1.SPI
SPI全称Service Provider Interface,服务提供方接口,是Java提供的一套用来被第三方实现或者扩展的API,它可以用来启用框架扩展和替换组件。服务通常指一个接口或者一个抽象类,服务提供方是对这个接口或者抽象类的具体实现,由第三方来实现接口提供具体的服务。SPI其实就是为某个接口寻找服务的机制,它将装配的控制权移交给ServiceLoader,使用ServiceLoader去加载接口对应的实现,这样开发者就可以不用关注实现类。
开发中有时一个接口可能有多种实现方式,如果将特定实现写死在代码里面,那么要更换实现的时候就要改动代码,对原有代码进行重写,这样非常麻烦,而且也容易导致bug。使用SPI可以对接口的实现进行动态替换,即动态加载实现类。
SPI在模块开发中会比较有用,不同的模块可以基于接口编程,每个模块有不同的接口实现类,然后通过SPI机制自动注册到一个配置文件中,就可以实现在程序运行时扫描加载同一接口的不同实现类,从而实现跨模块通信。这样模块之间不会基于实现类硬编码,可插拔。
SPI整体机制如下:
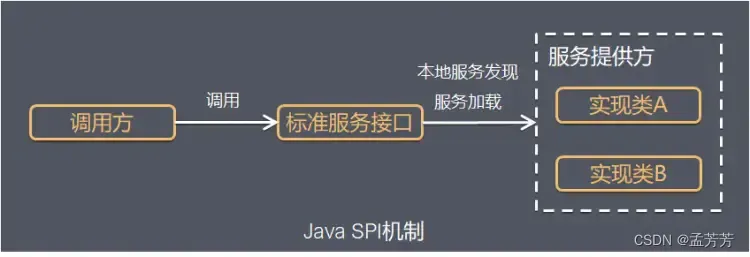
Java SPI 实际上是“基于接口的编程+策略模式+配置文件”组合实现的动态加载机制。模块之间基于接口编程,每个模块有不同的实现service provider,然后通过SPI机制自动注册到一个配置文件中,就可以实现在程序运行时扫描加载同一接口的不同service provider。这样模块之间不对实现类进行硬编码,实现解耦,而且实现可插拔替换。
2.SPI使用示例
SPI使用步骤:
①定义一个接口文件;
②写出多个该接口文件的实现;
③在src/main/resources/下新建/META-INF/services目录, 新增一个以接口命名的文件 , 文件内容是该接口的实现类全路径;
④使用ServiceLoader类查找这些接口的实现类。
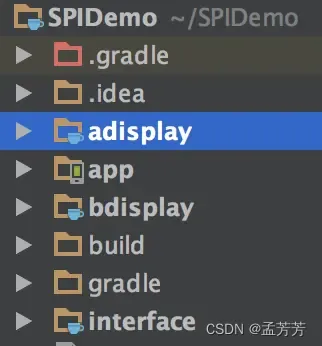
通过例子看一下SPI在Android中的应用。先看工程结构图,有四个模块,一个是app主程序模块,一个是接口interface模块,另外两个就是接口的不同实现模块adisplay和bdisplay。
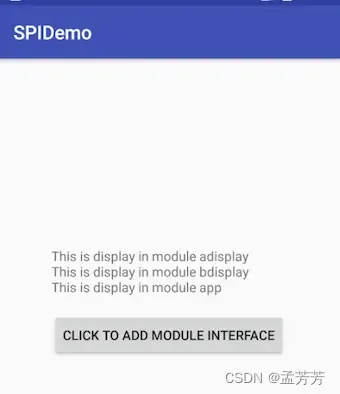
要实现的功能很简单,就是点击按钮,加载不同模块实现的方法,如下图所示:
①接口
首先是模块之间通信接口的实现,这里单独抽出一个模块interface,后面接口的不同实现模块可以都依赖同一个接口模块。
接口里面就是一个简单的方法:
package com.example;
public interface Display {
String display();
}
②模块实现
接下来就是用不同的模块实现接口,首先需要在模块的build.gradle中加入接口的依赖:
dependencies {
compile fileTree(include: ['*.jar'], dir: 'libs')
compile project(':interface')
}
然后写一个简单的实现类实现接口Display。adisplay模块的实现类就是ADisplay.java:
package com.example;
public class ADispaly implements Display{
@Override
public String display() {
return "This is display in module adisplay";
}
}
bdisplay模块的实现类就是BDisplay.java:
package com.example;
public class BDisplay implements Display{
@Override
public String display() {
return "This is display in module bdisplay";
}
}
然后要把这些接口实现类注册到配置文件中,SPI的机制就是注册到META-INF/services中。首先在java的同级目录中new一个包目录resources,然后在resources新建一个目录META-INF/services,再新建一个file,file的名称就是接口的全限定名,在该例子中就是:com.example.Display,文件中的内容就是不同实现类的全限定名,不同实现类分别一行。
adisplay模块最后的工程结构如下图所示。文件com.example.Display中的内容就是ADispaly实现类的全限定名com.example.ADispaly。
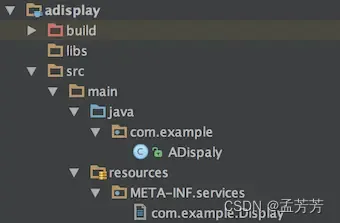
bdisplay模块的工程结构和上图类似,文件com.example.Display中的内容就是BDisplay实现类的全限定名com.example.BDisplay。
③加载不同服务
当然在主程序模块中也可以有自己的接口实现:
package com.example.spidemo;
import com.example.Display;
public class DisplayImpl implements Display {
@Override
public String display() {
return "This is display in module app";
}
}
在配置文件com.example.Display中的内容就是com.example.juexingzhe.spidemo.DisplayImpl。
在界面上放置一个按钮,点击按钮会加载所有模块配置文件中的实现类:
mButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
loadModule();
}
});
关键的代码其实就是下面三行,通过ServiceLoader来加载接口的不同实现类,然后会得到迭代器,在迭代器中可以拿到不同实现类全限定名,然后通过反射动态加载实例就可以调用display方法了。
ServiceLoader<Display> loader = ServiceLoader.load(Display.class);
mIterator = loader.iterator();
