一、分词简介
1.基本概念
分词是自然语言处理中的一个重要步骤,它可以帮助我们将文本分成一个个词语,以便更好地理解和分析文本。在计算机视觉、语音识别、机器翻译等领域,分词都扮演着重要的角色。
目前,常用的分词库包括 jieba、pyjieba、wordcloud、pkuseg(本次使用)等。这些库提供了丰富的功能,例如可以对文本进行分词、词性标注、命名实体识别等,可以方便地集成到其他自然语言处理任务中。
2.pkuseg介绍
pkuseg 是一个基于 Python 的自然语言处理库,主要用于情感分析、文本分类、命名实体识别等任务。该库由日本庆应大学开发,并于 2018 年公开发布。
pkuseg 库采用了深度学习技术,使用了预训练的神经网络模型,可以自动从大量的文本数据中学习到正确的分词模式和特征。因此,相对于传统的分词库,pkuseg 库的分词精度更高,并且可以处理更长的文本。
pkuseg 库提供了多种情感分析算法,包括基于规则、基于机器学习和基于深度学习的方法。同时,该库还支持文本分类和命名实体识别等任务,可以使用单分类、多分类、支持向量机、朴素贝叶斯等算法进行训练和预测。
pkuseg 库的优点是速度快、精度高,并且可以处理多种语言。此外,该库还提供了易于使用的 API,使用户可以更加方便地集成到自己的项目中。
二、依赖安装
1、pkuseg安装
在安装之前如果pip版本过低可能也会照成安装错误,所以在安装前可以更新一下pip:
python.exe -m pip install --upgrade pippython.exe为你的解释器路径
注意
安装pkuseg库需要使用python3.8。
第一次运行 会下载相关模型文件。若下载失败可到提示的github网址自行下载,或使用外网运行。
2、ddparser安装
本次安装的依赖有:
LAC==2.1.2 是一个用于自然语言处理的库,提供了多种自然语言处理任务的解决方案,例如文本分类、情感分析、命名实体识别等。该库使用深度学习技术,支持使用预训练模型和自定义模型,支持多种自然语言处理任务,并且提供了易于使用的 API。
paddlepaddle==2.4.0 是一个基于 Python 的自然语言处理库,提供了丰富的自然语言处理算法和模型,包括文本分类、情感分析、命名实体识别、机器翻译等。该库采用了深度学习技术,支持使用预训练模型和自定义模型,并提供了易于使用的 API 和工具。
protobuf==3.20.0 是一个用于数据结构和二进制数据的交换格式的库,通常用于ddparser==1.0.8 是一个用于解析 XML 和 HTML 数据的库,通常用于数据可视化和 Web 应用程序。该库提供了多种解析算法和数据结构,例如 DOM、SAX、HTML parser 等,并且支持多种编程语言。
在安装相关依赖我们一般是选择从源镜像下载 这次我们选择的源为清华镜像相关指令为:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple安装LAC:
pip install --upgrade LAC==2.1.2安装paddlepaddle:
pip install --upgrade paddlepaddle==2.4.0安装protobuf:
pip install --upgrade protobuf==3.20.0安装ddparser:
pip install --upgrade ddparser==1.0.8三、代码运行
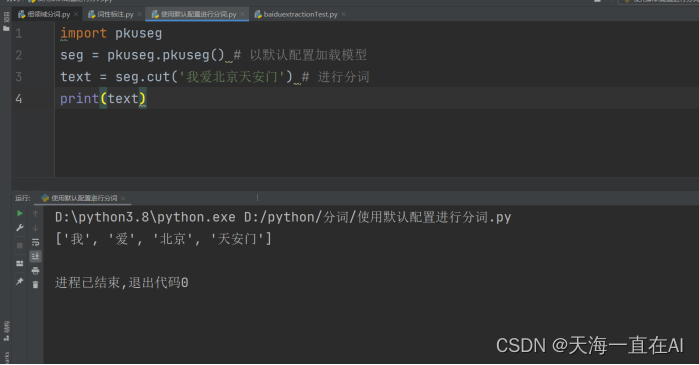
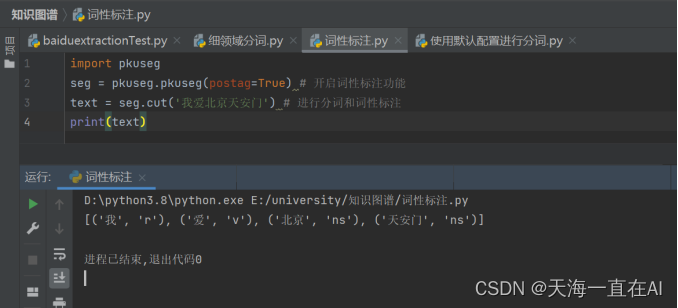
1、pkuseg基本使用
运行分词
词性标注
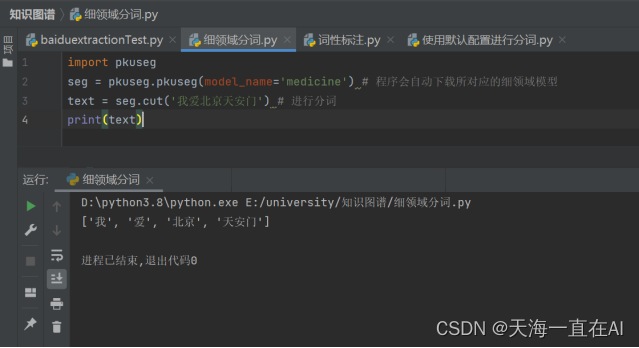
细领域分词
2、ddparser基本使用(代码为学校课程案例)
# encoding:utf-8
# 基于百度ddparser实现文本关系抽取
import os, re
from ddparser import DDParserclass SVOParser:def __init__(self):self.parser = DDParser(use_pos=True)print('loaded model')'''文章分句处理, 切分长句,冒号,分号,感叹号等做切分标识'''def split_sents(self, content):return [sentence for sentence in re.split(r'[??!!。;;::\n\r]', content) if sentence]'''句法分析---为句子中的每个词语维护一个保存句法依存儿子节点的字典'''def build_parse_child_dict(self, words, postags, rel_id, relation):child_dict_list = []format_parse_list = []for index in range(len(words)):child_dict = dict()for arc_index in range(len(rel_id)):if rel_id[arc_index] == index+1: #arcs的索引从1开始if rel_id[arc_index] in child_dict:child_dict[relation[arc_index]].append(arc_index)else:child_dict[relation[arc_index]] = []child_dict[relation[arc_index]].append(arc_index)child_dict_list.append(child_dict)heads = ['Root' if id == 0 else words[id - 1] for id in rel_id] # 匹配依存父节点词语for i in range(len(words)):# ['ATT', '李克强', 0, 'nh', '总理', 1, 'n']a = [relation[i], words[i], i, postags[i], heads[i], rel_id[i]-1, postags[rel_id[i]-1]]format_parse_list.append(a)return child_dict_list, format_parse_list'''parser主函数'''def parser_main(self, sentence):res = self.parser.parse(sentence, )[0]words = res["word"]postags = res["postag"]rel_id = res["head"]relation = res["deprel"]child_dict_list, format_parse_list = self.build_parse_child_dict(words, postags, rel_id, relation)return words, postags, child_dict_list, format_parse_list"""将所有的ATT进行合并"""def merge_ATT(self, words, postags, format_parse_list):words_ = wordsretain_nodes = set()ATTs = []ATT = []format_parse_list_ = []for parse in format_parse_list:dep = parse[0]if dep in ['ATT', 'ADV']:ATT += [parse[2], parse[5]]else:if ATT:body = ''.join([words[i] for i in sorted(set(ATT))])ATTs.append(body)retain_nodes.add(sorted(set(ATT))[-1])words_[sorted(set(ATT))[-1]] = bodyelse:retain_nodes.add(parse[2])ATT = []for indx, parse in enumerate(format_parse_list):if indx in retain_nodes:parse_ = [parse[0], words_[indx], indx, postags[indx], words_[parse[5]], parse[5], postags[parse[5]]]format_parse_list_.append(parse_)return words_, postags, format_parse_list_, retain_nodes"""基于该结果,提取三元组"""def extract(self, words, postags, child_dict_list, arcs, retain_nodes):svos = []for index in range(len(postags)):if index not in retain_nodes:continuetmp = 1# 如果语义角色标记为空,则使用依存句法进行抽取if postags[index]:# 抽取以谓词为中心的事实三元组child_dict = child_dict_list[index]# 主谓宾if 'SBV' in child_dict and 'VOB' in child_dict:# e1s = self.expand_e(words, postags, child_dict_list, child_dict['SBV'][0])# e2s = self.expand_e(words, postags, child_dict_list, child_dict['VOB'][0])r = words[index]e1 = words[child_dict['SBV'][0]]e2 = words[child_dict['VOB'][0]]if e1.replace(' ', '') and e2.replace(' ', ''):svos.append([e1, r, e2])# 含有介宾关系的主谓动补关系if 'SBV' in child_dict and 'CMP' in child_dict:e1 = words[child_dict['SBV'][0]]cmp_index = child_dict['CMP'][0]r = words[index] + words[cmp_index]if 'POB' in child_dict_list[cmp_index]:e2 = words[child_dict_list[cmp_index]['POB'][0]]if e1.replace(' ', '') and e2.replace(' ', ''):svos.append([e1, r, e2])return svos'''三元组抽取主函数'''def