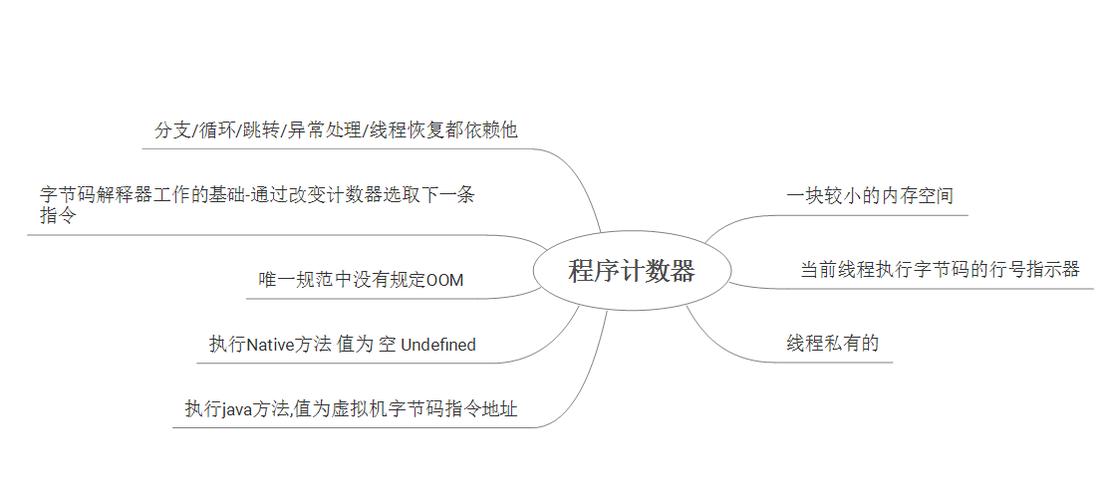
Elasticsearch 索引管理
索引压缩
执行索引压缩的步骤
创建索引
## create index
PUT idx_tobe_shirink_001
{"settings": {"number_of_shards": 10,"number_of_replicas": 10}
}
压缩前准备
压缩前准备工作
副本0; 禁止写; 必须同一个node
从这几点能看出其背后的一些限制
PUT idx_tobe_shirink_001/_settings
{"number_of_replicas": 0,"index.blocks.write": true,"index.routing.allocation.require._name":"node158"
}
压缩索引
# 压缩索引(内部原理:重建索引)
POST _reindex
{"source": {"index": "idx_tobe_shirink_001"},"dest": {"index": "idx_shirinked_001"}
}
查看设置
是否生效或者有没有其他限制
GET idx_tobe_shirink_001/_settings
执行 - 索引压缩
POST /idx_tobe_shirink_001/_shrink/idx_shirinked_001
{"settings": {"index.number_of_replicas": 1,"index.number_of_shards": 5,"index.codec": "best_compression","index.routing.allocation.require._name": null}
}
写数据前把禁止写开关去掉
PUT idx_shirinked_001/_settings
{"index.blocks.write": false
}
写入数据
POST idx_shirinked_001/_doc
{"key1": "value1"
}
查看写入数据
GET /idx_shirinked_001/_search
{"query": {"match_all": {}}
}索引压缩原理
实际上是压缩的分片,并非在原有索引上压缩,而是生成了一个新的索引,由于使用了 hash 路由算法以及索引不可变的特性
- 创建一个新的目标索引,其定义与源索引相同,但分片数量较少。
- 将段从源索引硬链接到目标索引。如果文件系统不支持硬链接,则将所有segment file都复制到新索引中,复制过程很耗时。
- shard recovery 操作,恢复目标索引。
- 要压缩的索引必须是只读
- target index的所有p shard必须位于同一节点。
- 索引的健康状态必须为 green
- target index不能已存在
- target index分片数量必须为source index的约数。比如source index p shard:12,那么target index p shard只能是6 4 3 2 1,如果比如source index p shard是质数,那target index p shard只能是1。
- 索引的 doc 数量不能超过 2 147 483 519个,因为单个分片最大支持这么多个doc。
- 目标节点所在服务器必须有足够大的磁盘空间。
- target index name必须满足一下条件
- 仅小写
- 不能包括****,/,,?,",<,>,|,``(空格字符), ,,#*
- 7.0之前的索引可能包含冒号(:),但已过时,并且在7.0+中不支持
- 不能为**.或…**
- 不能超过255个字节(请注意它是字节,因此多字节字符将更快地计入255个限制)
- 不建议使用以**.**开头的名称,但隐藏索引和由插件管理的内部索引 除外
# 设置为使索引和元数据只读
index.blocks.read_only:true
# 禁止索引读操作
index.blocks.read:true
# 禁止写索引
index.blocks.write :true
迁移数据时,可以指定节点
