]。他们提出了几种基于经典机器学习算法(κ最近邻、支持向量机和高斯过程回归)的定位方法。作为这些学习算法的输入,使用包含接收信号强度值的矢量。然而,这种方法只使用MaMIMO系统中可用信息的一小部分。
在Vieira等人[5]的一篇论文中,研究了使用卷积神经网络(CNN)提取MaMIMO系统CSI中空间信息的能力。与接收到的信号强度矢量相比,CSI提供了更多的信息,而CNN提供了一种有效的方法来处理这些数据。他们发现,在MaMIMO CSI样本的模拟测试集上,他们的模型可以达到低于波长精度的精度。他们使用由COST 2100 MIMO模型[6]生成的CSI样本评估他们的方法,使他们能够访问无限数量的完美标记数据。通过这种设置,作者达到了大约0.6波长的性能。然而,真正的挑战在于收集现实生活中标记的数据。
【1】Arnold等人提出了一种新的信道发声器架构,以解决测量MaMIMO CSI的不足。他们将拟建的64天线信道测深仪采集的数据集应用于室内定位问题。然而,他们的结果仅达到约75 cm的精度,远低于Vieira提出的精度。这种精度较低的原因是所提供标签的精度较低,建议约为10 cm。
放松对高精度标记数据的需求将是实际部署基于CNN的本地化系统的关键。在目前的研究中,每一个新的场景都需要大量的标记数据来训练CNN。收集这些数据量的成本太高,无法使基于指纹的定位技术可行。例如,对于完全分布式的MaMIMO架构,天线的拓扑结构将因其部署位置的功能而异。如果每个新部署都需要大量的标记数据,那么这种方法将永远无法达到实用状态。
这项工作将侧重于收集高度准确的标记测量数据,并在遇到新情况时尽量减少对这些数据的需求。
本文的主要贡献是:
-
最先进的MaMIMO系统的高精度空间标记CSI数据集的创建已经公开。
-
应用CNN根据测量的CSI数据集推断用户的位置,
-
在具有不同天线拓扑结构的两个场景之间传递知识,以尽量减少对新标记样本的需求,
-
使用MaMIMO系统CSI的最先进定位能力,平均精度为23.92 mm,对应于0.209λ。
这比Vieira【2】报告的准确度低65%。
DATASET
为了本研究的目的,创建了一个新的数据集。该数据集包含由KU鲁汶大规模MIMO测试台针对许多用户位置测量的CSI。基站(BS)配有64根天线,可以同时发射或接收。这64根天线用于接收来自每个用户的预定义导频信号。基于这些导频信号来估计CSI。导频音由频率均匀间隔的100个子载波组成。因此,测量的CSI可以由矩阵H表示![]() ,其中N是BS处的天线数量。有关该系统的更多详细信息,可参考国家仪器大规模MIMO应用框架文件[3]。
,其中N是BS处的天线数量。有关该系统的更多详细信息,可参考国家仪器大规模MIMO应用框架文件[3]。
在测量过程中,四个单天线用户被安置在办公室的室内。它们由CNC XY-工作台[9]沿预定义路线移动。通过使用这些XY表格,位置标签上的误差小于1 mm。该路线沿着每个用户的1.25 m x 1.25 m区域的网格行进。所有路线都完全在视线(LoS)内。使用此设置,以5 mm的间隔扫描该区域,得到包含252004个CSI样本的数据集,其定位精度小于1 mm。此外,测试台的BS设计为在天线阵列部署方面非常灵活。这允许创建三个不同的数据集,每个数据集都有一个独特的天线部署。首先,部署了8×8天线的统一矩形阵列(URA)。其次,在一条线上部署了64个天线的均匀线性阵列(ULA)。最后,天线以八对一的形式分布在房间中,构成了分布式场景。据我们所知,所得数据集是最大的室内MaMIMO CSI数据集,带有空间标签。
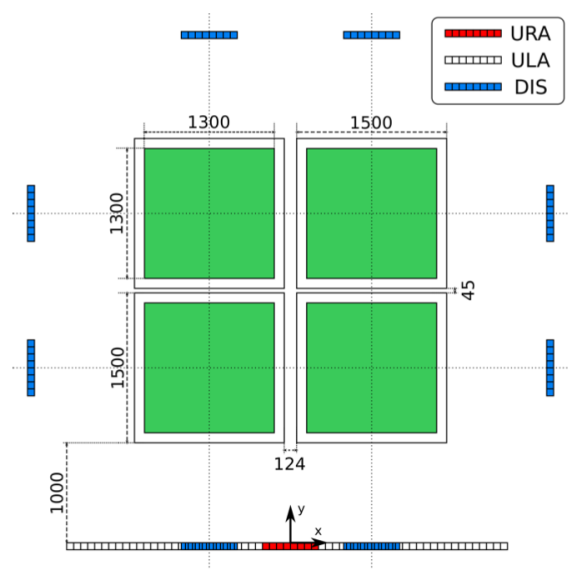
图1.三种测量场景。天线使用场景特定拓扑围绕用户间隔开。用户位于绿色区域内。图中的所有测量单位均为mm。
