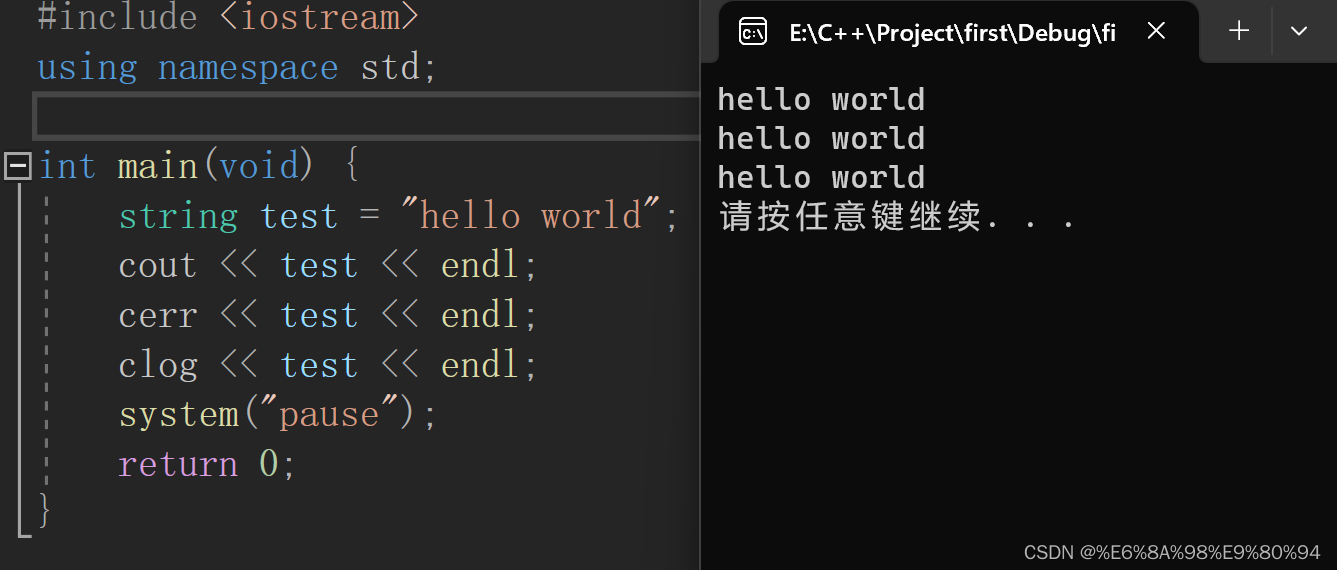
文章目录
- linux
- 第一章
- Linux历史
- 版本选择
- 计算机硬件(不考)
- 计算机软件(不考)
- 系统分区
- 安装
- 实验一
- 交换分区(swap)
- 手动创建Swap交换分区
- /etc/fstab介绍
- 第二章
- 常用命令
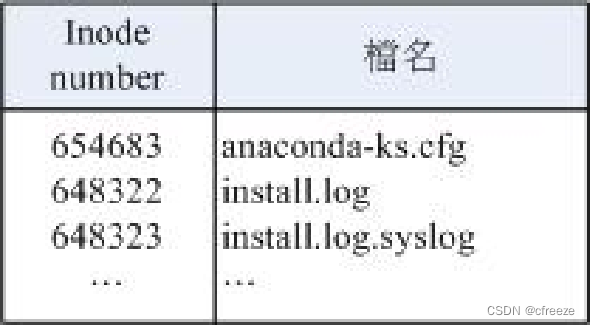
- 索引结点
- 1.文件系统概念:
- 2.Linux的文件系统特性:
- 3.索引式文件系统(indexed allocation)
- 目录树
- 文件操作命令
- 实验二
- 第三章
- 文本编辑器Vi及其工作模式
- vi的工作方式
- 命令/输入方式
- 编辑文件
- 字符串检索
- 实验三
- 第四章
- 1.shell脚本的建立和执行
- **执行shell脚本**的方式:
- 2.查看本机正在使用的shell种类
- 3.历史命令
- 命令
- 4.shell特殊字符
- 通配符
- 引号
- 输入/输出重定向符
- 注释、管道线和后台命令
- 命令执行操作符
- 成组命令
- 5.shell变量
- 用户定义的变量
- 数组
- 变量引用
- 输入/输出命令
- 位置参数(重点)
- 位置参数及其引用
- 用set命令为位置参数赋值
- 移动位置参数(重要)
- 预先定义的特殊变量(不重要)
- 环境变量(不重要)
- 6.算术运算
- 比较三种算术运算的异同
- 7.控制结构
- if语句
- 条件测试
- 文件测试运算符
- 字符串测试运算符
- 数值测试运算符
- 逻辑测试运算符
- 特殊条件测试
- while语句
- until语句
- for语句
- break和continue
- exit
- 8.函数
- SHELL脚本题目
- 第六章
- gcc编译系统
- 文件名后缀
- c语言编译过程
- 预处理阶段
- 编译阶段
- 汇编过程
- 连接阶段
- gcc命令行选择
- 动态静态链接库(重点)
- gdb程序调试程序(重点)
- 启动gdb和查看内部命令
- 显示源程序和数据
- 显示和搜索源程序
- 查看运行时数据
- 改变和显示目录或路径
- 控制程序的执行
- 程序维护工具make
- make的工作机制
复习以ppt和实验为主
燕大linux复习资料
不要背记,要多写代码实操
此处给出几个参考链接:
Linux实验 教材 Linux 教程 第5版 燕山大学_cfreeze的博客-CSDN博客
linux(Ubuntu发行版)文件命名 目录文件.和… 索引式文件系统 目录树 linux系统怎么找到某个文件 挂载分区后目录下文件消失了_cfreeze的博客-CSDN博客
linux Ubuntu 为什么最多有4个主分区 主分区最大为什么2T 扩展分区和逻辑分区的关系 sda1、hda1、nvme0n1p1的含义_linux mint分区_cfreeze的博客-CSDN博客
linux
第一章
Linux历史
要记住人名会考。
1965年 Unix原型Unics (Thompson)汇编语言编写,但因对硬件有依赖性,没安装到不同机器就要重写汇编语言。
1973年 Unix(Thompson与Ritchie) C语言重新改写编译(90%C语言和10%汇编)。
1984年 x86架构的Minix(Andrew Tanenbaum(谭宁邦)教授)通过购买磁盘使用。
1984年 Richard Stallman开始GNU(GNU’s Not Unix)计划, 目的是:建立一个自由、开放的Unix操作系统。Stallman认为,既然程序是想要分享给大家使用的,那么该程序的源代码就应该要同时释出,那么将会有很多人使用,队伍会越来越大!由于单打独斗创立一个Unix系统很不容易,所以先开发在Unix上面运行的小程序:GNU C (GCC)、Bash shell等。GNU软件缺乏一个开放的平台运行,只能在Unix上运行。
1984年之二:GNU计划与GPL版权声明。GNU的通用公共许可证:1985年,为了避免GNU所开发的自由软件被其他人所利用而成为专利软件, 所以他与律师草拟了有名的通用公共许可证(General Public License, GPL)。
GPL的《版权宣告》:Free Software(自由软件)是一种自由的权力,并非是价格。但是并不意味着没有商业行为。
自由软件是指用户可以对软件做任何修改,甚至再发行,但是始终要挂着GPL的版权;自由软件是可以卖的,但是 不能只卖软件,而是卖服务、手册 等。
1991年:Linux的诞生 Linus Torvalds在BBS上面贴了一则消息, 宣称他参考标准POSIX规范,写了一个小小的核心程序,可以在Intel的386机器上面运作, Linux从此诞生!因托瓦兹放置核心的那个FTP网站的目录为:Linux, 从此大家便称这个核心为Linux。
影响Linux发展的重要事件:
(1) Unics系统诞生(1969):简化高效的分时系统;
(2) C语言与Unix诞生(1973):Unix类操作系统跨平台移植;
(3) Minix诞生(1984):操作系统代码开源和x86架构支持;
(4) GNU和GPL(1984):保证开源系统的持续发展;
(5) Linux诞生(1991):按照POSIX规范重新编写了Minix系统(即Linux),使得Linux系统通过BBS广泛传播。
版本选择
Linux有两种版本:核心(Kernel)版和发行(Distribution)版。
核心版本的序号由三部分数字构成,其形式为:
major.minor.patchlevel
主版本号.次版本号.修订次数
例如:2.2.11表示对核心2.2版本的第11次修订。
约定:次版本号为奇数时,表示该版本加入新内容,但不一定很稳定,相当于测试版;次版本号为偶数时,表示这是一个可以使用的稳定版本。
发行版有:Ubuntu、CentOS、Redhat、红旗Linux等等
计算机硬件(不考)
1.频率是CPU每秒钟可以进行的工作次数,为倍频与外频的乘积。
外频指的是CPU与外部组件进行数据传输时的速度;
倍频是 CPU 内部用来加速工作效能的一个倍数。
举例:外频是333MHz,倍频则是9倍,因此CPU的频率是3.0GHz, (3.0G≈333Mx9, 其中1G≈1000M)。
2.CPU字长:CPU每次能够处理的数据量称为字长(word size), 字长大小依据CPU的设计而有32位与64位,二级制的上标指的就是CPU的位数。
因此,32位系统最大支持4G的内存!
