前言
本文教程均来自b站【小白也能听懂的人工智能原理】,感兴趣的可自行到b站观看。
本文【原文】章节来自课程的对白,由于缺少图片可能无法理解,故放到了最后,建议直接看代码(代码放到了前面)。
代码实现
dataset.py内容如下
import numpy as npdef get_beans(counts):xs = np.random.rand(counts)xs = np.sort(xs)ys = [1.2*x+np.random.rand()/10 for x in xs]return xs,yscost_function.py内容如下
import dataset
import numpy as np
from matplotlib import pyplot as plt
n=100
xs,ys=dataset.get_beans(n) # 得到一系列豆豆大小xs 和 毒性ys
ws=np.arange(0,3,0.1) # 通过numpy得到 0到3,步长为0.1的array数组ws,如0,0.1,0.2 ... 0.29
es=[]
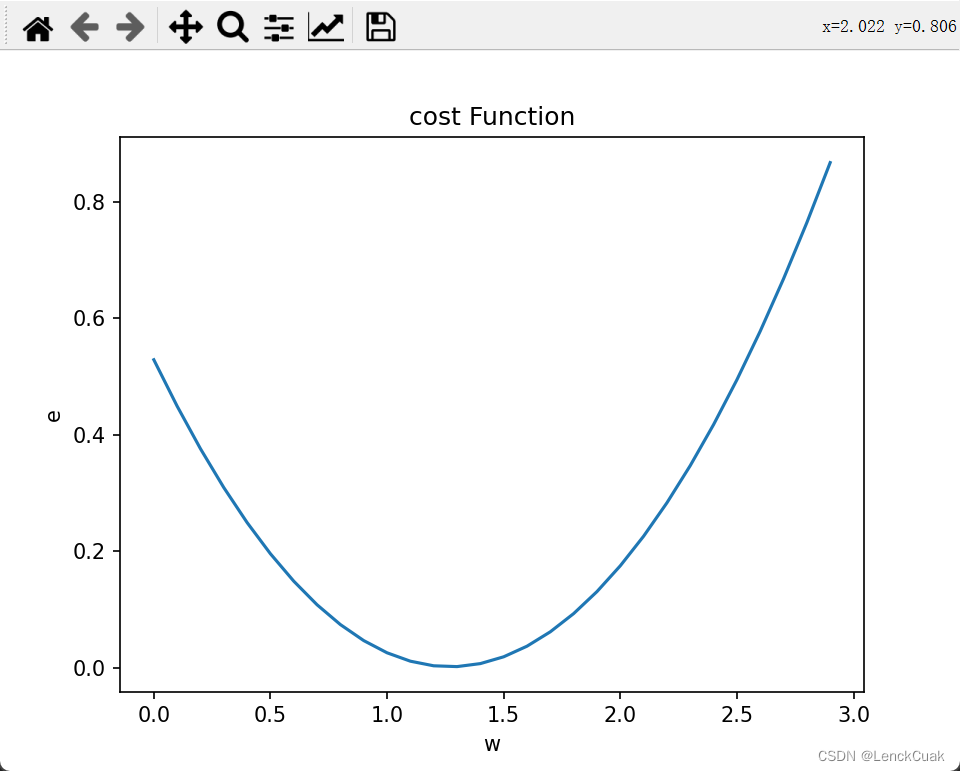
for w in ws:y_pre=xs*we=(1/n)*np.sum((y_pre-ys)**2) # 求出斜率取值为w时的平均平方误差,np.sum可以将所有的array数组对应值相加es.append(e)plt.xlabel('w')
plt.ylabel('e')
plt.title("cost Function",fontsize=12)
plt.plot(ws,es) # 绘制斜率与平方误差的关系
# plt.scatter(ws,es)
plt.show()plt.xlabel('Bean Size')
plt.ylabel('Toxicity')
plt.title("Size-Toxicity Function",fontsize=12)
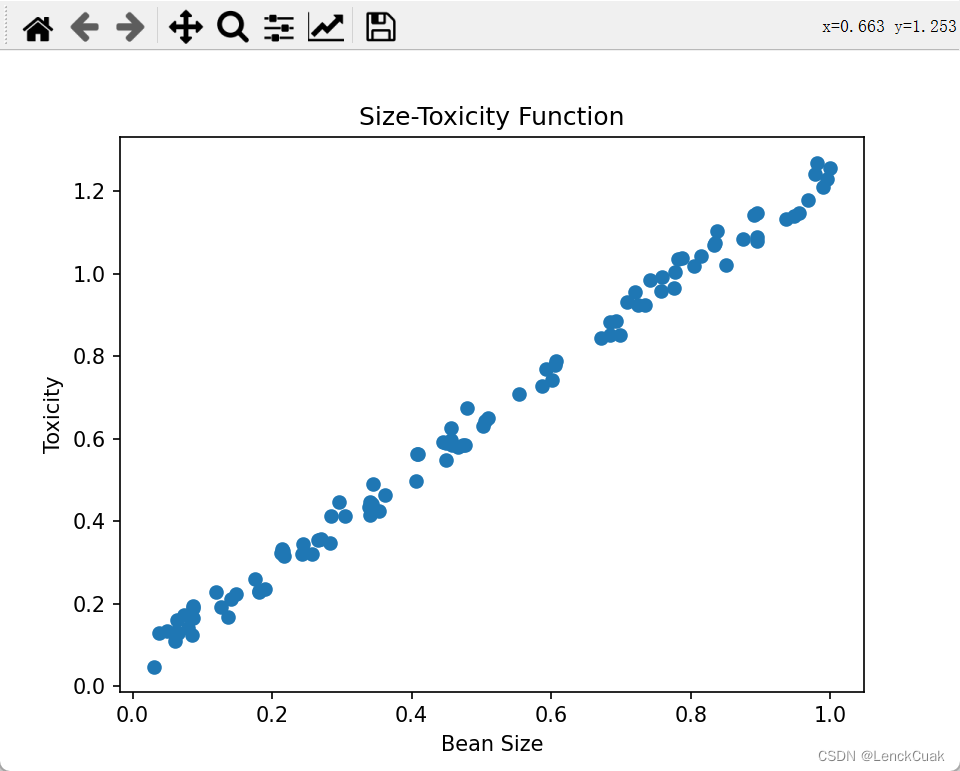
plt.scatter(xs,ys)
plt.show()w_min = np.sum(xs*ys)/np.sum(xs**2) # 这是通过一元二次方程求最值时的自变量取值公式得出的最佳斜率
print("The lowest cost gets when w=", w_min)
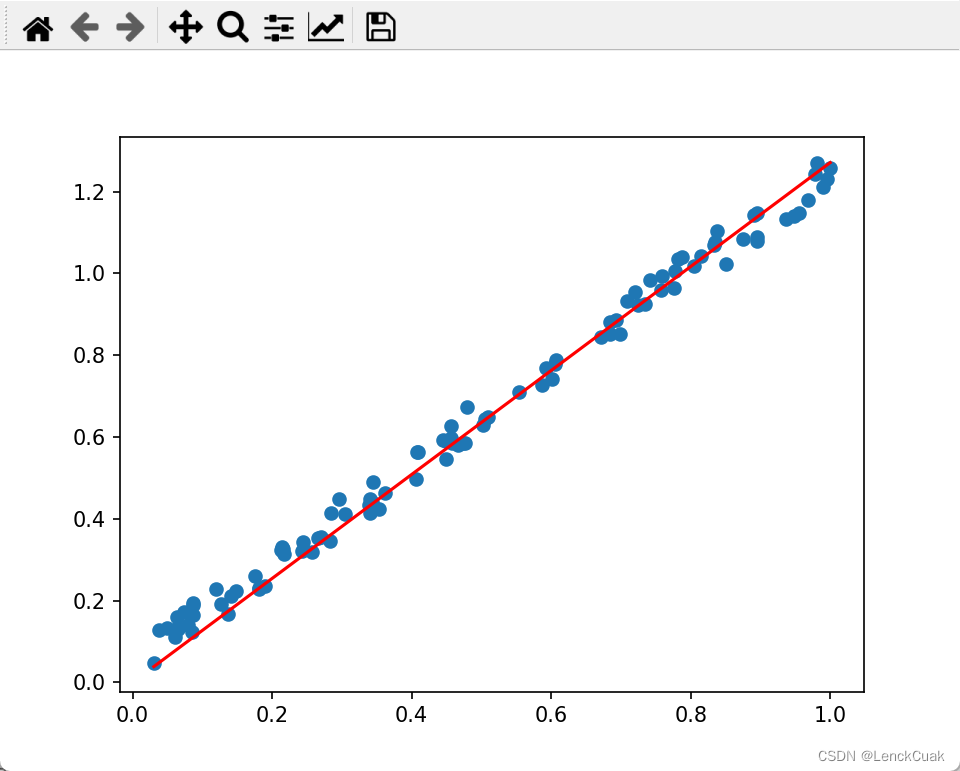
plt.clf()# 清空界面
plt.scatter(xs,ys)
plt.plot(xs,w_min*xs,'r')