"index.routing.allocation.require._name": "target_node",
关闭的索引被阻止进行读/写操作,并且不允许打开的索引允许的所有操作。无法索引文档或在封闭索引中搜索文档。这允许封闭索引不必维护用于索引或搜索文档的内部数据结构,从而减少集群的开销。
在打开或关闭索引时,master 负责重新启动索引分片以反映索引的新状态。然后分片将经历正常的恢复过程。打开/关闭索引的数据由集群自动复制,以确保始终安全地保留足够的分片副本。
常见的索引操作
判断索引是否存在
HEAD <index>
打开索引
POST <index>/_open
关闭索引
适用不允许索引写入的场景
POST <index>/_close
创建索引
覆盖更新创建
_doc 没有创建,有则更新
PUT test_index_create/_doc/1
{"k1": "v1"
}
## 后边index id是可选项,不指定系统生成
## _doc这种方式,如果存在会更新
POST test_index_create/_doc[/index_id]
{
"test_post_create":"test_post_create"
}
后边的数字1,表示索引的ID,如果不指定,系统会生成一个
创建索引及插入数据
POST test_index_create/_create/your_record_id
{
"key1": 'vale1'
}
## 如果索引id存在则报错
查询索引
HEAD test_index_createGET test_index_create
删除索引
DELETE test_index_create
插入索引
_update
_update_by_query
_upseart
_script
flush索引
DELETE test_idx_delay
PUT test_idx_delay
{"settings":{"refresh_interval": "30s"}
}
## 覆盖写入 1表示id
PUT test_idx_delay/_doc/1
{"key1": "val1"
}
## 增加写入,自动生成id
POST test_idx_delay/_doc
{"key1111": "val1111"
}
##立刻刷新写入
POST test_idx_delay/_doc?refresh
{"key1111": "val1111"
}
## 立刻刷新,把延迟写入立刻刷新
POST test_idx_delay/_refresh
GET test_idx_delay/_search
refresh行为会立即把缓存中的文档写入segment中,但是
此时新创建的segment是写在文件系统的缓存中的。如果出现断电等异常,那么这部分数据就丢失了。所以es会定期
执行flush操作,将缓存中的segment全部写入磁盘并确保写入成功,同时创建一个commit point,整个过程就是一个完整的commit过程必须从memorybuffer->segment->os cache中才能被看到
index.translog.durability:同步还是异步,默认fsync
index.translog.sync_interval:translog的同步间隔,默认5s
index.translog.flush_threshold_size: 512mb
索引别名
别名作用
官方描述
索引别名是用于引用一个或多个现有索引的辅助名称。大多数 Elasticsearch API 接受索引别名来代替索引。
Elasticsearch 中的 API 在处理特定索引时接受索引名称,并在适用时接受多个索引。索引别名 API 允许使用名称为索引设置别名,所有 API 都会自动将别名转换为实际的索引名称。一个别名也可以映射到多个索引,当指定它时,别名会自动扩展为别名索引。别名也可以与搜索时自动应用的过滤器和路由值相关联。别名不能与索引同名。
傻瓜式描述
第一点、别名可以隐藏真正索引
如果可以隐藏的话,那么后续能做的事情就很多了
隐藏真正索引安全只是一方面,另一方面是可以类比域名,索引别名也可以绑定不同的真实索引,那么问题来了绑定不同索引有什么用呢?
