本次教程的目的是带领大家学会基本的花朵图像分类
首先我们来介绍下数据集,该数据集有5种花,一共有3670张图片,分别是daisy、dandelion、roses、sunflowers、tulips,数据存放结构如下所示

我们可以展示下roses的几张图片
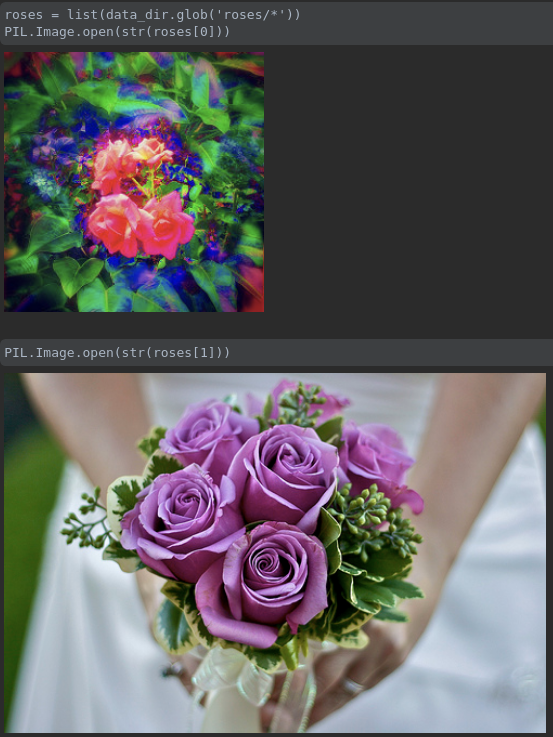
接下来我们需要加载数据集,然后对数据集进行划分,最后形成训练集、验证集、测试集,注意此处的验证集是从训练集切分出来的,比例是8:2
对数据进行探索的时候,我们发现原始的像素值是0-255,为了模型训练更稳定以及更容易收敛,我们需要标准化数据集,一般来说就是把像素值缩放到0-1,可以用下面的layer来实现
normalization_layer = tf.keras.layers.experimental.preprocessing.Rescaling(1./255)
为了使训练的时候I/O不成为瓶颈,我们可以进行如下设置
AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
下一步就是模型搭建,然后对模型进行训练
num_classes = 5 model = tf.keras.Sequential([tf.keras.layers.experimental.preprocessing.Rescaling(1./255),tf.keras.layers.Conv2D(32, 3, activation='relu'),tf.keras.layers.MaxPooling2D(),tf.keras.layers.Conv2D(32, 3, activation='relu'),tf.keras.layers.MaxPooling2D(),tf.keras.layers.Conv2D(32, 3, activation='relu'),tf.keras.layers.MaxPooling2D(),tf.keras.layers.Flatten(),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dense(num_classes) ]) model.compile(optimizer='adam',loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy']) model.fit(train_ds,validation_data=val_ds,epochs=3 )
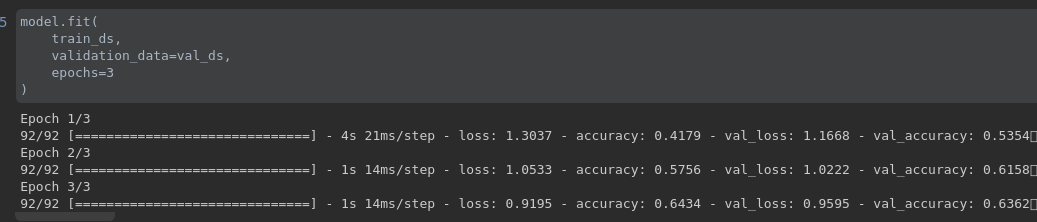
从上图的训练记录可以发现,该模型处于欠拟合状态,我们可以通过多训练几轮来解决这个问题,而且为了快速实验,我们这里用了一个非常简单的模型,我们可以通过更换更强的模型,来提升模型的表现
代码链接: https://codechina.csdn.net/csdn_codechina/enterprise_technology/-/blob/master/load_preprocess_images.ipynb