在一个学期对于《CSAPP》这本书的学习过程中,我了解到许多关于计算机软硬件交界面的知识,也了解到如何更好地编写一个更好、更安全、更少bug的程序。我希望能在下面的篇幅中,为与我一样的初学者介绍、总结我的学习感想与学习笔记。也许涵盖范围会比较广,例如会从我对《CSAPP》这本书的学习感触写到Linux系统使用过程中自己总结出来的小技巧。
第一次发帖的确会经验不足,但是总结出来的点都是对我自己十分受用的,希望与诸君共适。
下面是我主体内容的目录:
- 1:U2 信息的表示和处理
- 1.1:大/小端存储
- 1.2:整型数据类型
- 1.3:浮点数
- 1.4:相关实验
- 1.5:U2总结
- 2:U3 程序的机器级表示
- 2.1:高级语言—>机器代码
- 2.2:x86-64汇编指令系统
- 2.3:C语言的机器级表示
- 2.4:复杂数据类型的机器表示
- 2.5:相关Linux命令集
- 2.6:相关实验
- 2.7:U3总结
1:U2 信息的表示与处理
这一个单元于我看来,主要谈到了各种数据类型在机器中的表示方法,从最基础的各类进制的转换,谈到了数据在机器中的大/小端存储方式,最后谈到了各类数值的编码方式、何时会溢出。下面展开我对第二章知识点的总结。
1.1:大/小端存储
用我自己的话来说,小端方式便是一种“合理的”存储方式(因其在日常生活中应用较广,如Intel、Android、Apple等,故称“合理”),即“最高有效字节在最高地址,最低有效字节在最低地址,依次排列”。大端方式则相应地,相反。
那么如何检测所用机器是以哪种方式存储呢?有两种方法:
一种是利用show_bytes实现检测:
int val = 0x87654321;
byte_pointer valp = (byte_pointer) &val;
show_bytes(valp,1) ;
可知大/小端法存储的机器运行时输出的结果不会一样,如果输出结果是21,那么就是小端机器;如果87,那么就是大端机器;
第二种方法则是利用结构体顺序存储方式的特点来进行检测,到了第三章结构体存储部分我再详细介绍。
1.2:整型数据类型
讲述整型数据类型的几个小节内,我认为最重要的知识点便是:溢出情况的讨论、真值与补码之间的转换。
1.2.1溢出情况:
每一种整型数据类型的溢出情况是由自己的位数决定的,如x86-64系统中,int型占4个字节,long型占8个字节,它们的溢出上下界也相应地由位数决定。如下表:
| 类型 | 范围 |
|---|---|
| char | -128–127 |
| unsigned char | 0–255 |
| short | -2^15 – 2^15-1 |
| unsigned short | 0 – 2^16-1 |
| int | -2^31 – 2^31-1 |
| unsigned int | 0 – 2^32-1 |
| 以此类推 |
如果所要表示的数的真值大/小于所用数据类型的上/下界,那么便会发生正/负溢出。那么如何判断是否发生了溢出呢?一种方法是,利用四种标志:溢出标志O,进(借)位标志 C,零标志Z,符号标志S。计算过程中,如果(最高位进位标志Cn)^(次高位进位标志Cn-1)= 1,则发生了溢出。
1.2.2:真值补码之间的转换
真值与补码之间的转换之间有着转换公式,我就将它们直接列出来。


1.3:浮点数
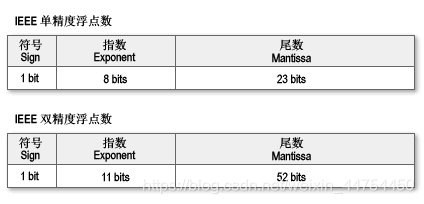
编码方式上,浮点数较整型数据类型是非常不同的,浮点数的编码方式为:符号位+阶码+尾数。下面我从其编码时各个部分,非规格化数的表示,舍入,浮点数运算四个部分展开我对浮点数的学习笔记:
1.3.1:符号位+阶码+尾数
符号位同任何二进制数一样,0表正,1表负;阶码的实际值为:阶码上表示的数e - bias(偏置量);而偏置量bias等于2(k-1)-1(k对单精度为8,对双精度是11);尾数的值为将真值化为1.xxxxxx*2E后,小数点后面的数,且在尾数部分中用原码表示。且,浮点数在机器中的存储结构如下图所示:
1.3.2:非规格化数的表示
非规格化数主要有两个用途:表示0与表示无穷。1.当符号位、阶码、尾数为全0时,则表示该数为0;2.当阶码为全1时,当尾数为全0时,符号位为0或1决定了该数为正无穷还是负无穷;若此时尾数不为0,则称该数为NaN(not a number)。
1.3.3:舍入
首先,舍入只针对二进制小数而言;其功能在于,将高位小数化为低位小数(为了符合对应数据类型的位数)时,更加精确,更加接近原值。
舍入共有四种方式,如图所示:

下面主要讨论就近舍入(round to even)的方式:
- 如果待舍入位小于保留位最低位的一半,则直接将待舍入位直接舍入;
- 如果待舍入位大于保留位最低位的一半,则保留位最低位+1;
- 如果待舍入位等于保留位最低位的一半,则看保留位最低位的后一位:1.若低位为0,则直接将待舍入位直接舍去;2.若低位不为0,则保留位最低位+1;
之所以详细讲round-to-even这种舍入方式是因为这种方式在大多数现实情况中避免了一些统计偏差。
1.3.4:浮点数运算
浮点数运算步骤与其存储结构相对应,三个部分:符号+阶码+尾数各自分别运算。此时为了计算的方便,我们运算时需要进行对阶操作,即将指数部分化为同一个数,尾数做出相应变化。
但,当两个数指数部分差值达到25时,则对阶时会将指数更小的那个数直接舍去。例如:1e20-(1e20+3.14) = 0,但是(1e20-1e20)-3.14 = -3.14;这就是因为前一个等式中进行(1e20+3.14)时,两个数之间的阶码差值>25,则括号内运算结果为1e20。
