0. 简介
最近作者希望系统性的去学习一下CUDA加速的相关知识,正好看到深蓝学院有这一门课程。所以这里作者以此课程来作为主线来进行记录分享,方便能给CUDA网络加速学习的萌新们去提供一定的帮助。
1. Cublas概念
cuBLAS是一个BLAS的实现,允许用户使用NVIDIA的GPU的计算资源。使用cuBLAS的时候,应用程序应该分配矩阵或向量所需的GPU内存空间,并加载数据,调用所需的cuBLAS函数,然后从GPU的内存空间上传计算结果至主机,cuBLASAPI也提供一些帮助函数来写或者读取数据从GPU中。它包含两套API,一个是常用到的cuBLAS API,需要用户自己分配GPU内存空间,按照规定格式填入数据,;还有一套CUBLASXT API,可以分配数据在CPU端,然后调用函数,它会自动管理内存、执行计算。既然都用cuda了,其实还是用第一套API多一点。
一般对于Cublas函数的学习,我们会在这个网站上学习。
最初,为了尽可能地兼容Fortran语言环境,cuBLAS库被设计成列优先存储的数据格式,不过C/C++是行优先的,我们比较好理解的也是行优先的格式,所以需要费点心思在数据格式上,同时Cublas是索引以1为基准的。头文件为include "cublas_v2.h“。主要适用于三类函数(向量标量、向量矩阵、矩阵矩阵)。

2. Cublas实现矩阵乘法
现在装好cuda会自带cuBLAS库的。相比与之前的旧库,现在的cuBLAS矩阵运算库有些新特性:
- handle更加可控,更加适用于多GPU或CPU多进程。handle是cuBLAS库上下文的句柄,可以把数据、函数等等连接在一起,就想Cuda的stream一样。现在,新版本的cuBLAS可以用简单的函数创建句柄,然后把它绑定到不同的函数、数据上去;非常方便。
- 所有的函数都可以返回错误标识符cublasStatus_t了。可以更加方便调试,发现代码的具体错误原因。
- 函数cublasAlloc() and cublasFree()被摒弃了。
目前整个流程大概如下:
...// 准备A, B, C 以及使用的线程网格、线程块的尺寸
// 创建句柄
cublasHandle_thandle;
cublasCreate(&handle);
// 调用计算函数
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, m, n, k, &alpha, *B, n, *A, k, &beta, *C, n);
// 销毁句柄
cublasDestroy(handle);
...// 回收计算结果,顺序可以和销毁句柄交换
大多数用于计算的cuBLAS函数名字里都包含数据类型信息,表明这个函数专门用于处理float、double还是什么数据类型的。
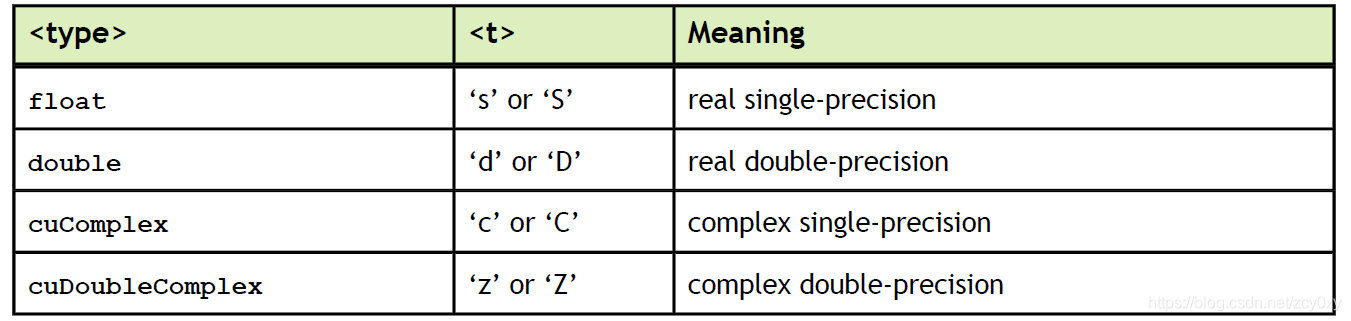
2.1 Cublaslevel1函数:标量
cublasStatus_t cublasIsamax(cublasHandle_t handle, int n, const float *x, int incx, int *result)
cublasStatus_t cublasIsamin(cublasHandle_t handle, int n, const float *x, int incx, int *result)
实现功能:
result = max/min( x )
参数意义:
Incx:x的存储间隔
2.2 Cublaslevel2函数:矩阵向量
cublasStatus_t cublasSgemv(cublasHandle_t handle, cublasOperation_t trans, int m, int n, const float *alpha, const float *A, int lda, const float *x, int incx, const float *beta, float *y, int incy)
实现功能:
y = alpha * op ( A ) * x + beta * y
参数意义:
Lda:A的leading dimension,若转置按行优先,则leadingdimension为A的列数
Incx/incy:x/y的存储间隔
2.3 Cublaslevel3函数:矩阵矩阵
cublasStatus_tcublasSgemm(cublasHandle_thandle,
cublasOperation_ttransa, cublasOperation_ttransb,
int m, int n, int k,
const float *alpha, const float *A, int lda, const float *B, int ldb,
const float *beta, float*C, int ldc)
实现功能:
C = alpha * op ( A ) * op ( B ) + beta * C
参数意义:
alpha和beta是标量,A B C是以列优先存储的矩阵
如果transa的参数是CUBLAS_OP_N 则op(A) = A ,如果是CUBLAS_OP_T 则op(A)=A的转置
如果transb的参数是CUBLAS_OP_N 则op(B) = B ,如果是CUBLAS_OP_T 则op(B)=B的转置
Lda/Ldb:A/B的leading dimension,若转置按行优先,则leadingdimension为A/B的列数
Ldc:C的leading dimension,C矩阵一定按列优先,则leading dimension为C的行数
3. cuBLAS代码常用函数
3.1 cublasSetMatrix()
先看个函数cublasSetMatrix():
cublasSetMatrix(int rows, int cols, int elemSize, const void *A,
int lda, void *B, int ldb)
这个函数可以把CPU上的矩阵A拷贝到GPU上的矩阵B,两个矩阵都是列优先存储的格式。lda是A的leading dimension ,既然是列优先,那么就是A的行数(A的一列有多少个元素);ldb同理。与 cublasGetMatrix()函数作用相反
3.2 cublasSscal()
传入矩阵x,总大小为n,每隔incx个数,就乘以alpha。很简单的函数,纯粹为了演示。
cublasSscal(cublasHandle_t handle, int n,const float *alpha,
float *x, int incx)
3.3 cublasCreate()和cublasDestroy()
cublasCreate()和cublasDestroy()为上下文管理函数。使用cuBLAS库函数,必须初始化一个句柄来管理cuBLAS上下文。函数为cublasCreate(),销毁的函数为cublasDestroy()。这些操作全部需要显式的定义,这样用户同时创建多个handle,绑定到不同的GPU上去,执行不同的运算,这样多个handle之间的计算工作就可以互不影响。
cublasCreate(cublasHandle_t *handle)
官方手册建议尽可能少的创建handle,并且在运行任何cuBLAS库函数之前创建好handle。handle会和当前的device(当前的GPU显卡)绑定,如果有多块GPU,你可以为每一块GPU创建一个handle。或者只有一个GPU,你也可以创建多个handle与之绑定。
cublasDestroy(cublasHandle_t handle)
销毁handle时,会隐性调用同步阻塞函数cublasDeviceSynchronize()。