3.内存越大代表系统越快,因为系统不用常常释放一些内存内部的数据。
计算机软件(不考)
软件是相对硬件而言的,它是与数据处理系统操作有关的计算机程序以及相关数据等的总称。
程序是计算机完成一项任务的指令的集合。
数据是由程序使用或生成的不同类型的信息。
硬件是软件建立与活动的基础,软件是对硬件功能的扩充。
软件通常可分为三大类,即系统软件、应用软件和支撑软件。
系统分区
-
Linux 通过字母和数字的组合来标志硬盘分区,sd 、 hd、 nvme表示的是设备类型。如:hd表示IDE硬盘, sd表示 SCSI/SATA/USB硬盘,而nvme表示的就是nvme硬盘。
-
sda 的 a 和 sdb 的 b分别表示 第一块SCSI硬盘,第二块SCSI硬盘, hda、hdb也是同样。那么nvme[x]n[y]的[y]表示的是第几块硬盘。
-
最后的数字[x]表示的是主分区或者扩展分区(1~4),逻辑分区从5开始。
-
举例:sdb2,是第二块SCSI硬盘上的第二个主分区或者扩展分区。
-
[y]表示的是硬盘插槽。
-
能够被格式化后,作为数据存取的分区为主要分区与逻辑分区,即扩展分配无法格式化;
-
逻辑分区的数量依操作系统而不同,在Linux系统中,IDE硬盘最多有59个逻辑分割(5号到63号), SATA硬盘则有11个逻辑分割(5号到15号)
-
给磁盘分 6 个分区,请给出主分区、扩展分区、逻辑分区的组合分区的3个方案,并给出分区号(默认第二个SATA硬盘)。
3 主(sdb1,sdb2,sdb3)+1扩(sdb4)+3 个逻辑(sdb5,sdb6,sdb7)
2 主(sdb1,sdb2)+1扩(sdb3)+4 逻辑(sdb5,sdb6,sdb7,sdb8)
1 主(sdb1)+1扩(sdb2)+5 逻辑(sdb5,sdb6,sdb7,sdb8,sdb9)
7.如果安装Linux 最少需要哪两个分区?选择什么文件系统类型?
①根文件系统分区(/),类型为ext3等;
②交换分区,类型为swap。
-
①BIOS:启动主动运行的韧体,会认识第一个可启动的装置;
②MBR:第一个可启动装置的第一个磁区内的主要启动记录区块,内含启动管理程序; MBR这个仅有446 bytes的硬盘容量里面会放置最基本的启动管理程序
③启动管理程序(boot loader):一支可读取核心文件来运行的软件;(EFI)
④核心文件:开始操作系统的功能…
9.CMOS是记录各项硬件参数且嵌入在主板上面的储存器,BIOS则是一个写入到主板上的一个固件(再次说明, 固件就是写入到硬件上的一个软件程序)。这个BIOS就是在启动的时候,计算机系统会主动运行的第一个程序了!
安装
1.硬盘20G
2.内存1024MB,1G
3.NAT
4.1个分区作为主分区,挂载点设置为“ / ”目录(类型为EXT3)将除了交换分区和空闲分区以外的空间都分配给它;
1个分区作为交换分区(swap),空间大小为虚拟机内存的1.5-2.0倍;(2G)
1个分区留着作为空闲分区,用于后续练习“挂载”操作使用。
实验一
1.操作分区:sudo fdisk /dev/sda
2.重写磁盘分区表:partprobe /df -h命令可查看分区挂载情况
3.格式化:(创建文件系统)mkfs -c -t ext4 /dev/sdb1(扩展分区不能格式化)
4.挂载:sudo mount 设备名(/dev/sda1) 目录名(/home/zxy/Documents)
5.开机自动挂载: /etc/fstab
交换分区(swap)
Swap 分区在系统的物理内存不够用的时候,把硬盘空间中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存到 Swap 分区中,等到那些程序要运行时,再从 Swap 分区中恢复保存的数据到内存中。(释放,存进swap,要用再从swap恢复)
手动创建Swap交换分区
创建一个新的分区(或选择一个已有的分区),将该分区设置为Swap分区,并保存分区设置;
格式化 Swap 分区;(mkswap命令)
启用(激活) Swap 分区;(swapon命令)
开机自动挂载 Swap 分区。(/etc/fstab文件)
/etc/fstab介绍
该文件中存在六列参数:
第1列:设备文件名
第2列:设备的挂载点(一般是空目录)
第3列:该分区文件系统的格式(如:ext4、swap等;参数auto,自动识别分区的分区格 式)
第4列:文件系统的参数,设置格式的选项,一般使用defaults
第5列:dump备份的设置(0表示不进行dump备份,1代表每天进行dump备份,2代表不 定日期的进行dump备份)
第6列:磁盘检查设置(其实是一个检查顺序,0代表不检查,1代表第一个检查,2后续.一般 根目录是1,数字相同则同时检查)
向该文件中添加以下内容(新创建并挂载的分区每个对应一行):
/dev/sda5 /home/sda5 ext4 defaults 0 0
/dev/sda10 swap swap defaults 0 0
| 命令 | 作用 |
|---|---|
| fdisk /dev/sda | 操作分区 |
| partprobe | 重写磁盘分区表(将磁盘分区表变化信息通知内核,请求操作系统重新加载分区表) |
| df -h | 查看分区挂载情况(命令用于显示目前在 Linux 系统上的文件系统磁盘使用情况统计。df -h 可查看分区挂载情况) |
| mkfs -c -t ext4 /dev/sdb1 | 创建文件系统,格式化 |
| sudo mount /dev/sda1 /home/zxy/Documents | 挂载 |
| gedit /etc/fstab | 开机自动挂载 |
| mkswap /dev/sdb1 | 创建交换分区(用于格式化交换区(swap area),可将磁盘分区或文件设为Linux的交换区) |
| swapon /dev/sdb1 | 激活交换分区(用于激活Linux系统中交换空间,Linux系统的内存管理必须使用交换区来建立虚拟内存) |
第二章
常用命令
| 命令 | 输出 | 作用 |
|---|---|---|
| echo ‘I am zxy’ | I am zxy | 输出字符串包括空格 |
| echo I am zxy | I am zxy | 输出由空格隔开字符串 |
| who | 列出所有正在使用系统的用户、所用终端名和注册到系统的时间 | |
| who am i | 当前用户 | |
| date | 2020年 02月21 日 | 在屏幕上显示或设置系统的日期和时间 |
| cal | 输出任意一个年月的日历 | 日历 |
| cal 10(Oct) 2023 | 输出2023年10月日历 | 日历 |
| clear | 清除屏幕上的信息 | |
| passwd | 修改用户密码 |
索引结点
1.文件系统概念:
①文件与目录的定义
文件系统 、文件、目录 、子目录、文件名、路径名、当前工作目录
②文件结构
文件的成分——索引节点 + 数据节点
③文件命名:
▲尽量简捷有效
▲不要用斜线(/)和空字符(ASCII字符\0)
▲避免空格、制表符或其他控制字符。
▲习惯上允许使用下线符(_)和句点(.)来区别文件的类型 ,但是应避免使用以下有特殊含义的字符:
; | < > ˋ ″ ′ $ ! % & * ? \ ( ) [ ]
▲同类文件应使用同样的后缀或扩展名
▲Linux系统区分文件名的大小写,如letter和Letter不是一个文件
▲以圆点(.)开头的文件名是隐含文件
③目录文件:

43516731 . ⽂件.的innode number是43516731
(innode number在2.Linux的文件系统特性有解释)
43384921 … ⽂件…的innode number是43384921
43516732 passwd.png ⽂件passwd.png的innode number是43516732
每个目录的第一项都表示目录本身,并以 “ . ” 作为该目录本身的文件名,通过cd . ,可以到达本目录,而第二项的名字都是 “ … ” ,表示该目录的父目录。
假如当前目录为/home/zxy/Documents,执行 cd … ,就会进入/home/zxy目录。‘
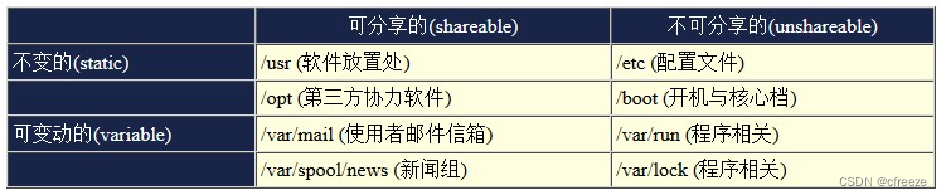
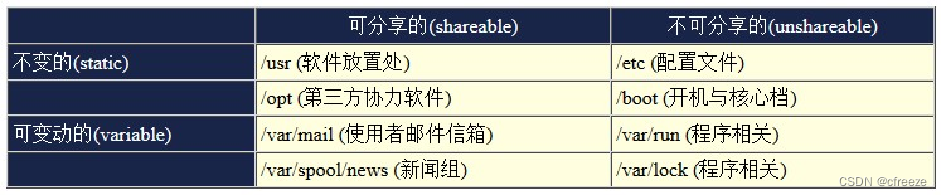
④代表性目录
/ (root, 根目录):与开机系统有关;
根目录是整个系统最重要的一个目录,因为不但所有的目录都是由根目录衍生出来的, 同时根目录也与开机/还原/系统修复等动作有关。
可分享的意思是多架构linux机器可共用,不需要修改的。

2.Linux的文件系统特性:
linux操作系统的文件数据除了文件实际内容外, 通常含有非常多的属性,例如 Linux 操作系统的文件权限(rwx)与文件属性(拥有者、群组、时间参数等。
文件系统通常会将这两部份的数据(实际内容和其他属性)分别存放在不同的区块,权限与属性放置到inode 中,至于实际数据则放置到 **data block (data node)**区块中。 若文件太大可能会占用多个数据块。
每个文件都会占用一个 inode ,inode 内则有文件数据放置的 block 号码。 因此如果能够找到文件的 inode 的话,那么就会知道这个文件的 block 号码, 也就能够读出该文件的实际数据了。
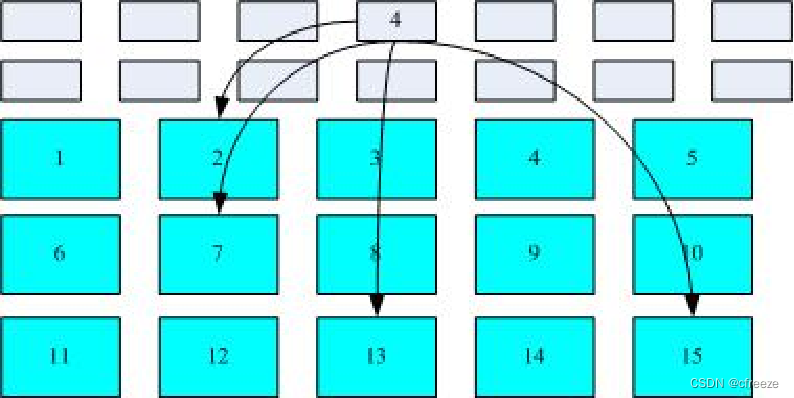
3.索引式文件系统(indexed allocation)
1.每一个文件都会和唯一的一个innode(索引节点)相对应。innode会对应一到多个data block(数据节点),存储的是多个data block的指针,通过指针并行的获取几个data block内的内容。data block存放的内容就是文件内的真实数据了。
2.FAT文件系统数据是链式的获取多个data block的内容
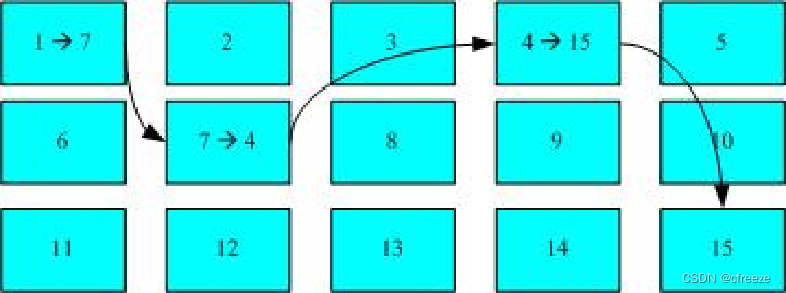
目录树
目录成分:索引节点和至少一块数据块。
inode 记录该目录的相关权限与属性,并可记录分配给目录的那块 block 号码; 而 block 则是记录在这个目录下的文件名与该文件名占用的 inode 号码数据。下图是block内容。
问题:
一、怎么找到m1.c这个文件?