从而我们可以总结一些数据类型转换之间、关于转换前后数值是否准确的规律:
- int ->float时,数值不会溢出,但可能发生舍入;
- int/float -> double时,能够保留精准的数值;
- double -> float时,因为表示范围不一样,因此可能发生溢出,也可能舍入;
- float/double -> int时,会向0舍入。
1.4:相关实验
1.4.1:实验代码及分析
《CSAPP》U2的课后习题中有一个好实验,其以show_bytes代码作为主体,来展示同一个数作为不同数据类型时在机器中的存储结构和地址,并且能够检验机器的存储方式(大端or小端)。代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>typedef unsigned char *byte_pointer;
//typedef char *byte_pointer;
//typedef int *byte_pointer;void show_bytes(byte_pointer start, size_t len) {size_t i;for (i = 0; i < len; i++)printf("%p\t0x%.2x\n", &start[i], start[i]); printf("\n");
}void show_int(int x) {show_bytes((byte_pointer) &x, sizeof(int));
}void show_float(float x) {show_bytes((byte_pointer) &x, sizeof(float));
}void show_pointer(void *x) {show_bytes((byte_pointer) &x, sizeof(void *));
}void test_show_bytes(int val) {int ival = val;//float fval = (float) ival;double fval = (double) ival;int *pval = &ival;printf("Stack variable ival = %d\n", ival);printf("(int)ival:\n");show_int(ival);printf("(float)ival:\n");show_float(fval);printf("&ival:\n");show_pointer(pval);
}int main(int argc, char *argv[])
{int val = 12345;if (argc > 1) {val = strtol(argv[1], NULL, 0);printf("calling test_show_bytes\n");test_show_bytes(val);} else {printf("No argument!\n");}return 0;
}
当输入参数ival为1073741824(2的30次方)时,结果如下:
calling test_show_bytes
Stack variable ival = 1073741824
(int)ival:
0xbfd40020 0x00
0xbfd40021 0x00
0xbfd40022 0x00
0xbfd40023 0x40
(float)ival:
0xbfd40020 0x00
0xbfd40021 0x00
0xbfd40022 0x80
0xbfd40023 0x4e
&ival:
0xbfd40020 0x34
0xbfd40021 0x00
0xbfd40022 0xd4
0xbfd40023 0xbf
但此时将byte_pointer类型改为int *型时,输出结果改变了:
calling test_show_bytes
Stack variable ival = 1073741824
(int)ival:
0xbfae9b90 0x40000000
0xbfae9b94 0x40000000
0xbfae9b98 0x40000000
0xbfae9b9c 0xb7521940
(float)ival:
0xbfae9b90 0x4e800000
0xbfae9b94 0x40000000
0xbfae9b98 0x40000000
0xbfae9b9c 0x4e800000
&ival:
0xbfae9b90 0xbfae9ba0
0xbfae9b94 0x40000000
0xbfae9b98 0x40000000
0xbfae9b9c 0x4e800000
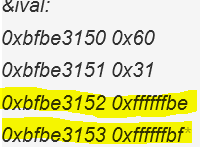
将byte_pointer类型改为char *型时,结果也有改变:
calling test_show_bytes
Stack variable ival = 1073741824
(int)ival:
0xbfbe3150 0x00
0xbfbe3151 0x00
0xbfbe3152 0x00
0xbfbe3153 0x40
(float)ival:
0xbfbe3150 0x00
0xbfbe3151 0x00
0xbfbe3152 0xffffff80
0xbfbe3153 0x4e
&ival:
0xbfbe3150 0x60
0xbfbe3151 0x31
0xbfbe3152 0xffffffbe
0xbfbe3153 0xffffffbf
Q:为什么byte_pointer类型发生改变时会出现这样的变化?
