欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
本篇概览
- 本文是《prometheus实战》系列的第二篇,在《prometheus实战之一:用ansible部署》一文咱们部署了prometheus服务,并且在应用服务器部署了node_exporter,整体情况如下图
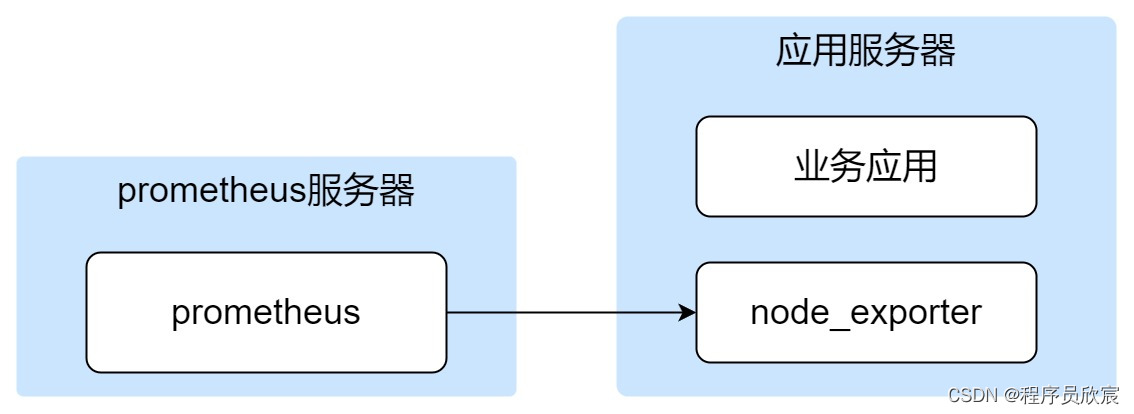
- 目前,prometheus已经可以通过node_exporter从应用服务器取得监控数据,本篇就来学习如何使用这些监控数据来展现应用服务器综合状态,例如CPU、内存、磁盘、网络等指标的情况,经过本篇的实战,算是对prometheus的指标和查询语言PromQL有了最基本的了解,算是入门了
- 总的来说,本篇由以下内容组成,学习最基础的指标,以及与之匹配的表达式
- 基础知识储备
- 官方入门指标:prometheus_target_interval_length_seconds
- 最简单的counter类型指标:prometheus_tsdb_head_chunks_created_total
- node_exporter指标:CPU相关
- node_exporter指标:内存相关
- node_exporter指标:磁盘相关
- node_exporter指标:网络相关
基础知识储备
- 要想写出有用的查询表达式,必须有一些必要的基础知识储备,主要有:指标类型、常用函数
- 先看指标类型,共有四种
- counter(计数器):这个很好理解,只增不减,例如CPU时间
- guage(仪表盘):可以用现实生活中仪器的仪表盘来理解,只用来反映当前的瞬时状态,例如车辆的时速,是有时高有时低的
- summary:这个类型用于一些统计分布的场景,举个例子:服务端响应了一百个请求,除了平均响应时间,有时候还想了解一百个请求耗时排序后的情况,例如中位耗时是多少,9分位耗时是多少,这时候用summary就比较合适了,它本身就是客户端计算好分布情况之后再上报的,标签中带有分位情况,例如:quantile=0.9
- histogram:与summary类似,也是用来反应统计分布的情况,不同的是histogram是为分段统计准备的,也就是直方图,这里还是举一个例子吧
