一、分布式系统的一致性问题
1、分布式系统的一致性问题
随着摩尔定律碰到瓶颈,越来越多情况下要依靠可扩展的分布式架构来实现海量处理能力。单点结构演变到分布式结构,首要解决的问题就是数据的一致性。如果分布式集群中多个节点不能保证处理结果的一致性,建立在其上的业务系统将无法正常工作。区块链系统是一个典型的分布式系统,在设计上必然也要考虑一致性问题。
在面向大规模复杂任务场景时,单点的服务往往难以解决可扩展(Scalability)和容错(Fault-tolerance)两方面的需求,就需要多台服务器来组成集群系统,虚拟为更加强大和稳定的“超级服务器”。
集群的规模越大,处理能力越强,管理的复杂度也就越高。目前在运行的大规模集群包括谷歌公司的搜索系统,通过数十万台服务器支持了对整个互联网内容的搜索服务。
通常情况下,集群系统中的不同节点可能处于不同的状态,随时收到不同的请求,要时刻保持对外响应的一致性。
一致性(Consistency)在分布式系统领域中是指对于多个服务节点,给定一系列操作,在约定协议的保障下使得多个节点对处理结果达成某种程度的协同。
理想情况(不考虑节点故障)下,如果各个服务节点严格遵循相同的处理协议(即构成相同的状态机逻辑),则在给定相同的初始状态和输入序列时,可以确保处理过程中的每个步骤的执行结果都相同。因此,传统分布式系统中讨论一致性,通常是指在外部任意发起请求(如向多个节点发送不同请求)的情况下,确保系统内大部分节点实际处理请求序列的一致,即对请求进行全局排序。
一致性关注的是系统呈现的状态,并不关注结果是否正确;例如,所有节点都对某请求达成否定状态也是一种一致性。
2、分布式系统的挑战
典型的分布式系统中存在如下挑战:
A、节点之间只能通过消息来交互和同步,而网络通讯是不可靠的,可能出现任意消息延迟、乱序和错误。
B、节点处理请求的时间无法保障,处理的结果可能是错误的,甚至节点自身随时可能发生故障。
C、为了避免冲突,采用同步调用可以简化设计,但会严重降低系统的可扩展性,甚至使其退化为单点系统。
3、分布式系统一致性的要求
分布式系统达成一致的过程应该满足如下要求:
A、可终止性(Termination)
一致的结果在有限时间内能完成。
B、约同性(Agreement)
不同节点最终完成决策的结果是相同的。为了确保协同性,分布式系统通常会把不同时空发生的多个事件进行全局唯一排序,并且顺序必须是所有节点认可的。
C、合法性(Validity)
决策的结果必须是某个节点提出的提案。
4、分布式系统带约束的一致性
要实现绝对理想的严格一致性(Strict Consistency)代价很大。除非系统不发生任何故障,并且所有节点之间的通信无需任何时间,此时整个系统其实就等价于单点系统。实际上,越强的一致性要求往往意味着带来越弱的处理性能,以及越差的可扩展性。根据实际需求的不用,可以选择不同强度的一致性,包括强一致性(Strong Consistency)和弱一致性(Weak Consistency)。
强一致性包括两类:
A、顺序一致性
顺序一致性(Sequential Consistency):Leslie Lamport1979年经典论文《How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs》中提出,是一种比较强的约束,保证所有进程看到的全局执行顺序(total order)一致,并且每个进程看自身的执行顺序(local order)跟实际发生顺序一致。例如,某进程先执行A,后执行 B,则实际得到的全局结果中就应该为A在B前面,而不能反过来。同时所有其它进程在全局上也应该看到这个顺序。顺序一致性实际上限制了各进程内指令的偏序关系,但不在进程间按照物理时间进行全局排序。
B、线性一致性
