大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用9-模型训练中学习率的调整和假数据生成技巧与总结,我们在训练模型的时候,为了测试模型是否可以行,但是目前还没有标注好大量的数据,在缺乏数据的情况下,今天教大家如何生成假数据(测试数据)进行模型调试,并且教到家学习率如何调整来提高模型的性能,加快收敛的效果。
一、PyTorch框架下模型训练技巧
在PyTorch模型训练过程中,有很多可以提高训练效果和训练速度的技巧。以下是一些常见的技巧:
1. 学习率调整
2. 权重衰减
3. 使用预训练模型
4. 数据增强
5. 早停法
6. 使用不同的优化器
7. 层归一化
8. 使用更深的模型
9. 使用模型集成
后续会依依介绍,下面展开介绍其中一个技巧:学习率调整。
二、学习率调整技巧
学习率调整是通过在训练过程中动态调整学习率来优化模型训练的过程。在训练初期,学习率可以设得较高,以快速收敛;当训练接近收敛时,学习率可以降低,以减少参数的震荡,使模型更稳定。PyTorch 提供了一些现成的学习率调整策略,如StepLR,ExponentialLR和ReduceLROnPlateau等。
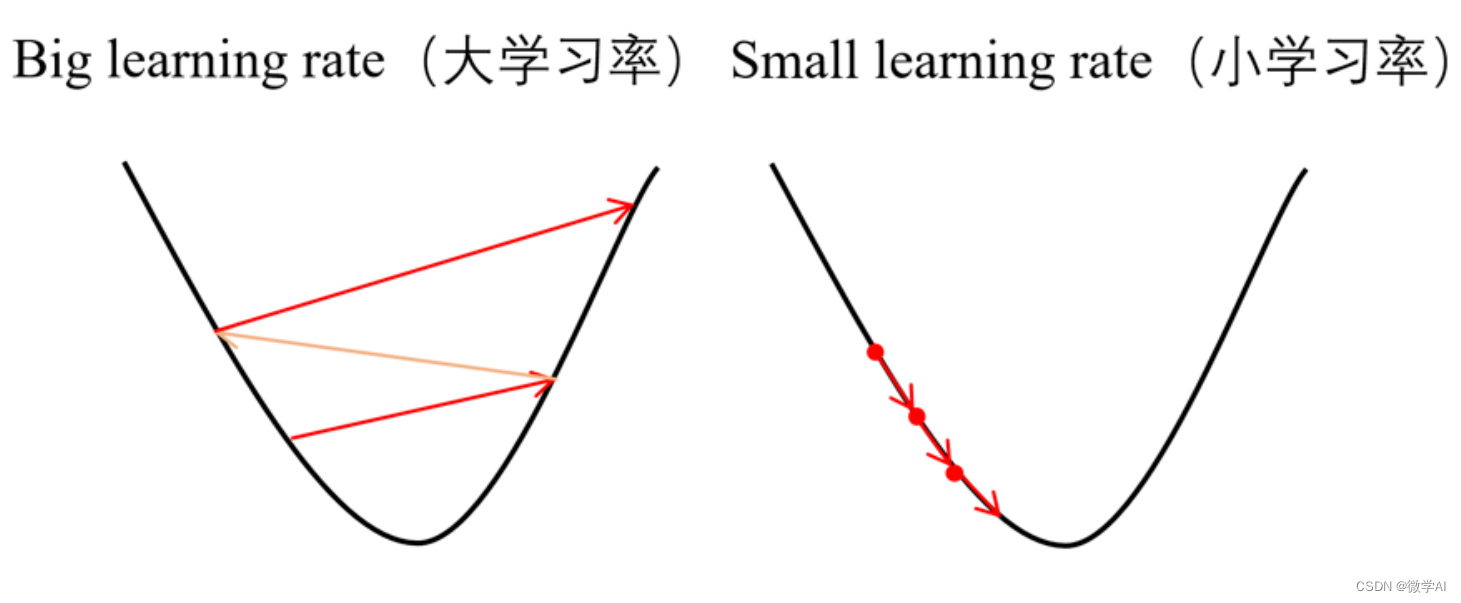
训练过程中越到极值点的时候步长就要越小,为了防止跳跃过极值点,但是刚开始的时候学习率过小又会使得收敛过慢,所以这里可以采用 StepLR学习率调整, StepLR学习率调整原理:将学习率按照固定的步长进行衰减。实际是,每经过一定的步数(由step_size指定),学习率就会乘以一个系数(由gamma指定)。例如,如果初始学习率为0.1,step_size为30,gamma为0.1,则在每30个步骤后,学习率都会乘以0.1,即变为之前的十分之一,直到达到最小学习率。使用StepLR能够使得模型在训练初期使用较大的学习率,有利于快速收敛;随着训练的进行,学习率逐渐变小,有助于细致优化模型参数,提高模型的泛化性能。
import torch
import torch.optim as optim
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
import torch.utils.data as data# 使用预训练模型
model = models.resnet18(pretrained=True)
# 修改最后全连接层的输出
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 2)
# GPU支持
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)# 定义损失函数及优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)# 使用StepLR调整学习率
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# 加载数据集
transform = transforms.Compose([transforms.Resize(256),transforms.RandomCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])三、FakeData生成假数据
FakeData可以用于生成各种类型的假数据集,包括图像数据。FakeData内置了一些函数,可以快速生成符合我们需求的假图像数据。例如,我们创建了一个名为fake_data的对象,它包含20个样本,2个类别,每个图像大小为3x224x224,其中3表示图像有3个颜色通道(RGB),224x224是图像的空间大小。同时,我们使用transforms.ToTensor()将生成的图像转换为张量形式,以便于深度学习模型的训练。接下来,使用data.DataLoader函数将fake_data中的数据加载到训练器中。DataLoader函数允许我们根据需要批量加载数据,并支持多个数据加载线程。我们将每个批次中包含4个样本,并通过参数shuffle=True来打乱数据集的顺序,以提高训练效果。
fake_data = datasets.FakeData(size=20, num_classes=2, image_size=(3, 224, 224), transform=transforms.ToTensor())
train_loader = data.DataLoader(fake_data, batch_size=4, shuffle=True)
四、真数据样例
如果我们有图片数据的话,可以设定相应文件夹,按照相应类别的文件夹下放置相应类别的图片,我们可以使用ImageFolder加载数据集。ImageFolder需要一个文件夹结构,其中每个子文件夹都包含一个类别的图像。这是一个非常常见的用于训练分类模型的数据集结构。
train_dataset = datasets.ImageFolder('train_data', transform=transform)
train_loader = data.DataLoader(train_dataset, batch_size=64, shuffle=True)假设我们有一个简单的数据集,包含两个类别:猫和狗。文件夹结构如下:
train_data/
cat/
cat1.jpg
cat2.jpg
…
dog/
dog1.jpg
dog2.jpg
…
五、模型训练
# 训练模型
num_epochs = 20
for epoch in range(num_epochs):model.train()running_loss = 0.0for inputs, labels in train_loader:inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()scheduler.step()print(f"Epoch {epoch + 1}, Loss: {running_loss / len(train_loader)}")我的这个训练过程使用预训练的ResNet18模型进行微调。我们使用SGD优化器,并定义了StepLR调度策略。每7个训练周期,学习率乘以一个系数(0.1),进行衰减。用一个简单的循环进行训练,并在每个训练周期的末尾调用scheduler.step()来更新学习率。在训练过程中,学习率将根据预定的学习率调度策略动态调整。
相信大家已经掌握了学习率调试的技巧了。