比如按照时间、空间、数量进行滚动创建的索引,比如你规定客户只能查询当月的数据,这时候你就可以通过绑定当月索引进行强制限制数据访问范围。
查看索引信息:
GET test_idx_delay/_search
GET test_idx_delay/_mapping
GET test_idx_delay/_settings
GET test_idx_delay/_alias
保护索引
索引相对于调用者是隐藏的。
语法
POST /_aliases
基本用法
## 插入数据的一种写法
POST /_bulk
{ "index": { "_index": "test_idx_delay", "_id": "1" }} ## 表示插入哪个索引的哪个doc
{ "name": "iphone" ,"desc" : "good"} ## 表示插入的数据cmd+问号
## 官方文档地址: https://www.elastic.co/guide/en/elasticsearch/reference/7.17/indices-aliases.html
## add aliase
POST _aliases
{"actions": [{"add": {"index": "test_idx_delay","alias": "test_idx_delay_alias"}}]
}
## remove aliase
POST _aliases
{"actions": [{"remove": {"index": "test_idx_delay","alias": "test_idx_delay_alias"}}]
}## query alias
GET test_idx_delay/_alias
POST /_aliases
{"actions" : [{ "remove" : { "index" : "test_idx_delay", "alias" : "test_idx_delay_aliase1" } },{ "add" : { "index" : "test_idx_delay", "alias" : "test_idx_delay_aliase1" } }]
}
一个索引绑定多个别名
POST /_aliases
{"actions" : [{ "add" : { "index" : "product", "alias" : "product_real2" } },{ "add" : { "index" : "product2", "alias" : "product_real2" } }]
}
别名配置过滤器,使用PUT命令
使用PUT 上面用的是POST
PUT /test
{"aliases": {"alias_1": {},"alias_2": {"filter": {"term": { "user.id": "kimchy" }}}}
}
完整流程脚本
# 创建索引
POST test_idx_tobe_aliased/_doc
{"username":"tom"
}
#对已有索引创建别名
POST _aliases
{"actions": [{"add": {"index": "test_idx_tobe_aliased","alias": "test_idx_aliase"}}]
}## 创建索引时指定别名
PUT /test_idx_tobe_aliased01
{"aliases": {"test_idx_aliased_01": {"filter": {"term": {"user.age": "30"}}}}
}# 插入数据
POST test_idx_tobe_aliased/_doc/1
{
"test_post_create":"test_post_create"
}
## 插入数据2
POST test_idx_tobe_aliased/_create/3
{"user.id": "lily","age":4
}GET test_idx_tobe_aliased/_search
GET test_idx_tobe_aliased/_alias
## 根据索引别名查询数据
GET /test_idx_aliase/_search
{"query": {"match_all": {}}
}## 根据索引查询数据
GET /test_idx_tobe_aliased/_search
{"query": {"match_all": {}}
}
注意
- 一个索引可以绑定多个别名,一个别名也可以绑定多个索引
- 别名不能和索引名相同
滚动索引:rollover index
触发条件
- max_age:时间阈值
- max_docs:文档数阈值
- max_size:空间阈值
谁负责执行?
_rollover
它的原理是不断创建索引,然后把新创建的索引和索引别名进行关联
注意整个过程索引别名是不变的
内部怎么执行的?
todo 定时调度?No 手动执行_rollover方法
语法
POST /<index_alias>/_rollover
{"conditions": {"max_age": "7d","max_docs": 2,"max_size": "5gb"}
}
存在什么问题
无法把mapping信息带过去
如何解决?
需要定义索引模板
完整案例
# 滚动索引 6位数字或者date,注意数字前只能-而不允许是_
# 主要是创建别名, 这个字段定义不知道什么作用
PUT test_rollover_log-000001
{"mappings": {"properties": {"title":{"type": "text","analyzer": "english"}}},"aliases": {"test_rollover_alias": {}}
}
# 删除错误索引别名,注意这个不会删除索引,只删别名,指定索引只是表示要删除这个索引的别名
POST /_aliases
{"actions": [{"remove": {"index": "test_rollover_log_000001","alias": "test_rollover_alias"}}]
}
# 删除索引
DELETE test_rollover_log-000001
# 查看是否删除
HEAD test_rollover_log-000001## 存入数据
PUT test_rollover_alias/_bulk
{"index":{}}
{"title":"t3"}
{"index":{}}
{"title":"t4"}
GET test_rollover_alias/_search## 插入后需要刷新,否则延迟刷新不会立刻看到
POST test_rollover_alias/_refresh# 设置滚动条件,为什么现在设置而不是定义时设置?