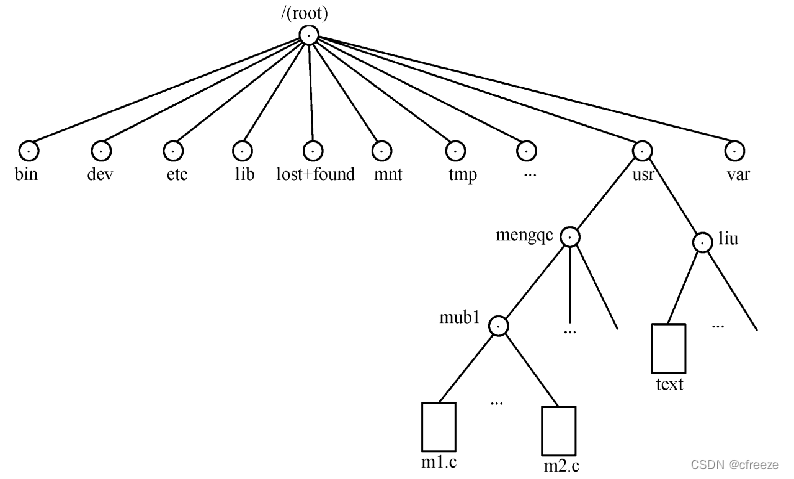
1.根目录的innode number是2(规定),获取根目录的data block(也就是文件名和结点号表格),从表格中获取/usr目录的innode number,获取/usr innode数据。
2.通过/usr的innode,获取/usr的data block(也就是文件名和结点号表格),从表格中获取/mengqc目录的innode number,获取/mengqc innode数据。
3.通过/mengqc 的innode,获取/mengqc 的data block(也就是文件名和结点号表格),从表格中获取/mub1目录的innode number,获取/mub1 innode数据。
4.通过/mub1的innode,获取/mub1 的data block(也就是文件名和结点号表格),获取m1.c的innode number,获取m1.c的innode。
5.通过m1.c的innode,获取其指向数据的data block指针,获取m1.c内的数据,即文件内容。
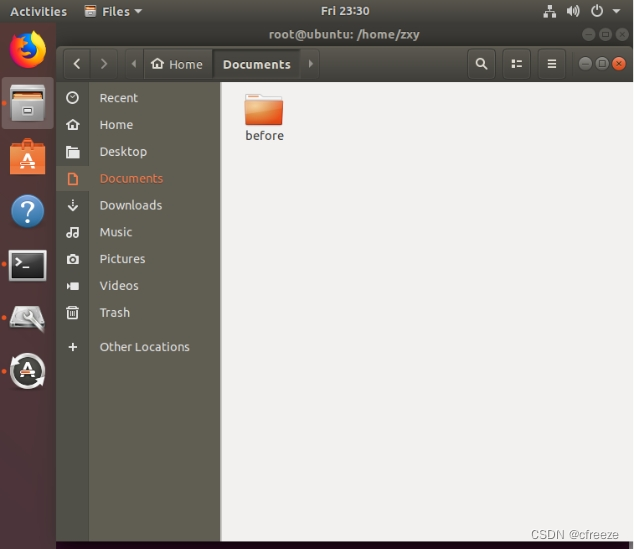
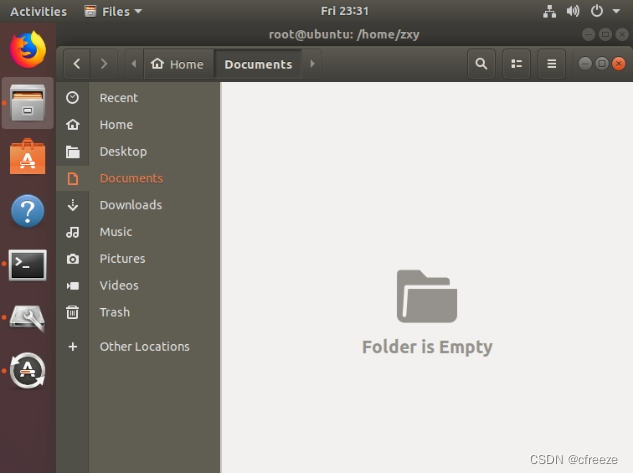
二、为什么把某个新分区挂载到某个目录后,该目录原本的文件会消失?
该问题预设场景:/home/zxy/Documents原挂载分区为/dev/sda6,后挂载新分区/dev/sdb2,原文件消失。
/home/zxy/Documents 挂载新分区前:
/home/zxy/Documents 挂载新分区后:

形象化解释:
原本before文件存放在名字叫/dev/sda6的盒子里,后来这个盒子从目录树上取下来了(解挂载),随之被一个空盒子/dev/sdb2替代了,那么现在再次进入/zxy/Documents后,就是相当于进入/dev/sdb2这个空盒子了,因此原本的before看起来消失了。
但其实before还存在,只是因为/dev/sda6这个盒子没挂到树上,所以无法访问,重新挂载这个盒子即可看到盒子里的内容,如before等。
三、文件系统与目录树的关系。(挂载)
2023年linux考试简答题:(将挂载)
所谓的**『挂载』就是利用一个目录当成进入点**,将磁盘分区槽的数据放置在该目录下; 也就是说,进入该目录就可以读取该分割槽的意思。这个动作我们称为『挂载』,那个进入点的目录我们称为挂载点。

文件操作命令
| 命令 | 输出&&选项 | 作用 |
|---|---|---|
| file 2.c | 查看文件类型 | |
| 有关文件显示命令处理的是文件,不是目录 | ||
| cat f1 cat f1 f2 cat f1 f2 >f3 cat -b f1 cat -n f1 | 1.显示文件f1内容 2.同时显示文件f1和f2的内容 3.将文件f1和f2合并起来放入文件f3 4.从1开始对所有非空输出行编号 5.从1开始对所有输出行编号 | |
| more -dc f1 more -c -10 f1 | -dc -c N | 该命令一次显示一屏文本,满屏后停下来, 并且在屏幕的底部出现一个提示信息, 给出至今已显示的该文件的百分比:–More–(XX%) [Press space to continue,‘q’ to quit.] -num,这个选项指定一个整数,表示一屏显示多少行。 |
| -d,在每屏的底部显示以下更友好的提示信息: | ||
| +num,从行号num开始。 | ||
| less | less命令允许用户向前或向后浏览文件,而more命令只能向前浏览 | |
| head | head命令在屏幕上显示指定文件的开头若干行,行数由参数值来确定。显示行数的默认值是10。 | |
| head -5 file | -num | 显示文件file前5行内容 |
| tail | tail命令在屏幕上显示指定文件的末尾10行。如果没有指定文件或者文件名为“-”,则读取标准输入。 | |
| tail file | 显示文件后十行 | |
| tail +20 file | +num | 显示文件从第二十行到末尾 |
| tail -5 file | -num | 显示文件后5行内容 |
| tail -c 10 file | -c N | 显示文件最后十个字符(最后10字节) |
| touch | 修改文件的时间或创建一个空文件夹 | |
| touch file | 创建一个名为file的空文件夹(file文件在创建前不存在) | |
| touch file | 将file的时间标签更新为系统当前的时间 | |
| touch -t 200409011300 file | -t | 修改file的时间标签为2004-09-01 13:00 |
| -m | 仅改变指定文件的修改时间 | |
| -a | 仅改变指定文件的存取时间 | |
| 匹配、排序及显示指定内容命令 | ||
| grep 行信息 | 该命令用来在文本文件中查找指定模式的词或短语,并在标准输出上显示包括给定字符串模式的所有行。 | |
| grep -F mengqc /etc/passwd | -F | 从/etc/passwd中匹配mengqc的行并显示 |
| grep -i ’ main | printf’ f1 f2 | -i | 匹配比较时不区分字母的大小写 |
| -r | 以递归方式查询目录下的所有子目录中的文件 | |
| -n | 在输出包含匹配模式的行之前,加上该行的行号。 | |
| grep -E ’ [Mm]ain | [Pp]rintf’ f1 f2 | -E | 在文件f1和f2内不区分首字母大小写查找包含main和printf的所有行 |
| grep ‘zhangsan’ | ||
| sort(不考) | 用来对文本文件的各行进行排序,排序比较是依据从输入文件的每一行中提取的一个或多个排序关键字进行的 | |
| -u | 对排序后的重复行只输出第一行 | |
| cat seq.txt | banana apple pear orange pear | 打印seq.txt内容 |
| sort seq.txt | apple banana orange pear pear | 对seq.txt排序 |
| sort -u seq.txt | apple banana orange pear | 重复行只输出一行 |
| uniq(不考) | 读取输入文件,比较相邻的行,去掉重复的行,只留下其中的一行。 (空白行也算) | |
| 1 2 2 3 | **-c ** 1 1 2 2 1 3 | 显示输出时,在每行的行首加上该行在文件中出现的次数。 |
| -d 2 | 只显示重复行。 | |
| -u 1 3 | 只显示文件中不重复的行。 | |
| 比较文件内容的命令 | ||
| comm(不考) | 对两个已经排好序的文件进行比较同与不同。 | |
| -123 | 选项1,2和3分别表示不显示comm输出中的第一、二、三列 | |
| comm r3 r4 | 第一列:文件1有2没有 第二列:文件2有,1没有 第三列:文件1.2都有 | 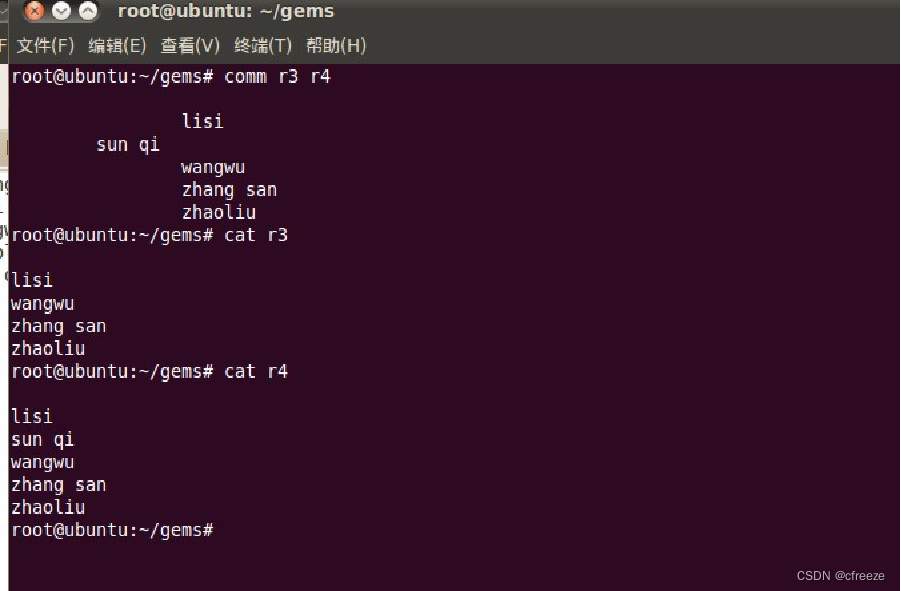 |
| diff(不考) | 比较两个文本文件,并找出它们的不同。并告诉用户为了使两个文件一致,需要修改它们的哪些行。 如果两个文件完全相同,则该命令不显示任何输出。 | |
| -b | 忽略空格造成的差别。 | |
