深度学习(26)——YOLO-v7(5)
文章目录
- 深度学习(26)——YOLO-v7(5)
- 絮絮叨叨
- 1. conv和BN的融合
- 2. 3*3卷积的替换
- (1)1*1卷积有什么作用?
- (2)怎么将1 * 1卷积核转化为3 * 3卷积核
- 3. 正样本分配策略
- (1)什么是正样本匹配??
- (2)为什么要用正样本匹配?
- (3)lead的三个点
- (4)aux的五个点
- (5)最后的loss和哪些正样本有关?
- 4. AUX辅助头
- 5. 网络结构
不知不觉YOLO系列已经出了四篇了,原本想着两三篇就差不多了,但是奈何YOLO是个大家,学都学不完,今天是YOLOv7理论,所以熟悉的可以预测到下一个就是v7代码了。
絮絮叨叨
在我们的认知中训练和推理(预测)的网络一定要是一样的,但是YOLO-v7即将颠覆我们的认知,训练和推理的网络可以不同。为了提高推理的效率,YOLO-v7在推理过程中做了两个改进
- 一般情况一个convolution层(conv层)后加一个batchnormalization(BN层),将两者融合为一个conv层计算
- VGG在2014年提出一个观点因为英伟达底层的原理,3 * 3的卷积效果和计算速率是所有卷积中效果最好的,所有YOLO-v7在推理过程中将所有卷积都替换为3 * 3卷积
1. conv和BN的融合
-
batchnormalization是将一个channel的数值标准化,使其尽量集中在一个片区
【BN的计算公式↓】 其中γ和β是两个可学习的变量,γ控制缩放,β控制偏移,尽可能让一个channel都集中在(0,0)

-
怎么融合呢??
- 卷积的格式无非是y=wx+b,将上式拆开↓,可以发现和卷积有相同的格式:
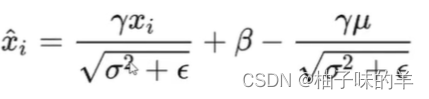
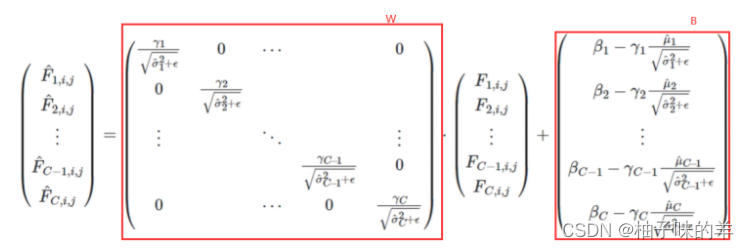
- 卷积以后BN
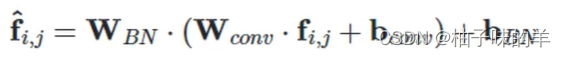
- 整合以后可以得出整合后的w和b是下面这样,就可用这样的卷积实现了
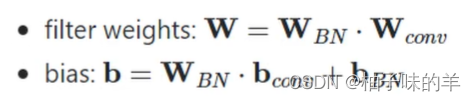
- 卷积的格式无非是y=wx+b,将上式拆开↓,可以发现和卷积有相同的格式:
2. 3*3卷积的替换
YOLO-v7中除了3 * 3就是1 * 1 的卷积了,所以这里其实就是怎么将1 * 1的卷积转化成3 * 3卷积:
(1)1*1卷积有什么作用?
这个问题是前段时间ly留给我的问题,当时只想到了升维降维和特征提取,今天查了一下详细记录:具体大家可以参考这篇:blog
- 降维和升维
- 跨通道的特征整合
- 增加非线性特性,在保持特征尺度不变的情况下,将网络做的更deep
- 减少计算量
(2)怎么将1 * 1卷积核转化为3 * 3卷积核
将11卷积周围加padding就可,需要注意的是原图也要在周围增加padding。计算方式是一样的。
残差连接的方式使用的卷积也不是直接拿来,乘以一个对角元素都为1的33卷积即可
3. 正样本分配策略
(1)什么是正样本匹配??
特征图中每个点都会有预测结果,为了提高效率,只有正样本参与loss的计算,那哪些是正样本呢?
距离groundtruth中心点附近的点才是正样本
(2)为什么要用正样本匹配?
甲方可能希望你无论检测的效果如何,都希望你能检测出来,就是希望recall值提高,所以在前期不想YOLOv5等前期版本只有一个正样本,这里给正样本更多选择(lead有三个点,aux有五个点)。
(3)lead的三个点
假设蓝色的点是距离groundtruth最近的点,那么对他进行0.5的偏移就到了他的右侧和下册,所以就又多了两个点,一共三个点。

(4)aux的五个点
和上面类似,为什么是五个点呢,aux采用的偏移量是1,所以上下左右都是正样本,一共五个
(5)最后的loss和哪些正样本有关?