# 执行一次仅创建和绑定一个,即使存在多个需要绑定的,多执行几次它会依次创建并绑定
POST /test_rollover_alias/_rollover
{"conditions":{"max_age": "7d","max_docs": 2,"max_size": "1gb"}
}#-------------------rollover index test-------------------------
注意
ES 的写入默认有延迟,可执行手动刷新
POST logs_write/_refresh
索引模板
概念
官方解释:索引模板是一种告诉Elasticsearch在创建索引时如何配置索引的方法。对于数据流,索引模板在创建时配置流的 backingDice。模板已配置创建索引之前. 创建索引时(无论是手动创建还是通过索引文档),模板设置都将用作创建索引的基础。
官方对于索引模板的解释已经比较清晰了,索引模板在企业生产实践中常配合滚动索引(Rollover Index)、索引的生命周期管理(ILM:Index lifecycle management)、数据流一起使用。
我的解释:
主要场景是: 你想某写情况下创建的索引按照你的个性化设置创建,不要每次都手动设置属性值。
这种情况下你就可以使用索引模板了。
具体做法是
- 你首先定义好设置模板
- 定义哪些索引使用这个模板,一般通过正则表达式
创建模板
PUT _index_template/test_zyy_template1
{"index_patterns": ["test-zyy-rollover-*", "test-zyy-template*"],"template": {"settings": {"number_of_shards": 1},"mappings": {"_source": {"enabled": true},"properties": {"host_name": {"type": "keyword"},"created_at": {"type": "date","format": "EEE MMM dd HH:mm:ss Z yyyy"}}},"aliases": {"test_alias_template1": { }}},"priority": 500
}
更新模板
重新put一遍即可,跟创建语句一样
删除模板
DELETE /_index_template/test_zyy_template1
如何使用模板
当执行任何创建模板的操作时会自动触发,根据正则匹配判断创建的索引是否匹配.
创建模板的方式:
- _reindex
- _rollover
- PUT index_name
- POST index_name
## 验证命中
PUT test-zyy-template22
GET test-zyy-template22/_mapping## 验证未命中
PUT test_zyy_not_template1
GET test_zyy_not_template1/_mapping## POST创建测试
POST test_zyy_template2/_doc
{"key":"val"
}
GET test_zyy_template2/_mapping## _reindex 未命中测试
POST _reindex
{"source": {"index": "test_zyy_template2"},"dest": {"index": "test_zyy_not_template3"}
}
GET test_zyy_template2/_mapping
GET test_zyy_not_template3/_mapping## _reindex 命中测试
POST _reindex
{"source": {"index": "test_zyy_template2"},"dest": {"index": "test_zyy_template_reindex1"}
}
GET test_zyy_template2/_mapping
GET test_zyy_template_reindex1/_mapping## _rollover测试
忽略自己实验吧
关于node roles
一个node就是一个elasticsearch实例.
每个node处理http和传输层流量,http由rest客户端使用.传输层用于node之间通信.
node.roles在elasticsearch.yml文件中进行配置,"node.roles":["",""]
role几种类型
master : 允许被选举为master 而不是实际的masterdata: 通用数据角色. 存储数据及执行数据相关的操作CRUD/聚合等.数据节点对机器IO/CPU/内幕才能要求较高.data_contentdata_hotdata_warmdata_colddata_frozeningestmlremote_cluster_clienttransform
在多层部署架构中,可以使用专用的数据角色将数据节点分配给特定的层级:data_content、data_hot、data_warm、data_cold或data_frozen。一个节点可以属于多个层级,但具有专门的数据角色之一的节点不能具有通用的数据角色。
remote_cluster_client role 主要用于跨集群搜索和跨集群复制
es中 content tier.和 hot tier有什么区别于联系
在Elasticsearch中,Content Tier和Hot Tier是存储和处理数据的不同层级,具有不同的特点和功能。它们之间的区别和联系如下:
区别:
- 数据类型:Content Tier主要用于存储静态内容,如产品目录或文章存档等不经常变化的数据。而Hot Tier主要用于存储时间序列数据,包括最新和频繁被查询的数据。
- 性能需求:Content Tier节点在处理查询时注重处理能力,优化查询性能和复杂搜索聚合的速度,通常使用较高的处理能力。而Hot Tier节点需要在读写方面都具备较高的速度,通常使用更快的存储设备(如SSDs)来处理高频查询和索引操作。
- 数据保留期限:Content Tier通常用于长期保留数据,即使数据变旧,也需要快速检索。Hot Tier主要保存最新的时间序列数据,随着时间的推移,数据可能会从Hot Tier移动到其他层级。
联系:
- 层级关系:Hot Tier通常作为数据流的入口层级,而Content Tier作为其他层级的基础层级。新的数据流索引会自动分配到Hot Tier,而不属于数据流的索引会自动分配到Content Tier。