| -i | 忽略字母大小写的区别。 | |
| -r | 当文件file1 和文件file2都是目录时,递归比较各子目录。 | |
| n1 a n3,n4 | (把文件1的n1行附加到文件2的n3-n4后,则相同) | |
| n1,n2 d n3 | (删除文件1的n1-n2行及文件2的n3行,则相同) | |
| n1,n2 c n3,n4 | (把文件1的n1-n2行改为文件2的n3~n4行,则相同) | |
| 复制、删除和移动文件的命令 | ||
| cp | 将源文件或目录复制到目标文件或目录中 | |
| cp -i /home/zxy/m*.c /home/temp | -i | 在覆盖目标文件之前先给出提示,要求用户予以确认。回答y,将覆盖目标文件。这是交互式复制。 将/home/zxy下的所有以m开头的.c文件复制到目录/home/temp下 |
| cp -r /home/zxy /home/temp | -r | 将目录下所有的文件和子目录都复制到目标位置 |
| -p | 除复制源文件的内容外,还将其修改时间和存取权限也复制到新文件中。 | |
| cp file /home/zxy/file1 | 将当前目录下的file复制到/home/zxy目录下并改名为file1 | |
| * 注意WARN * | 1.所有目录必须是已经存在的,cp命令不能创建目录。 2.若文件没有复制权限,则系统会显示出错信息,需要用chmod修改文件权限。 | |
| rm | 删除文件和目录 | |
| rm -d /home/zxy | -d | 删除目录,不管它是否为空(仅超级用户才可使用)。 |
| -r | 递归地删除指定目录及其下属的各级子目录和相应的文件。 | |
| mv | 对文件或目录重新命名,或者将文件从一个目录移到另一个目录中 | |
| mv file file1 | 把文件file重新命名为file1 | |
| mv /home/zxy/* . | 将目录/home/zxy/下的所有文件移动到当前目录下 | |
| * 注意WARN * | cp是复制,mv是移动 | |
| 文件内容统计命令 | ||
| wc | 统计指定文件的字节数、字数、行数,并将统计结果显示出来 | |
| -c | 统计字节数 | |
| -l | 统计行数 | |
| -w | 统计字数 | |
| wc ex1 ex2 wc ex1 wc ex2 | 两者等价 | 输出ex1,ex2的字节数,行数,字数 |
| wc -lcw ex1 wc ex1 | 两者等价 | 输出ex1的字节数,行数,字数 |
| 创建和删除目录的命令 | ||
| mkdir [选项] dirname | 创建由dirname命名的目录 | |
| mkdir -m 700 /home/zxy/file | -m 数字 | 对新建目录设置存取权限,存取权限用给定的八进制数字表示。 对于file来说只有文件主有读写执行权限 |
| rmdir [选项] dirname | 从一个目录中删除一个或多个子目录 | |
| -p | 递归删除目录dirname,当子目录删除后其父目录为空时,也一同被删除。如果有非空的目录,则该目录保留下来。 | |
| 改变工作目录和显示目录内容的命令 | ||
| cd [dirname] | 改变当前工作目录 | |
| cd /home/zxy | 切换当前目录到/home/zxy | |
| pwd | 显示出当前工作目录的绝对路径 | |
| ls | 如果给出的参数是目录,该命令将列出其中所有子目录与文件的信息;如果给出的参数是文件,将列出有关该文件属性的一些信息 | |
| -a | 显示指定目录下所有子目录和文件,包括以“.”开头的隐藏文件(如 .cshrc)。 | |
| -i | 输出的第一列显示文件的I节点号。 | |
| -l | 以长格式显示文件的详细信息。输出的信息依次是: | |
| 文件类型与权限 链接数 文件主 文件组 文件大小 建立或最近修改的时间 文件名 | ||
例如:-rw-r–r-- 2 mengqc group 198 Jul 30 2001 csh1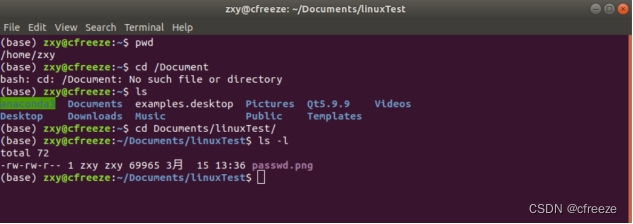 | ||
| 文件压缩和解压缩命令 | ||
| gzip | 对文件进行压缩和解压缩。 | |
| gzip file | file.gz | 压缩file |
| gzip -d file.gz | file -d | 解压file |
| gzip -l * | -l | 列出压缩文件、未压缩文件的大小,压缩比等信息,但不解压缩。 |
| gzip -r /home/zxy | -r | 递归地压缩(或解压)指定目录的所有文件 |
| -num | 指定压缩速度(压缩比),-1表示高速压缩(低压缩比),-9表示低速压缩(高压缩比),默认为-6. | |
| 生成的文件名为.gz | ||
| unzip [选项] 被压缩的文件名 | 该命令可以列出、测试和抽取zip文件格式的压缩文件。Zip文件通常是在windows下进行压缩的。 | |
| -x 文件列表 | 对列表中以外的文件进行解压缩 指定不要处理.zip压缩文件中的哪些文件 | |
| unzip -d /home/zxy/Download windows.zip | -d 目录 | 解压到指定目录中 |
| -j | 将所有文件解压到同一层目录下 ,废除原压缩文件的目录结构 | |
| 有关进程管理的命令 | ||
| ps [选项] | ||
| -a | 显示系统中与tty相关的所有进程的信息 | |
| -e | 显示所有进程的信息 | |
| -f | 显示进程的所有信息 | |
| -l | 以长格式显示进程信息 | |
| -r | 只显示正在运行的进程 | |
| ps | 无选项 | 列出每个与当前shell有关的进程的基本信息 |
| kill | ||
| -p | 指定kill命令只是显示进程的PID(进程标志号),并不真正发出结束信号。 | |
| kill pid | 结束某个进程 | |
| sleep 时间值 | “时间值”参数以秒为单位,即让进程暂停由时间值所指定的秒数 | |
| sleep 100; who | grep ‘zhangsan’ | 暂停100s后,将who输出内容传递给grep,找到包含zhangsan的行输出到终端 | |
| 联机帮助命令 | ||
| man | 格式化并显示某一命令的联机帮助手册页 | |
| man sleep | 显示sleep命令的手册业 | |
| help | 用来查看所有shell内置命令的帮助信息 | |
| help cd | ||
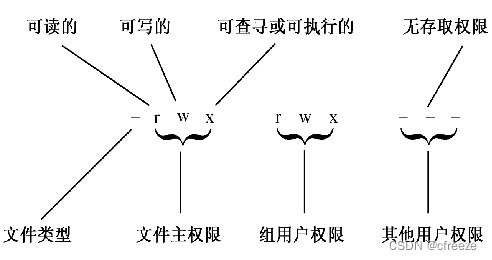
| 改变文件或目录存取权限的命令 | ||
 | ||
 | ||
| chmod u+x,g+x,o+x ex1 chmod u=rwx,g=rwx,o=rwx ex1 |  | |
| chmod 777 ex1 |  | |
| umask u=,g=w,o=rwx |  | |
| chgrp |  | |
| chown |  | |
实验二
重要实验总结如下,其他实验请查阅实验报告:
一.使用cd命令,将工作目录改到根(/)上。运行ls –l命令,结合教材中图2.2,了解各个目录的作用。
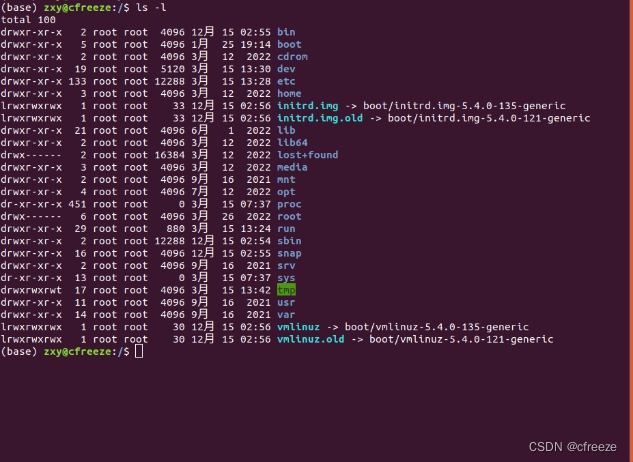
-
total 100
-