- 下面是指标prometheus_http_response_size_bytes的数据,prometheus_http_response_size_bytes_bucket有九条记录,相当于按照每一次响应的大小一共准备了9个桶,第一个桶,le=100表示小于100的响应全部在这个桶里,一共有四条记录,注意第二条len=1000,其值也等于4,表示小于1000的总数是4个,这里是包含了len=100的那4条记录的,所以,100-1000这个区间的总数是0个!
# TYPE prometheus_http_response_size_bytes histogram
prometheus_http_response_size_bytes_bucket{handler="/",le="100"} 4
prometheus_http_response_size_bytes_bucket{handler="/",le="1000"} 4
prometheus_http_response_size_bytes_bucket{handler="/",le="10000"} 4
prometheus_http_response_size_bytes_bucket{handler="/",le="100000"} 4
prometheus_http_response_size_bytes_bucket{handler="/",le="1e+06"} 4
prometheus_http_response_size_bytes_bucket{handler="/",le="1e+07"} 4
prometheus_http_response_size_bytes_bucket{handler="/",le="1e+08"} 4
prometheus_http_response_size_bytes_bucket{handler="/",le="1e+09"} 4
prometheus_http_response_size_bytes_bucket{handler="/",le="+Inf"} 4
prometheus_http_response_size_bytes_sum{handler="/"} 116
prometheus_http_response_size_bytes_count{handler="/"} 4
