R中的方差分析
介绍用于比较独立组的不同类型的方差分析,包括:
- 单因素方差分析:独立样本 t 检验的扩展,用于在存在两个以上组的情况下比较均值。这是方差分析检验的最简单情况,其中数据仅根据一个分组变量(也称为因子变量)组织成多个组。其他同义词是:1 方式方差分析、单因素方差分析和主体间方差分析。
- 双向方差分析用于同时评估两个不同分组变量对连续结果变量的影响。其他同义词是:双因子设计、因子方差分析或双向主体间方差分析。
- 三因素方差分析用于同时评估三个不同分组变量对连续结果变量的影响。其他同义词是:阶乘方差分析或三向主体间方差分析。
请注意,独立分组变量也称为主体间因子。双向和三向方差分析的主要目标分别是评估在解释连续结果变量时,两个和三个主体间因子之间是否存在统计学上显着的交互作用效应。
学习内容:
- 计算和解释 R 中不同类型的方差分析,以比较独立组。
- 检查方差分析检验假设
- 执行事后测试,组之间的多个成对比较,以确定哪些组不同
- 使用箱形图可视化数据,将方差分析和成对比较 p 值添加到图中
基本
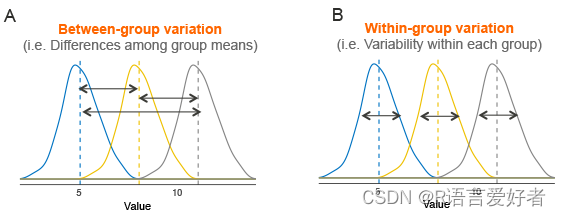
假设我们有 3 组要比较,如下图所示。虚线表示组均值。该图显示了组均值(面板 A)和每个组内的变化(面板 B)之间的变异,也称为残差方差。
方差分析检验背后的想法非常简单:如果组间的平均变异与组内的平均变异相比足够大,那么您可以得出结论,至少一个组均值不等于其他组均值。
因此,可以通过比较两个方差估计来评估组均值之间的差异是否显著。这就是为什么该方法被称为方差分析,即使主要目标是比较组均值。
简而言之,方差分析检验背后的数学过程如下:
- 计算组内方差,也称为残差方差。这告诉我们,每个参与者与他们自己的小组平均值有多大不同(见图,面板B)。
- 计算组均值之间的方差(见图,面板 A)。
- 将 F 统计量生成为 的比率。variance.between.groups/variance.within.groups
请注意,较低的 F 值 (F < 1) 表示所比较样本的均值之间没有显著差异。然而,较高的比率意味着与每个组中单个观测值的变异相比,组均值之间的变异彼此之间存在很大差异。
假设
方差分析检验对数据做出以下假设:
- 观察的独立性。每个主题只能属于一个组。每个组中的观测值之间没有关系。不允许对相同的参与者重复采取措施。
- 设计的任何单元中都没有明显的异常值
- 常态。每个设计单元的数据应近似呈正态分布。
- 方差的同质性。结果变量的方差在设计的每个单元格中应相等。
在计算方差分析检验之前,您需要执行一些初步检验以检查是否满足假设。