第⼀列是:d(-,p,l,b,c,s)rwxrwxrwx
d:⽬录⽂件eg:home
-:普通⽂件eg:passwd.png
p:管理⽂件
l:链接⽂件
b:块设备⽂件
c:字符设备⽂件
s:套接字⽂件
r:可读(“-”不可读)
w:可写(“-”不可写)
x:可执⾏(“-”不可执⾏)
前三个rwx是所有者权限
中间三个rwx是组⽤户权限
后三个rwx是其他组⽤户权限
3.第二列:(1)、如果是⽬录的话,这个数字表⽰当前这个⽬录下⾯的⼀级⽬录个数。(2)、如果 是⽂件的话,数字表⽰硬链接个数。(硬链接个数:可以简单的理解为⼀个⽂件的⽂件名 个数,⽐如a⽂件的⽂件名有s和j两个,因为s和j指向同⼀个a,改动s或j都会对a造成改变)
4、第三列:该文件或目录的所有者。
5、第四列:表示所属的组。
6、第五列:文件的⼤⼩。
7、第六列:月份(最近修改⽂件的⽇期)。
8、第七列:多少号(最近修改⽂件的最后⽇期)。
9、第⼋列:几点(最近修改⽂件的最后⽇期)。
10、第九列:
白色:表示普通文件
蓝色:表示目录
绿色:表示可执行文件
红色:表示压缩文件
蓝绿色:链接文件
红色闪烁:表示链接的文件有问题
黄色:表示设备文件
灰色:表示其他文件



二、运行man date>>file1,看到什么信息?运行cat file1,看到什么信息?
“>”表⽰输出重定向,“>>”表⽰追加重定向。
先 date > file1,再man date >> file1
先将当前时间存入file1,再把date的帮助文档存入file1,>>不会覆盖原内容。
三、权限管理
1、使用图1中的分组创建组,并将相应的学生添加到相应分组
1)创建组
sudo groupadd designing
sudo groupadd coding
sudo groupadd testing
2)查看创建组是否成功
tail /etc/group
3)将学生添加到分组
sudo useradd -g designing zhao
sudo useradd -g designing qian……
4)检查学生是否已添加到分组
groups zhao
groups qian……
2、所有目录都保存在同一的文件夹下/LinuxDemo
cd /
mkdir LinuxDemo
3、每个分组拥有独立的文件夹
cd LinuxDemo
mkdir designing
mkdir coding
mkdir testing
4、不同组之间不可访问各自的文件夹
5、每个学生在所在组的文件夹下拥有一个所属的文件夹
6、同组不同学生之间可以查看各自文件夹的内容,但不可以修改,学生只能修改自己的文件内容
//设置学生文件的文件主
sudo chown zhao /LinuxDemo/designing/zhao //设置zhao是zhao文件夹的文件主,通过文件主(zhao)和同组(qian)和其他用户(sun li ……)来区分权限
sudo chown qian /LinuxDemo/designing/qian……
//设置权限 同组可查看不可修改(5)不同组不可访问(0)
cd /LinuxDemo/designing
chmod 750 zhao
chmod 750 qian……
//设置文件权限
cd …
chmod 770 designing/
第三章
文本编辑器Vi及其工作模式
1.进入vi编辑器:vi + 文件名
2.退出vi编辑器:按ESC键后,强制保存退出(:wq!)或强行退出(:q!)
3.感叹号(! )告诉vi,无条件退出,丢弃缓冲区内容。
如何三种方式间切换(如下图):
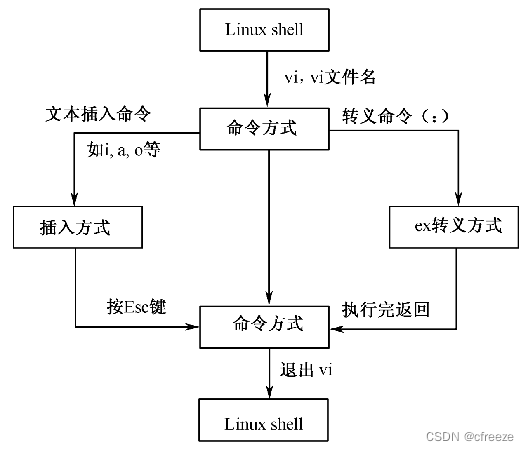
vi的工作方式
vi编辑器有三种工作方式:命令方式、输入方式和ex转义方式
命令/输入方式
通过输入vi的插入命令( i )、附加命令( a )、打开命令(o)、替换命令( s )、修改命令( c )或取代命令( r )可以从命令方式进入到输入方式
由输入方式回到命令方式的办法是按下< Esc >键
下面的命令考试考的很少,大概记忆即可。
| 命令 | 作用 |
|---|---|
| 文本输入命令 | |
| i | 1.内容都插在光标位置之前 2.光标后的文本相应向右移动。 3.如按下Enter键,就插入新的一行或者换行。 |
| I(大写i) | 1.在当前行(即光标所在行)的行首插入新增文本 2.行首是该行的第一个非空白字符 3.当输入I命令时,光标就移到行首。 |
| a | 在光标之后插入,光标可在一行的任何位置。 |
| A | 在光标所在行的行尾添加文本 |
| o | 在光标所在行的下面插入一行 |
| O | 在光标所在行的上面插入一行 |
| 文本修改命令 | |
| 修改文本 | |
| c | 删除从所在行到第x行再接受新输入(c[x]G) |
| C | 修改从光标开始到行末的文本 |
| 删除字符的命令 | |
| x | 删除光标所在的字符 |
| X | 删除光标前面的那个字符 |
| 删除文本对象的命令 | |
| dd | 删除光标所在的整行 |
| D | 从光标位置开始删除到行尾 |
| d<光标移动命令> | 从光标位置开始删到由光标移动限定的文本对象的末尾 |
| 复原命令 | |
| u | 如果插入后用u命令,就删除刚插入的正文;如果删除后用它,就相当于又插入刚删除的正文 |
| U | 把当前行恢复成它被编辑之前的状态,不管你把光标移到该行后对它编辑了多少次 |
| 重复命令 | |
| . | 重复实现刚才的插入命令或删除命令 |
| 取代命令 | |
| r | 命令用随后打入的单个字符取代光标所在的字符 |
| R | 命令用随后打入的文本取代光标位及其右面的若干字符,每打入一个字符就替代原有的一个字符。 |
| 替换命令 | |
| s | 命令用随后打入的正文替换光标所在的字符 |
| S | 命令用新打入的正文替换当前行(整行 |
编辑文件
编辑已存文件的最常用方式是:
$ vi 文件名
从某一指定行进入vi。其格式是:
$ vi +行号 文件名
从某一指定词进入vi。其格式是:
$ vi +/词 文件名
编辑多个文件
可以同时调入多个文件,依次对它们进行编辑。其命令格式是:
$ vi 文件1 文件2…
当完成对第一个文件的编辑及存盘(用:w命令)后,输入命令:n就进入第二个文件。
字符串检索
实验三
无重要内容,掌握上面总结的vi的三种工作方式及其转换,和部分重点文本修改命令即可。
第四章
1.shell脚本的建立和执行
执行shell脚本的方式:
执行shell脚本的方式基本上有三种:
(1)输入定向到shell脚本
$ bash < 脚本名
(2)以脚本名作为参数
其一般形式是: $ bash 脚本名 [参数]
(3)将shell脚本的权限设置为可执行,然后在提示符下直接执行它。
chmod a+x ex2
PATH= P A T H : . ( P A T H = PATH:. (PATH= PATH:.(PATH=PATH:/root/chapter4)
ex2
注意:此时该脚本所在的目录应被包含在命令搜索路径中,即包含在环境变量PATH中。若不设置环境变量,则可以使用./等形式来指定脚本所在目录。
若需要一直有效,那么需要执行export PATH。
#①
bash < shell.sh
#②
bash shell.sh 1 2 3
./shell.sh 1 2 3
#③
chmod a+x shell.sh
PATH=$PATH:/zxy/LinuxShellFolder #或者PATH=$PATH:.