线性一致性(Linearizability Consistency):Maurice P. Herlihy与Jeannette M.Wing在1990年经典论文《Linearizability: A Correctness Condition for Concurrent Objects》中共同提出,在顺序一致性前提下加强了进程间的操作排序,形成唯一的全局顺序(系统等价于是顺序执行,所有进程看到的所有操作的序列顺序都一致,并且跟实际发生顺序一致),是很强的原子性保证。但比较难实现,目前基本上要么依赖于全局的时钟或锁,要么通过一些复杂算法实现,性能通常不高。
实现强一致性往往需要准确的计时设备。高精度的石英钟的漂移率为10^-7,最准确的原子震荡时钟的漂移率为10^-13。Google曾在其分布式数据库Spanner 中采用基于原子时钟和GPS的TrueTime方案,能够将不同数据中心的时间偏差控制在10ms以内。在不考虑成本的前提下,TrueTime方案简单、粗暴,但有效。
强一致的系统往往比较难实现,而且很多场景下对一致性的需求并没有那么强。因此,可以适当放宽对一致性的要求,降低系统实现的难度。例如在一定约束下实现所谓最终一致性(Eventual Consistency),即总会存在一个时刻(而不是立刻),让系统达到一致的状态。
例如电商购物时将某物品放入购物车,但可能在最终付款时才提示物品已经售罄。实际上,大部分的Web 系统为了保持服务的稳定,实现的都是最终一致性。
弱一致性相对于强一致性,是在某些方面弱化的一致性,如最终一致性。
二、分布式共识算法简介
1、分布式共识简介
共识(Consensus)通常会与一致性(Consistency)术语放在一起讨论。严谨地讲,两者的含义并不完全相同。
一致性的含义比共识宽泛,在不同场景(基于事务的数据库、分布式系统等)下意义不同。具体到分布式系统场景下,一致性指的是多个副本对外呈现的状态。如顺序一致性、线性一致性,描述了多节点对数据状态的共同维护能力。而共识,则特指在分布式系统中多个节点之间对某个事情(例如多个事务请求的执行顺序)达成一致看法的过程。因此,达成某种共识并不意味着就保障了一致性。
实践中,要保障系统满足不同程度的一致性,往往需要通过共识算法来达成。
共识算法解决的是分布式系统中大部分节点对某个提案(Proposal)达成一致意见的过程。提案的含义在分布式系统中十分宽泛,如多个事件发生的顺序、某个键对应的值等等。任何可以达成一致的信息都是一个提案。对于分布式系统,各个节点通常都是相同的确定性状态机模型(又称为状态机复制问题,State-Machine Replication),从相同初始状态开始接收相同顺序的指令,则可以保证相同的结果状态。因此,分布式系统中多个节点达成共识的关键是对多个事件的顺序进行共识,即排序。
2、分布式共识的挑战
分布式系统达成共识都要解决两个基本的问题:
A、如何提出一个待共识的提案,如通过令牌传递、随机选取、权重比较、求解难题等。
B、如何让多个节点对提案达成共识(同意或拒绝),如投票、规则验证等。
在实际应用的分布式系统中,不同节点之间通信存在延迟(光速物理限制、通信处理延迟),并且任意环节都可能存在故障(系统规模越大,发生故障可能性越高)。如通信网络会发生中断、节点会发生故障、甚至存在被入侵的节点故意伪造消息,破坏正常的共识过程。
通常,把出现故障(Crash或Fail-stop,即不响应)但不会伪造信息的情况称为“非拜占庭错误(Non-Byzantine Fault)”或“故障错误(Crash Fault)”;伪造信息恶意响应的情况称为“拜占庭错误”(Byzantine Fault),对应节点为拜占庭节点。拜占庭错误场景中因为存在捣乱者更难达成共识。