请注意,如果不满足上述假设,则存在单因子方差分析的非参数替代方案(Kruskal-Wallis 检验)。不幸的是,没有双向和三向方差分析的非参数替代方案。因此,在不满足假设的情况下,您可以考虑对变换数据和非变换数据运行双向/三向方差分析,以查看是否存在任何有意义的差异。如果两个检验都得出相同的结论,则可能不会选择变换结果变量并继续对原始数据进行双向/三向方差分析。也可以使用 WRS2 R 包执行稳健的方差分析测试。无论您的选择如何,您都应该报告您在结果中做了什么。
先决条件
请确保具有以下 R 包:
- tidyverse用于数据操作和可视化
- ggpubr用于创建易于发布的绘图
- rstatix提供管道友好型 R 函数,便于统计分析
- datarium:包含本章所需的数据集
加载所需的 R 包:
library(tidyverse)
library(ggpubr)
library(rstatix)data("PlantGrowth")
set.seed(1234)
PlantGrowth %>% sample_n_by(group, size = 1)
#查看group有几个水平
levels(PlantGrowth$group)单因素方差分析
检查假设
正态性假设
可以使用以下两种方法之一检查正态性假设:
- 分析方差分析模型残差以检查所有组的正态性。此方法更容易,并且当您有许多组或每个组的数据点很少时,它非常方便。
- 分别检查每个组的正态性。当只有几个组并且每个组有许多数据点时,可以使用此方法。
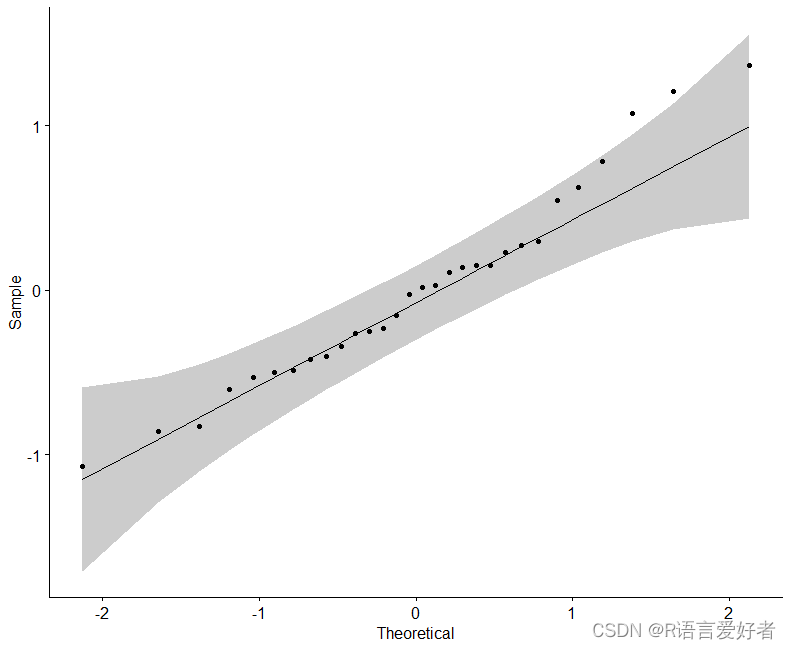
通过分析模型残差来检查正态性假设。使用QQ图和夏皮罗-威尔克正态性检验。QQ图绘制给定数据与正态分布之间的相关性。
# Build the linear model
model <- lm(weight ~ group, data = PlantGrowth)
# Create a QQ plot of residuals
ggqqplot(residuals(model))
shapiro_test(residuals(model))
# A tibble: 1 × 3variable statistic p.value<chr> <dbl> <dbl>
1 residuals(model) 0.966 0.438
在 QQ 图中,由于所有点都大致沿参考线落下,我们可以假设正态性。这一结论得到了夏皮罗-威尔克检验的支持。p 值不显著 (p = 0.13),因此我们可以假设正态性。
按组检查正态性假设。计算每个组级别的夏皮罗-威尔克测试。如果数据呈正态分布,则 p 值应大于 0.05。
> PlantGrowth %>%
+ group_by(group) %>%
+ shapiro_test(weight)
# A tibble: 3 × 4group variable statistic p<fct> <chr> <dbl> <dbl>
1 ctrl weight 0.957 0.747