ruler2(self, words, postags, child_dict_list, arcs):svos = []for index in range(len(postags)):tmp = 1# 先借助语义角色标注的结果,进行三元组抽取if tmp == 1:# 如果语义角色标记为空,则使用依存句法进行抽取# if postags[index] == 'v':if postags[index]:# 抽取以谓词为中心的事实三元组child_dict = child_dict_list[index]# 主谓宾if 'SBV' in child_dict and 'VOB' in child_dict:r = words[index]e1 = self.complete_e(words, postags, child_dict_list, child_dict['SBV'][0])e2 = self.complete_e(words, postags, child_dict_list, child_dict['VOB'][0])if e1.replace(' ', '') and e2.replace(' ', ''):svos.append([e1, r, e2])# 定语后置,动宾关系relation = arcs[index][0]head = arcs[index][2]if relation == 'ATT':if 'VOB' in child_dict:e1 = self.complete_e(words, postags, child_dict_list, head - 1)r = words[index]e2 = self.complete_e(words, postags, child_dict_list, child_dict['VOB'][0])temp_string = r + e2if temp_string == e1[:len(temp_string)]:e1 = e1[len(temp_string):]if temp_string not in e1:if e1.replace(' ', '') and e2.replace(' ', ''):svos.append([e1, r, e2])# 含有介宾关系的主谓动补关系if 'SBV' in child_dict and 'CMP' in child_dict:e1 = self.complete_e(words, postags, child_dict_list, child_dict['SBV'][0])cmp_index = child_dict['CMP'][0]r = words[index] + words[cmp_index]if 'POB' in child_dict_list[cmp_index]:e2 = self.complete_e(words, postags, child_dict_list, child_dict_list[cmp_index]['POB'][0])if e1.replace(' ', '') and e2.replace(' ', ''):svos.append([e1, r, e2])return svos'''对找出的主语或者宾语进行扩展'''def complete_e(self, words, postags, child_dict_list, word_index):child_dict = child_dict_list[word_index]prefix = ''if 'ATT' in child_dict:for i in range(len(child_dict['ATT'])):prefix += self.complete_e(words, postags, child_dict_list, child_dict['ATT'][i])postfix = ''if postags[word_index] == 'v':if 'VOB' in child_dict:postfix += self.complete_e(words, postags, child_dict_list, child_dict['VOB'][0])if 'SBV' in child_dict:prefix = self.complete_e(words, postags, child_dict_list, child_dict['SBV'][0]) + prefixreturn prefix + words[word_index] + postfix'''程序主控函数'''def triples_main(self, content):sentences = self.split_sents(content)svos = []for sentence in sentences:print(sentence)words, postags, child_dict_list, arcs = self.parser_main(sentence)svo = self.ruler2(words, postags, child_dict_list, arcs)svos += svoreturn svos'''测试'''