- 数据冗余:为了提高容错性,两个层级中的索引都可以配置使用一个或多个副本。
- 分层存储策略:Hot Tier用于存储最新、频繁被查询的数据,而Content Tier用于存储静态内容。通过将数据根据查询频率和重要性分配到不同的层级,可以实现更高效的存储和查询。
总的来说,Content Tier和Hot Tier在存储和处理数据的方式上有所不同,但它们都是构建多层存储和处理架构的重要组成部分,以满足不同类型数据的需求和性能要求。
索引的生命周期管理
官方释义
配置索引生命周期管理 (ILM) 策略,以根据性能、可伸缩性和保留要求自动管理索引。例如,使用 ILM 来:
- 当索引达到特定大小或文档数量时启动新索引
- 每天、每周或每月创建一个新索引并归档以前的索引
- 删除过时的索引以强制执行数据保留标准
通过 Kibana Management 或 ILM API 创建和管理索引生命周期策略。当为 Beats 或 Logstash Elasticsearch 输出插件启用索引生命周期管理时,会自动配置默认策略。
我的理解就是把不同数据放到不同索引,甚至放到不同节点,这样提升查询性能
生命周期的阶段
-
Hot: The index is actively being updated and queried.
-
可以设置滚动阈值
hot阶段是必须的,其他的阶段是可选的
hot phase有个坑: rollover
这里指的是如果你想让索引在hot阶段待5min,你可以在hot设置rollover时间触发条件为5min,然后warm阶段设置data into为0,正常情况下没问题.但是问题出在哪呢?rollover的触发条件有3个,时间/空间/doc数量,哪个先触发就先执行哪个,比如5min和2个doc,如果doc先触发就会提前导致新建索引导致hot没有待够5min. 如果必须要求时间可以把rollover关闭. 虽然各个阶段的机制和rollover有点类似但是他们是同时执行的.
-
Warm: The index is no longer being updated but is still being queried.
配置项:
move data into phase: 指的是上个阶段(hot)多久移动到这个阶段
另外还可以指定哪些node可以分配warm,这个可以通过role或者自定义属性实现分配.如果通过role进行node选择,hot role的node一定要增加data_content角色,否则不生效.但是同时要注意其余的节点千万不要配置data_content,如果配置了,它不会优先分配给hot role的node,而是会随机选择
-
那么问题来了,data和data_content分别什么作用?
-
Cold: The index is no longer being updated and is queried infrequently. The information still needs to be searchable, but it’s okay if those queries are slower.
-
Frozen: The index is no longer being updated and is queried rarely. The information still needs to be searchable, but it’s okay if those queries are extremely slow.
-
Delete: The index is no longer needed and can safely be removed.
每个生命周期都可以设置不同的行为
Frozen可以设置可搜索快照
如果使用kibana可视化配置,它支持直接导出 http请求
如何一直白嫖付费功能
先点击适用,到时间之后,删除data目录
ILM: Index lifecicyle Management
注意几个问题
- ilm一般用于数据流
- 如果不是数据流使用,那么默认会优先分配data_content角色,即它不是优先分给data_hot的角色,然后依次流转的.知道这个点避免后续创建索引时迷惑
cold流转frozen报错
-
打开日志
-
PUT _cluster/settings {"persistent": {"indices": {"lifecycle":{"poll_interval": "1s"}},"logger.org.elasticsearch.xpack.ilm": "TRACE"} } -
GET /*/_ilm/explain?error_trace=true -
PUT /_cluster/settings {"transient": {"logger.org.elasticsearch.xpack.core.indexlifecycle": "DEBUG","logger.org.elasticsearch.xpack.indexlifecycle": "DEBUG","logger.org.elasticsearch.xpack.core.ilm": "DEBUG","logger.org.elasticsearch.xpack.ilm": "DEBUG"} }### 可以修改为INFO DEBUG等 -
可能的原因:没有创建repo
创建repo报错
doesn't match any of the locations specified by path.repo because this setting is empty
这个错误的原因所有的master和data都要配置一个path.repo路径
索引分片没有分配的原因
## 查看未分配原因
GET _cluster/allocation/explain## 手动重新分配
POST /_cluster/reroute?retry_failed=true
ILM和角色之间的关系
如果根据角色流转不要分配data_content角色
data_content : 优先分配给这个角色,如果有多个data_content,会根据负载均衡策略进行自动负载.因为这个角色优先级比较高,所以如果data_content和data_hot之类的同时设置的话,那么data_hot, data_warm等就会不起作用. 现象:就是不会优先分配data_hot,会随机选择data_content角色. 解决方案就是如果根据节点角色进行数据流转或者索引分配就不要配置data_content角色.