2 trt1 weight 0.930 0.452
3 trt2 weight 0.941 0.564
每组的评分呈正态分布(p > 0.05),由夏皮罗-威尔克的正态性检验评估。
请注意,如果您的样本数量大于 50,则首选正态 QQ 图,因为在较大的样本量下,夏皮罗-威尔克检验变得非常敏感,即使与正态性有轻微的偏差。
QQ图绘制给定数据与正态分布之间的相关性。为每个组级别创建QQ图:
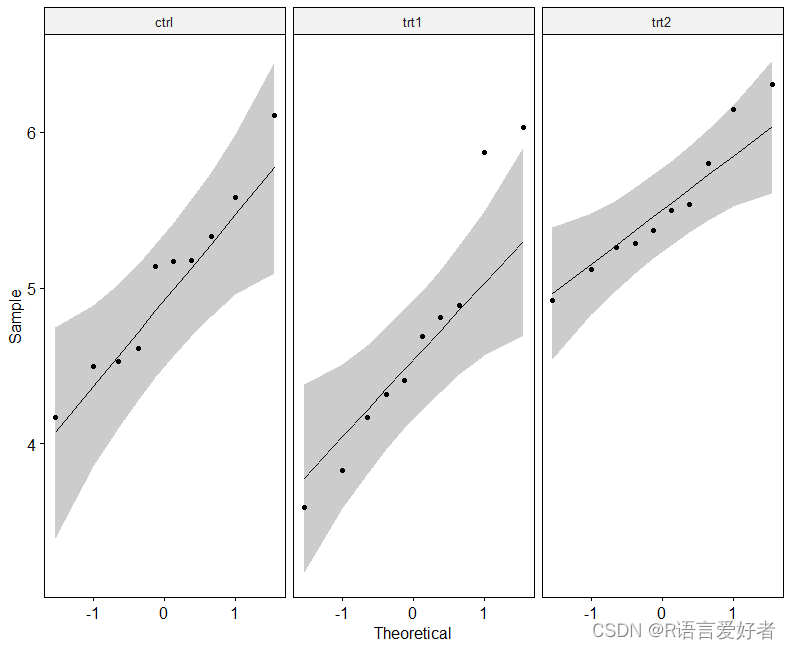
对于每个像元,所有点都大致沿参考线落下。因此,我们可以假设数据的正态性。
方差一致性假设
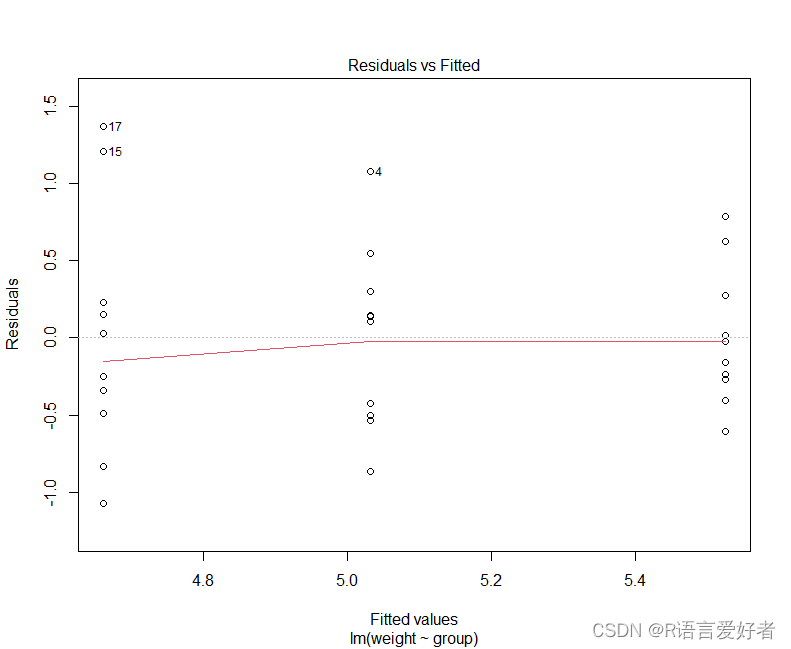
- 残差与拟合图可用于检查方差的同质性
plot(model, 1)
- 也可以使用 Levene 检验来检查方差的同质性:
> PlantGrowth %>% levene_test(weight ~ group)
# A tibble: 1 × 4df1 df2 statistic p<int> <int> <dbl> <dbl>
1 2 27 1.12 0.341
从上面的输出中,我们可以看到 p 值> 0.05,这并不显著。这意味着,组间方差之间没有显著差异。因此,我们可以假设不同治疗组中方差的同质性。
在不满足方差齐性假设的情况下,您可以使用函数 welch_anova_test()[rstatix 包] 计算 Welch 单因素方差分析检验。此检验不需要假设方差相等。
计算
> res.aov <- PlantGrowth %>% anova_test(weight ~ group)
> res.aov
ANOVA Table (type II tests)Effect DFn DFd F p p<.05 ges
1 group 2 27 4.846 0.016 * 0.264
在上表中,该列对应于广义 eta 平方(效应大小)。它测量结果变量(此处为植物)中变异性的比例,可以用预测因子(此处为治疗)来解释。0.26(26%)的效应大小意味着26%的变化可以解释治疗条件。
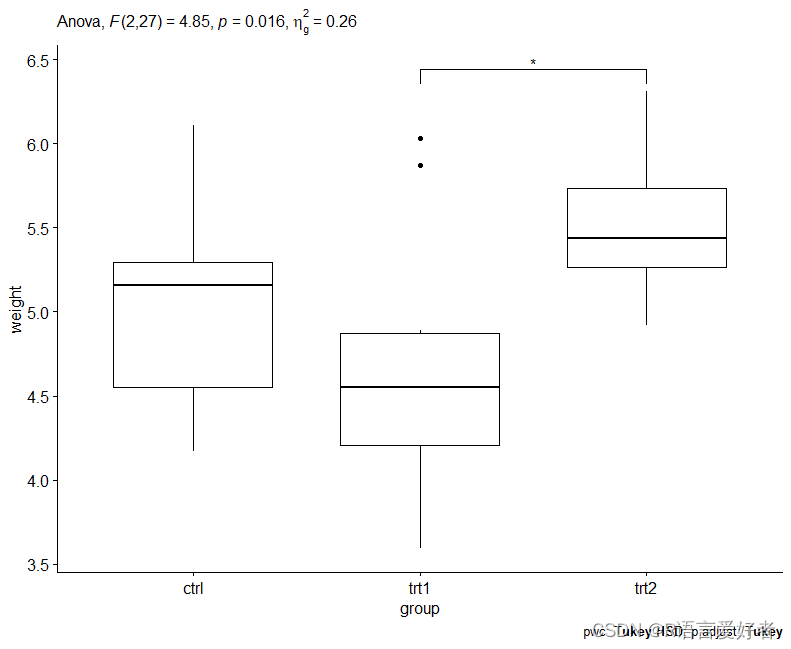
注意:从上面的方差分析表中可以看出,组间存在显著差异(p = 0.016),用“*”突出显示,F(2, 27) = 4.85,p = 0.16,eta2[g] = 0.26。
- F表示我们正在与 F 分布(F 检验)进行比较; 分别表示分子 (DFn) 和分母 (DFd) 中的自由度; 表示获得的 F 统计量值(2, 27)4.85
- p指定 p 值
- ges是广义效应大小(因子引起的变异量)
事后检查
显著的单因素方差分析通常由Tukey事后检验跟进,以在组之间进行多次成对比较。关键函数:tukey_hsd()