def test():content1 = """环境很好,位置独立性很强,比较安静很切合店名,半闲居,偷得半日闲。点了比较经典的菜品,味道果然不错!烤乳鸽,超级赞赞赞,脆皮焦香,肉质细嫩,超好吃。艇仔粥料很足,香葱自己添加,很贴心。金钱肚味道不错,不过没有在广州吃的烂,牙口不好的慎点。凤爪很火候很好,推荐。最惊艳的是长寿菜,菜料十足,很新鲜,清淡又不乏味道,而且没有添加调料的味道,搭配的非常不错!"""content2 = """近日,一条男子高铁吃泡面被女乘客怒怼的视频引发热议。女子情绪激动,言辞激烈,大声斥责该乘客,称高铁上有规定不能吃泡面,质问其“有公德心吗”“没素质”。视频曝光后,该女子回应称,因自己的孩子对泡面过敏,曾跟这名男子沟通过,但对方执意不听,她才发泄不满,并称男子拍视频上传已侵犯了她的隐私权和名誉权,将采取法律手段。12306客服人员表示,高铁、动车上一般不卖泡面,但没有规定高铁、动车上不能吃泡面。高铁属于密封性较强的空间,每名乘客都有维护高铁内秩序,不破坏该空间内空气质量的义务。这也是乘客作为公民应当具备的基本品质。但是,在高铁没有明确禁止食用泡面等食物的背景下,以影响自己或孩子为由阻挠他人食用某种食品并厉声斥责,恐怕也超出了权利边界。当人们在公共场所活动时,不宜过分干涉他人权利,这样才能构建和谐美好的公共秩序。一般来说,个人的权利便是他人的义务,任何人不得随意侵犯他人权利,这是每个公民得以正常工作、生活的基本条件。如果权利可以被肆意侵犯而得不到救济,社会将无法运转,人们也没有幸福可言。如西谚所说,“你的权利止于我的鼻尖”,“你可以唱歌,但不能在午夜破坏我的美梦”。无论何种权利,其能够得以行使的前提是不影响他人正常生活,不违反公共利益和公序良俗。超越了这个边界,权利便不再为权利,也就不再受到保护。在“男子高铁吃泡面被怒怼”事件中,初一看,吃泡面男子可能侵犯公共场所秩序,被怒怼乃咎由自取,其实不尽然。虽然高铁属于封闭空间,但与禁止食用刺激性食品的地铁不同,高铁运营方虽然不建议食用泡面等刺激性食品,但并未作出禁止性规定。由此可见,即使食用泡面、榴莲、麻辣烫等食物可能产生刺激性味道,让他人不适,但是否食用该食品,依然取决于个人喜好,他人无权随意干涉乃至横加斥责。这也是此事件披露后,很多网友并未一边倒地批评食用泡面的男子,反而认为女乘客不该高声喧哗。现代社会,公民的义务一般分为法律义务和道德义务。如果某个行为被确定为法律义务,行为人必须遵守,一旦违反,无论是受害人抑或旁观群众,均有权制止、投诉、举报。违法者既会受到应有惩戒,也会受到道德谴责,积极制止者则属于应受鼓励的见义勇为。如果有人违反道德义务,则应受到道德和舆论谴责,并有可能被追究法律责任。如在公共场所随地吐痰、乱扔垃圾、脱掉鞋子、随意插队等。此时,如果行为人对他人的劝阻置之不理甚至行凶报复,无疑要受到严厉惩戒。当然,随着社会的发展,某些道德义务可能上升为法律义务。如之前,很多人对公共场所吸烟不以为然,烟民可以旁若无人地吞云吐雾。现在,要是还有人不识时务地在公共场所吸烟,必然将成为众矢之的。再回到“高铁吃泡面”事件,要是随着人们观念的更新,在高铁上不得吃泡面等可能产生刺激性气味的食物逐渐成为共识,或者上升到道德义务或法律义务。斥责、制止他人吃泡面将理直气壮,否则很难摆脱“矫情”,“将自我权利凌驾于他人权利之上”的嫌疑。在相关部门并未禁止在高铁上吃泡面的背景下,吃不吃泡面系个人权利或者个人私德,是不违反公共利益的个人正常生活的一部分。如果认为他人吃泡面让自己不适,最好是请求他人配合并加以感谢,而非站在道德制高点强制干预。只有每个人行使权利时不逾越边界,与他人沟通时好好说话,不过分自我地将幸福和舒适凌驾于他人之上,人与人之间才更趋于平等,公共生活才更趋向美好有序。"""content3 = '''(原标题:央视独家采访:陕西榆林产妇坠楼事件在场人员还原事情经过)央视新闻客户端11月24日消息,2017年8月31日晚,在陕西省榆林市第一医院绥德院区,产妇马茸茸在待产时,从医院五楼坠亡。事发后,医院方面表示,由于家属多次拒绝剖宫产,最终导致产妇难忍疼痛跳楼。但是产妇家属却声称,曾向医生多次提出剖宫产被拒绝。事情经过究竟如何,曾引起舆论纷纷,而随着时间的推移,更多的反思也留给了我们,只有解决了这起事件中暴露出的一些问题,比如患者的医疗选择权,人们对剖宫产和顺产的认识问题等,这样的悲剧才不会再次发生。央视记者找到了等待产妇的家属,主治医生,病区主任,以及当时的两位助产师,一位实习医生,希望通过他们的讲述,更准确地还原事情经过。产妇待产时坠亡,事件有何疑点。公安机关经过调查,排除他杀可能,初步认定马茸茸为跳楼自杀身亡。马茸茸为何会在医院待产期间跳楼身亡,这让所有人的目光都聚焦到了榆林第一医院,这家在当地人心目中数一数二的大医院。就这起事件来说,如何保障患者和家属的知情权,如何让患者和医生能够多一份实质化的沟通?这就需要与之相关的法律法规更加的细化、人性化并且充满温度。用这种温度来消除孕妇对未知的恐惧,来保障医患双方的权益,迎接新生儿平安健康地来到这个世界。'''content4 = '李克强总理今天来我家了,我感到非常荣幸'content5 = ''' 以色列国防军20日对加沙地带实施轰炸,造成3名巴勒斯坦武装人员死亡。此外,巴勒斯坦人与以色列士兵当天在加沙地带与以交界地区发生冲突,一名巴勒斯坦人被打死。当天的冲突还造成210名巴勒斯坦人受伤。当天,数千名巴勒斯坦人在加沙地带边境地区继续“回归大游行”抗议活动。部分示威者燃烧轮胎,并向以军投掷石块、燃烧瓶等,驻守边境的以军士兵向示威人群发射催泪瓦斯并开枪射击。'''extractor = SVOParser()svos = extractor.triples_main(content5)print('svos', svos)for svo in svos:print(svo)if __name__ == '__main__':print("loading model...")test()