while (mIterator.hasNext()){
mIterator.next().display();
}
注意:这种方法在平常组件化开发中非常便利,但是每次都需要到/META-INF/services目录建立文件,不能动态添加。因此可以采用Google的@AutoService,它可以在编译的时候动态生成这些东西。ServiceLoader + @AutoService的使用方法如下:
①添加AutoService依赖
implementation 'com.google.auto.service:auto-service:1.0'
annotationProcessor 'com.google.auto.service:auto-service:1.0'
②接口module不需要变,只需要在实现类进行改变一下即可:
@AutoService(Display.class)
public class ADispaly implements Display{
@Override
public String display() {
return "This is display in module adisplay";
}
}
只需要在具体的实现类上面加上一个@AutoService注解,参数则为接口的class类。
③最后在App模块中调用
ServiceLoader<Display> loader = ServiceLoader.load(Display.class);
mIterator = loader.iterator();
while (mIterator.hasNext()){
mIterator.next().display();
}
注意:由于组件隔离了,其他模块除了依赖基础base库,是不能调用主模块和其他业务模块的。而SPI可以实现业务模块调用主模块的功能。在其他模块调用主模块:
ServiceLoader<Display> loader = ServiceLoader.load(Display.class);
Iterator<Display> mIterator = loader.iterator();
while (mIterator.hasNext()){
Display next = mIterator.next();
if(next.getClass().getSimpleName().equals( "DisplayImpl")) {
mIterator.next().display();
}
}
这样就走了app模块里的方法了,实现了跨组件通信。
3.源码分析
主要工作都是在ServiceLoader类中,这个类在java.util包中。ServiceLoader是一个简单的服务提供者加载工具,先看下几个重要的成员变量:
public final class ServiceLoader<S> implements Iterable<S> { //S 范型,就是指定的接口,实现了迭代器接口
private static final String PREFIX = "META-INF/services/"; //PREFIX是配置文件所在的包目录路径
private Class<S> service; //service是接口名称,在上面的例子中就是Display
private ClassLoader loader; //loader是类加载器,其实最终都是通过反射加载实例
private LinkedHashMap<String,S> providers = new LinkedHashMap<>(); //providers是不同实现类的缓存,key是实现类的全限定名,value是实现类的实例
private LazyIterator lookupIterator; //lookupIterator是懒加载的迭代器,是内部类LazyIterator的实例
}
使用SPI的三个关键步骤:
ServiceLoader<Display> loader = ServiceLoader.load(Display.class);
mIterator = loader.iterator();
while (mIterator.hasNext()) {
mIterator.next().display();
}
①第一个步骤ServiceLoader.load()
ServiceLoader提供了两个静态的load方法,如果没有传入类加载器,ServiceLoader会自动获得一个当前线程的类加载器,最终都是调用构造函数。
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().ge tContextClassLoader();
return ServiceLoader.load(service, cl);
}
public static <S> ServiceLoader<S> load( Class<S> service,ClassLoader loader) {
return new ServiceLoader<>(service, loader);
}
在构造函数中工作很简单,就是清除实现类的缓存,实例化迭代器。
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = svc;
loader = cl;
reload();
}
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
其实ServiceLoader.load(Display.class)方法只是创建了LazyIterator、ServiceLoader和ClassLoader,并没有加载service provider,也就是懒加载的设计模式,这也是Java SPI的设计亮点。
那么service provider在什么地方进行加载?接着看第二个步骤loader.iterator(),其实就是返回一个迭代器。
②第二个步骤loader.iterator()
这个就是懒加载实现的地方,首先会到providers中去查找有没有存在的实例,有就直接返回,没有再到LazyIterator中查找。
public Iterator<S> iterator() {
return new Iterator<S>() {