3、常见分布式共识算法
根据解决的场景是否允许拜占庭错误情况,共识算法可以分为CFT(CrashFault Tolerance)和BFT(Byzantine Fault Tolerance)两类。
对于非拜占庭错误的情况,经典的共识算法包括Paxos(1990年)、Raft(2014年)及其变种等。CFT类容错算法通常性能比较好,处理较快,容忍不超过一半的故障节点。
对于要能容忍拜占庭错误的情况,包括PBFT(Practical Byzantine Fault Tolerance,1999年)为代表的确定性系列算法、PoW(1997年)为代表的概率算法等。确定性算法一旦达成共识就不可逆转,即共识是最终结果;而概率类算法的共识结果则是临时的,随着时间推移或某种强化,共识结果被推翻的概率越来越小,最终成为事实上结果。拜占庭类容错算法通常性能较差,容忍不超过1/3的故障节点。
此外,XFT(Cross Fault Tolerance,2015年)等最近提出的改进算法可以提供类似CFT的处理响应速度,并能在大多数节点正常工作时提供BFT保障。
Algorand算法(2017年)基于PBFT进行改进,通过引入可验证随机函数解决了提案选择的问题,理论上可以在容忍拜占庭错误的前提下实现更好的性能(1000+TPS)。
实践中,通常客户端要拿到共识结果需要自行验证,典型地,可以访问足够多个服务节点来比对结果,确保获取结果的准确性。
三、FLP不可能原理
1、FLP原理简介
FLP不可能原理:在网络可靠,但允许节点失效(即便只有一个)的最小化异步模型系统中,不存在一个可以解决一致性问题的确定性共识算法。
FLP不可能原理在1985年由Fischer,Lynch和Patterson三位科学家在《Impossibility of Distributed Consensus with One Faulty Process》论文中提出并证明。
FLP不可能原理表明,不要浪费时间,去试图为异步分布式系统设计面向任意场景的共识算法。
2、分布式系统的同步与异步
分布式系统中同步和异步的定义如下:
同步是指系统中的各个节点的时钟误差存在上限,并且消息传递必须在一定时间内完成,否则认为失败;同时各个节点完成处理消息的时间是一定的。因此同步系统中可以很容易地判断消息是否丢失。
异步是指系统中各个节点可能存在较大的时钟差异,同时消息传输时间是任意长的;各节点对消息进行处理的时间也可能是任意长的。因此,无法判断某个消息迟迟没有被响应的原因(节点故障或传输故障)。
现实生活中的分布式系统通常都是异步系统。
3、FLP原理的意义
FLP不可能原理实际上说明对于允许节点失效情况下,纯粹异步系统无法确保共识在有限时间内完成。即便对于非拜占庭错误的前提下,包括Paxos、Raft等算法也都存在无法达成共识的极端情况,只是在工程实践中出现的概率很小。
FLP不可能原理并不意味着研究共识算法没有意义。学术研究通常考虑地是数学和物理意义上理想化的情形,很多时候现实世界要稳定得多;工程实现上某次共识失败,再尝试几次,很大可能就成功。
四、CAP原理
1、CAP原理简介
CAP原理最早出现在2000年,由加州大学伯克利分校的Eric Brewer教授在ACM组织的Principles of Distributed Computing(PODC)研讨会上提出猜想,后来麻省理工学院的Nancy Lynch等学者进行了理论证明。
CAP原理被认为是分布式系统领域的重要原理之一,深刻影响了分布式计算与系统设计的发展。
CAP原理:分布式系统无法同时确保一致性(Consistency)、可用性(Availability)和分区容忍性(Partition),设计中往往需要弱化对某个特性的需求。
