公众号文章链接
- 前一段时间就想做简单的==可视化文本分析==玩,今天就花点时间先对整体班级的==QQ群聊天信息做一个简单的分析==。
- 打算分两步做,本文是最简单的第一步过程
- 1:分析整个聊天记录的时间分配。并且用matplotlib展示出来。并把整个聊天的关键词做成词云。
- 2:融入snownlp情感分析,分析每个同学的词云分布,每个同学的发言次数情况,以及每个同学文本的情绪走势以及展示。 等等
- 总的来说就是先试试水,然后再做第二个。用到的库有:jieba分词,wordcloud词云,numpy数组,matplotlib可视化,snownlp(第二个),re正则(很重要)。这些用不到深入的东西,只用到很简单的一小部分,都可以直接 pip install xxx。
- 言归正传,下面说一下我的学习历程:
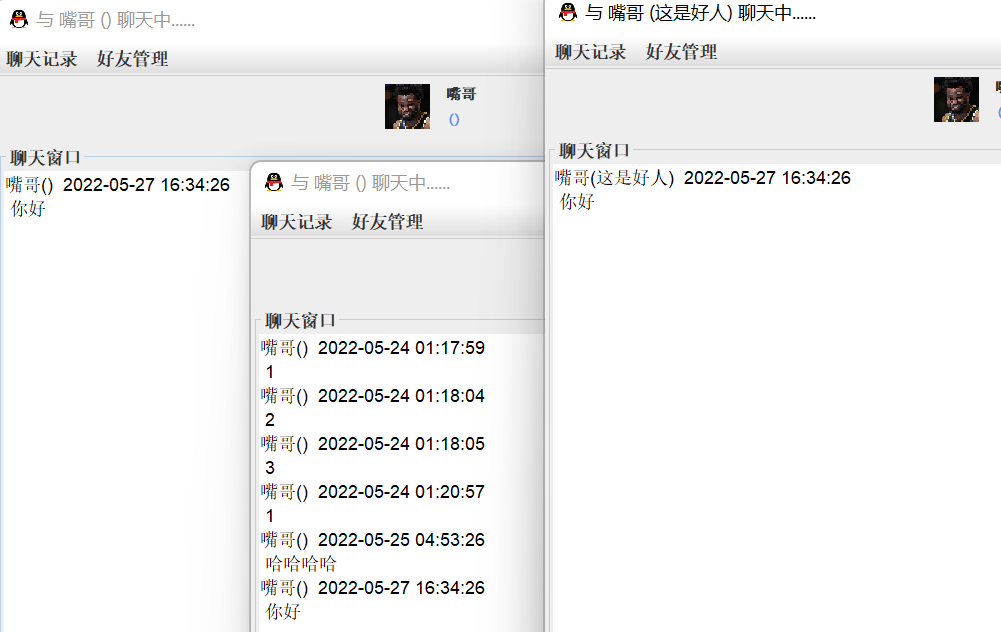
- 首先,第一步就是导出群聊消息,再qq的资源管理器上选择群可以==导出群消息==记录成txt文本。
- 要观察聊天记录的规则,了解==文本结构==。能够解析下列方框标注的内容很重要。
2018-05-05 15:55:40 2班某某(1315426911)
2018-05-07 13:48:39 2XXX<xxxx@qq.com>
复制代码- 下一步就需要==正则匹配==获取相应的内容。 这个地方的正则匹配规则也很简单,因为格式固定. 但是我要分配各个聊天的时间,那么就要匹配"15:55:40"这段话,可以重写一个正则或者在原来的正则上添加,我选择重写正则,对于==正则取值==前端时间简单写过取值两个正则表达式为:
pattern=re.compile(r'(\d*)-(\d*)-(\d*) .* .*')#匹配 信息
pattern2=re.compile(r'(\d+):(\d+):\d+')#匹配 15:55:40
复制代码- 既然能取到上一步骤人说的话,那么我们在下一步就需要对==数据去噪==。那些数据会对结果有影响但是我们不需要的,这里大致列了几个(要注意的是文本换行符/n,每行无论是什么都有一个换行符):
- 空格消息
- 红包
- 表情
- 撤回的消息
- 图片
- @全体成员
- 个别群复读机严重适当处理
- 其他
- 这样每次按行读取,添加对应的次数和文本内容和水群次数。
- 制作聊天时间分布图。使用matplotlib展示坐标的一些坑点已经解决。保存图片到本地。
- 将各个文本合并生成班级主题词云。保存图片到本地。
- 观察词云的词是否有不该出现的词语,分析原因对数据进行==二次去噪==。我当时就是因为第一次写的正则没有匹配"2018-05-07 13:48:39 2班xxxxxxx@qq.com"导致词云出现一个同学的名字。。后来把正则改了就决绝了。你也可能会遇到特殊情况需要经常@某个人,,你可以自行处理。
代码开箱可用,你需要把你的文件名==替换正确的路径==,还有要在同级目录下==创建img文件夹==保存生成的两张图片。各种依赖环境很简单,直接pip install xxx。 附上核心代码:
import re
import numpy as np
import matplotlib.pyplot as plt ##绘图库
from wordcloud import WordCloud
import jieba.analyse
string="2018-05-05 15:55:40 2班某某(1315426911)"
pattern=re.compile(r'(\d*)-(\d*)-(\d*) .* .*')
#匹配 2018-05-05 15:55:40 2班某某(1315426911) 有一个坑点就是2018-05-07 13:48:39 2XXX<xxxx@qq.com>这种格式
pattern2=re.compile(r'(\d+):(\d+):\d+')#匹配 15:55:40
#pattern3=re.compile(r'(\()(.*?)(\))')#匹配 2班某某(1315426911)相关内容
f = open('E:/text.txt', 'r', encoding='utf-8') # 要进行分词处理的文本文件 (统统按照utf8文件去处理,省得麻烦)
lines = f.readlines()
index=0