以上是单纯使用ilm的效果,如果是数据流的话data_content的这个规则就不生效了,它会根据节点实际的data_xx角色来分配.
数据流转策略
在ILM配置页面可以选择根据节点角色进行hot,warm,cold,frozen等数据流转.也可以根据自定义属性.
后续流转会根据你设置的条件如时间,大小,数量等等流转到data_warm,data_cold,data_frozen等等节点.
另外可以关闭rollover,rollover只对hot’节点数据流转起作用
data_frozen角色磁盘空间不够
解决办法
vim ./config/elasticsearch.yml
add
xpack.searchable.snapshot.shared_cache.size: 50%
以下几个设置不起作用:
<!-- 当磁盘使用量低于 cluster.routing.allocation.disk.watermark.low 的阈值时,Elasticsearch 将会解除对分片分配的限制,允许新的分片分配和重新分配操作。默认情况下,cluster.routing.allocation.disk.watermark.low 的值是 85%。 -->
cluster.routing.allocation.disk.watermark.low: 75%
<!--当磁盘使用量超过cluster.routing.allocation.disk.watermark.high的阈值时,Elasticsearch 将尝试阻止新的分片分配,但仍会继续进行分片的重新分配操作,以平衡集群的负载。-->
cluster.routing.allocation.disk.watermark.high: 80%
<!--当磁盘使用量超过cluster.routing.allocation.disk.watermark.flood_stage的阈值时,Elasticsearch 将进入洪水阶段,停止所有新的分片分配和重新分配操作。此时,集群将完全停止对磁盘的写入操作,以防止磁盘耗尽。-->
cluster.routing.allocation.disk.watermark.flood_stage: 85%
如何使用ILM
- 首先要配置ILM策略: Kibana-> stack Mangement ->Data->Index LifeCycle Policies->右侧create policies
- 配置模板,引用ILM策略
- 创建索引
- 插入数据
- 观察数据在节点流转
配置ILM策略
试用30天
试用可以试用searchable snapshot.直接点击license management ->试用30天即可
创建 ILM Policy
PUT _ilm/policy/test_ilm_000001
{"policy": {"phases": {"hot": {"min_age": "0ms","actions": {"set_priority": {"priority": 100}}},"warm": {"min_age": "10s","actions": {"set_priority": {"priority": 50},"allocate": {"number_of_replicas": 0}}},"cold": {"min_age": "20s","actions": {"set_priority": {"priority": 0},"allocate": {"number_of_replicas": 0}}},"frozen": {"min_age": "30s","actions": {"searchable_snapshot": {"snapshot_repository": "test_repo_001","force_merge_index": true}}},"delete": {"min_age": "1m","actions": {"delete": {"delete_searchable_snapshot": true}}}}}
}
创建索引模板 引用ILM
# 组件模板
PUT _component_template/test_component_template1
{"template": {"mappings": {"properties": {"created_at": {"type": "date","format": "EEE MMM dd HH:mm:ss Z yyyy"}}}}
}
PUT _component_template/test_component_template2
{"template": {"mappings": {"properties": {"host_name": {"type": "keyword"}}}}}
}
DELETE _index_template/test_idx_template1# 索引模板
PUT _index_template/test_idx_template1
{"index_patterns": ["test_idx_ilm_*"],"template": {"settings": {"index.lifecycle.name":"test_ilm_000001","number_of_shards": 1,"number_of_replicas":0},"mappings": {"properties": {}}},"composed_of": ["test_component_template1", "test_component_template2"]}
验证节点流转:使用直接插入数据到索引
# 新建索引
DELETE test_idx_ilm_*# 插入数据
PUT /test_idx_ilm_000001/_bulk
{"index":{}}
{"title": "head1"}
{"index":{}}
{"title": "head2"}刷新索引方便看结果
(非必要代码)
POST /test_idx_ilm_000001/_refresh
节点不流转分析
PUT _cluster/settings
{"persistent": {"indices": {"lifecycle":{"poll_interval": "1s"}}}
}
把ILM中的rollover关闭.后续数据流的时候再打开.