不同的部署如图1所示。在所有情况下,天线都放置在距离XY表1米的位置。图中的绿色矩形描绘了1.3米乘1.3米的区域,XY表可以将用户移动到该区域。为了减少测量期间的误差,使用了中心1.25米乘1.25米的区域。XY工作台之间的间距由电机驱动运动所需的空间以及将电机连接到控制器的电缆决定。这些表通过以太网与BS同步,以确保采样的H具有正确的空间标签,从而实现高度准确的数据集。
本文的贡献点:
在测量期间,BS被配置为使用2.61 GHz的中心频率fc,波长λ为114.56 mm。系统使用20 MHz的带宽。相邻天线元件之间的间距为70mm,最低天线元件位于地板上方93cm处。用户的天线放置在地板上方20厘米处。该空间的起源被定义为URA的中部。从这个空间点开始,测量用户的x和y位置。分布式场景的图片如图2所示。
包含空间标记的公共可用数据集MaMIMO CSI样品对测试和台架测试非常有价值标记不同的基于MaMIMO CSI的定位方法。此外,这些数据集可以用于更多的应用和研究,而不是本地化问题。然而,这类数据集的数量非常有限。因此,为了鼓励进一步研究,该数据集公开【4】可用。
数据集介绍:
超密度MAMIMO CSI数据集(2020年6月)
该数据集包含使用KU鲁汶大规模MIMO测试台收集的数千个信道状态信息样本。它是在电气工程系的一个实验室里收集的。测量集中于四种不同的天线阵列拓扑;URA LoS、URA NLoS、ULA LoS和DIS LoS。所有样本都配有非常准确的空间标签。
会议室数据集(2019年8月)
该数据集包含使用KU鲁汶大规模MIMO测试台收集的数千个信道状态信息样本。它是在电气工程部的会议室里收集的。测量集中于三种不同的天线阵列拓扑;URA、ULA和DIS。所有测量均在静态环境中的视线条件下进行。所有样本都配有非常准确的空间标签。
MIMO实验室数据集
该数据集包含使用KU鲁汶大规模MIMO测试台收集的数千个信道状态信息样本。它是在TELEMIC研究小组的MIMO实验室收集的。数据集中于视线和非视线条件下的室内位置。它还包含同一个房间的数据和移动的行人,创造了一个游牧环境。
卷积神经网络模型
卷积神经网络(CNNs)最近对图像分类领域进行了革新。事实证明,它们在学习结构化数据中的相关特征以分类数据内容方面非常有效。所获得的MaMIMO CSI包含大量结构化数据,因此,CNN是处理这些CSI样本并推断其空间信息的良好候选技术。本节介绍CNN是如何为这一特定任务设计的。首先,我们评估如何利用特定领域的知识来帮助CNN提取有用的特征。其次,讨论了模型的架构,CNN的Python代码是开源的。
A、 特定领域的知识
在执行此任务的CNN时,特定于领域知识可以用来帮助网络学习有用特征。首先,数据集包含复数。为了帮助CNN获取这些信息将有值的数字转换为极域。在这个域、振幅和相移副载波可以很容易地提取出来,帮助CNN学习有用的功能。第二,由于信息在在频域,我们执行快速傅立叶逆变换对数据进行变换以显示时域中的特征。然后,这三组不同的特征(原始特征、极轴特征和时域特征)在CNN输入端呈现之前被连接起来。该预处理产生输入矩阵![]()
在设计CNN时,卷积的大小可以自由选择,这个大小称为核大小。当训练CNN进行图像分类任务时,这个大小通常被选择为(3,3)或类似的大小。然而,由于该数据与图像数据非常不同,并且领域知识可用,因此应该相应地调整内核大小。因此,在CNN的高层中,内核大小被设计为对数据执行1D卷积。这样,神经网络首先从每个天线的数据中提取相关特征。下层在其他维度上执行卷积,以组合来自多个天线的特征。使用领域特定知识设计内核大小可以减少可训练参数的数量,这使得CNN训练更快,不太容易过度拟合。
B、 体系结构
完整的CNN包含13个卷积层,通过跳转连接[10]和跳出层进行了改进,最后有三个完全连接的层。可训练参数的总量取决于模型中使用的天线数量。对于64个天线,可训练参数的数量为217378,仅为Arnold等人使用的权重的1.36%[7]。
