实际开发时抓取到的诸多数据如何保存是一个关键问题,MongoDB 相比传统关系型数据库(比如mysql)来说灵活度更高,爬虫时字段格式及数量很可能会随着需求或实际数据的变动而改变,因此 MongoDB 作为数据库来说最合适不过了。
目录
1 MongoDB
1.1 介绍
1.2 可视化工具
① Robo 3T(推荐)
③ Pycharm 专业版
2 pymongo 使用
2.1 pymongo 介绍
2.2 连接及指定数据库和集合
① 连接 MongoDB
② 指定数据库和集合
2.3 增删改查
① 插入数据
② 删除数据
③ 修改数据
④ 查询数据
2.4 pymongo 版本< 4.0 之异同
① < 4.0 权限认证
② < 4.0 插入数据
② < 4.0 删除数据
③ < 4.0 更新数据
1 MongoDB
1.1 介绍
官方文档:Introduction to MongoDB — MongoDB Manual
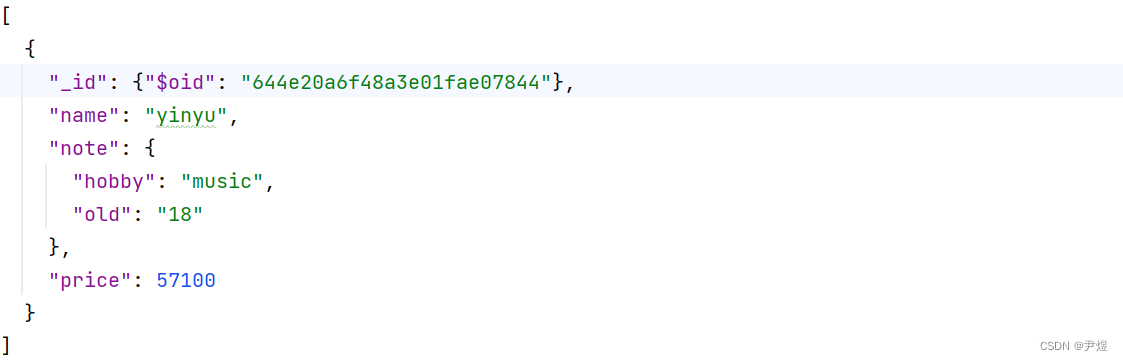
MongoDB 是一种流行的 NoSQL 数据库,也就是非关系型数据库,使用文档存储数据(简单来说就是 json 格式,如下图👇),而不是传统的关系型数据库中的行和表。总之,MongoDB 具有高度的可扩展性和灵活性,可以用于各种类型的应用程序。
然后简单介绍下 MongoDB 的结构,和 mysql 一样,MongoDB Server(实例)下紧接着就是数据库(db),但是数据库下边紧跟着的是集合(Collection) ,集合就是存储文档数据的单位。

本文我连接的是云服务器上的 MongoDB,当时通过 Docker 安装启动,有想了解的可以看一下这篇文章的第一部分即可 👇,至于本地 MongoDB 的安装配置,本文就不赘述了,网上教程蛮多,
Spring 03:云服务器 Docker 环境下安装 MongoDB 并连接 Spring 项目实现简单 CRUD
1.2 可视化工具
介绍以下几种 MongoDB GUI 可视化客户端管理工具:
① Robo 3T(推荐)
Robo 3T 前身是 Robomongo,后被 3T 公司收购,是一款免费开源的 GUI 管理工具。支持 MongoDB 4.0+,轻量级 GUI,支持语法填充等等,目前与 Studio 3T 合并。
下载地址:Robo 3T | Free, open-source MongoDB GUI
② Navicat for MongoDB
Navicat 拓展开发用于管理 MongoDB 的工具,属于付费型管理工具,好处是用会了一个 DB 版的 Navicat,如果 Navicat 用习惯的话会比较顺手。
下载地址:Navicat | 下载 Navicat for MongoDB
③ Pycharm 专业版
最新版的 Pycharm(IDEA 等) 已支持 MongoDB 乃至 Redis,可以说提供了很大方便。
本文是使用最后一种方式进行 MongoDB 的管理可视化。
2 pymongo 使用
2.1 pymongo 介绍
简单来说,pymongo 提供了一组简单而强大的 API,可以用于连接,查询和操作 MongoDB 数据库。
- 官方地址:pymongo · PyPI
- 安装:pip install pymogo
本文 pymogo 的版本为4.1.1,若 pymogo 版本低于 4.0,认证和操作函数会有些不一致(后边会讲解)。
2.2 连接及指定数据库和集合
① 连接 MongoDB
本地连接,无需权限认证:
以下是本地连接的两种方式,本地一般不设置账户密码,直接连接就行,27017是端口,localhost 也可替换为 127.0.0.1。
from pymongo import MongoClient# 本地连接
client = MongoClient("mongodb://localhost:27017") #方式1
client = MongoClient('localhost',27017) #方式2远程连接:需要权限认证:
远程连接则需要配置账户密码了,有下边两种方式,pymongo 4.0版本之前的稍不一样,在 2.4 章节有解释。
from pymongo import MongoClient# 远程连接
client = MongoClient("mongodb://root:root@x.x.x.x:27017") #方式1
