参考博客:https://blog.csdn.net/u012494876/article/details/80588823?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159144588119724846460968%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=159144588119724846460968&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_ctr_v2-20-80588823.ecpm_v1_rank_ctr_v2&utm_term=opencv%E5%9B%BE%E5%83%8F%E5%88%86%E8%A7%A3
针对红外和可见光图像进行细节信息提取。由于实际应用的需求,图像融合的源图像实际上可以有多种类型。不同种类的源图像具有自身比较独特的性质,因此,图像融合发生的场景将会对图像融合产生较大的影响。现在图像融合应用场景主流的有如下四类:
- Detailed information is extracted from infrared and visible images.Due to practical application requirements, the source images of image fusion can actually be of various types.Different types of source images have their own unique properties, so the scene of image fusion will have a great impact on image fusion.At present, there are four main types of image fusion application scenes:
可见光图像——红外图像融合
红外传感器通常对热效应造成的红外辐射比较敏感,在黑暗或者复杂背景中,能够较好探查发热物体,与此同此,其也经常忽视环境中不发热的背景信息。而可见光传感器能够有效感知环境信息的特性,正好与红外互补。
图像细节信息提取完成后可根据需求进行图像融合的操作。以下是我之前总结好的融合方法:
-
Visible image -- infrared image fusion
Infrared sensors are usually sensitive to infrared radiation caused by thermal effect. In dark or complex background, they can better detect hot objects. Meanwhile, they often ignore the background information of no heating in the environment.The visible light sensor can effectively perceive environmental information, which is just complementary with infrared.
After the image detail information is extracted, image fusion can be carried out according to the requirements.The following is the fusion method I summarized before:
像素级融合
像素级融合也称数据级融合,是三个层次中最基本的融合,指直接对传感器采集来得数据进行处理而获得融合图像的过程。
像素级融合中有空间域算法和变换域算法,
空间域算法中又有多种融合规则方法,如逻辑滤波法,灰度加权平均法,对比调制法等;
变换域中又有金字塔分解融合法,小波变换法。其中的小波变换是当前最重要,最常用的方法。
优点:
经过像素级图像融合以后得到的图像具有更多的细节信息,如边缘、纹理的提取,有利于图像的进一步分析、处理与理解,还能够把潜在的目标暴露出来,利于判断识别潜在的目标像素点的操作,这种方法还可以尽可能多的保存源图像中的信息,使得融合后的图片不论是内容还是细节都有所增加,这个优点是独一无二的,仅存在于像素级融合中。
缺点:
像素级图像融合的局限性也是不能忽视的,由于它是对像素点进行操作,所以计算机就要对大量的数据进行处理,处理时所消耗的时间会比较长,就不能够及时地将融合后图像显示出来,无法实现实时处理;另外在进行数据通信时,信息量较大,容易受到噪声的影响;还有如果没有将图片进行严格的配准就直接参加图像融合,会导致融合后的图像模糊,目标和细节不清楚、不精确。
-
Pixel-level fusion
-
Pixel-level fusion, also known as data-level fusion, is the most basic of the three levels. It refers to the process of directly processing the data collected by the sensor to obtain the fused image.
-
There are spatial domain algorithm and transform domain algorithm in pixel-level fusion.
-
In the spatial domain algorithm, there are a variety of fusion rule methods, such as logical filtering method, gray weighted average method, contrast modulation method, etc.
-
In the transform domain, there are also pyramid decomposition and fusion method, wavelet transform method.The wavelet transform is the most important and commonly used method.
-
Advantages:
-
After image fusion at pixel level image with more details information, such as edge, texture extraction, conducive to the further analysis of the image, processing and understanding, can also expose potential targets, good judgment, identify potential target pixel operation, this method also can be as much as possible to save the information in the source image, make the image after fusion both content and details are increased, the advantage is unique, only exist in pixel level fusion.
-
Disadvantages:
-
The limitations of pixel-level image fusion cannot be ignored. As it operates on pixel points, the computer has to process a large amount of data, which will take a long time. Therefore, the fused image cannot be displayed in time and real-time processing cannot be realized.In addition, in the process of data communication, the amount of information is large and is easily affected by noise.In addition, if the image is not registered strictly, it will directly participate in the image fusion, which will lead to the image blur after fusion, and the target and details are unclear and inaccurate.
特征级融合
特征级图像融合是从源图像中将特征信息提取出来,这些特征信息是观察者对源图像中目标或感兴趣的区域,如边缘、人物、建筑或车辆等信息,然后对这些特征信息进行分析、处理与整合从而得到融合后的图像特征。
在特征级融合中,保证不同图像包含信息的特征,如红外光对于对象热量的表征,可见光对于对象亮度的表征等等。
优点:
对融合后的特征进行目标识别的精确度明显高于原始图像的精确度。特征级融合对图像信息进行了压缩,再用计算机分析与处理,所消耗的内存与时间与像素级相比都会减少,所需图像的实时性就会有所提高。特征级图像融合对图像匹配的精确度的要求没有第一层那么高,计算速度也比第一层快。
缺点:
特征级融合通过提取图像特征作为融合信息,因此会丢掉很多的细节性特征。
-
Eigenlevel fusion
-
Feature-level image fusion is the extraction of feature information from the source image, which is the target or area of interest to the observer in the source image, such as edge, person, building or vehicle, etc., and then the analysis, processing and integration of these feature information to obtain the fused image features.