shell.sh #或者shell.sh
2.查看本机正在使用的shell种类
echo $SHELL
3.历史命令
在默认方式下,bash使用用户主目录下面的文件“.bash_history”来保存命令历史
改变存放历史命令的**文件 **
$ HISTFILE="/home/mengqc/.myhistory"
重新设定能够**保留的命令个数 **
$ HISTSIZE=600
命令
| 命令 | 输出/选项 | 作用 |
|---|---|---|
| 显示历史命令 | ||
| **history ** | 显示历史命令 | |
| history | 无选项 | 命令会显示历史命令的清单 |
| history 50 | 只显示历史表中的最后50行命(即最近执行的50条命令) |
4.shell特殊字符
通配符
| 通配符 | 含义 | 例子 |
|---|---|---|
| *(星号) | 匹配任意字符的0次或多次出现 | f* f、fa、fb、fbbb |
| ?(问号) | 匹配任意一个字符 | f? fa、fb 不能匹配f |
| [ ](一对方括号) | 其中有一个字符组 其作用是匹配该字符组所限定的任何一个字符 | f[a-d] fa、fb、fc、fd |
| !(惊叹号) | 如果它紧跟在一对方括号的左方括号([)之后 则表示不在一对方括号中所列出的字符 | f[!0-9] fa、fb、fbb fa0也不能被列出,因为其中包含0 |
引号
| 引号 | 含义 | 例子 |
|---|---|---|
| 双引号 | 由双引号括起来的字符均作为普通字符对待。 除KaTeX parse error: Undefined control sequence: \) at position 14: 、倒引号(` )和反斜线(\̲)̲外。<br />表示变量替换 ``表示命令替换 \转义字符,只有其后为$,倒引号,",\时,否则\为普通字符。 | echo “floder is ‘$HOME’ ” ‘单引号’再“双引号”中只是普通字符,不会把其内内容看做普通字符串。 |
| 单引号 | 由单引号括起来的字符都作为普通字符出现。 | 没有例外,全看做普通字符,包括$、倒引号(` )和反斜线(\)外。 |
| 倒引号 | 倒引号括起来的字符串被shell解释为命令行 在执行时,shell会先执行该命令行 并以它的标准输出结果取代整个倒引号部分。 倒引号还可以嵌套使用。但应注意, 嵌套使用时内层的倒引号必须用反斜线(\)将其转义。 | Nuser=反引号echo the number is \ 反引号 who | wc -l\反引号反引号 echo $ Nuser 结果是:the number is 5 |
| \ | 可以把特殊字符变成普通字符 | 想用" \ "本身就要输入 "\ \ " |
输入/输出重定向符
执行shell时自动打开三个标准文件,即标准输入文件(stdin),标准输出文件(stdout)和标准出错输出文件(stderr)。
1.输入重定向符
一般形式是:命令 < 文件名 如:$ score < file1
2.输出重定向符
一般形式是:命令 > 文件名 如:$ who > abc
输入和输出重新定向可以连在一起使用。例如:
$ wc -l < infile > outfile
3.输出附加定向符 “ >> ” ,若指定文件名不存在则新建
注释、管道线和后台命令
1.注释:#!/bin/bash反映了该脚本使用哪一种shell编写的,#开头的正文表示注释
2.管道线:前一个命令的输出是下一个命令的输入。
ls | grep "m?.c“ | wc –l
# 将本目录下的m?.c的文件数输出到终端
3.后台命令
gcc 1.c& #&表示的是在后台启动该程序
命令执行操作符
1.顺序执行
在执行时,以分号隔开的各条命令从左到右依次执行
pwd ; who | wc -l ; cd /usr/bin
#等价
pwd
who | wc -l
cd /usr/bin
2.逻辑与
格式:命令1 && 命令2
功能:先执行命令1,如果执行成功,才执行命令2;
否则,若命令1执行不成功,则不执行命令2。
若命令执行成功时返回值为0,执行不成功,返回非零值
3.逻辑或
格式:命令1 || 命令2
功能: 先执行命令1,如果执行不成功,则执行命令2;
否则,若命令1执行成功,则不执行命令2。
成组命令
{空格----;}和(-----)的重要区别用花括号括起来的成组命令只是在本shell内执行命令表,不产生新的进程;而用圆括号括起来的成组命令是在新的子shell内执行,要建立新的子进程。
5.shell变量
用户定义的变量
1.变量名是以字母或下线符打头的字母、数字和下线符序列,并且大小写字母意义不同。(区分大小写)
eg:2a(×)、_2a(√)、a12(√)等等
2.定义变量并赋值的一般形式是:
变量名=字符串 (赋值语句中,”=“两边没有空格)
3.引用变量值:在变量名前面加上一个符号“$”
如果在赋给变量的值中要含有空格、制表符或换行符,那么,就应该用双引号把这个字符串括起来。
names=“Zhangsan Lisi Wangwu”
echo $names
4.如果变量值须出现在长字符串的开头或者中间,为了使变量名与其后的字符区分开,避免shell把它与其它字符混在一起视为一个新变量,则应该用花括号将该变量名括起来。例:
$ dir=/usr/meng
$ cat ${dir}qc/m1.c
5.命令替换
有两种形式的命令替换:一种是使用倒引号引用命令,其一般形式是: ''命令表`
dir=`pwd`
另一种形式是:$(命令表)
dir=$(pwd)
echo $(pwd ; cd /home/mengqc ; ls -d)
数组
1.赋值
数组名[下标]=值
赋初值的一般形式是:数组名=(值1 值2 … 值n)****其中,各个值之间以空格分开,用 小括号框其数值。
city[0]=beijing
city=(beijing shanghai tianjin)
2.显式声明
declare命令显式声明一个数组,一般形式是:declare -a 数组名
3.输出&读取
读取数组元素值的一般格式是:${数组名[下标]}
echo ${city[0]} # 读取city数组第一个值
echo ${city[*]} # 读取city数组所有内容
echo ${city[@]} # 等价[*]
4.取消一个数组的定义
unset city[0] # 取消city[0]定义
unset city==unset city[*]==unset city[@] # 取消city定义
变量引用
$name
${name}
n a m e [ n ] = = {name[n]} == name[n]=={name[*]}==
${name [@]}
①表达式 n a m e 表示变量 n a m e 的值,若变量未定义,则用空值替换。②表达式 name表示变量name的值,若变量未定义,则用空值替换。 ②表达式 name表示变量name的值,若变量未定义,则用空值替换。②表达式{name}将变量name的值替换。用花括号括起name,目的在于把变量名与后面的字符分隔开,避免出现混淆。替换后花括号被取消。
③${name[n]}表示数组变量name中第n个元素的值。
④表达式 n a m e [ ∗ ] 和 {name[* ]}和 name[∗]和{name[@]}都表示数组name中所有非空元素的值,每个元素的值用空格分开。如果用双引号把它们都括起来。
那么二者的含义就有区别:对于" n a m e [ ∗ ] " , 它被扩展成 ∗ ∗ 一个词 ∗ ∗ ( 即字符串 ) ,这个词由以 ∗ ∗ 空格 ∗ ∗ 分开的各个数组元素组成;对于 " {name[*]}",它被扩展成**一个词**(即字符串),这个词由以**空格**分开的各个数组元素组成;对于" name[∗]",它被扩展成∗∗一个词∗∗(即字符串),这个词由以∗∗空格∗∗分开的各个数组元素组成;对于"{name[@]}",它被扩展成多个词,每个数组元素是一个词。如果数组name中没有元素,则${name[@]}被扩展为空串。
$person=("zhangsan" "lisi" "wangwu")
$for i in "${name[*]}"; do echo $i; done
zhangsan lisi wangwu
$for i in "${name[@]}"; do echo $i; done
zhangsan
lisi
wangwu
输入/输出命令
1. read命令
功能:利用read命令从键盘上读取数据,然后赋给指定的变量。
格式:read 变量1 [ 变量2 …]
① 变量个数与给定数据个数相同,则依次对应赋值
② 变量个数少于数据个数,则从左至右对应赋值,但最后一个变量被赋予剩余的所有数据。
③ 变量个数多于给定数据个数,则依次对应赋值,而没有数据与之对应的变量取空串
# ①
$ read a b c
today is monday
$ echo $c $b $a
monday is today
# ②
$ read a b
my name is zxy
$ echo $b $a
name is zxy my
# ③
$ read a b c
1 2
$ echo $c $b $a2 1
2. echo命令
功能:显示其后的变量值或者直接显示它后面的字符串
# -n/-e不换行
$echo -n "Login: "
$read name
# 关闭回显
$stty -echo
$echo -n "Password: "
$read passwd
$echo " "
# 打开回显
$stty echo
# 输出重定向
$echo $name $passwd > /tmp/ttt&
$sleep 2
$echo "Login Incorrect.Re-enter, Please. "
位置参数(重点)
位置参数及其引用
位置变量的名称很特别,分别是0,1,2,…
命令行实参与脚本中位置变量的对应关系如下所示:
exam1 m1 m2 m3 m4
$0 $1 $2 $3 $4 $5 $6 $7 $8 $9 ${10} ${11}
引用它们的方式依次是$0, $1, $2, …, $9, ${10}, ${11}等。
其中,$0始终表示命令名或shell脚本名。
▲位置变量不能通过一般赋值的方式直接赋值
▲通过命令行上对应位置实参传值
$ cat m1.c
int main()
{return 0;
}
$ cat m2.c
main()
{
}
$ cat ex1
cat $1 $2 $3 $4 $5 $6 | wc -l
$ ex1 m1.c m2.c
7
# cat m1.c和m2.c,统计输出了多少行,一共7行,故输出7
用set命令为位置参数赋值
但$0不能用set赋值,$0的值总是命令名。
set赋值是从$1开始依次往后给位置参数赋值的。
$ set `pwd;ls;date`
$ echo $1 $2 $3 $4 $5 $6
/home/zxy/Documents 1.txt 2.txt Fri Apr 14
# set `pwd;ls;date`
# 首先反引号``内包含的是三个命令
# 先执行三个命令
# 得到 /home/zxy/Documents 1.txt 2.txt Fri Apr 14 06:53:18 PDT 2023
# 共9个参数分别赋值给$1 $2 $3 $4 $5 $6 $7 $8 $9
移动位置参数(重要)
每执行一次shift命令,就把命令行上的实参向左移一位,即相当于位置参数向右
shift命令不能将$0移走,所以经shift右移位置参数后, $0的值不会发生变化。
shift命令可以带有一个整数作为参数 eg: shift
A B C D E F G H I
$0 $1 $2 $3 $4 $5 $6 $7 $8 $9
shift
$0 $1 $2 $3 $4 $5 $6 $7 $8 $9
shift 4
$0 $1 $2 $3 $4 $5 $6 $7 $8 $9
echo $0 $1 $2 $3 $4 $5 $6 $7 $8 $9
shift
echo $0 $1 $2 $3 $4 $5 $6 $7 $8 $9
shift 4
echo $0 $1 $2 $3 $4 $5 $6 $7 $8 $9$ ex8 A B C D E F G H I
A B C D E F G H I
B C D E F G H I
F G H I
预先定义的特殊变量(不重要)
KaTeX parse error: Expected 'EOF', got '#' at position 1: #̲ :命令行上参数的个数,但不包…#可以给出实际参数的个数。
$*:表示在命令行中实际给出的所有实参字符串。
$ @:它与$ *基本功能相同,即表示在命令行中给出的所有实参。但“ @ ”与“ @”与“ @”与“ *”不同。参考教材例子!