- 通过上面九个桶的统计,可知一共有4条记录,这和prometheus_http_response_size_bytes_count的值是一致的,另外prometheus_http_response_size_bytes_sum表示这所有4条记录的字节数之和是116,有了这些数据,画出每个区间的直方图就很容易了
- 再来看常用的内置函数
- increase:指定时间区间后,计算该指标在最早和最晚时间的值的查,即增长量,例如increase(node_cpu_seconds_total[1m])
- rate:如果将increase(node_cpu_seconds_total[1m])除以60,即这一分钟内平均每秒的增长量,那就是rate了,即rate(node_cpu_seconds_total[1m])
- irate:rate(node_cpu_seconds_total[1m])表示每一秒的增长量,除以60的弊端就是瞬时变化值被平摊到每一秒中,因此曲线图无法反映真实的瞬时变化,这时候用irate更合适,因为它取的是这一分钟内最后两个采样点的差值
- 至此,基础知识已经大致了解,接下来就用真实的指标在prometheus系统上实战
summary类型指标:prometheus_target_interval_length_seconds
-
来看一个内置指标prometheus_target_interval_length_seconds,其值的含义是两次抓取操作的间隔时间
-
如下图,首先一定要勾选红框中的Use local time,再在箭头所指位置输入prometheus_target_interval_length_seconds,就会显示该指标的曲线图
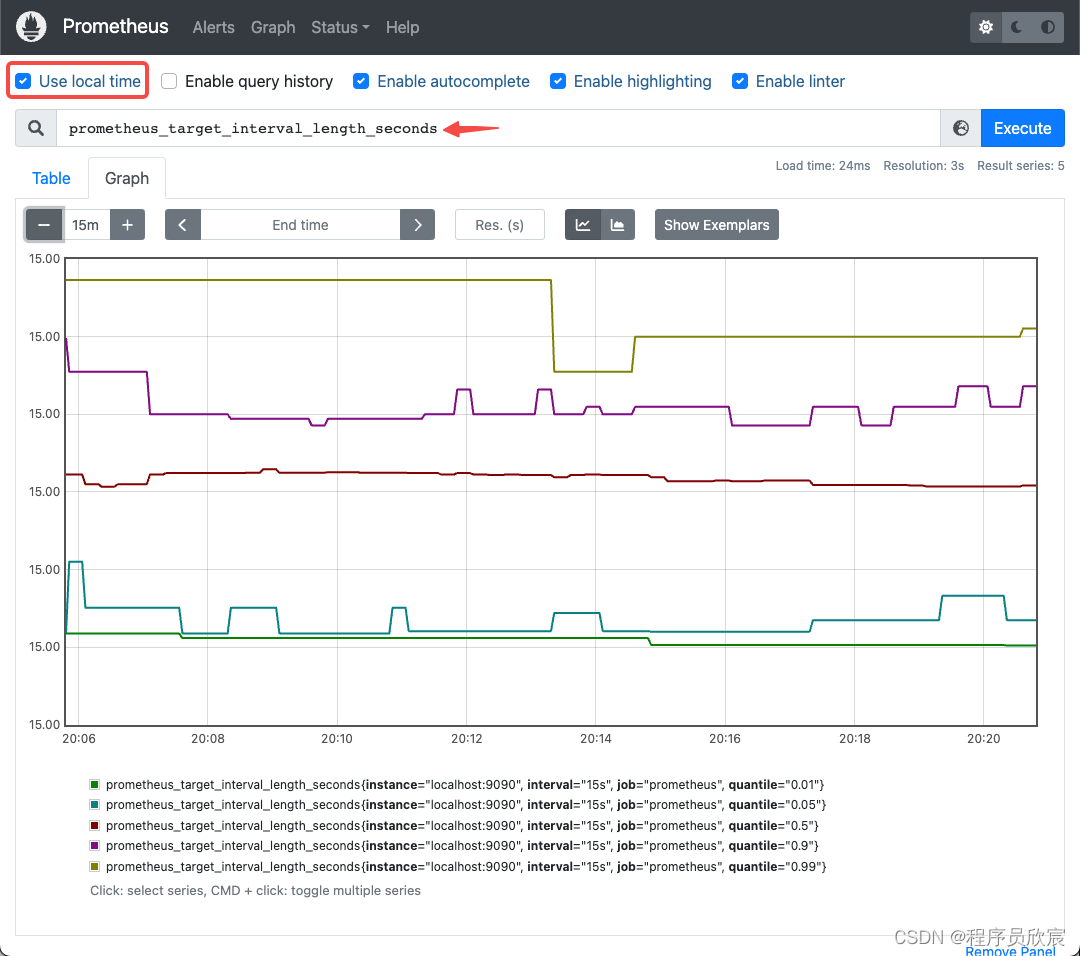
-
上图有四个曲线,分别代表该指标的P01到P99数据,P99的含义,是说假设同一时刻该指标有一百个值,P99代表排序后第九十九名的值
-
如果想查看具体数据,可以像下图这样切到Table页
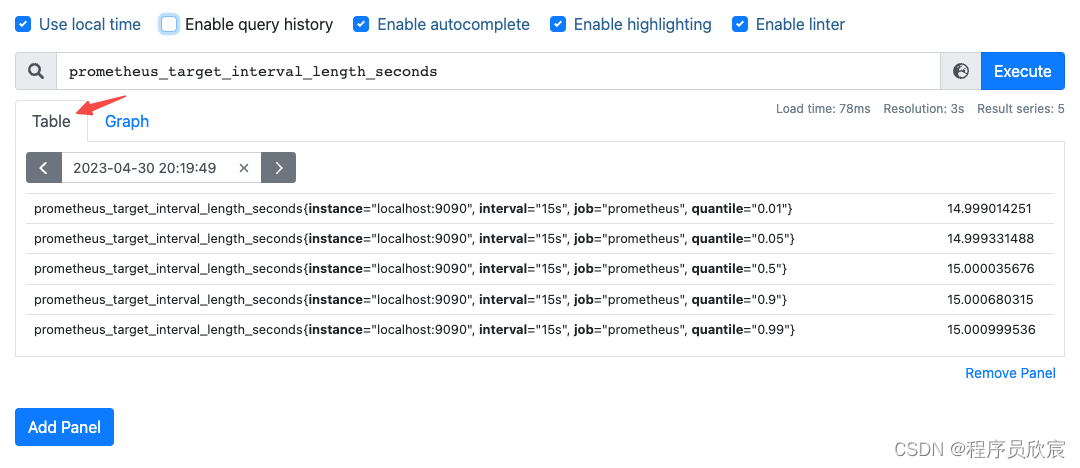
-
从上图可见,prometheus_target_interval_length_seconds是指标(metric),而job、quantile这些都是标签(label),来看第一个表达式,按照标签过滤指标,注意是大括号:
prometheus_target_interval_length_seconds{quantile="0.99"}