plt.show()实验结果
原文
在上节课中我们聊到McCulloch-Pitts神经元模型和Rosenblatt感知器,最后我们说古老的Rosenblatt感知器启发了现代神经网络的研究,但是其本身已经并不常用了,那么就让我们来看看现代神经网络的实现方式。从Rosenblatt感知器身上可以看出来,参数的自适应调整乃是一个人工神经元的精髓,Rosenblatt感知器已经给出了调整的详细方法,怎么看似乎都没有问题,但是总感觉差点意思,为什么他就该是这个样子?正所谓横看成岭侧尘峰,远近高低各不同,让我们换个角度去看待这件事情,或许能更简单一点。
首先问大家一个问题,我们该如何去评估误差?你的第一反应可能是差值呗。这是标准答案,这是预测答案,两者一减就是误差,这样好吗?这样不好。我们举个极端且简明的例子,假设样本只有两个豆豆,那么这时候预测曲线在这两个豆豆上的误差是多少呢?第一个的误差是0.15,第二个呢是-0.15,所以预测曲线在两个豆豆上的总体误差是0,误差是0,所以现在是完美预测,很明显不是,这就是用差值评估预测误差的问题,差值有正负,所以相互之间会发生抵消作用。
机智如你,肯定会立马想到用差值的绝对值,因为面对误差比标准大0.15还是小0.15,其实和标准答案的差距都是0.15,我们并不关心正或者负。不错是一个方法,用绝对值处理的误差叫做绝对差。但是绝对值在数学处理和编码处理上都不是特别的方便。
于是人们提出了另外一种更好的误差评估方式,把差值取个平方,正负号也就消失了,这种误差也就是所谓的平方误差。很明显,我们对一批豆豆预测的结果和标准答案之间的平方误差越小,说明偏离事实越小,小蓝的思考也就越接近真相。
我们可以打开第二节课的可视化工具,随意的调整w的值,观察平(均)方误差的变化,而我们知道实际上是参数w决定了预测函数的样子,换句话说,每次w取不同的值产生的误差也会不同,如果我们把误差和w之间的关系画出来,它是这样的一个曲线,好像一个开口向上的一元二次函数,没错,正是一个开口向上的一元二次函数。
且慢,怎么证明它是一个开口向上的一元二次函数呢?其实很简单,研究一组豆豆太麻烦了,不如我们先看一个豆豆,大小是0.4,毒性是0.68,那么小蓝的预测就是w乘以0.4,误差是这个样子。你看这不就是一个标准的一元二次函数吗?W是自变量,e是因变量,a等于0.16,b=-0.544,c=0.4624,非常标准的一个开口向上的一元二次函数。
