来看看论文:《Light Space Perspective Shadow Maps》
其中最精髓的一节是解释了阴影为什么会有锯齿。


dy = dz cosα /cosβ
dp/dy = 1/z
这里假定摄像机的近平面设置为1.

如果dp比一个像素还要大,那么就会出现锯齿。这个要这么理解,shadowmap里的1个像素,对应了屏幕上的多个像素,自然就会出现信息的丢失。换一种角度,假定近平面的分辨率,高度为1,
那么如果dp/ds比shadowmap/屏幕 分辨率之比还要大,那么也会出现锯齿。首先,我们假定shadowmap和屏幕分辨率一样大,那么希望像素一一对应。可是最终,dp=2ds,也就是说,一个shadowmap上的像素最终影响了两个屏幕上的像素,那么我们需要提高shadowmap的精度为原来的2倍才行。
那么看公式我们就知道:
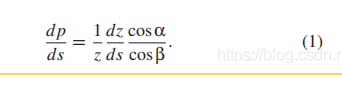

然后看这篇论:
《Parallel-Split Shadow Maps for Large-scale Virtual Environments》

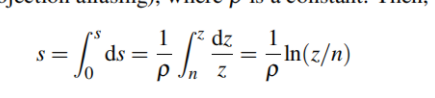
这个用了最基本的积分换元法。
因为s属于0-1,所以我们认为shadowmap完全覆盖了整个场景的深度而且没有任何浪费,然而这只是理论上的可能。在这样的假设下,我们推导出了ρ的值是ln(f/n).



有了这些结论,我们再来看英伟达的那篇级联阴影的论文。




最后这个矩阵看一下。因为我们算出来了物体的包围盒M,我们想让他和我们的投影后的矩阵完美的重合,这样我们可以通过缩放和平移来提高精度。

缩放上,我们把x,y从M缩放到2,也就是Sx,Sy,来完成,同时需要平移到合适的中心点。
(Mx+mx) / 2 应该平移到0点,这样就求出了Ox,Oy.

到这里,我发现英伟达这篇论文真的太水了。。。。