- 在页面输入,效果如下图所示,只会展示P99的数据
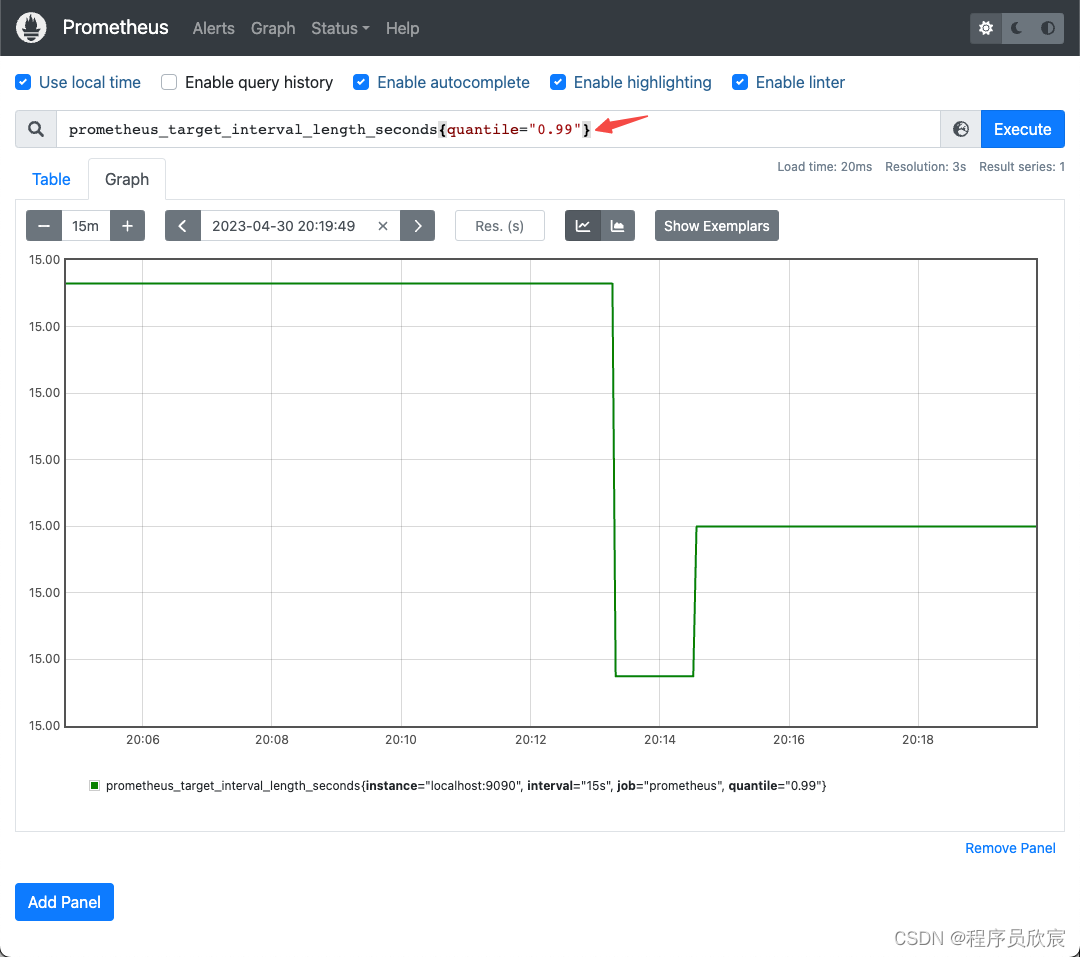
- 统计数量
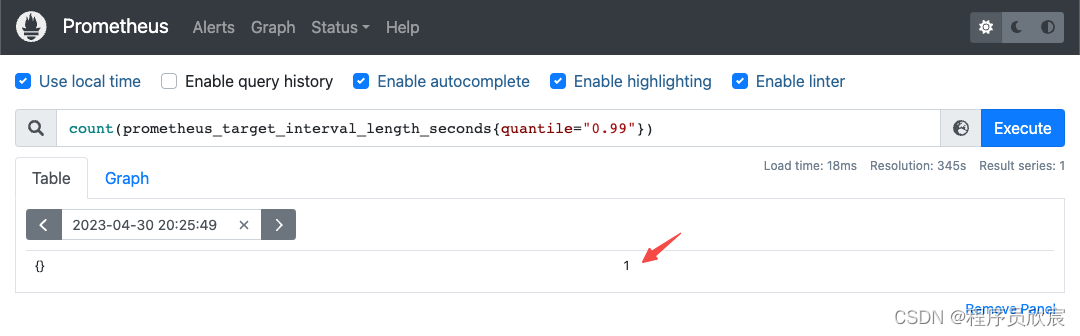
count(prometheus_target_interval_length_seconds{quantile="0.99"})
- 结果如下图,数量是1
counter类型指标:prometheus_tsdb_head_chunks_created_total
- prometheus_tsdb_head_chunks_created_total是counter类型的指标,其值会一直增加,含义是时序数据库tsdb的head中创建的chunk数量
- 先看prometheus_tsdb_head_chunks_created_total原始值的曲线图,如下图,可见确实是一直在增长
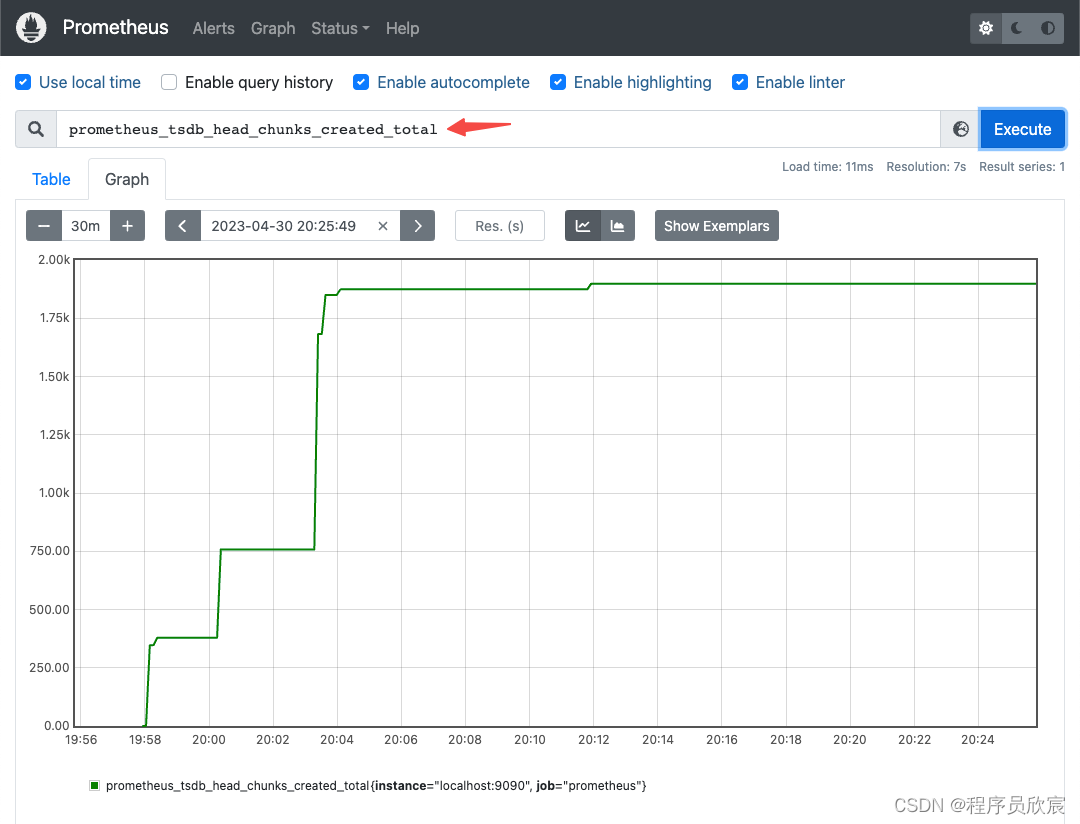
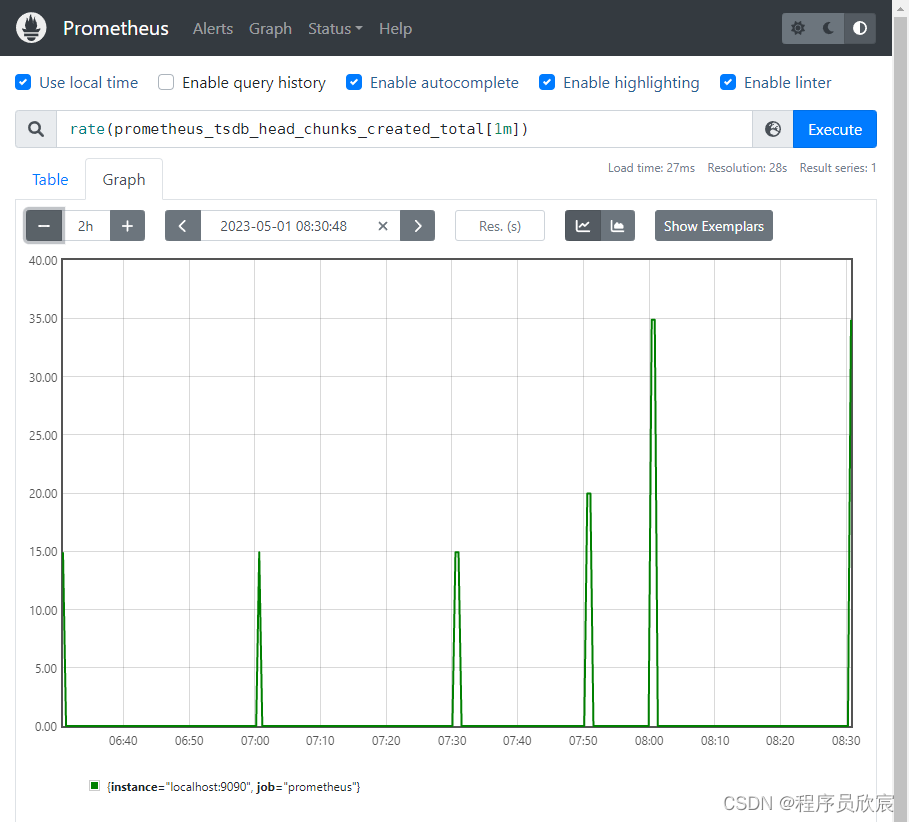
- 用rate函数,表达式如下,意思是取一分钟前后的变化(例如一分钟后增长了60),然后除以秒数60,所以表达式的值等于1
rate(prometheus_tsdb_head_chunks_created_total[1m])
- 上述表达式的曲线图如下
CPU使用率:理论分析
- 有了上面的基础,接下来自己试着写一个实用的表达式看看,先写一个常见的概念:CPU使用率
- 先把基础知识准备好,来看一个CPU使用率的截图,也就是top命令的效果

- 那么如何计算CPU使用率呢?来看一个云监控网站上的描述

- 可见,CPU使用率简单的说就是:除idle状态之外的CPU时间除以CPU总时间
- 因此,接下来咱们用prometheus的计算思路就是:1- idle/total
CPU使用率:准备工作(可跳过)
- 为了让CPU看起来很忙,我在应用服务器上做了个很消耗CPU的操作:用ffmpeg将h264文件转码为h265,参考命令如下,当然了您也可以不做此操作,这样CPU负载显得很低
~/bin/ffmpeg -i ~/videos/4kh264.mp4 -c:v libx265 -vtag hvc1 -c:a copy ./output.mp4