Iterator<Map.Entry<String,S>> knownProviders = providers.entrySet().iterator(); //providers就是开始定义的不同接口实现类的缓存,获取到linkedhashmap的迭代器了
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
上面hasNext、next、remove的实现主要依赖knownProviders的实现,但从定义就知道他只是个缓存工具,具体还是要看lookupIterator的实现。
在hasNext()方法中,一开始knownProviders中是没有缓存实例的,knownProviders.hasNext()会返回false的,走lookupIterator.hasNext()方法,即会到LazyIterator中查找,去看看LazyIterator,先看下它的hasNext()方法:
public boolean hasNext() {
return hasNextService();
}
private boolean hasNextService() {
if (nextName != null) { //nextName定义的k-v
return true;
}
if (configs == null) { //是一个URL集合
try {
String fullName = PREFIX + service.getName(); //service就是传进来的接口的Class对象,fullName = META-INF/services/ + 接口全路径,所以定义的时候就是按照上面格式定义的文件
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources( fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
//这个循环条件中pending是待办的拦截器,第一次为null
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement()); //parse函数会返回String类型集合的迭代器,实际操作就是使用BufferedReader读取fullName配置文件里面的内容,这个配置文件是合并后的,包含所有模块下的fullName里面的内容,也就是实现接口类的实现类的全路径类名。配置文件千万不能写错,因为后面要用到反射
}
nextName = pending.next(); //pending会返回当前fullName对应的全路径包名字符串
return true;
}
首先拿到配置文件名fullName,上面的例子中是com.example.Display。然后通过类加载器获得所有模块的配置文件configs。接着依次扫描每个配置文件的内容,返回配置文件内容Iterator<String> pending,每个配置文件中可能有多个实现类的全限定名,所以pending也是个迭代器。
总结下hasNext方法的操作,就是根据全路径文件名,打开一个io流,读取里面配置,就是实现接口的实现类的全路径,返回一个包含全路径类名的String类型迭代器,迭代器存在值就返回true,并定义了nextName的值,方便nextService方法的调用。
在hasNext()方法中拿到的nextName就是实现类的全限定名,接下来看具体实例化工作的地方,即LazyIterator的next()方法:
public S next() {
return nextService();
}
private S nextService() {
if (!hasNextService()) {
throw new NoSuchElementException();
}
String cn = nextName; //拿到hasNextService找到的实现类路径
nextName = null; //再清空,方便下次处理
Class<?> c = null;
try {
c = Class.forName(cn, false, loader); //根据全路径反射获取Class
} catch (ClassNotFoundException x) {
fail(service, "Provider " + cn + " not found", x);
}
try {
S p = service.cast(c.newInstance()); //调用newInstance创建实例
providers.put(cn, p); //放入缓存
return p;
} catch (Throwable x) {
fail(service, "Provider " + cn + " could not be instantiated: " + x, x);
}
throw new Error(); // This cannot happen
}
首先根据nextName,通过Class.forName加载拿到具体实现类的class对象。然后通过Class.newInstance()实例化拿到具体实现类的实例对象。接着将实例对象通过service.cast转化为service接口。并通过providers.put(cn, p)将实例对象放到缓存中,其中key是实现类的全限定名,value是实例对象。最后返回实例对象。
这里用到的主要思想其实就是懒加载的思想。通过LazyIterator类获取META-INF/services/目录下接口对应的文件,并读取里面的继承类名,然后通过类实例化返回,最终就可以获取到接口对应的实现的子类了。
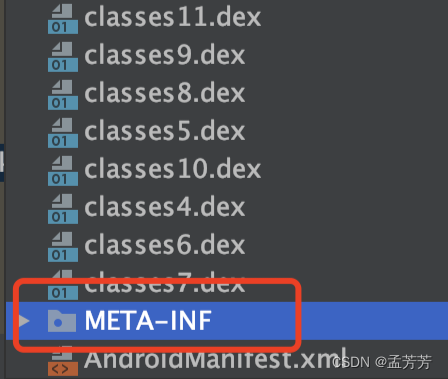
有一点可能不理解,为啥能读到不同模块下配置的路径名,其实在app运行是会有合并操作的,各模块下根据路径合并的。这里分析apk文件可以看出:
4.SPI机制的优缺点
①优点
SPI只提供服务接口,具体服务由其他组件实现,接口和具体实现分离,同时能够通过系统的ServiceLoader得到这些实现类的集合,统一处理。
SPI机制可以实现不同模块之间方便的面向接口编程,拒绝了硬编码的方式,解耦效果很好。用起来也简单,只需要在目录META-INF/services中配置实现类就行。源码中也用来了懒加载的思想,开发中可以借鉴。
②缺点
通过Java的SPI机制有一个缺点就是在运行时通过反射加载类实例,这个对性能会有点影响。