-
In feature-level fusion, different images are guaranteed to contain information features, such as infrared light's representation of heat of the object, visible light's representation of brightness of the object, and so on.
-
Advantages:
-
The accuracy of target recognition after fusion is obviously higher than that of original image.Feature-level fusion compresses the image information, and then analyzes and processes it by computer. The memory and time consumed will be reduced compared with the pixel level, and the real-time performance of the required image will be improved.Feature-level image fusion requires less accuracy of image matching than the first layer, and the calculation speed is also faster than the first layer.
-
Disadvantages:
-
Feature-level fusion extracts image features as fusion information, so many detailed features are lost.
决策级融合
决策级图像融合是以认知为基础的方法,它不仅是最高层次的图像融合方法,抽象等级也是最高的。决策级图像融合是有针对性的,根据所提问题的具体要求,将来自特征级图像所得到的特征信息加以利用,然后根据一定的准则以及每个决策的可信度(目标存在的概率)直接作出最优决策。
决策级融合主要在于主观的要求,同样也有一些规则,如贝叶斯法,D-S证据法和表决法等。
优点:
三个融合层级中,决策级图像融合的计算量是最小的,而且图像传输时噪声对它的影响最小。
缺点:
这种方法对前一个层级有很强的依赖性,得到的图像与前两种融合方法相比不是很清晰,将决策级图像融合实现起来比较困难。
- Decision level fusion
- Decision-level image fusion is a cognition-based method, which is not only the highest level of image fusion, but also the highest level of abstraction.Decision-level image fusion is targeted. According to the specific requirements of the question, the feature information obtained from the feature-level image is utilized, and then the optimal decision is directly made according to certain criteria and the credibility of each decision (the probability of the existence of the target).
- Decision-level integration mainly depends on subjective requirements, and there are also some rules, such as Bayesian method, D-S evidence method and voting method.
- Advantages:
- Among the three fusion levels, the calculation amount of the decision-level image fusion is the smallest, and the noise has the least influence on the image transmission.
- Disadvantages:
- This method has a strong dependence on the previous level, and the resulting image is not very clear compared with the previous two fusion methods, so it is difficult to realize the decision-level image fusion.
一幅图像可以分解为两层:底层(base layer)和细节层(detail layer)。底层包含图像的低频信息,反映了图像在大尺度上的强度变化;细节层包含图像的高频信息,反映了图像在小尺度上的细节。
1. 加性分解
要获取图像的底层,即图像的低频信息,使用低通滤波(如均值滤波(mean filter),高斯滤波(gaussian filter),导向滤波(guided filter))对图像进行滤波即可:B=f(I)
其中II表示要分解的图像,f(⋅)表示低通滤波操作,B为提取的底层。
提取底层后,使用源图像减去底层,即为细节层:D=I−B
其中D表示提取的细节层。
因为底层加上细节层即为源图像,所以我称此种分解方法为加性分解,对应于加性噪声。
2. 乘性分解
获取底层的方法与加性分解相同。然后使用源图像除以底层,即可得到细节层: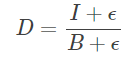
其中ϵ为一个很小的常数,以防止除零错误。
因为底层乘以细节层即为源图像,所以我称此种分解方法为乘性分解,对应于乘性噪声。在其他文章中,此处得到的细节层也称为商图像(quotient image)或比例图像(ratio image)。
测试代码:
#include "stdafx.h"
#include "opencv2/core/core.hpp"
#include "opencv2/imgcodecs/imgcodecs.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"int main()
{cv::Mat I = cv::imread("lwir1.png");if (I.empty()){return -1;}I.convertTo(I, CV_32FC3);cv::Mat B;cv::boxFilter(I, B, -1, cv::Size(31, 31));// 1. 加性分解cv::Mat D1 = I - B;// 2. 乘性分解const float epsilon = 1.0f;cv::Mat D2 = (I + epsilon) / (B + epsilon);// 显示图像I.convertTo(I, CV_8UC3);//cv::imshow("源图像", I);B.convertTo(B, CV_8UC3);//cv::imshow("Base layer", B);imwrite("B.jpg",B);D1 = cv::abs(D1); // 因为包含负数,所以取绝对值D1.convertTo(D1, CV_8UC3);//cv::imshow("Detail layer 1", D1);imwrite("D1.jpg", D1);cv::normalize(D2, D2, 0.0, 255.0, cv::NORM_MINMAX); // 归一化D2.convertTo(D2, CV_8UC3);//cv::imshow("Detail layer 2", D2);imwrite("D2.jpg", D2);//cv::waitKey();return 0;
}测试效果:
result:






I hope I can help you,If you have any questions, please comment on this blog or send me a private message. I will reply in my free time.