- 在ffmpeg转码的时候,CPU消耗是比较严重的,如下图,每个CPU核的空闲状态(idle)只剩下了30%,所以整体的CPU使用率大概在70%左右

CPU使用率:编写表达式
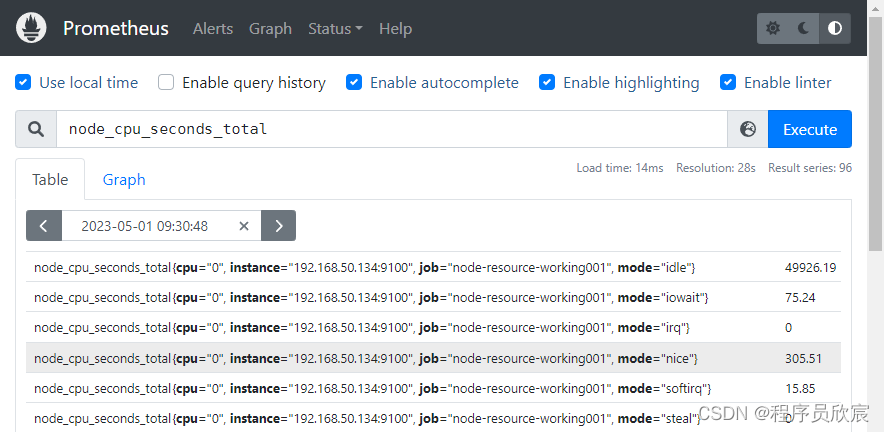
- 在prometheus计算CPU使用率,要用到的原始指标是node_cpu_seconds_total,它代表CPU每种模式下花费的时间,是counter型的,会随着时间一直增长
- 前文咱们为应用服务器配置了node_exporter,因此可以从prometheus查看应用服务器的node_cpu_seconds_total指标,如下图所示,每个值有四个标签,cpu表示第几个核,instance表示node_exporter所在机器,job表示来自prometheus配置的哪个任务,mode表示这是cpu哪个模式的值(相当于执行top命令后看到的用户态、内核态的CPU占比)
- 接下来梳理一下计算总时长和空闲状态时长的逻辑,如下图
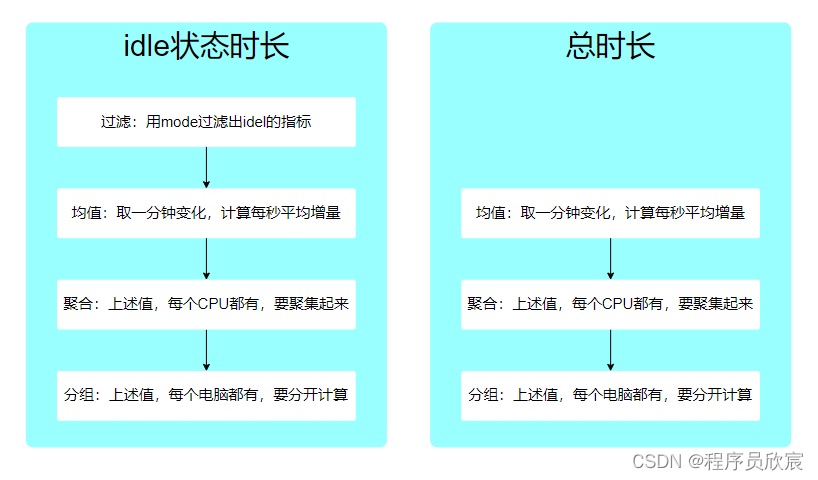
- 既然逻辑已经清晰,先写idle状态时长
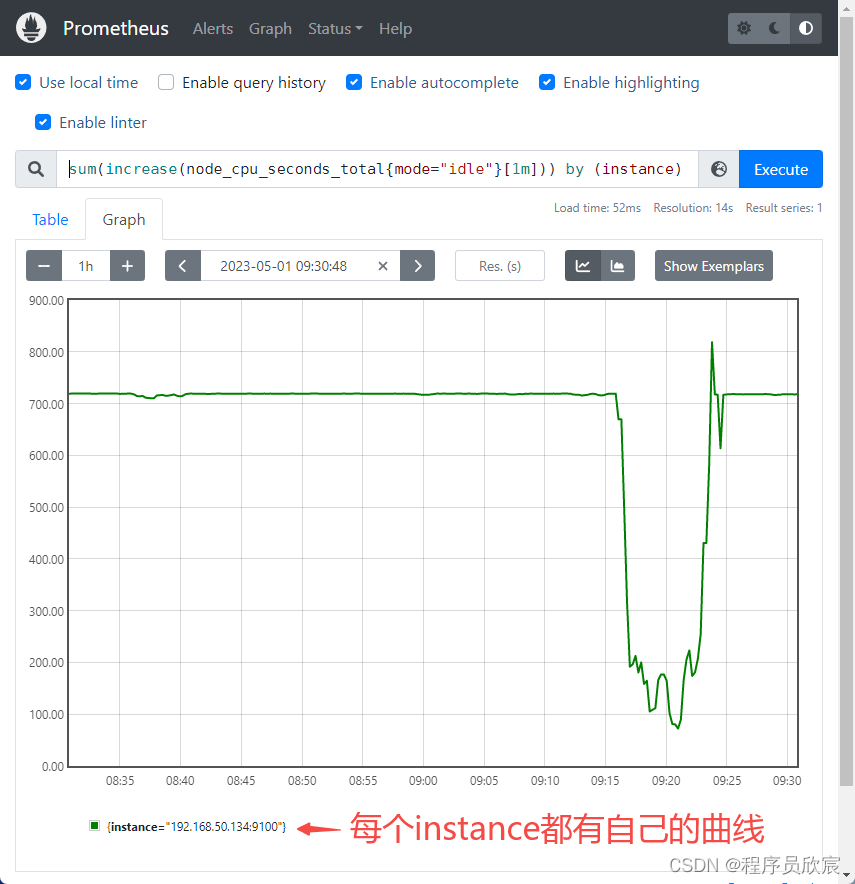
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)
- 用曲线图看看,可见09:30开始有个明显的凹坑,这是执行ffmpeg转码的时间段,这时候CPU负载高,导致idle状态的时间变短,符合实际情况
- 然后是总时长
sum(increase(node_cpu_seconds_total[1m])) by (instance)
- 现在有了idle时长和总时长,CPU使用率的表达式也就呼之欲出了:
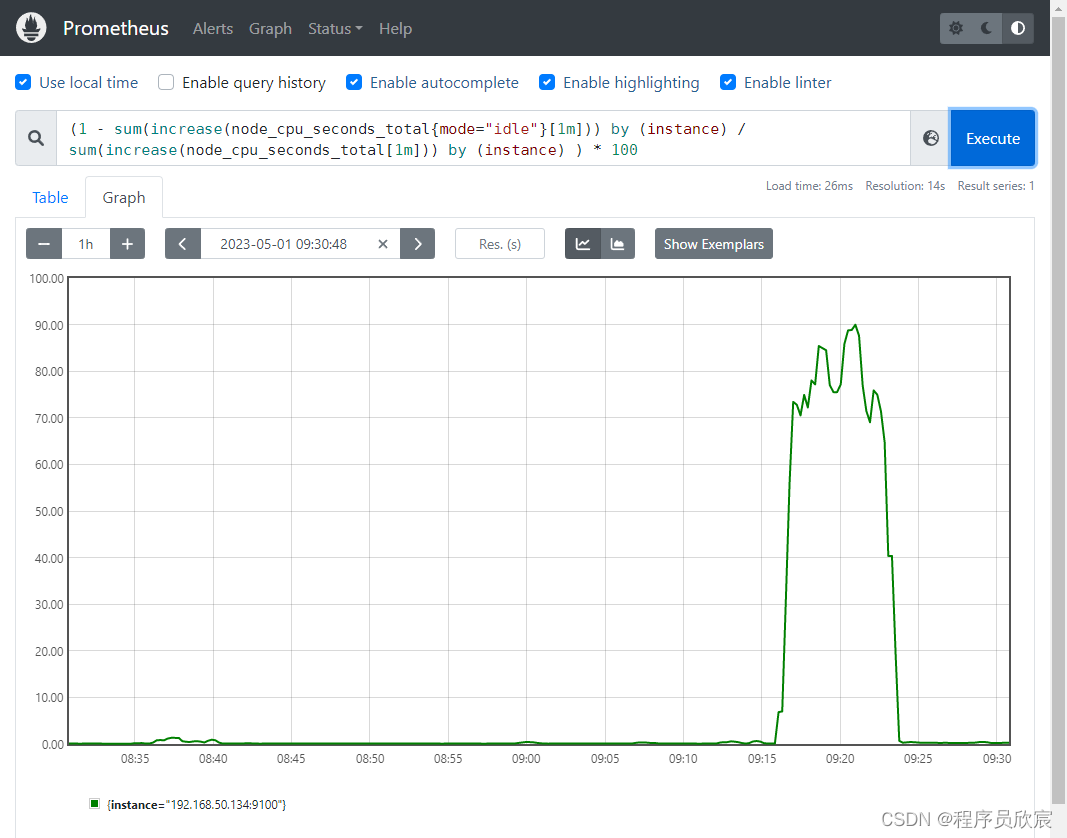
(1 - sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance) ) * 100
- 曲线图如下,与实际情况符合
- 另外,在计算idle时间的时候,刚才咱们用的是
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)
- 其实上述表达式还可以用下面这个替代,因为这里是有一个instance,所以可以不关注,这样就只剩下cpu这个标签没有处理了,用without相当于去掉了cpu这个维度