先前关于使用CNN的基于CSI的定位的工作没有包括对应用的深度学习技术的详细描述。因此,无法将我们的方法的学习效率与其他方法进行比较。为了在将来缓解这个问题,以及有关实现的更多细节,该代码已在线发布。CNN是使用Keras和TensorFlow以及它的源代码实现的
评估
本节探讨了影响上述CNN定位能力的各种因素。首先,对CNN在三种不同场景下的定位任务训练的性能进行评估。其次,研究了基站使用的天线数量的影响。之后,研究了使用迁移学习将知识从一个场景迁移到另一个场景的能力。所有结果都是在测试集上计算的,这是总数据集的5%。
A、 天线拓扑结构导致的性能差异
所使用的天线拓扑结构影响定位系统的精度。因此,对三种不同的天线拓扑进行了评估。图3显示了三种不同天线拓扑的定位误差的CDF。该模型对85%的数据集进行了训练,剩下10%的数据集用于验证。结果表明,CNN能够推断所有三种场景的空间信息,其中URA和ULA场景具有最高的准确性。
在使用的数据集中,用户都被放置在地板上方相同的高度。因此,模型不需要推断用户的身高。然而,推断高度信息的能力可能取决于天线拓扑结构。因此,为了进一步研究定位性能的拓扑依赖性,需要一个包含用户高度变化的样本的数据集。
B、 天线数量的影响
BS中使用的天线数量也在很大程度上影响精度。在基于CSI的定位系统中,系统的精度将随着使用天线的数量而提高。这正是我们在使用数据集子集评估建议模型时所看到的。这里,我们对数据集进行子采样,因此我们只使用特定数量的天线提供的数据。当天线数量从8个增加到64个时,根据拓扑结构,系统的精确度提高了58%到76%。
表I显示了三种情况下测试集的平均误差(ME)与使用天线数量的关系。ME计算如下:
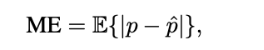
其中p是用户的测量位置(x,y),pˆ是估计位置。结果均以毫米为单位以绝对精度显示,以一个波长λ为单位以相对精度显示。这允许独立于所使用的载波频率来比较结果。
表一平均误差-在不同场景的测试集上测量的拟议系统的定位性能。
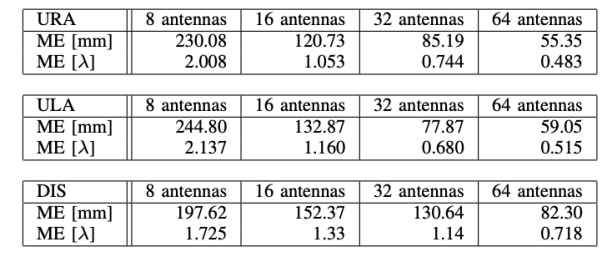
结果表明,系统的准确度确实随着天线使用量的增加而提高。当使用64个天线时,URA和ULA拓扑的精度约为12λ。现在,主要的问题是,学习的模型在多大程度上可以在不同的背景下推广,例如不同的天线拓扑。
C、 迁移学习
使用迁移学习,在前一项任务的培训过程中收集的知识可用于加速类似新任务的培训。此外,为新任务训练模型所需的训练样本数量大大减少。该技术通常用于图像分类,,其中CNN中第一层的权重在新网络中重用。这些第一层包含低级别功能的过滤器,它们通常适用于类似的任务。这样,CNN已经从基本知识开始。
本文研究了具有不同天线拓扑结构的两种场景之间传递知识的能力。具体而言,评估了从URA场景到具有64个天线的ULA场景的知识转移。其主要思想是,CNN的第一层包含如何从原始数据推断空间相关特征的知识。无论使用哪种天线拓扑结构,都可以重复使用。较低的层组合单独的空间特征以估计用户的位置。因此,只需要对较低的层进行再培训,这样可以以较低的样本需求实现更快的培训。
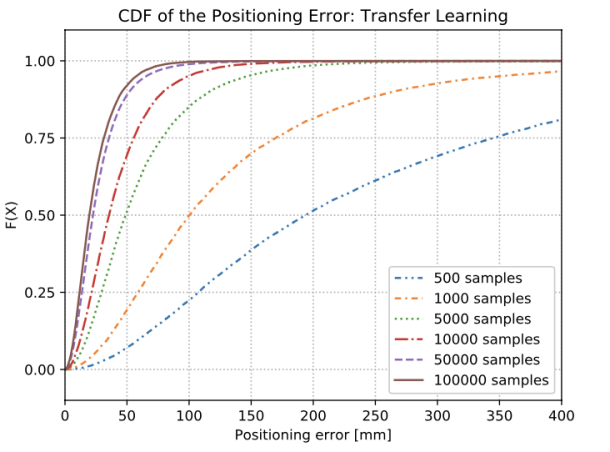
图4.使用不同数量的训练样本执行迁移学习的平均误差的CDF。
图4显示了我们如何用较少的训练样本实现类似或甚至更高的性能。仅使用5000个ULA训练集样本,CNN在不使用转移学习的情况下实现了与在完整ULA训练集中训练的网络相似的性能。此外,当使用100000个样本进行训练时,系统的性能比使用所有ULA样本但没有应用转移学习的情况下更高。这可以解释为,与没有迁移学习的情况相比,模型有更多的样本可供学习。这使得模型能够进一步微调样本的一般统计数据,同时学习新场景的机制。
表二使用迁移学习时的平均误差与使用的训练样本的数量成函数。

