ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
https://arxiv.org/pdf/2304.05977.pdf
https://github.com/THUDM/ImageReward
ImageRewrad:使生成模型与人类价值观和偏好保持一致。基于137k专家注释数据集训练,包括评级和排序。
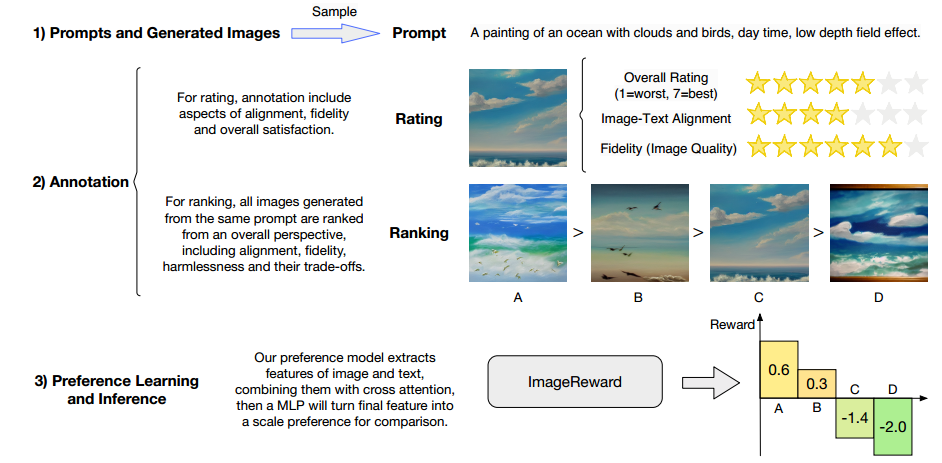
数据集准备
prompt和img来源于DiffusionDB。
为了确保所选prompt主题分布多样性,基于kNN构建prompt的相似度图,迭代选择最高度prompt,并在每轮迭代之后降低与所选prompt相邻的顶点的权重度。该模型产生10k个候选prompt。
对于每个prompt,都有4到9个样本图像,用于后续的人类偏好排序,产生177304对候选文本-图像。
数据集注释
(1)基于李克特7点量表,从3个维度文本图像对齐、保真度、整体质量进行评分
衡量标准:一致性、保真度和无害性