环境变量(不重要)
- 环境变量举例
HOME:用户主目录的全路径名
PATH: shell从中查找命令的目录列表。可以设置它,
如:PATH= P A T H : PATH: PATH:HOME/bin
PWD:你当前工作目录的路径
SHELL:你当前使用的shell
-
环境变量使用
$ HOME
6.算术运算
bash中执行整数算术运算的命令是let,其语法格式为:
let arg …
其中arg是单独的算术表达式。它使用C语言中表达式的语法、优先级和结合性。除++、–和逗号(,)之外,所有整型运算符都得到支持,此外,还提供了方幂运算符“** ”。
注意:在算术表达式中直接利用名称访问命名的参数,不要前面带有**“$”符号(见第二个例子),当表达式中有shell的特殊字符时,必须用双引号将其括起来**。例如,let ″val=a|b″(见 expr中的例子)
let 命令的替代表示形式是:
((算术表达式))
例如:
let ″j=i 6+2″ 等价于 ((j=i*6+2))*
注意:如果表达式的值是非0,那么返回的状态值是0;否则,返回的状态值是1。只有使用 $((算术表达式)) 形式才能返回表达式的值
比较三种算术运算的异同
# !/bin/bash
number=0
number=$((12*9))
echo "1 $number"
let "number=12*9"
echo "2 $number"
number=`expr 12 \* 9`
# 或者可以写作 number=`expr 12 "*" 9`
echo "3 $number"
# expr 部分每一部分中间的空格必不可少,*前加\是因为:当表达式中有shell特殊字符时,必须进行处理,否则会看作通配符,无法识别。
# !/bin/bash
# 在(()) 和 let 中访问命名参数不需要加$
# 在expr中需要加$符号。
number=0
temp=9
number=$((12*temp))
let "number=12*temp"
number=`expr 12 "*" $temp`
7.控制结构
if语句
条件测试可以使用一般命令执行成功与否作判断。如果命令执行成功,返回值为0,测试条件为真;如果命令执行不成功,返回值不为0,测试条件为假。
if语句的更一般形式是:
if 命令表1
then 命令表2
else 命令表3
fi
# ①
if
then
else
fi
# ②
if
then
fi
# ③
if
then
elif
then
……
elif
then
else
fi
#then 后是要做什么 elif 后面是检测什么
#else 相当于 default 条件全部不满足做什么
# !/bin/bash
if [ $1 -eq 1 ]
then echo "1"
elif [ $1 -eq 2 ]
then echo "2"
elif [ $1 -eq 3 ]
then echo "3"
else echo "default"
fi
$ ex1 4
default
$ ex1 1
1
# !/bin/bash
if [ $1 -eq 1 ]
then echo "1"
fi
$ ex1 4
$ ex1 1
1
条件测试

[[ xxx ]]在 “ [[ ” 的后面和 “ ]]” 前面应该有空格。
[ xxx ] 在 “[” 的后面和 “]” 前面应该有空格。
if语句和 “[[” 之间也应该有一个空格。
文件测试运算符
| 参 数 | 功 能 |
|---|---|
| -r 文件名 | 若文件存在并且是用户可读的,则测试条件为真 |
| -w 文件名 | 若文件存在并且是用户可写的,则测试条件为真 |
| -x 文件名 | 若文件存在并且是用户可执行的,则测试条件为真 |
| -f 文件名 | 若文件存在并且是普通文件,则测试条件为真 |
| -d 文件名 | 若文件存在并且是目录文件,则测试条件为真 |
| -b 文件名 | 若文件存在并且是块设备文件,则测试条件为真 |
| -c文件名 | 若文件存在并且是字符设备文件,则测试条件为真 |
| -s文件名 | 若文件存在并且文件的长度大于0,则测试条件为真 |
字符串测试运算符
z 等于零;n不等于0。
| 参 数 | 功 能 |
|---|---|
| -z s1 | 如果字符串s1的长度为0,则测试条件为真。 |
| -n s1 | 如果字符串s1的长度大于0,则测试条件为真。 |
| s1 | 如果字符串s1不是空字符串,则测试条件为真。 |
| s1 = s2 | 如果s1等于s2,则测试条件为真。“=”也可以用“==”代替。在**“=”前后应有空格**。 |
| s1 != s2 | 如果s1不等于s2,则测试条件为真。 |
| s1 < s2 | 如果按字典顺序s1在s2之前,则测试条件为真 |
| s1 > s2 | 如果按字典顺序s1在s2之后,则测试条件为真 |
数值测试运算符
e等于;n不;l小于;g大于;lt,gt;le,ge;eq,ne。
| 参 数 | 功 能 |
|---|---|
| n1 -eq n2 | 如果整数n1等于n2,则测试条件为真 |
| n1 -ne n2 | 如果整数n1不等于n2,则测试条件为真 |
| n1 -lt n2 | 如果n1小于n2,则测试条件为真 |
| n1 -le n2 | 如果n1小于或等于n2,则测试条件为真 |
| n1 -gt n2 | 如果n1大于n2,则测试条件为真 |
| n1 -ge n2 | 如果n1大于或等于n2,则测试条件为真 |
逻辑测试运算符
上述测试条件可以在if 语句或循环语句中单个使用,也可以通过逻辑运算符把它们组合起来使用。可以在测试语句中使用的逻辑运算符有:
🔺**!** 逻辑非( NOT ),它放在任意逻辑表达式之前,使原来为真的表达式变为假,使原来为假的变为真。例如,
[ ! -r $1 ] , ! test -r “$1”等。
🔺a 逻辑与( AND ),它放在两个逻辑表达式中间,仅当两个表达式都为真时,结果才为真。例如,
[ - f “ m y f i l e ” − a − r “ myfile” - a - r “ myfile”−a−r“myfile" ]
🔺o 逻辑或( OR ),它放在两个逻辑表达式中间,其中只要有一个表达式为真,结果就为真。例如,
[ “ a " − g e 0 − o " a" -ge 0 -o " a"−ge0−o"b” -le 100 ]
🔺**(表达式)** 圆括号,它可以把一个逻辑表达式括起来,使之成为一个整体,优先得到运算,且必须使用转义符。例如,
[ ( “KaTeX parse error: Can't use function '\)' in math mode at position 12: a" -ge 0 \̲)̲ -a \( "b” -le 100 ) ]
🔺逻辑表达式中的条件测试运算符优先级高于“!” 运算符,“!” 运算符的优先级高于“ -a”运算符,“-a”运算符高于 “-o”,而且圆括号( )高于 “-a”
# !/bin/bash
read a
if [ $a -lt 1 -o $a -gt 10 ]
then echo "Error"
exit
elif [ ! $a -lt 5 ]
then echo "no less 5"
else echo "less 5"
fi
# 两者等价
# !/bin/bash
read a
if [ "$a" -lt 1 -o "$a" -gt 10 ]
then echo "Error"
exit
elif [ ! "$a" -lt 5 ]
then echo "no less 5"
else echo "less 5"
fi
特殊条件测试
(1) :表示不做任何事情,其退出值为0。
(2)true 表示总为真,其退出值总是0。
(3)false 表示总为假,其退出值是255。
while语句
while 测试条件
do
命令表
done
# 测试条件部分除使用test命令或等价的方括号外
# 还可以是一组命令。根据其**最后一个命令的退出值**决定是否进入循环体执行。
# !/bin/bash
while [ $1 ]
do
if [ -f $1 ]
then echo "display:$1"
cat $1
else echo "$1 is not a file name"
fi
shift
done$ bash muma 1 2 3 4 5 6 muma
1 is not a file name
2 is not a file name
3 is not a file name
4 is not a file name
5 is not a file name
6 is not a file name
display:muma
# !/bin/bash
while [ $1 ]
do
if [ -f $1 ]
then echo "display:$1"
cat $1
else echo "$1 is not a file name"
fi
shift
done
until语句
until语句的一般形式是:
until 测试条件
do
命令表
done
它与while语句很相似,只是测试条件不同:当测试条件为假时,才进入循环体,直至测试条件为真时终止循环。
until 测试条件
do命令表
done
for语句

# !/bin/bash
# 一般格式
person=(1 2 3 4 5 6)
for i in ${person[*]};do echo $i;done
$ ex1
1
2
3
4
5
6
# !/bin/bash
# 格式一
person=(1 2 3 4 5 6)
for i in ${person[*]}
do echo $i
done

# !/bin/bash
# 格式二
for i in m*
do
cat $i | wc -l
done
$ ex1
5
# !/bin/bash
# 格式三
# 该方式获取的是位置参数的数据,也就是输入的数据
for i # 或者 for i in $*
do
echo "$i"
done

# !/bin/bash
for((i=1;i<=$1;i++))
dofor((j=1;j<=$i;j++))doecho -n "*" #-n取消输出换行done
echo " " #恢复换行
done
$ ex1 3
*
**
***
break和continue

#4.按反方向输出命令行中给出的参数
# !/bin/bash
count=$#
cmd=echo
while true
docmd="$cmd \$$count"((count=count-1))if [ $count -eq 0 ]then breakfi
done
eval $cmd
# eval 执行命令行
# $count=1 \$$count=my
$ ex1 my name is zxy
zxy is name my
exit

8.函数

SHELL脚本题目
#1.检测位置参数个数,若等于0,则列出当前目录;否则,对每个位置参数,显示其所包含的子目录。
#2.显示给定目录下指定文件的内容
#3.打印给定行数的“*”。第一行打印1个,第二行打印两个。(后者打印正三角,倒三角,左对齐,右对齐三角)
#4.按反方向输出命令行中给出的参数
#5.