> # Pairwise comparisons
> pwc <- PlantGrowth %>% tukey_hsd(weight ~ group)
> pwc
# A tibble: 3 × 9term group1 group2 null.value estimate conf.low conf.high p.adj p.adj.signif* <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
1 group ctrl trt1 0 -0.371 -1.06 0.320 0.391 ns
2 group ctrl trt2 0 0.494 -0.197 1.19 0.198 ns
3 group trt1 trt2 0 0.865 0.174 1.56 0.012 *
输出包含以下列:
- estimate:估计两组均值之间的差异
- conf.low, : 置信区间的下限和上限为 95%(默认值)conf.high
- p.adj:多重比较调整后的 p 值。
注意:从输出中可以看出,只有 trt2 和 trt1 之间的差异是显著的(调整后的 p 值 = 0.012)。
报告
我们可以报告单因素方差分析的结果如下:
进行单因素方差分析以评估3个不同处理组的植物生长是否不同:ctr (n = 10),trt1(n = 10)和trt2(n = 10)。
数据以平均值 +/- 标准差表示。不同处理组间植物生长差异有统计学意义,F(2, 27) = 4.85, p = 0.016, 广义η平方 = 0.26.
与CTR组(1.4 +/- 66.0)相比,trt79组(5.03 +/- 0.58)的植物生长下降。与trt2和ctr组相比,trt5组(53.0 +/- 44.1)增加。
Tukey事后分析显示,从trt1到trt2(0.87,95%CI(0.17至1.56))的增加具有统计学意义(p = 0.012),但其他组间差异无统计学意义。
# Visualization: box plots with p-values
pwc <- pwc %>% add_xy_position(x = "group")
ggboxplot(PlantGrowth, x = "group", y = "weight") +stat_pvalue_manual(pwc, hide.ns = TRUE) +labs(subtitle = get_test_label(res.aov, detailed = TRUE),caption = get_pwc_label(pwc))
报告
经典的单因素方差分析检验要求假设所有组的方差相等。在我们的示例中,方差假设的同质性结果很好:Levene 检验并不显著。
在违反方差假设的同质性的情况下,我们如何保存方差分析检验?