A:
- 当byte_pointer从unsigned char*型改为int *型时,指针指向的存储空间从以前的1 byte(unsigned char)变成了4 bytes(int),因此此时地址每一次变化是+4,而非以前的+1;
- 当byte_pointer从unsigned char*型改为char *型时,指针指向的存储空间内容变化在于多出了符号位,因此每个byte如果以前最高位为1,则改变之后需要进行补符号位的操作,即高位变为全1,16进制中表现为多个f,如下图:
1.4.2:实验过程中我掌握的技巧
因为课程要求,我的实验都是在Linux系统上实现。完全习惯了Windows操作系统的我,上手Linux颇有难度,又由于我的机器的问题,电脑上不能安装Vmtools,因此Windows里面的文件传送到虚拟机上有困难。一开始我搜网上的教程,发现需要建立共享文件夹,我建立之后发现因为电脑原因还是不能够共享文件;因此我尝试了从手机上传文件到电脑的方法:在任意浏览器中登陆网页版微信(非广告),从手机上将目标文件发到网页上,再保存即可。目前我只试过文本文件,其他文件格式可能不尽相同。不过还是希望这种小伎俩能对同等level的初学者有所帮助。
1.5:总结
以上便是我对《CSAPP》U2的学习理解,第二单元涵盖了从各种进制之间的转换、到各类数据类型的详细介绍、再到对程序中的应用,可谓十分重要,是该本书学习的基础。我的笔记只是一家之言,但也希望对读者有所帮助,也希望发现了问题的读者能够不吝赐教。
2:U3 程序的机器级表示
这一个单元从标题上就可知主要内容为高级语言(此处以C语言为例)编写的程序在机器中如何表示。然而从高级语言的繁琐(例如条件语句、循环、递归等各种语法)化简到机器代码(由0、1构成)中间的过程也非常复杂。
因此我接下来的笔记将从总体的高级语言到机器代码的转换过程、x86-64汇编指令系统、C语言的机器表示、复杂数据类型的机器表示、相关Linux命令、相关实验这六个方面展开我对U3的学习笔记。
2.1:高级语言源程序——>机器代码

下面解释一下每一个紫色框内的具体操作:
- 预处理:将C程序中的头文件全部找齐,为之后操作做准备;
- 编译:将C程序转化为汇编语言程序(重点);
- 汇编与链接:将汇编语言程序转化为机器代码程序,由二进制表示;
2.2:x86-64汇编指令系统
x86-64系统中指令基本上分为有效地址加载指令、数据传送指令、跳转指令、栈相关指令、算术操作指令,而每个指令都与寄存器与内存相关。指令是什么与为什么是这样的定义这样的问题我就不再多言,此处不是难点,用记忆解决即可;我主要谈一谈在使用这些指令时需要注意的地方:
2.2.1:汇编代码后缀
x86-64指令集系统中,根据每一种简单数据类型的字长,在使用时规定了不同的后缀,如char型占一个byte,因此其后缀为b;我也不做过多解释,记忆即可;
2.2.2: 各类寄存器
x86-64指令集系统中共有16个通用寄存器,其中每一个寄存器在使用时都要根据其字长来使用,如rax寄存器,对long型或指针型数据则要用rax,对int型数据则要用eax,以此类推;有疑惑、想要了解更多的读者可以移步:x86-64寄存器及栈帧描述
2.2.3:数据传送指令
作为使用频率最高的指令,mov指令无疑是最为重要的,以下是几个我自己认为的重点:
- mov指令之后必须接有两个操作数,操作数可以是立即数、寄存器内容、内存中的内容,三者可以有下图中几种搭配(以movq指令为例):

由图可见,使用过程中我们不能够进行内存直接到内存之间的操作,例如:movq (%rax),(%rdi)是不允许的。想要实现这样的操作必须通过两条指令实现。 - mov指令也可以用来实现扩展、截断操作。进行截断则直接将操作数定为截断后长度的寄存器;进行扩展则需在mov指令后加上两个类型后缀,例如:将一个al寄存器中的char型数据扩展到edi寄存器中的int型,汇编指令为:movsbl al,edi ;但也存在特例,movzlq指令是不存在的,在汇编中它被直接简化为movl指令,执行过程中会直接把被操作数的高32位置0;
2.2.4:栈相关操作
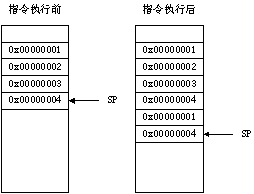
有关栈的操作就是压入/弹出栈的操作,其作用主要是保护现场,保证当前语句段执行完后能够找到回去的路,比如函数调用则是一个典型的需要将返回地址进行入栈操作的例子。下面是一些使用栈相关指令时需要注意的点:
- x86-64系统中的栈是满+递减向下生长的模式的。“满”意思是栈顶指针永远指向栈中实际存在的栈顶元素;“递减”在于此类ISA的栈入栈时栈顶指针会向低地址递减生长,如图:
- pop指令与push指令必定同时出现,并且,push指令也可以等价于(以四字长度为例):
subq $8,%rsp movq %rbp,(%rsp)
pop指令也同理;
2.2.5:加载有效地址
lea(load effective address)指令有两种用法,
- 实现加/乘法(例如:
leaq (%rax, %rax,3),%rdi实现了将rax中内容*5后放到rdi中去); - 真正的加载有效地址;
2.2.6:比较指令(cmp)/测试指令(test)与跳转指令(j)
之所以将比较指令/测试指令与跳转指令放在一起是因为,这几条指令一般是连用在一起,构成条件语句/循环语句/goto语句。
比较指令实际上是做减法,测试指令则是测试该内容是否为0;
而跳转指令则较为复杂,在于其后缀的多样,需要记忆,觉得有必要详细理解或是有疑惑的读者可以移步:跳转指令汇总
而且,跳转指令有特殊的编码方式,即:PC相对的(PC relatively);即将目标指令的地址与紧跟在跳转指令后面那条指令的地址之间的差作为编码,公式化后便是:编码=目标地址-跳转指令后一条指令的地址。《CSAPP》课后习题中有:
下面je指令的目标是什么? 4003fa: 74 02 4003fc: ff d0
由上述公式可知,je指令指向的地址就是(4003fc+02 == 4003fe)。
2.2.7:算术操作指令
多个算术操作指令中,我选取移位(s:shift)指令与乘法(imul:multiple)指令来讲:
- 移位指令从移位标准上分两种,算术移(sa)与逻辑移(sh),后面接一个操作数(一般是寄存器内容)时,意为该内容算术/逻辑移动(向左/右)1位;后面接两个操作数(立即数k+其他)则是该内容算术/逻辑移动(向左/右)k位。
- 乘法指令则一般接两个操作数(多种搭配);
- 移位指令与乘法指令都可以实现乘法操作,但是不同在于执行时间长短。移位指令执行时间<<乘法指令执行时间。虽然单个移位指令只能用于进行(×2的n次方)操作,但是辅以加法指令,基本上乘任何一个立即数都能够实现。但是,仍有一种情况需要用到乘法指令,那就是参数×参数的情况,此时两个操作数都不是确值,因此不得不需要用到乘法指令。例如:
int Imul(int x,int y){
return x*y;}
若将该函数汇编后得到的汇编代码便是:
imul %rdi,%rsi movl %rsi,%rax
2.3:C语言程序的机器表示
C语言是一门高级语言,C程序中含有多种复杂语法,如条件语句、开关语句、循环语句、递归调用等等。它们化繁为简到机器代码(只含0与1)之间的过程值得我们仔细研究:
2.3.1:条件语句:
条件语句(if—else)通常由比较指令(或测试指令)与跳转语句构成,其思路为:将if——else语句化为goto语句形式,再化为汇编语言。以《CSAPP》书U3 图3-16 图a)中代码为例:
long Inc(long x,long y){long result;if(x<y)return y-x;elsereturn x-y;}
化为goto语句形式后,C语言代码为(只展示条件语句):
if(x<=y)goto false;
return y-x;
false:return x-y;
化为汇编语句后,为:
cmpq %rsi,%rdi
jge .L2//goto false
movq %rsi,%rax //then-statement
subq %rdi,%rax
ret
.L2:
movq %rdi,%rax//else-statement
subq %rsi,%rax
ret
2.3.2:循环语句
C语言中含有多种循环语句的写法,如for循环、while循环、do—while循环,但汇编语言中没有专门的循环语句,因此同条件语句一样,汇编语言中通过比较语句与条件跳转语句配合来实现循环结构。同C语言中循环语句的三种形式,我也分别对do-while语句、while语句、for语句进行讲述分析,并在最后给出实例进行分析:
- do—while语句较其他两种来说,最为简单,简单来说此语句可以简化为:
loop:body-statementif(test-expr)goto loop