client = MongoClient("x.x.x.x", 27017, username="root", password="xxx") #方式2② 指定数据库和集合
连接数据库后便是获取数据库和指定集合,“yinyudb”即数据名,“yinyucol”即集合名,集合是数据操作的基本单位,建议使用方式1,因为方式一返回的 col 能自动弹出实例的方法,而方式二不行。
#获取数据库
db = client['yinyudb'] #方式1
db = client.yinyudb #方式2#指定集合
col = db['yinyucol'] #方式1
col = db.yinyucol #方式2
2.3 增删改查
① 插入数据
注意,此时 MongoDB 中并没有创建“yinyudb”这个数据库,当然也就没用“yinyucol”这个集合,而使用 pymongo 指定数据库+集合,插入数据后便会自动生成“yinyudb”数据库和“yinyucol”集合,这便是 MongoDB 的高度灵活性。
增加一条:
#增加一条
car = {'name': 'Audi', 'price': 52642}
result = col.insert_one(car)
print(result.inserted_id) # insert_one方法返回的是InsertOneResult对象,我们可以调用其inserted_id属性获取_id。
#输出:644e5cd69616930ff53dd95b增加多条:
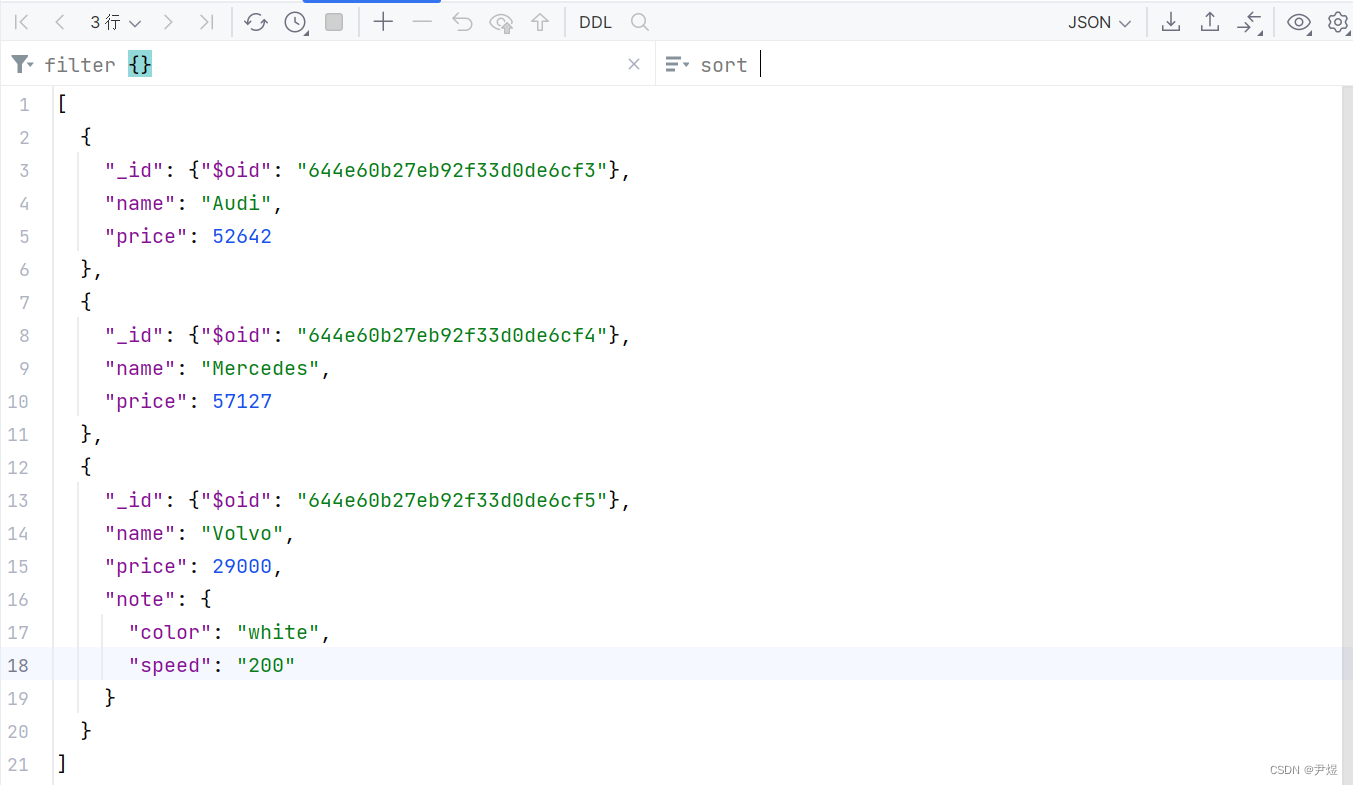
#增加多条
cars = [{'name': 'Mercedes', 'price': 57127},{'name': 'BYD', 'price': 29000, 'note':{'color': 'white', 'speed':'200'}}]
result = col.insert_many(cars) #中括号(集合)包裹json文档
print(result.inserted_ids) # insert_many()方法返回的类型是InsertManyResult,调用inserted_ids属性可以获取插入数据的_id列表
#输出:[ObjectId('644e5cd69616930ff53dd95c'), ObjectId('644e5cd69616930ff53dd95d')]通过可视化工具查看 👇
② 删除数据
delete_one 和 delete_many 返回的类型是 deleted_result,此时可以使用 raw_result 获取删除结果,返回删除数量('n')和操作状态('ok'),也可以使用 deleted_count,那么只会返回删除数量。
删除一条:
# 删除一个
result = col.delete_one({'name': 'Mercedes'})
print(result.raw_result)
# 输出:{'n': 1, 'ok': 1.0}删除多条:
# 删除多个
result = col.delete_many({'price': {'$lt': 55000}})
print(result.raw_result)
# 输出:{'n': 2, 'ok': 1.0}注:如果数据库中已不存在需要删除的数据,那么该删除操作也不会报错,删除数量将是0。
③ 修改数据
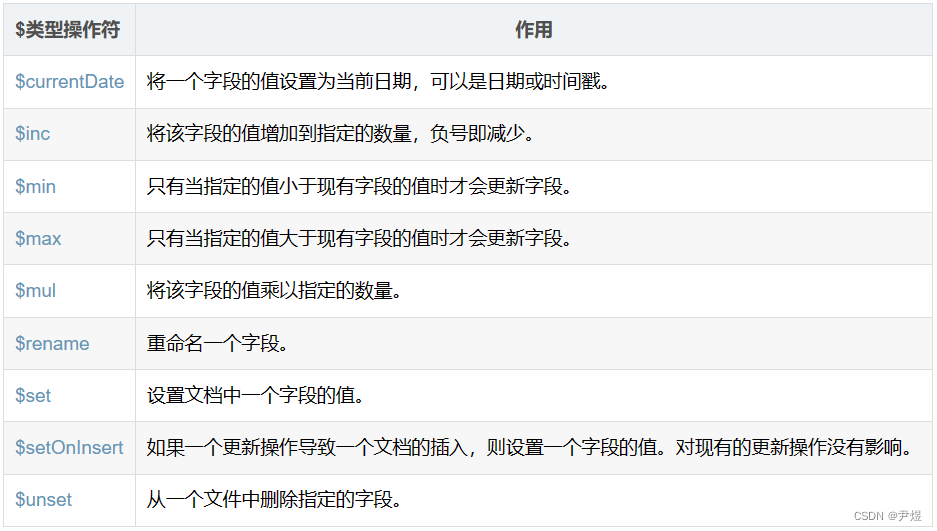
修改数据就会特殊一点,需要用到 $ 类型操作符,比如 $set 是设置,既可修改字段,也可新增字段。主要有以下 $ 类型操作符(官方地址:Field Update Operators — MongoDB Manual)👇
修改一条:
#修改一个,第2个参数需要使用$类型操作符作为字典的键名
#目标1:姓名为Mercedes的记录,price修改为80000
condition = {'name': 'Mercedes'}
res = col.find_one(condition)
res['price'] = 80000
result = col.update_one(condition, {'$set': res})
print(result.raw_result) #返回结果是UpdateResult类型