有的同学或许会问了,这只是一个豆豆,那么对于一组豆豆的误差呢其实结果也是一样的,我们再来算一遍。这一次我们用x0,y0分别代表豆豆,那如果是一个大小为x1,毒性为y1的豆豆预测值,y等于w乘以x1,误差是这个样子。也就是说对于任意一个大小和毒性的豆豆,它的预测误差和参数w的关系都是一个开口向上的抛物线,所以在一组豆豆上计算出来的整体误差还是不是一个开口向上的抛物线,那是必须的,他们的整体误差就是把单个豆豆的预测误差加起来再求平均,我们从第0个豆豆一直加到最后第m个,把含有二次项一次项和零次项的稍微整理一下放在一起,它是这个样子。
x0到xm和y0到ym既然都是一致的值,那么我们会发现面对一组m的豆豆,误差e和w的关系仍然是一个标准的一元二次函数,它描述了当W取不同值的时候,小蓝中队一组豆豆的预测的整体误差。
这个公式看起来又臭又长,数学呢讲究个简洁优美,而每个豆豆的误差的形式又是一样的,所以我们一般用一个求和符号来表示整体的误差,当然这时候因为取的是平方误差的平均值,所以我们也称亦为均方误差,同样一件事情引入一个符号就变得更加简洁了。
大家不必害怕这个求和符号,他只是在说一件事情,面对多个数据,我们只需要把单个的误差求出来,再全部加在一起平均一下,这就是预测函数在整体样本上的误差。而我们之前说到的单个豆豆其实只是它的一个特例,样本只有一个,也就是求和中的m等于1,实际上样本的数量m不论等于几。这个均方误差,e和w的关系都都会形成一个开口向上的抛物线,当我们知道不同的w取值对误差的影响之后,接下来的事情就很简单了,我们让机器自己去寻找这个开口向上的抛物线的最低点,此处恰是误差的最小点。
但是对于没有接触过或者已经忘却概率和统计相关知识的同学们,在这里有必要和大家说明一点点数学上的事情,防止你的思维乱掉。
我们说函数是我们对事物认知的数学描述,一般情况下函数的形成过程都是由某个问题的专家通过多年的经验总结出来的,比如牛顿爵士研究物体受力多年总结出加速度和受力的函数关系,但是世界是复杂的,很多非理想环境下,我们一点点的研究和总结是不现实的。比如正常来说一枚质地均匀的硬币抛掷出去,正反两面朝上的概率都应该是1/2,但是如果无聊的庄稼在这个硬币上做了手脚,比如在一侧灌入了一些东西,倒导致一侧更重了,那么现在两面朝上的概率各自是多少?当然我们可以采用高精尖的技术去研究这个硬币的材料构成受力模型,然后得到一个极其复杂的概率函数。但是这样不好更简单的方法是统计,也就是说我们不断的去抛掷这枚硬币并进入朝向。
当抛掷的次数足够大的时候,我们看一下统计的数据,比如1万次中出现了6567次,正面朝上3433次反面朝上,那么概率自然开始浮出水面。这就是我们常说的事物出现的频率收敛于它的概率。同样的道理,我们在设计小蓝大脑的时候,其实也是在干抛掷一枚不确定硬币这件事情。一开始我们猜想一个w然后统计出大量的数据去评估我们的w到底合不合适,这实际上就是数理统计学里重要的一个分支回归分析,而我们评估的标准是均方误差,并试图让它最小,也就是回归分析中的最小二乘法。