数据流
操作步骤
官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/data-streams.html
关于data roles的几个疑问和说明
data和data_content
区别于联系是什么?他们分别应用什么场景?
如果把data_content角色理解成冷热数据的分层,那么官方文档的描述貌似有不是这样
Content data node Content data nodes are part of the content tier. Data stored in the content tier is generally a collection of items such as a product catalog or article archive. Unlike time series data, the value of the content remains relatively constant over time, so it doesn’t make sense to move it to a tier with different performance characteristics as it ages. Content data typically has long data retention requirements, and you want to be able to retrieve items quickly regardless of how old they are.
这段大致意思是说:内容层主要存储一些归档文章,产品目录等非时间序列相关数据,这些数据随着时间移动到其他层没有意义(so it doesn’t make sense to move it to a tier with different performance characteristics as it ages.),这些内容数据另一个特性是具有长效存储和检索的要求(Content data typically has long data retention requirements, and you want to be able to retrieve items quickly regardless of how old they are)
data_content
是不是为了冷热分册设计的?或者说生命周期管理是不是为了实现冷热封层的管理手段(这里的内容分层我指的数据在hot,warm,cold,frozen之间流转)?
我的理解是内容分层的目标,产生了ilm生命周期管理的方式,使数据进行流式流转,
但是这段官方文档要表达的意思貌似是data_content不是应付数据流转的
我觉得如果这么理解的话我们设置data_content and data_hot等等内容分层还有什么意义?
这个角色在使用不同组件会产生很多迷惑的行为,比如当生性周期+数据流时规则是这样的:
data_content必须和[data_hot,data_warm,data_cold,data_frozen]等搭配使用.
数据流默认优先分配data_hot节点.
当触发新建索引阈值时,老索引才会流转
当直接使用索引+生性周期时:
此时它不会关注data_hot, 它会找data_content的角色的所有节点,然后根据负载策略找一个节点进行分配.
后续流转就会根据你配置的策略进行流转了,比如根据node 的role,它就会匹配data_warm,data_cold,data_frozen
但如果当前节点同时是下一个流转的节点它会报个错误,比如data_content和data_warm是一个节点, 首先第一次分配直接分配到到当前节点了,下个流转节点是data_warm,发现就是当前节点,那么就会报个错误
data
如果只设置data节点不设置data_content还能不能使用生命周期ilm来管理?比如使用自定义属性实现生命周期的数据流转?
集群特点与角色选择
我的集群存储什么类型的数据需要使用data角色,什么内容需要使用data_content角色(hot,warm…等等),另外如果不同角色我的机器配置有什么要求?
创建ILM策略
这是数据流所必须的,步骤如上
PUT _ilm/policy/test_ilm_datastream_000002
{"policy": {"phases": {"hot": {"min_age": "0ms","actions": {"set_priority": {"priority": 100},"rollover": {"max_size": "5gb","max_primary_shard_size": "5gb","max_age": "8s","max_docs": 2}}},"warm": {"min_age": "10s","actions": {"set_priority": {"priority": 50},"allocate": {"number_of_replicas": 0}}},"cold": {"min_age": "20s","actions": {"set_priority": {"priority": 0},"allocate": {"number_of_replicas": 0}}},"delete": {"min_age": "1m","actions": {"delete": {"delete_searchable_snapshot": true}}}}}
}
可以根据node 的role来进行分配,也可以根据自定义属性,上边的例子就是根据自定义属性.