sum without(cpu) (increase(node_cpu_seconds_total{mode="idle"}[1m]))
可用内存
- 先来看常用的free命令,得到结果如下
free -mtotal used free shared buff/cache available
Mem: 31772 655 29065 1 2051 30653
Swap: 0 0 0
- 一般的,从应用程序视角来看,可用内存等于:free + buff + cache(这只是理论上的,实际上可能有较大出入)
- 再看看node_exporter上报的参数中,上述信息对应的指标分别是
- node_memory_Buffers_bytes
- node_memory_Cached_bytes
- node_memory_MemFree_bytes
- 基于上述条件,可用内存表达式就很简单了
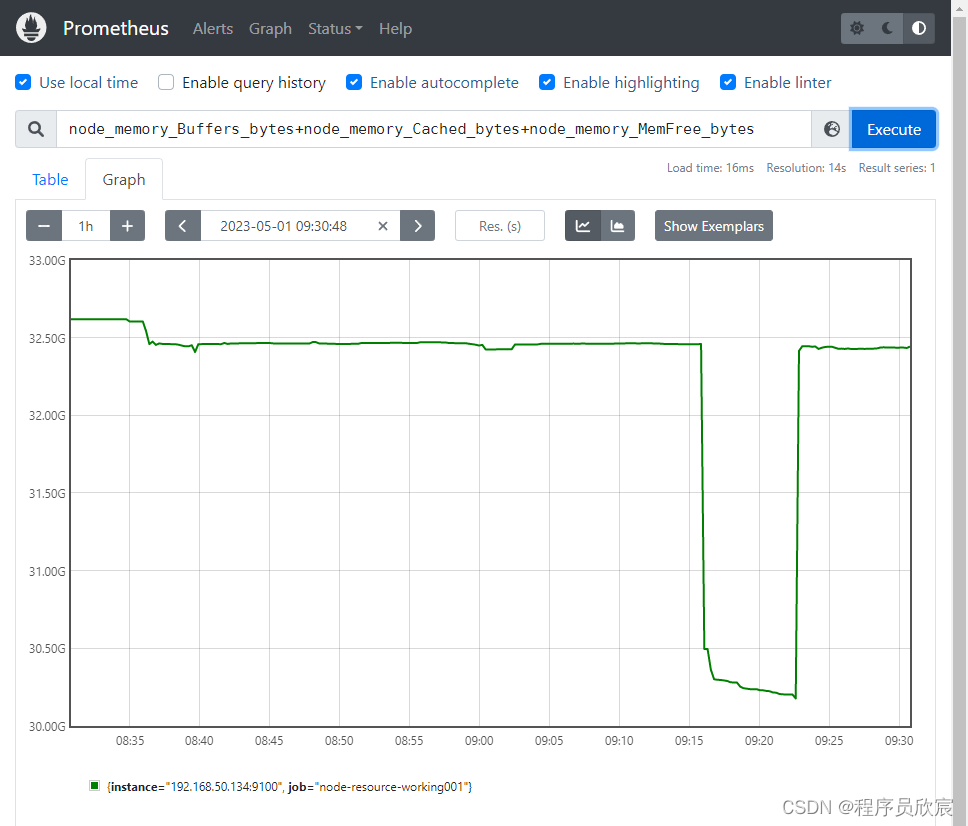
node_memory_Buffers_bytes+node_memory_Cached_bytes+node_memory_MemFree_bytes
- 效果如下图,09:30时候那个凹坑对应的是ffmpeg转码的时间,正好消耗了较多内存,导致可用内存降低
- 总内存的指标是node_memory_MemTotal_bytes,有了这四个参数,计算内存使用率也就很简单了,参考CPU使用率的做法,这里就不赘述了
磁盘使用率
- 先用df命令看一下应用服务器磁盘空间情况,如下所示,需要重点关注的是/dev/mapper/ubuntu–vg-ubuntu–lv
df -h
Filesystem Size Used Avail Use% Mounted on
udev 16G 0 16G 0% /dev
tmpfs 3.2G 1.5M 3.2G 1% /run
/dev/mapper/ubuntu--vg-ubuntu--lv 935G 26G 871G 3% /
tmpfs 16G 0 16G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 16G 0 16G 0% /sys/fs/cgroup
/dev/nvme0n1p2 1.5G 210M 1.2G 16% /boot