第六章
gcc编译系统
文件名后缀
| 文件名后缀 | 文 件 类 型 | 文件名后缀 | 文 件 类 型 |
|---|---|---|---|
| .c | C源文件 | .s | 汇编程序文件 |
| .i | 预处理后的C源文件 | .o | 目标文件 |
| .ii | 预处理后的C++源文件 | .a | 静态链接库 |
| .h | 头文件 | .so | 动态链接库 |
| .C .cc .cp .cpp .c++ .cxx | C++源文件 | .out | 可执行程序文件 |
c语言编译过程
预处理阶段
预处理是常规编译之前预先进行的工作,故此得名。它读取C语言源文件,对其中以“#”开头的指令(伪指令)和特殊符号进行处理。主要包括文件包含、宏定义和条件编译指令。
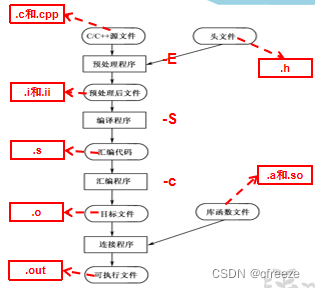
编译阶段
编译程序(Compiler)对预处理之后的输出文件进行词法分析和语法分析,试图找出所有不符合语法规则的部分
汇编过程
汇编过程是汇编程序(Assembler)把汇编语言代码翻译成目标机器代码的过程
连接阶段
连接程序(Linker)要解决外部符号访问地址问题。
连接模式分为静态连接和动态连接。
静态连接是将静态库在编译时把.a复制到可执行文件中,执行时已经是完整代码。
gcc命令行选择
在Linux系统中,C/C++程序编译命令是gcc,例如:
$ gcc f1.c f2.c (针对C语言源程序)
执行完成后,生成默认的可执行文件a.out。
1.预处理选项
C语言预处理程序通常称为cpp,它是宏处理程序,由C编译程序自动调用,在真正的编译过程之前对程序进行转换。
常用选项:
-o file
2.编译程序选项
gcc编译程序常用选项及其作用
| 选项 | 功能 |
|---|---|
| -c | 只生成目标文件,不进行连接。用于对源文件的分别编译 |
| -E | 只生成预处理文件,不进行编译 |
| **-S ** | 只进行编译,不做汇编,生成汇编代码文件格式,其名与源文件相同,但扩展名为.s |
| **-o file ** | 将输出放在文件file中。如果未使用该选项,则可执行文件放在a.out中 |
| -g | 指示编译程序在目标代码中加入供调试程序gdb使用的附加信息 |
| -v | 在标准出错输出上显示编译阶段所执行的命令,即编译驱动程序及预处理程序的版本号 |
3.连接程序选项
| 选项格式 | 功能 |
|---|---|
| -c -S -E | 如果使用其中任何一个选项,那么都不运行连接程序,而且目标文件名不应该用做参数 |
| -llibrary | 连接时搜索由library命名的库。连接程序按照在命令行上给定的顺序搜索和处理库及目标文件。实际的库名是liblibrary,但**按默认规则,开头的lib和后缀(.a或.so)可以被省略 ** |
| -static | 在支持动态连接的系统中,它强制使用静态链接库,而阻止连接动态库;而在其他系统中不起作用 |
| -Ldir | 把指定的目录dir加到连接程序搜索库文件的路径表中,即在搜索-l后面列举的库文件时,首先到dir下搜索,找不到再到标准位置下搜索 |
| -o file | 指定连接程序最后生成的可执行文件名称为file,不是默认的a.out |
动态静态链接库(重点)
Linux下库文件的命名有一个约定,所有的库名都以lib开头。形如:
libx.a 其中,x是指定的库名
以.a(归档,archive)结尾的库是静态库,以.so(共享目标,shared object)结尾的库是动态库
生成静态库的方法实际上可分为两步:
① 将各函数的源文件编译成目标文件
② 使用ar工具将目标文件收集起来,放到一个归档文件中
$gcc -c f1.c f2.c f3.c -0 game.o
$ar -rcs $HOME/Lib/libgame.a game.o
# 搜索静态库
$gcc f1.c f2.c f3.c -o mygame -static -L$HOME/Lib -lgame
# 动态链接库的生成gcc -c getdate.c -shared -o libgetdate.so
# 静态链接库的生成gcc -c getdate.c -o getdate.oar -rcs libgetdate.a getdate.o
# 链接库的使用动态:gcc main.c -L/root/ -lgetdate -o main.out静态:gcc main.c -static -L/root/ -lgetdate -o main.out
gdb程序调试程序(重点)
启动gdb和查看内部命令
程序中的错误可按性质分为三种:
(1)编译错误,即语法错误。
(2)运行错误。
(3)逻辑错误。
查找程序中的错误,诊断其准确位置,并予以改正,这就是程序调试,分为人工查错与机器调试。
当程序执行过程中忽然中止,屏幕上显示××××-core dumped消息,然后显示提示符,其中,××××表示出错原因
为了发挥gdb的全部功能,需要在编译源程序时使用==-g==选项 。如:
gcc -g prog.c -o prog # (针对C语言源程序prog.c)
gcc -g program.cpp -o program #(针对C++源程序program.cpp)
在编译失败的基础上,启动gdb调试的方法有以下几种:
(1) 直接使用shell命令gdb
$ gdb
(2) 以一个可执行程序作为gdb的参数 一旦启动gdb,就显示gdb提示符:(gdb)并等待用户输入相应的内部命令
$ gdb program
显示源程序和数据
显示和搜索源程序
1)显示源文件
利用list命令可以显示源文件中指定的函数或代码行
list list [file:] num
list start , end list [file:]function
2)模式搜索
forward-search regexp
search regexp
reverse-search regexp
查看运行时数据
(1)print命令 一般使用格式是 :print [/fmt] exp
当被调试的程序停止时,可以用print命令(简写为p)或同义命令inspect来查看当前程序中运行的数据,比如:print i*j **
(2)gdb所支持的运算符
① 用&运算符取出变量在内存中的地址**,如:print &i , print &array[i]
print &i
② { type }adrexp表示一个数据类型为type、存放地址为adrexp的数据。
{int}a
③ @ 是一个与数组有关的双目运算符,使用形式如:
print array@10 print array[3]@5
print array[3]@5
④ file :: var (或者 function :: var ) 表示文件file(或者函数function)中变量var的值
function::temp
(3)输出格式
在print /fmt exp命令中,“/”之后的fmt是表示输出格式的字母,它由表示格式的字母和表示数据长度的字母组成 。如:
表示格式 的字母:o x d u t f a i c s
表示长度的字母: b w h g
(4)whatis命令显示出变量的数据类型,如:whatis i
(5)x命令可以查看内存地址中数据的值 。其使用格式是:
x [/fmt] address
(6)display命令可以预先设置一些要显示的表达式。其一般格式是:
display [/fmt] exp
要取消对先前设置的某些表达式的自动显示功能,可以使用以下命令:
undisplay [disnum]
delete display [disnum]
改变和显示目录或路径
(1)directory命令一般格式是:directory [dir] 或dir [dir] ,设置源文件搜索路径
(2)cd命令使用格式为: cd dir
(3)path命令使用格式是: path dirs
(4)pwd命令
(5)show directories
(6)show paths
控制程序的执行



# 查看书本6.2.6应用示例!
# 1.-g选项编译但出错
gcc -g demo.c -o demo
./demo
# 2.初始化gdb
gdb demo
# 3.运行程序看报错
run
# 4.打印程序判断错误
list 11,22
# 5.设置断点
break 12
# 6.print地址或数值判断错误
程序维护工具make
make的工作机制
GNU的make的工作过程如下:
① 依次读入各makefile文件;
② 初始化文件中的变量;
③ 推导隐式规则,并分析所有规则;
④ 为所有的目标文件创建依赖关系链;
⑤ 根据依赖关系和时间数据,确定哪些目标文件要重新生成;
⑥ 执行相应的生成命令。