#输出:{'n': 1, 'nModified': 1, 'ok': 1.0, 'updatedExisting': True}
print(result.matched_count,result.modified_count) #获得匹配的数据条数、影响的数据条数
#1 1#目标2:将pric高于60000的记录,price减500
condition = {'price': {'$gt':60000}} #若匹配到两条,也只会更新第一条
result = col.update_one(condition, {'$inc': {'price': -500}})
print(result.raw_result)
#输出:{'n': 1, 'nModified': 1, 'ok': 1.0, 'updatedExisting': True}修改多条:
# 修改多个
#目标:将pricd低于60000的记录,price都加500
condition = {'price': {'$lt':60000}}
result = col.update_many(condition,{'$inc': {'price': 500}})
print(result.raw_result)
#{'n': 2, 'nModified': 2, 'ok': 1.0, 'updatedExisting': True}④ 查询数据
查询数据的话我们可以通过 find_one() 或 find() 方法,find_one() 查询得到是单个结果,find() 则返回多个结果(查询可就没有 find_many() 方法了)。
查询所有:
#若无入参,默认返回所有的数据
for i in col.find():print(i)
#{'_id': ObjectId('644e669757fdbcff71f7e3fd'), 'name': 'Audi', 'price': 52142}
# {'_id': ObjectId('644e669857fdbcff71f7e3fe'), 'name': 'Mercedes', 'price': 79500, 'note': '备注'}
# {'_id': ObjectId('644e669857fdbcff71f7e3ff'), 'name': 'Volvo', 'price': 29500, 'note': {'color': 'white', 'speed': '200'}}
查询一条:
#查询一条
#根据name字段查询
result = col.find_one({"name": "Mercedes"})
print(result) #返回字典
#{'_id': ObjectId('644e669857fdbcff71f7e3fe'), 'name': 'Mercedes', 'price': 79500, 'note': '备注'}#直接根据ObjectId来查询,这里需要使用bson库里面的ObjectId。
from bson.objectid import ObjectId
result = col.find_one({'_id': ObjectId('644e669757fdbcff71f7e3fd')})
print(result)
#{'_id': ObjectId('644e669757fdbcff71f7e3fd'), 'name': 'Audi', 'price': 52142}查询多条:
#多条查询
#查询price低于60000的记录
results = col.find({'price':{'$lt': 60000}})
for i in results: #返回是集合,所以遍历print(i)
#{'_id': ObjectId('644e669757fdbcff71f7e3fd'), 'name': 'Audi', 'price': 52142}
# {'_id': ObjectId('644e669857fdbcff71f7e3ff'), 'name': 'Volvo', 'price': 29500, 'note': {'color': 'white', 'speed': '200'}}#逻辑符号:查询price大于50000,同时name为Mercedes的记录
results = col.find({'$and':[{'price':{'$gt': 50000}},{'name':"Mercedes"}]})