此时此刻如果我们把函数看作处理问题的机器,那么事情从原先的向机器输入数据得到结果,变成用很多观察到的数据去评估这个函数机器到底是合适。原先的自变量x和因变量y变成了从环境中观测到了大量的已知数,而我们把w作为自变量误差,e作为因变量,也就形成了一个新的函数——代价函数(cost function),这个所谓的代价函数展现出当参数w取不同值的时候,对环境中问题数据预测时产生的不同误差e而利用代价函数的最低点的w值把它放回到预测函数中,这时候预测函数也就很好的完成了对数据的拟合。
所以大家要千万时刻牢记,在预测函数中w作为参数,x是自变量输入,y是因变量输出,这是我们最终要得到的预测问题的函数。而在研究代价函数的时候,x和y都是通过观测统计而来的已知数成为了代价函数的已知参数部分,而w成为的自变量误差代价亦是因变量,这是我们用来分析并改进预测函数的辅助函数。
就此打住,让我们回来,如果一开始w是0.1,距离合适的最低点还有一段距离,那么究竟如何让机器自己去把w向最低点挪动,这个问题并不难用,初中数学足以。最低点很明显是这个抛物线的顶点,我们自然可以用抛物线的顶点坐标公式来求。
先看样本,只有一个豆豆的简单情况,代入计算得到最低点的w值是y0÷x0。再来看样本有多个豆豆的一般情况,我们先利用求和符号的性质整理一下,把求和符号分别作用到二次项,一次项和0次项上代入计算,把把分子分母能约分的都约掉得到,最低点的w值是这个样子。
这种求解参数的方式,如果你之前接触过机器学习,可能会听过一个叫做正规方程的东西,这种一次性求解出让误差最小的w取值的方法也,就是所谓的正规方程了.
只不过我们这里还没有说到矩阵和向量,而是采用单个的数值,当我们把正规方程中的矩阵和向量都退化成单个数值,你看结果是一样的。
这种方法它合适吗?
当样本数量比较少的时候,其实这很合适,但是众所周知机器学习往往需要处理海量的数据,这种一步到位的方式就意味着巨大的计算量和存储量,这时候事情就开始起了变化。我们来算一笔账,比如我们有100万条样本数据,每个数据用一个单精度的浮点型数表示,那么在正规方程中,比如分母部分就要运行100万次乘法和加法的浮点预算,而在后面的课程中我们会说到,实际上输入x在实际应用中往往不会只有一个特征数值,更一般的情况是一个多维的向量,比如1000个维度,那那么这个运算的次数就是10亿次,而在现在神经网络中为了加快运算的速度,一般都会采用并行计算的方式,也就是说一次性把它们都计算出来,这更够劲呀。
那么接下来我们来看一种更加常用的方法梯度下降。