- 韦尔奇单因子检验是在无法假设方差同质性的情况下(即 Levene 检验显著)的情况下替代标准单因素方差分析。
- 在这种情况下,可以使用 Games-Howell 事后检验或成对 t 检验(不假设方差相等)来比较组差异的所有可能组合。
# Welch One way ANOVA test
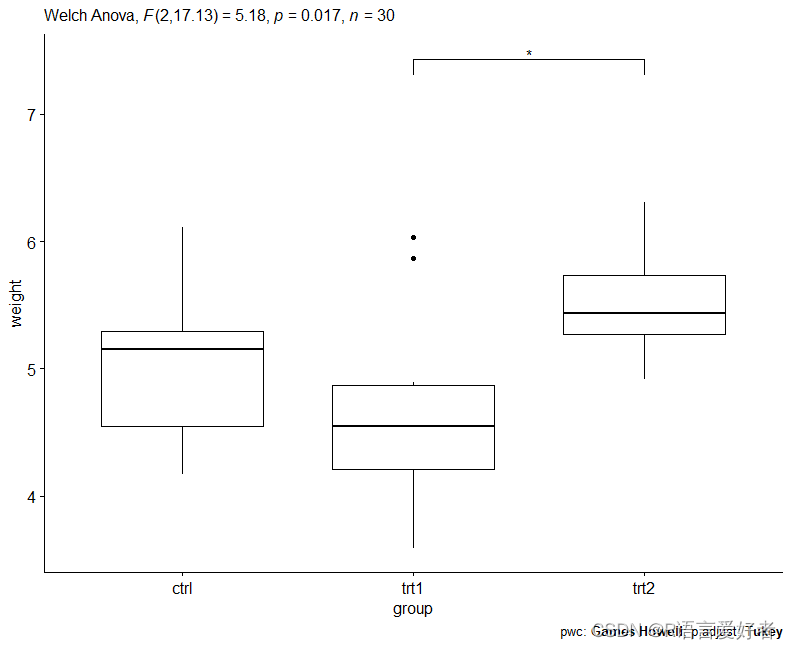
res.aov2 <- PlantGrowth %>% welch_anova_test(weight ~ group)
# Pairwise comparisons (Games-Howell)
pwc2 <- PlantGrowth %>% games_howell_test(weight ~ group)
# Visualization: box plots with p-values
pwc2 <- pwc2 %>% add_xy_position(x = "group", step.increase = 1)
ggboxplot(PlantGrowth, x = "group", y = "weight") +stat_pvalue_manual(pwc2, hide.ns = TRUE) +labs(subtitle = get_test_label(res.aov2, detailed = TRUE),caption = get_pwc_label(pwc2))
您还可以使用成对 t 检验执行成对比较,而不假设方差相等:
> pwc3 <- PlantGrowth %>%
+ pairwise_t_test(
+ weight ~ group, pool.sd = FALSE,
+ p.adjust.method = "bonferroni"
+ )
> pwc3
# A tibble: 3 × 10.y. group1 group2 n1 n2 statistic df p p.adj p.adj.signif
* <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <chr>
1 weight ctrl trt1 10 10 1.19 16.5 0.25 0.75 ns
2 weight ctrl trt2 10 10 -2.13 16.8 0.048 0.144 ns
3 weight trt1 trt2 10 10 -3.01 14.1 0.009 0.028 *
双因素方差分析
数据准备
我们将使用数据集 [datarium 包],其中包含按性别和教育水平组织的工作满意度分数。jobsatisfaction
在这项研究中,一项研究想要评估工作满意度分数之间是否存在显着的双向交互作用。当一个自变量对结果变量的影响取决于其他自变量的水平时,就会发生交互作用效应。如果交互作用效应不存在,则可以报告主效应。gendereducation_level
加载数据并按组随机检查一行:
五级标题
参考链接:
https://editor.csdn.net/md/?articleId=130452005