/dev/loop0 64M 64M 0 100% /snap/core20/1828
/dev/nvme0n1p1 1.1G 6.1M 1.1G 1% /boot/efi
/dev/loop1 68M 68M 0 100% /snap/lxd/21835
/dev/loop2 92M 92M 0 100% /snap/lxd/24061
/dev/loop3 54M 54M 0 100% /snap/snapd/18933
/dev/loop4 64M 64M 0 100% /snap/core20/1852
/dev/loop5 50M 50M 0 100% /snap/snapd/18596
overlay 935G 26G 871G 3% /var/lib/docker/overlay2/a63fc1b19c2ced0053ed406ae065f7f5db5ccc82801967d3ed89a17a22886120/merged
tmpfs 3.2G 0 3.2G 0% /run/user/0
- 计算磁盘使用率要用到两个指标
- node_filesystem_avail_bytes:磁盘可用空间
- node_filesystem_size_bytes:磁盘总空间
- 基于上述指标以及过滤标签device,得到磁盘空间使用率
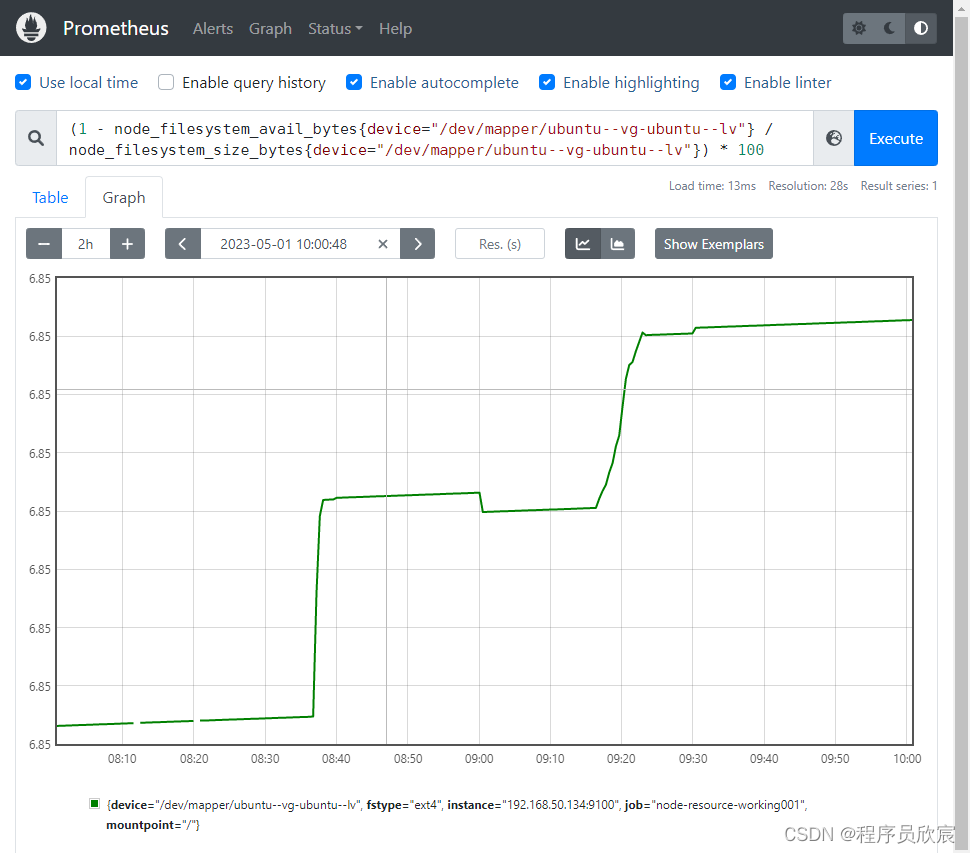
(1 - node_filesystem_avail_bytes{device="/dev/mapper/ubuntu--vg-ubuntu--lv"} / node_filesystem_size_bytes{device="/dev/mapper/ubuntu--vg-ubuntu--lv"}) * 100
- 效果如下图,由于ffmpeg转码时生成了新的视频文件,导致磁盘使用率变大,这是符合实际情况的
磁盘IO
- 磁盘IO有两个指标
- node_disk_read_bytes_total:读IO
- node_disk_writes_completed_total:写IO
- 由于ffmpeg转码新增了一个视频文件,因此写IO会有明显增长,下面这个表达式反映了平均每秒的磁盘写入量
rate(node_disk_writes_completed_total[5m])
-
如下图,有多个磁盘的数据