for i in results: #返回是集合,所以遍历print(i)
#{'_id': ObjectId('644e669857fdbcff71f7e3fe'), 'name': 'Mercedes', 'price': 79500, 'note': '备注'}#通过正则表达式查询name以A开头的记录
results = col.find({'name':{'$regex': '^A.*'}})
for i in results:print(i)
#{'_id': ObjectId('644e669757fdbcff71f7e3fd'), 'name': 'Audi', 'price': 52142}计数:
统计查询结果有多少条数据,col.find().count() 方法已被弃用,如果是所有数据条数,使用estimated_document_count(),如果是条件查询的数量,使用 count_documents。
#计数
#统计所有数据条数
count = col.estimated_document_count()
print(count)
#3# #查询price低于60000的记录数量
count = col.count_documents({'price':{'$lt': 60000}})
print(count)
#2排序:
import pymongo#排序,查询所有记录并按price逆序
results = col.find().sort('price', pymongo.DESCENDING)
print([i['price'] for i in results])
#[79500, 52142, 29500]限制:
#限制,只取前两个
results = col.find().sort('price', pymongo.DESCENDING).limit(2)
print([i['price'] for i in results])
#[79500, 52142]具体符号的使用方式可在下边地址中进行查看!
符号官方地址:Query and Projection Operators — MongoDB Manual
比较符号:

逻辑符号:

功能符号:

2.4 pymongo 版本< 4.0 之异同
pymongo 版本介于 4.0 前后主要有以下两方面的区别:
① < 4.0 权限认证
client = pymongo.MongoClient("127.0.0.1", 27017)
admin = client.get_database("admin") # 连接所需数据库
admin.authenticate("root", "root")4.0 之前也可通过 authenticate 这个方法进行权限认证,4.0 之后就去掉了,和IP地址、端口放一起~
② < 4.0 插入数据
cars = [{'name': 'Mercedes', 'price': 57127},{'name': 'Volvo', 'price': 29000, 'note':{'color': 'white', 'speed':'200'}}]
col.insert(cars) #中括号(列表)包裹json文档4.0 之前也可以使用 insert() 方法执行插入数据(单个+批量),但是 4.0 之后该方法就不再被支持了,只能使用 insert_one() 和 insert_many()。
② < 4.0 删除数据
result = col.remove({'name': 'Mercedes'})4.0 之前也可以使用 remove() 方法执行删除数据(单个+批量),但是 4.0 之后该方法就不再被支持了,只能使用 delete_one() 和 delete_many()。
③ < 4.0 更新数据
#将pric高于60000的记录,price减500
condition = {'price': {'$gt':60000}}
result = col.update(condition, {'$inc': {'price': -500}})4.0 之前也可以使用 update() 方法执行更新数据(单个+批量), 4.0 之后该方法就不再被支持了。