以lead为例,根据上述得到的三个点对对候选框做选择,怎么选呢?
- 初筛:0.25<groundtruth与anchor长宽比例<4
- 计算IOU
- 计算类别预测损失
根据上述损失排名后选择topk,但是有时会出现断崖式下降的,所以将topk进行累加后重新定义k(如:如果之前的k为10 ,累加后和为7的k变为7,累加和为5将k更新为5)
4. AUX辅助头
- YOLO-v5的输入size是640,YOLO-v7中可以取1280,间隔取值,将12801280的特征间隔1转化为4个640640的特征图,在channel维度增加了,进网络的时候还是640,隐性的增大了图片尺寸
- 原本有四个输出层,现在每个输出层都有一个辅助输出头,相当于增加了一个输出,一共有8个输出层
5. 网络结构
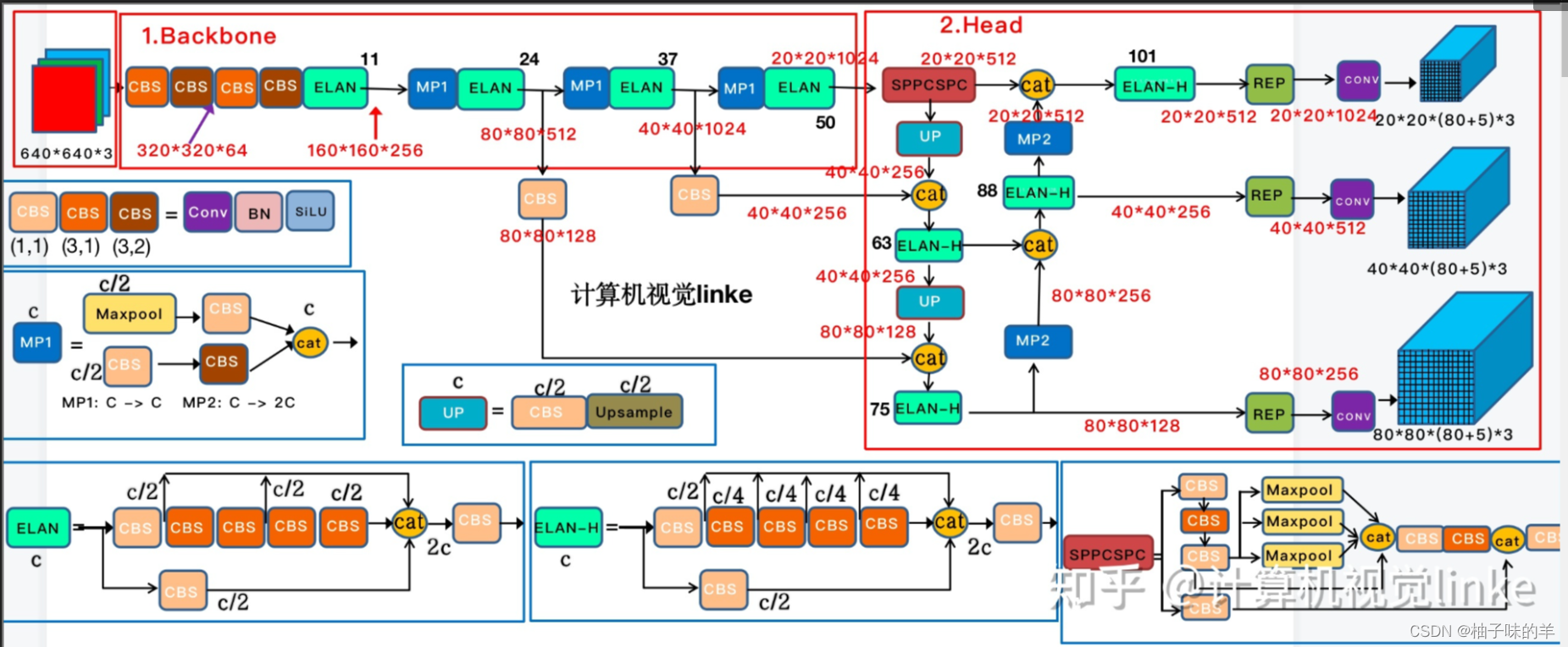
里面没有很亮眼的地方,就是特征的拼接,和YOLO-v5有很多地方都是异曲同工,SPP思想和PAN思想,可以看上篇。
今天又是充实的一天,先这样,886!