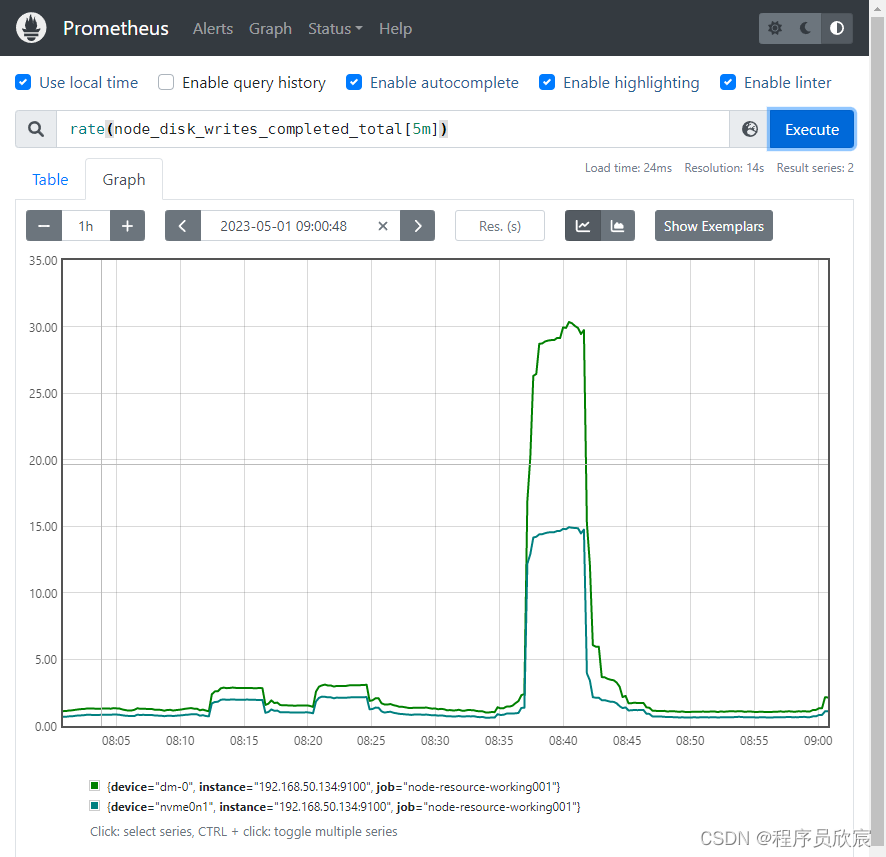
-
如果想看每个机器上的总磁盘写入量,可以同时使用sum和by来完成,by与SQL的group by类似,group by的数据可以做聚合操作,求和正是其中之一,也就是这里的sum
sum by (instance) (rate(node_disk_writes_completed_total[5m]))
- 效果如下图,每个实例的所有写操作被累加在一起
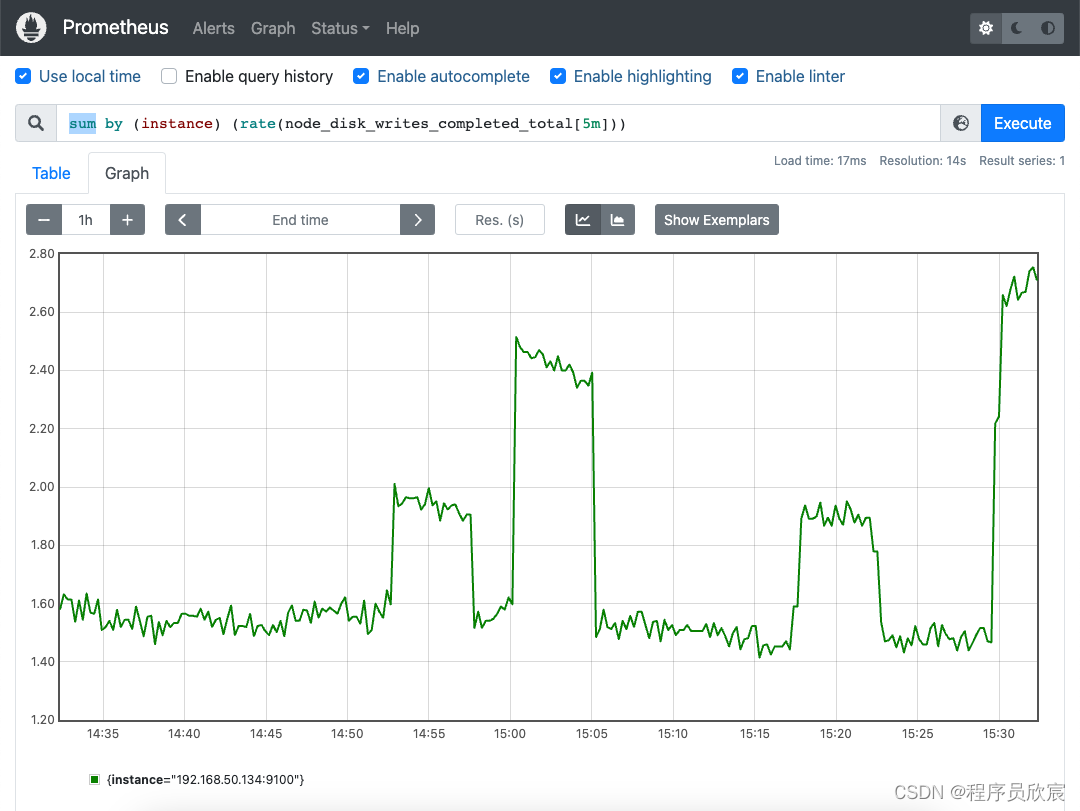
网络IO
- 网络IO相关的两个重要指标
- node_network_receive_bytes_total:收到的字节数,count型
- node_network_transmit_bytes_total:发出的字节数,count型
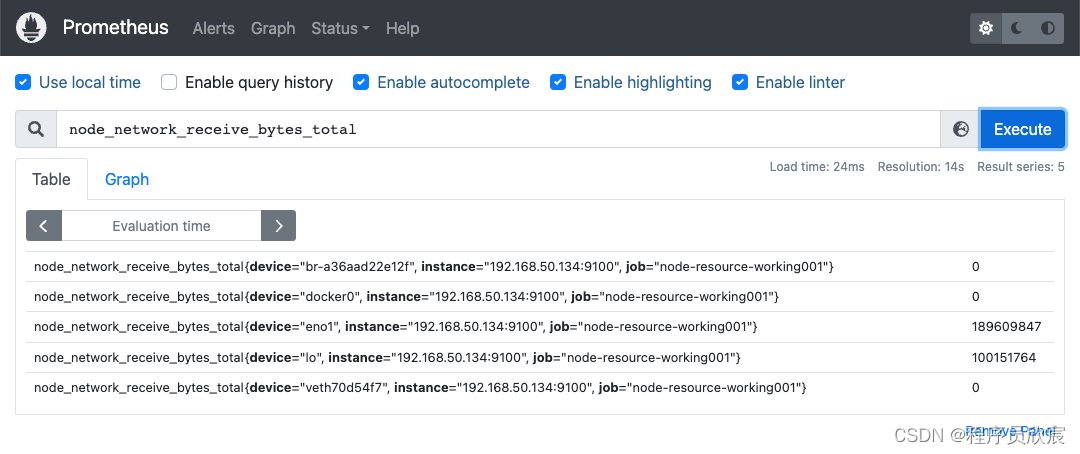
- 先看node_network_receive_bytes_total的原始数据,如下图,可见有多个网卡的数据,如果只想观察实际接受的字节数,需要用device这个label将回环网卡和虚拟网卡剔除
- 另外,对于网络IO而言,我们更关注瞬时情况,而非某个时间段的平均情况,这时候用rate就不合适了,建议使用irate函数,它用的是区间内最后两个点来计算(rate是用所有点),表达式如下
sum by (instance)(irate (node_network_receive_bytes_total[1m]))
- 对于的图形如下,应用服务器的网络IO读速率
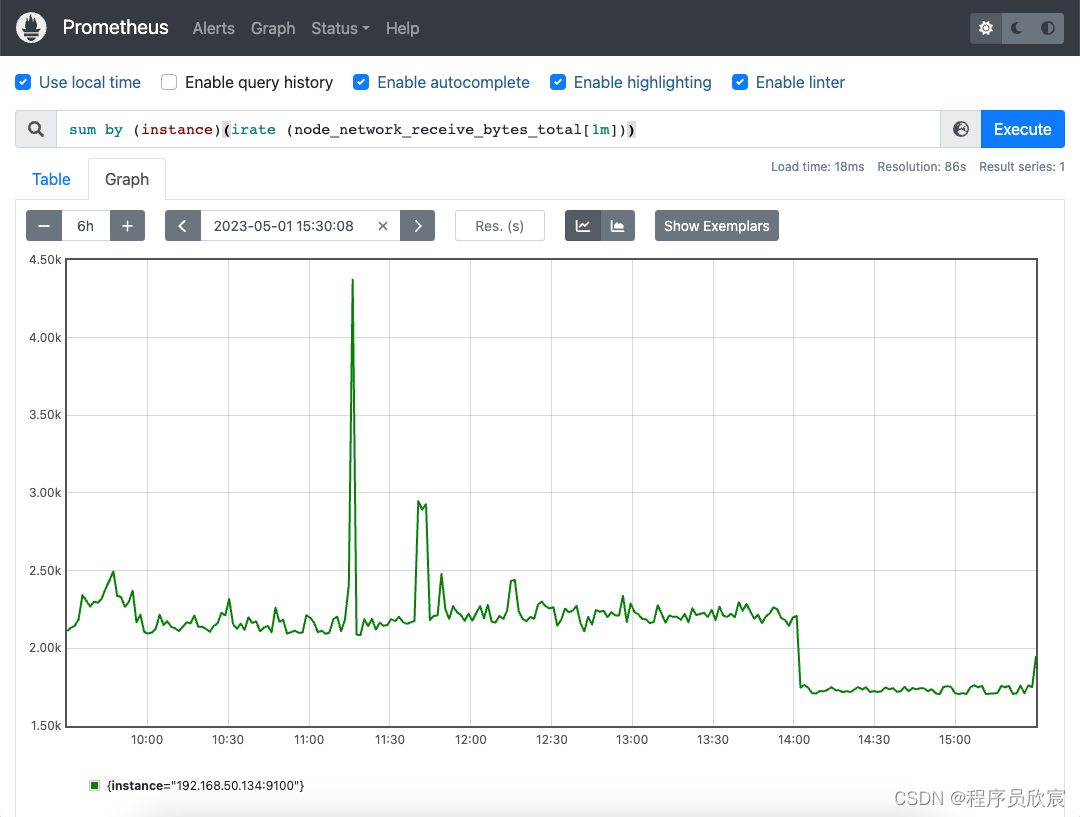
- 写速率用指标node_network_transmit_bytes_total,表达式与读类似
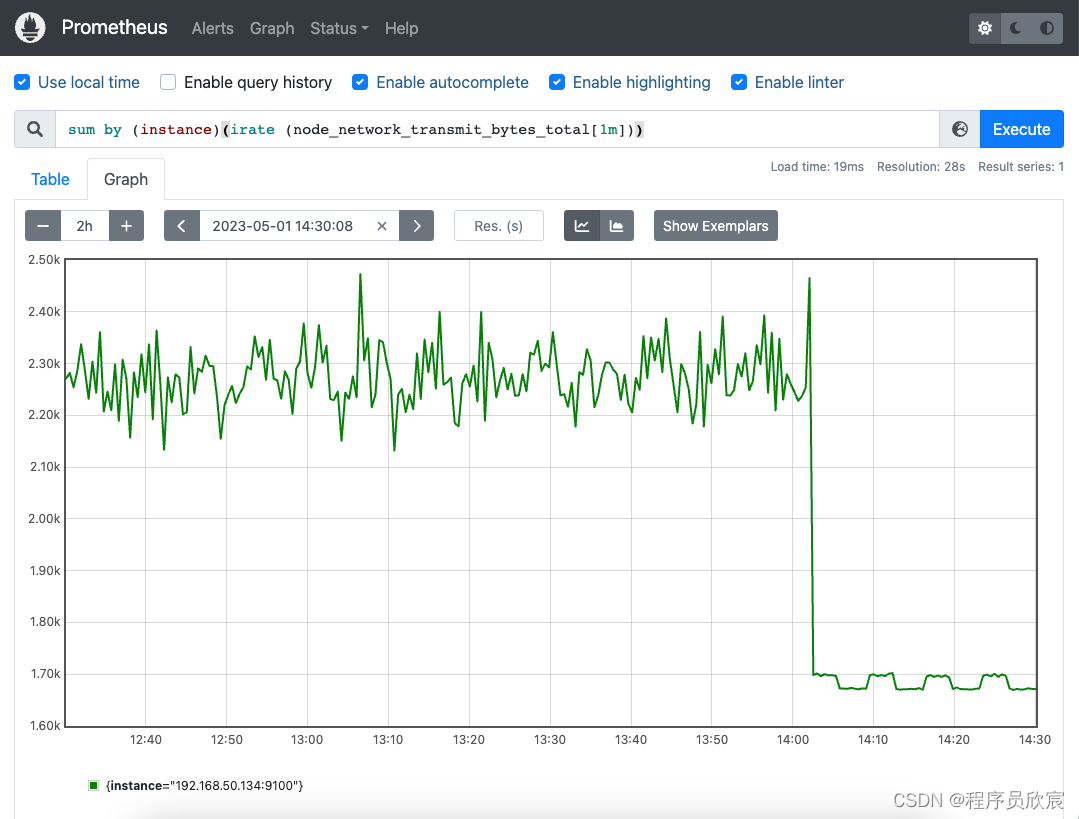
sum by (instance)(irate (node_network_transmit_bytes_total[1m]))
- 图形效果如下
- 至此,最初级的指标操作已经完成,相信您对prometheus已经有了初步的了解,接下来的文章,咱们会继续深入学习
你不孤单,欣宸原创一路相伴
- Java系列
- Spring系列
- Docker系列
- kubernetes系列
- 数据库+中间件系列
- DevOps系列