表II显示了使用从URA到ULA场景的转移学习时的平均定位误差。这表明,与仅使用一个特定场景的信息的情况相比,转移学习可以达到更高的定位性能。建议的技术达到23.92 mm的ME,对应于0.209λ。
为了可视化我们提出的模型的性能,我们将大学名称的字母转换为XY表格区域内的坐标。模型使用这些位置处测量的CSI来预测相应的位置。该模型的预测拼写了我们大学的名字“KU鲁汶”,ME为23.97 mm(0.21λ),如图5所示。
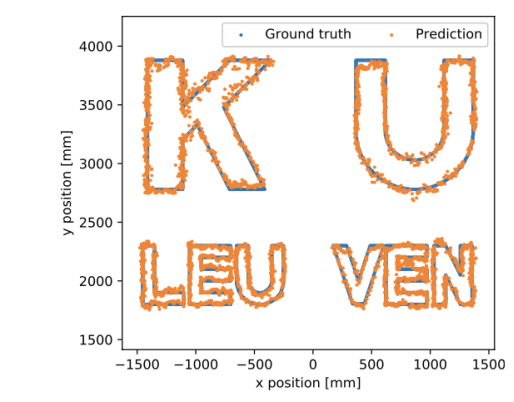
图5:一个可视化示例,展示了我们提出的模型的性能。该模型首先在完整的URA训练集上进行训练,然后使用迁移学习,用100000个ULA训练集样本对其进行再训练。可视化是使用ULA数据集创建的。
结论
下一步将是对不同的环境进行评估,以实现拟议技术的实际应用。到目前为止,通过在不同的拓扑中部署天线,情况发生了变化。但是,还必须研究将系统转移到另一个环境(例如另一个房间)的影响。这将为系统如何推断空间信息以及在新环境中收集多少数据以使用转移学习重新训练CNN提供额外的见解。
此外,最近在半监督学习方面的进步允许使用仅部分标记的数据训练模型。由于在新环境中获取空间标记的数据非常昂贵,而收集未标记的数据则非常容易,因此减少对收集的数据进行标记的需要将降低拟议定位系统的部署成本。半监督学习的主要思想是,模型使用未标记数据学习任务的统计信息,而标记数据负责将收集的知识映射到有用的输出。因此,在这项任务中应用半监督学习可以真正推动这项技术从研究走向实际解决方案。
结论
我们研究了卷积神经网络在大规模MIMO通信系统中推断用户位置的能力。从基站收集的信道状态信息中提取用户的空间信息。为了训练CNN,创建并发布了一个新的室内MaMIMO CSI测量数据集。据我们所知,该数据集是最大的具有空间标签的公共可用数据集,它由三个不同场景组成,每个场景有252004个CSI样本。
该数据集与最先进的CNN架构一起,使我们能够以55.35 mm的精度推断用户的位置,即0.483λ。该结果优于文献中发现的任何结果。此外,我们还研究了在使用不同天线拓扑部署系统时,使用传输学习来降低所需数据量的能力。我们表明,与不使用知识转移相比,达到类似性能所需的标记数据量减少了20倍。此外,当新场景的更多标记数据可用时,这种技术甚至可以达到更高的性能,即23.92 mm或0.209λ。
参考文献:
1 M.Arnold,J.Hoydis,andS.tenBrink,“NovelMassiveMIMOChannel Sounding Data applied to Deep learning-based Indoor Positioning”, 12th International ITG Conference on Systems, Communications and Coding, February 2019.
2 J. Vieira, E. Leitinger, M. Sarajlic, X. Li, and F. Tufvesson, “Deep Convolutional Neural Networks for Massive MIMO Fingerprint-Based Positioning,”, IEEE PIMRC 2017.
3 NI, “5G Massive MIMO Testbed: From Theory to Reality”, http://www.ni.com/nl-be/innovations/white-papers/14/5g-massive- mimo-testbed–from-theory-to-reality–.html
4 https://homes.esat.kuleuven.be/~sdebast/
关注下方《学姐带你玩AI》🚀🚀🚀
论文资料+比赛方案+面试经验all in
码字不易,欢迎大家点赞评论收藏!