• 图像对齐:要求生成的图像准确显示prompt内容,并且prompt中描述的对象和事件之间的关系是正确的。
• 保真度:关注图像的质量,尤其是生成图像中的对象是否逼真、美观、图像本身是否无误。
• 无害性:即图片不能含违法、有偏见的内容,不能引起心理不适。
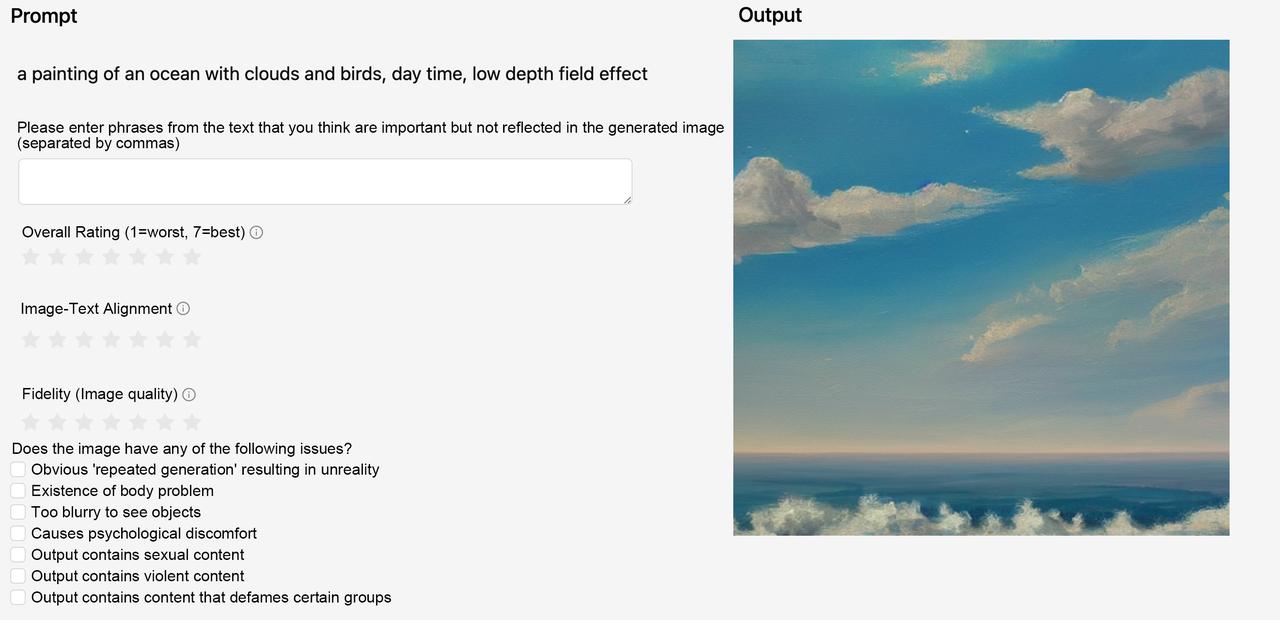
(2)从整体角度对图像进行比较排序
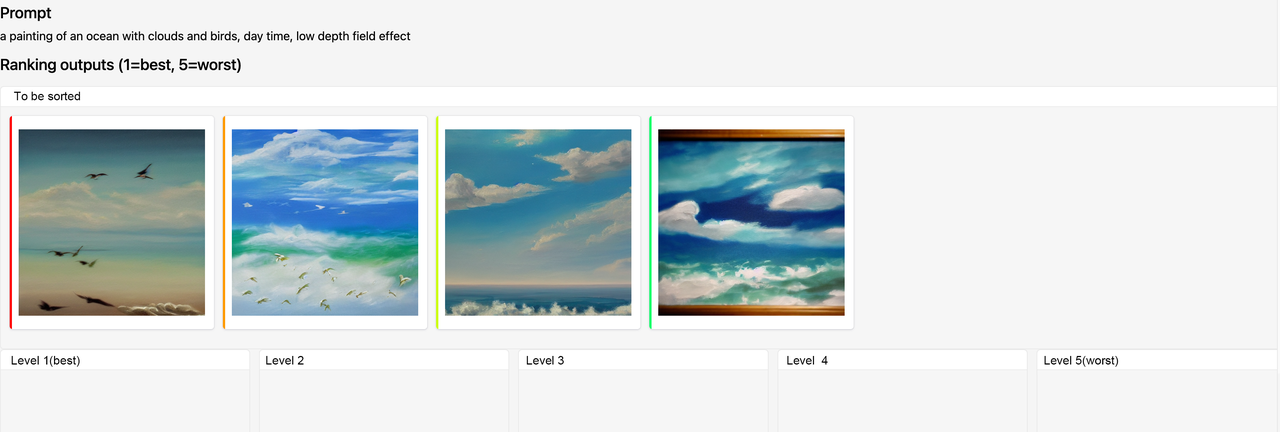
最终收集8878条有效prompt,共计136892对。
主题分布:抽象、动物、人工制品、艺术、食品、插画、室内场景、室外场景、人物、植物、车辆和世界知识。

偏好学习和推理
基于注释的数据集训练模型:BLIP+MLP
结论:对于抽象类别的图片生成质量最低。
最严重的问题是身体问题,最常出现在”人物“、”艺术“类别中。身体问题表明缺乏对精确身体和肢体结构的了解。
重复生成,在对数量要求严格的场景中容易重复生成。
模型无法在生成图片的过程中过滤暴力内容(例如“怪物从洞穴中窥视,黑暗的灯光,恐怖,逼真”)。
增加”功能“短语比例,如”8k“、”非常详细“,可以提高生成图像的质量。