def getpicture(y):#matplotlib绘图x=[]for i in range(0,24):x.append(str(i)+':00-'+str(i+1)+':00')Xi = np.array(x)Yi = np.array(y)plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签plt.figure(figsize=(8, 6)) ##指定图像比例: 8:6plt.subplots_adjust(bottom=0.2)plt.scatter(Xi, Yi, color="red", label="times")plt.xlabel("时间00:00—24:00")plt.ylabel("发言次数/次")plt.xticks(range(0,24),rotation=75,fontsize=10)#设置横坐标显示24次。plt.yticks(range(0,1000,50))# plt.legend(loc='lower right') # 绘制图例# plt.show()plt.savefig("img/hour.png",format='png')plt.close()
def getciyun(value):text=''for i in range(0,24):text+=str(value[i]['text'])args=jieba.analyse.extract_tags(text,topK=80)text=' '.join(args)wc = WordCloud(background_color="white",width=1500, height=1000,min_font_size=40,font_path="simhei.ttf",# max_font_size=300, # 设置字体最大值random_state=40, # 设置有多少种随机生成状态,即有多少种配色方案) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体# wc.font_path="simhei.ttf"my_wordcloud = wc.generate(text)plt.imshow(my_wordcloud)plt.axis("off")plt.show()wc.to_file('img/wordcloud.png')
def analysebyhour(lines):value=[]y=[]index=0for i in range(0,24):value.append({})value[i]['time']=0value[i]['text']=''for line in lines:if line != "\n" and line.strip() != "\n" and line != None and not line.__contains__("撤回了"):line = line.replace("[表情]", " ").replace("@全体成员", " ").replace("[表情]", " ").\replace("[QQ红包]我发了一个“专享红包”,请使用新版手机QQ查收红。", "").replace("\n", " ").replace("[图片]",'')if(pattern.search(line)):#匹配到正确的对象date=pattern.search(line)hour=pattern2.search(line).group(1)#print(date.group(0),hour)value[int(hour)]['time']+=1index=hourelse:print(line)value[int(index)]['text']+=str(line)for i in range(0,24):print('time:',i,'time',value[i]['time'])y.append(value[i]['time'])getpicture(y)getciyun(value)
analysebyhour(lines)
复制代码然后两张图片就出来了:
- 第一个点状图可以发现我们的聊天时间11:00-12:00突出,17:00-18:00突出,因为这个时间我们没有课程在吃饭或者玩,有时候下午或者晚上或者其他的安排或者考试啥的可能会讨论。而13:00-14:00这个点我们大部分在午休一般没人聊天。但是醒了之后就会一直很活跃?。
- 第二个词云可以看的出我们最近在聊啥,因为我的记录是5月十几才开始,记录不足,准备找一份记录足的做下一个研究。你可能通过词云发现我的其实还有挺大的不足就是QQ小冰没有过滤掉。希望如果读者有兴趣尝试可以处理一下。
通过这些简单的文本分析感觉很有趣,有兴趣等有时间把第二种也做出来,那种可能做起来比较麻烦一些。但是难道还是不大的。这些东西看似高深,其实了解api做起来很简单。
希望一起加油。