role的官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/modules-node.html#data-node
创建组件模板
组件模板相当于是索引模板更小粒度的拆分,使得索引模板的使用更加灵活。你可以把组件模板理解成积木,模板可以灵活使用组件模板进行组合,提高模板的复用性
## 组件模板 - 定义mapping的模板组件
PUT _component_template/test_component_datastream_template_mappings
{"template": {"mappings": {"properties": {// 这个字段数据流必须的 名字也必须是这个,为什么?"@timestamp": {"type": "date","format": "date_optional_time||epoch_millis"},"message": {"type": "wildcard"}}}}
}
# 组件模板 - 定义settings
PUT _component_template/test_component_datastream_template_settings
{"template": {"settings": {"index.lifecycle.name": "test_ilm_datastream_000002","number_of_replicas": 0}}}
}创建索引模板
创建索引模板目的是关联哪些索引会使用到数据流. 它会把所有组件模板进行归并. 但是有一个问题,如果一个属性冲突了,是怎么一个策略?是按照先后顺序进行覆盖?
# DELETE /_index_template/test_idx_*
# 索引模板
PUT _index_template/test_idx_template_datastream01
{
// 表示这个开头的索引"index_patterns": ["test_idx_ilm_datastream_*"],// 上边开头的索引会应用到数据流"data_stream": { },"composed_of": ["test_component_datastream_template_mappings", "test_component_datastream_template_settings"]
}
创建数据流
数据流是针对于已存在的索引创建的,也是通过索引名称去关联索引模板中定义好的数据流的。
方式一 写入数据自动创建
## 删除所有索引,但是无法删除数据流索引
DELETE *
## 删除数据流索引
DELETE _data_stream/星号# 写入方式1: 写入数据到 数据流[索引] test_idx_ilm_datastream_000001
PUT test_idx_ilm_datastream_000001/_bulk
{ "create":{ } }
{ "@timestamp": "2099-05-06T16:21:15.000Z", "message": "aaaa" }
{ "create":{ } }
{ "@timestamp": "2099-05-06T16:25:42.000Z", "message": "bbb" }
## 查询
GET _data_stream/test_idx_ilm_datastream_000001# 写入方式2
POST test_idx_ilm_datastream_000002/_doc
{"@timestamp": "2099-05-06T16:21:15.000Z","message": "xxx"
}
#查询
GET _data_stream/test_idx_ilm_datastream_000002
方式二 使用 _data_stream API
PUT _data_stream/your_datastream_name
坑与避坑
Rollover中的时间配置和ILM的流转时间关系
-
Hot phase的默认最小声明周期(min_age,可配置)为10秒( [min_age]=[10s]),当在Hot phase中未设置Rollover时,Warm中的最小时间流转不能低于Hot phase的默认最小声明周期,也就是10秒。此时Hot phase向Warm phase的时间流转取决于Warm phase的min_age值,和Hot phase的min_age值无关 -
当在
Hot phase中配置了Rollover的时候,Hot phase向Warm phase的时间流转会受到Rollover的影响。其最终流转时间需同时满足Warm phase的min_age和Rollover的最先执行的条件。Rollover如果所有条件都一直不满足,Warm phase的min_age会等待Rollover的条件至少满足一个为止,换句话说,只要设置了Rollover,Rollover如果不满足创建新索引的条件,那么Warm phase会一直等待下去,直到创建新索引那一刻,Warm phase的min_age开始计时。举个例子:如果Rollover的三个条件为:
"rollover": {"max_primary_shard_size": "50gb","max_age": "100m","max_docs": 5
},
而 Warm phase的 min_age设置的时间为 10 秒,此时,如果索引的文档数一直是小于5,并且索引的体积一直小于50GB,那么索引从 Hot phase流转到 Warm phase的时间即:100m + 10 s,因为100分钟后Rollover产生了新索引。此时 Warm phase开始计时,10秒后流转。如果在100分钟内,max_primary_shard_size 或者 max_docs满足了其中任何一个条件,那么从满足条件这一刻起开始计时,10s中后数据从 Hot phase流转到 Warm phase。因此在做数据流或者ILM题目的时候,如果不是题目要求,不建议配置Rollover,以避免在对Rollover和ILM Phase关系不熟的情况下,把时间配置错误。
关于 node.roles的注意事项
node.roles配置项如果没有显式的配置,那么当前节点拥有所有角色(master、data、ingest、ml、remote_cluster_client、transform)。如果配置了则以配置的为准.
单节点集群角色
单节点集群一定要保证节点同时拥有 master和 data两个角色,切记是 data(或 data_content)不是 data_hot/data_warm/data_cold。