一致性(Consistency):任何事务应该都是原子的,所有副本上的状态都是事务成功提交后的结果,并保持强一致。
可用性(Availability):系统(非失败节点)能在有限时间内完成对操作请求的应答。
分区容忍性(Partition):系统中的网络可能发生分区故障(成为多个子网,甚至出现节点上线和下线),即节点之间的通信无法保障。而网络故障不应该影响到系统正常服务。
CAP原理认为,分布式系统最多只能保证三项特性中的两项特性。当网络可能出现分区时,系统是无法同时保证一致性和可用性的。要么,节点收到请求后因为没有得到其它节点的确认而不应答(牺牲可用性),要么节点只能应答非一致的结果(牺牲一致性)。
由于大部分时候网络被认为是可靠的,因此系统可以提供一致可靠的服务;当网络不可靠时,系统要么牺牲掉一致性(多数场景下),要么牺牲掉可用性。
网络分区是可能存在的,出现分区情况后很可能会导致发生脑裂,多个新出现的主节点可能会尝试关闭其它主节点。
2、CAP原理应用场景
CAP三种特性不可同时得到保障,因此设计系统时候必然要弱化对某个特性的支持。根据CAP原理可以定义三种应用场景:
A、弱化一致性
对结果一致性不敏感的应用,可以允许在新版本上线后过一段时间才最终更新成功,期间不保证一致性。例如网站静态页面内容、实时性较弱的查询类数据库等,简单分布式同步协议如Gossip,以及CouchDB、Cassandra数据库等都弱化了一致性。
B、弱化可用性
对结果一致性很敏感的应用,例如银行取款机,当系统故障时候会拒绝服务。MongoDB、Redis、MapReduce等都弱化了可用性。
Paxos、Raft等共识算法主要处理对于一致性敏感的情况。在Paxos类算法中,可能存在着无法提供可用结果的情形,同时允许少数节点离线。
C、弱化分区容忍性
现实中,网络分区出现概率较小,但很难完全避免。
两阶段的提交算法,某些关系型数据库以及ZooKeeper 主要考虑了这种设计。
实践中,网络可以通过双通道等机制增强可靠性,实现高稳定的网络通信。
五、ACID原则与多阶段提交
1、ACID原则简介
ACID,即Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)、
Durability(持久性)四种特性的缩写。
ACID 是一种比较出名的描述一致性的原则,通常出现在分布式数据库等基于事务过程的系统中。
ACID 原则描述了分布式数据库需要满足的一致性需,同时允许付出可用性的代价。
Atomicity:每次事务是原子的,事务包含的所有操作要么全部成功,要么全部不执行。一旦有操作失败,则需要回退状态到执行事务前。
Consistency:数据库的状态在事务执行前后的状态是一致的和完整的,无中间状态。即只能处于成功事务提交后的状态。
Isolation:各种事务可以并发执行,但彼此之间互相不影响。按照标准SQL规范,从弱到强可以分为未授权读取、授权读取、可重复读取和串行化四种隔离等级。
Durability:状态的改变是持久的,不会失效。一旦某个事务提交,则它造成的状态变更就是永久性的。
与ACID 相对的一个原则是eBay技术专家Dan Pritchett 提出的BASE(Basic Availability,Soft-state,Eventual Consistency)原则。BASE原则面向大型高可用分布式系统,主张牺牲掉对强一致性的追求,而实现最终一致性,来换取一定的可用性。
ACID和BASE两种原则实际是对 CAP原理三种特性的不同取舍。
对于分布式事务一致性的研究成果包括著名的两阶段提交算法(Two-phaseCommit,2PC)和三阶段提交算法(Three-phase Commit,3PC)。
2、两阶段提交算法