可见其中的if语句与goto语句都可以像之前说的,简单地使用比较指令、条件跳转指令来实现汇编化;
- 对于while语句,我们采用的方法是将其转化为do—while语句来实现汇编化:
goto test;
loop:body-statement;
test:t = test-expr;if(t)goto loop;- for语句较while语句只是加上了循环控制变量,因此可以在while语句之前加上对循环控制变量的初始化,并在循环体中加上对循环控制变量的更新操作,便可将其转化为while语句,进而将其转化为do—while语句:
init-expr;//循环控制变量的初始化
while(test-expr){body-statement;update-expr;//更新操作}
- 因为for语句的汇编化可以说涵盖了前两种语句的要点,也就是说最难转化为汇编,因此我将以for循环的汇编化作为例子,出自《CSAPP》U3 P157示例:
long fact_for(long n){
long i;
long sum = 0;
for(i=0;i<n;i++)sum+=i;
return sum;}
将其化为goto型代码可以是:
long fact_goto(long n){
long i = 0;// init-expr
long sum = 0;
goto test;
loop:sum+=i;i++;
test:if(i<n)goto loop;
return sum;
}
再将其写成汇编,为:
fact_goto:
movq $0,%rax
movq $0,%rdx
jmp .L8
.L9://循环体addq %rdx,%raxincq %rdx
.L8://循环继续条件cmpq %rdi,%rdxjl .L9
rep;ret
- 总结:可见,在汇编化的过程中,对于循环语句而言,三种循环语句之间可以互相转换,而且do—while循环是最为容易转换为汇编语言的,因此其编译时的效率最高,可知我们在编写程序时为了编译时的效率可以优先采用do—while循环。
2.3.3:递归调用
C语言函数的递归调用在解决实际问题时十分常见,在将C代码化为汇编代码时,递归过程又会如何表示呢?我将从栈的使用、递归过程两个方面阐述递归调用在编译时的具体表示:
- 栈的使用:因为递归调用需要一步一步回到调用者函数中去,因此返回地址必须要入栈,具体代码中,这个过程由call指令实现,call指令隐式地将返回地址入栈,并在这一次调用完成后将返回地址弹出栈;而且部分参数也需要入栈,以保护现场,一般使用%rbx寄存器保存需要进行保护的数据;举例如图:

- 递归过程:每一次递归调用都需要使用栈,需要将调用者的返回地址与参数(可能)入栈;例如《CSAPP》U3练习题3.35中:
C代码:
long rfun(unsigned long x){
if(x==0)return 0;
unsigned long nx = x>>2;
long rv = rfun(nx);
return x+rv;
}汇编代码:
rfun:
pushq %rbx
movq %rdi,%rbx //将x入栈,保护现场;
movl $0 , %eax
testq %rdi,%rdi
je .L2
shrq $2,%rdi //此时rdi寄存器中内容已经不是x,而是x>>2
call rfun //此时需要将返回地址,即call指令的下一条指令的地址入栈;
addq %rbx,%rax //此时可知为何需要将x的值入栈保护现场
.L2:
popq %rbx
ret
可见递归调用对栈的调用极其频繁,因此存在一种隐患,当一个入栈的数据,溢出了栈分配给它的空间,可能会影响到其他存放的数据。因此,针对这个特殊的危险情况,cmu官方有一个实验,我在第六个部分“相关实验”中详细讲解这个实验。
2.4:复杂数据类型的机器级表示
复杂数据结构,如数组、结构体、联合体等等在机器中都有其特殊的、独特的表示方式,现在我来讲述这几个复杂数据类型在机器中的具体表示方法。
-
数组:数组元素都是顺序存储,一维数组不用说,二维数组是按行优先的规则进行顺序存储;对于这种定长数组最重要的就是对一个给定下标与起始地址的数组元素寻址,解决这类问题有如下公式:
&D[i][j] = Xd + L(C*i + j),其中Xd为起始地址,L为数组数据类型的字长,C为该二维数组的列数。且在汇编语言中,数组元素寻址时一般用间接比例变址的方式(Imm1(Reg1,Reg2,Imm2))寻址。 -
结构体:结构体元素也是顺序存储,将不同类型的元素整合在一个对象中,而第一个元素的地址便是整个结构体变量的地址。但其结构体元素的存放有一条规则,该元素存放的地址必须是该元素字长的整数倍数。因此存放结构体时可能会存在浪费空间的问题,我们来看一个结构体的定义:
struct rec{
int i;
char a[2];
int *p;}
其存储结构如图:

可见其中有存储空间被浪费了,那么存在让存储空间浪费减少的方法吗?有的。
方法就是将字长最长的结构体成员放在定义最前,最短的放在最后面,依次定义。此时存储结构如图:

可见其所占用的存储空间确实减少了,而且没有浪费的情况出现。
- 联合体:联合体与结构体大致类似,但是特殊在于其元素共用同一个存储空间,来看这样一个联合体的定义:
union{
long data;
char a[8];
}
对union.data赋值为0x87654321。其存储结构如图:
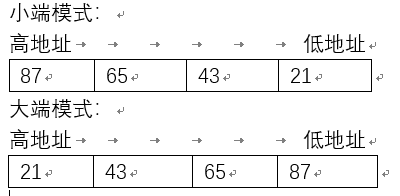
因此可见可以利用联合体的存储结构来对机器的存储方式(大or小端)进行检测。
2.5:相关Linux命令
这个单元绝大多数篇幅都是在讲C程序与汇编语言之间的联系,因此应该如何得到汇编代码,如何对C程序编译、优化成为一个亟待解决的问题,因此来引出相关Linux命令:想了解的读者请移步:Linux常用命令大全。
2.6:相关实验
在”2.3.3:递归调用“中,我提到cmu官方有一个关于栈数据溢出的实验。现在将其列出:
主体代码为:
#include <stdio.h>
#include <stdlib.h>
typedef struct {int a[2];double d;
} struct_t;
double fun(int i) {volatile struct_t s;s.d = 3.14;s.a[i] = 1073741824; /* Possibly out of bounds */return s.d; /* Should be 3.14 */
}
int main(int argc, char *argv[]) {int i = 0;if (argc >= 2)i = atoi(argv[1]);double d = fun(i);printf("fun(%d) --> %.10f\n", i, d);return 0;
}
当i不同时,输出结果是不一样的,如下:
gec@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out 0
fun(0) --> 3.1400000000
gec@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out 1
fun(1) --> 3.1400000000
gec@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out 2
fun(2) --> 3.1399998665
gec@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out 3
fun(3) --> 2.0000006104
gec@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out 4
fun(4) --> 3.1400000000
段错误 (核心已转储)
为什么会出现这样的变化,甚至在最后出现报错呢?答案是缓冲区溢出。
该函数涉及到的存储结构大致如下:

- 当数组下标i从0变化到1时,d的值都不会受到影响;
- 但当数组下标变到2和3时,d的内容则会被改变,因此才会看到打印出来的fun(i)的值不是3.14;
- 但当数组下标变到2和3时,d的内容则会被改变,因此才会看到打印出来的fun(i)的值不是3.14;
当数组下标i变到5时,问题更严重了,这一次修改的数据从d变到到了d之前的数据,即调用fun函数的调用者的返回地址,因此此时系统会报错“段错误(核心已转储)”。
2.7:U3总结
U3较U2来说,与实际编写程序的过程更加贴近,主体内容为讨论如何将C程序汇编化,期间也涉及到许多等价语法的转化,for循环—>while循环等等。期间可以看到哪一种语句在编译时效率更高,将这一单元学好对以后编程提高效率大有裨益。