两阶段提交算法最早由Jim Gray于1979年在论文《Notes on Database Operating Systems》中提出。其基本思想十分简单,既然在分布式场景下,直接提交事务可能出现各种故障和冲突,那么可将其分解为预提交和正式提交两个阶段,规避冲突的风险。
预提交:协调者(Coordinator)发起提交某个事务的申请,各参与执行者
(Participant)需要尝试进行提交并反馈是否能完成。
正式提交:协调者如果得到所有执行者的成功答复,则发出正式提交请求。如果成功完成,则算法执行成功。
在此过程中任何步骤出现问题(例如预提交阶段有执行者回复预计无法完成提交),则需要回退。
两阶段提交算法因为简单容易实现的优点,在关系型数据库等系统中被广泛应用。两阶段提交算法的缺点是整个过程需要同步阻塞导致性能通常较差;同时存在单点问题,较坏情况下可能一直无法完成提交;可能产生数据不一致的情况(例如协调者和执行者在第二个阶段出现故障)。
3、三阶段提交算法
三阶段提交针对两阶段提交算法第一阶段中可能阻塞部分执行者的情况进行了优化,即将预提交阶段进一步拆成两个步骤:尝试预提交和预提交。
完整过程如下:
尝试预提交:协调者询问执行者是否能进行某个事务的提交。执行者需要返回答复,但无需执行提交,可以避免出现部分执行者被无效阻塞住的情况。
预提交:协调者检查收集到的答复,如果全部为,,则发起提交事务请求。各参与执行者(Participant)需要尝试进行提交并反馈是否能完成。
正式提交:协调者如果得到所有执行者的成功答复,则发出正式提交请求。如果成功完成,则算法执行成功。
无论两阶段提交还是三阶段提交,都只是一定程度上缓解了提交冲突的问题,并无法一定保证系统的一致性。多阶段提交首个有效算法是Paxos算法。
六、可靠性指标
1、可靠性指标简介
可靠性(Availability,可用性)是描述系统可以提供服务能力的重要指标。高可靠的分布式系统通常需要各种复杂的机制来进行保障。
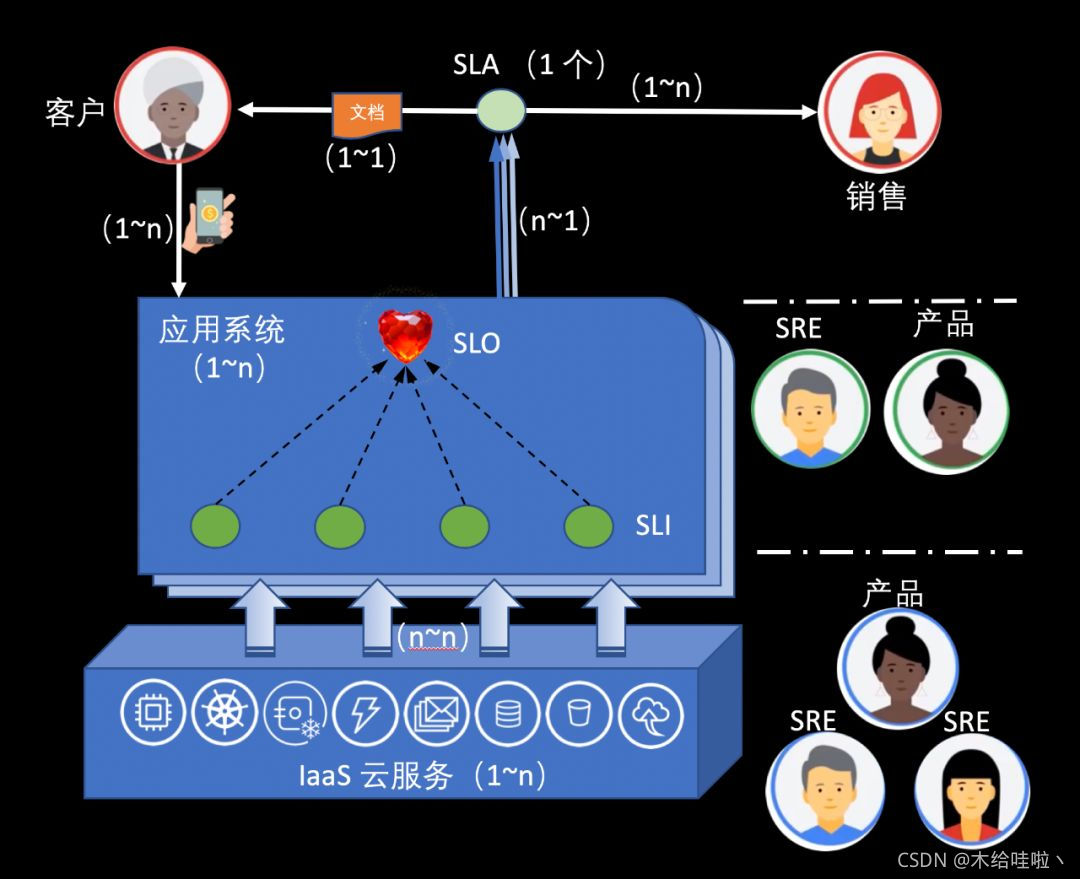
通常情况下,服务的可用性可以用服务承诺(Service Level Agreement,SLA)、服务指标(Service Level Indicator,SLI)、服务目标(Service Level Objective,SLO)等方面进行衡量。每年允许服务出现不可用时间的可靠性指标参考值如下:

通常,单点的服务器系统至少应能满足两个9;普通企业信息系统三个9就足够;系统能达到四个9已经是领先水平(参考AWS等云计算平台);电信级的应用一般需要能达到五个9,一年里面最多允许出现五分钟左右的服务不可用;六个9以及以上的系统较为少见,要实现往往意味着极高的代价。
2、两个核心时间
一般地,描述系统出现故障的可能性和故障出现后的恢复能力,有两个基础的指标:MTBF和 MTTR。
MTBF(Mean Time Between Failures),即平均故障间隔时间,是系统可以无故障运行的预期时间。
MTTR(Mean Time To Repair),即平均修复时间,是发生故障后系统可以恢复到正常运行的预期时间。
MTBF衡量了系统发生故障的频率,如果一个系统的MTBF很短,则意味着系统可用性低;而MTTR则反映了系统碰到故障后服务的恢复能力,如果系统的 MTTR 过长,则说明系统一旦发生故障需要较长时间才能恢复服务。
一个高可用的系统应该是具有尽量长的MTBF和尽量短的MTTR。
3、提高可靠性
由两种方法可以提高可靠性:一是让系统中的单个组件都变得更可靠;二
是消灭单点。
依靠单点实现的可靠性毕竟有限,要想进一步的提升系统的可靠性,就只好消灭单点,通过主从、多活等模式让多个节点集体完成原先单点的工作(分布式),可以从概率意义上改善服务对外整体的可靠性。