从一个不寻常的 I/O 卡顿入手,发现苹果 APFS 的一个严重 bug。
近期有用户反馈频繁遇到了一个奇怪的严重卡顿问题,微信刷朋友圈和查看聊天都非常卡,主线程卡在最普通的 access, rename 等常见 I/O 系统调用,并且经常卡上百 ms,而这种场景的底层接口一般都没干什么大量的 I/O 操作。比如 access 接口也就是获取文件是否存在的轻量操作,正常耗时都只有几十 us 而已,远达不到此时的上百 ms 耗时。
一、分析问题
寻找关键堆栈
堆栈上看,只是很常规的视频号卡片列表滑动时,触发了下载图片和查图片本地缓存的逻辑,通过 access 接口同步查本地图片是否存在,有则直接展示,否则从网络下载图片,下载完成时再尝试删除可能已有的旧文件。这完全是一个非常简单的图片缓存和加载逻辑。
通过搜寻卡顿报告,发现子线程都疑似存在大量的并发 I/O 操作,那是否卡顿的主因是和并发 I/O 有关呢?
尝试触发子线程并发 I/O 这个目录的图片,并打日志输出 access 接口的平均耗时,一切正常。走查功能也一切正常,毫无卡顿。
有同学说可能是目录下文件过多才会有 I/O 问题,在对应目录下构造了足够多的文件,再次走查业务功能,还是一切正常。
最终在多次试验和猜测后,构造出了一个高概率复现的场景,在对应目录下写入10万个小图片伪造图片数据,并触发并发 I/O,此时问题终于复现了。这个时候如果触发视频号卡片滑动,朋友圈卡片滑动,就大概率必现严重的滑动掉帧和卡顿了。
构造必现代码
大概知道了必现路径后,我们构造出了一个必现代码,打开 Instruments 的 System Trace 分析,结果如下:

发现 access 等常规 I/O 接口的平均耗时依旧很低只有几十 us,但等待耗时波动很大,可以达到140 ms,也就导致了主线程每次查询图片存在状态时,单次调用耗时超过了140 ms,而滑动过程中大概存在十几次这样的行为,那最终就是每次滑动都要因为这些 I/O wait time 导致滑动耗时数秒之久,甚至个别情况下还会因此滑动卡死触发 watchdog。
资料领取直通车:大厂面试题锦集+视频教程![]() https://docs.qq.com/doc/DTlhVekRrZUdDUEpy
https://docs.qq.com/doc/DTlhVekRrZUdDUEpy
免费学习网站:C/C++Linux服务器开发/后台架构师![]() https://ke.qq.com/course/417774?flowToken=1028592
https://ke.qq.com/course/417774?flowToken=1028592
继续分析 Instruments 报告,发现等待的主因如下:will wait for event/lock xxx.

经过前面的研究,我们已经能够构造一个必现 demo 了。大概如下:
- 特定目录下写入大约10万个文件
- 主线程触发频繁的 access 接口调用,统计平均耗时
- 子线程触发对该目录下的文件遍历并频繁的 rename 操作调用,统计平均耗时
如果2和3是同一个目录且当前目录文件数较多时,那么会高概率稳定复现平均 access 和 rename 等 I/O 接口调用 调用耗时过高的问题。而其它情况组合下,都不会复现这个问题。
测试工程跑在 MacBook Pro(2019) macOS 12.3 上,会定时 benchmark 测 access 接口耗时。
int retry = 5;long long duration = benchmark(retry,^{access(path.UTF8String, F_OK);});if(duration > 1000 * retry) {//avg >1 ms.LOG_P("lag: avg access %.3f ms",duration*1.f/1000/retry);}
在 APFS 分区的该目录下会频繁因大目录并发 I/O 遍历导致 access 超时问题,log输出如下:
lag: avg access 2.134 mslag: avg access 11.859 mslag: avg access 5.483 mslag: avg access 5.259 mslag: avg access 4.634 ms
这时在 x86 的 ssd 设备上都能稳定复现出 access 调用平均耗时 1ms 以上,个别情况下可以达到几十ms,确实令人费解。
dtrace 分析
既然 Instruments 告诉我们耗时的主因是 wait for lock,那接下来我们尝试分析下到底在 wait 什么 lock 最多。这就需要借助于 dtrace 来进一步分析了。
DTrace 即动态追踪技术(Dynamic Tracing),是内核提供的高级动态调试能力,可以帮助开发者快速调试定位一些奇怪的疑难杂症。操作系统会在内核的一些关键调用操作里提供 trace 代码执行的入口,我们可以通过注入 trace 命令或代码来实现自定义 trace 分析。Xcode Instruments 本质就是基于内核提供的 dtrace 能力来封装并实现的。
由于 iOS 平台不支持自定义 dtrace (虽然Instruments 就是基于 dtrace 的,但 iOS 即便越狱了也没办法触发自定义 dtrace 行为), 我们只有基于 macOS 打开 dtrace 分析下这个时候到底发生了什么。 运行 demo ,多次跑如下 dtrace 命令分析 demo 运行状态。
sudo dtrace -n 'lockstat:::adaptive-block { @[stack()] = sum(arg1); }' -p 95637
sudo dtrace -n 'profile-999 /arg0/ { @[stack()] = count(); }' -p 95806
sudo lockstat sleep 10
得到的 dtrace 相关数据如下:
kernel`0xffffff8005aa6990+0x72apfs`apfs_vnop_rename+0x94kernel`vn_rename+0x4aekernel`0xffffff8005d42020+0xb12kernel`unix_syscall64+0x1fbkernel`hndl_unix_scall64+0x161367kernel`lck_mtx_lock_spinwait_x86+0x2bekernel`vn_rename+0x4aekernel`0xffffff8005d42020+0xb12kernel`unix_syscall64+0x1fbkernel`hndl_unix_scall64+0x162242kernel`0xffffff8005aa67f0+0x7ekernel`namei+0x9f7kernel`0xffffff8005d375a0+0x79kernel`0xffffff8005d42020+0x35bkernel`unix_syscall64+0x1fbkernel`hndl_unix_scall64+0x162262R/W writer blocked by readers: 239 events in 10.048 seconds (24 events/sec)Count indv cuml rcnt abs Lock Caller
-------------------------------------------------------------------------------227 95% 95% 0.00 13385718 0xffffff8b638223e0 apfs_vnop_lookup+0x2f6 11 5% 100% 0.00 8140855 0xffffff8b638223e0 apfs_vnop_getattr+0xc4 1 0% 100% 0.00 2610265 0xffffff90339a97b0 omap_get+0x7c
-------------------------------------------------------------------------------R/W reader blocked by writer: 192 events in 10.021 seconds (19 events/sec)Count indv cuml rcnt abs Lock Caller
-------------------------------------------------------------------------------129 67% 67% 0.00 6408120 0xffffff8b638223e0 IORWLockWrite+0x90 22 11% 79% 0.00 23902 0xffffff99cd1fbc00 IORWLockWrite+0x90 12 6% 85% 0.00 28194 0xffffff804e970608 IORWLockWrite+0x90 4 2% 87% 0.00 18808 0xffffff8048892e08 IORWLockWrite+0x90 3 2% 89% 0.00 41491 0xffffff803825e608 lck_rw_lock_exclusive_check_contended+0x932 1% 90% 0.00 22725 0xffffff99cd1fbc80 IORWLockWrite+0x90 2 1% 91% 0.00 78215 0xffffff8b666c2610 IORWLockWrite+0x90 2 1% 92% 0.00 34049 0xffffff8b666c22c8 IORWLockWrite+0x90 2 1% 93% 0.00 23949 0xffffff8b666bc4c0 IORWLockWrite+0x90 2 1% 94% 0.00 28546 0xffffff8b666b94c0 IORWLockWrite+0x90 2 1% 95% 0.00 38088 0xffffff804e97ab08 lck_rw_lock_exclusive_check_contended+0x932 1% 96% 0.00 17158 0xffffff803dc78d08 0xffffff8005aa77d0 2 1% 97% 0.00 18658 0xffffff803dc78d08 IORWLockWrite+0x90 2 1% 98% 0.00 29096 tcbinfo+0x38 IORWLockWrite+0x90 1 1% 98% 0.00 52994 0xffffff8b666be7a0 IORWLockWrite+0x90 1 1% 99% 0.00 20135 0xffffff8048892e08 0xffffff8005aa77d0 1 1% 99% 0.00 18584 0xffffff80345de608 IORWLockWrite+0x90 1 1% 100% 0.00 13805 0xffffff803825e608 IORWLockWrite+0x90
-------------------------------------------------------------------------------
通过 dtrace 的 lockstat 数据,大概率怀疑是 kernel 层的 APFS 相关的 lock 出了问题,那为什么 APFS lock 会导致如此严重的问题呢?
Hopper 分析
rename 和 access 都是系统调用,他们都是 XNU 里 VFS 注册的系统服务。APFS 的系统支持是通过系统的 apfs.kext 内核扩展载入的,我们通过 Hopper 打开 apfs.kext,分析下 APFS 对应的 rename 或 access 里到底干了什么
_apfs_vnop_renamex
{r12 = arg0;r14 = *(int32_t *)(arg0 + 0x40);r14 = r14 & 0xfffffff7;if (r14 < 0x3) goto loc_5ad56;loc_5ad47:rax = 0x2d;if (r14 != 0x4) goto .l17;loc_5ad56:var_C8 = 0x0;var_170 = 0x0;var_190 = 0x0;r15 = _vfs_fsprivate(_vnode_mount(*(r12 + 0x8))); //获取目录r13 = _vnode_fsnode(*(r12 + 0x8));var_58 = _vnode_fsnode(*(r12 + 0x20));//... ....rax = _current_thread();var_120 = rax;if (rbx != rax) {_lck_rw_lock_shared(var_108); // 获取锁}
apf.kext 的代码里 vfs_fsprivate 返回了一个结构,这个结构存了每个 vnode 相关的附加字段,比如这里会疑似返回一个目录相关的锁,每次执行 rename 接口时,会取出目录锁,尝试加锁处理,而在 apfs.kext 代码里还有很多处额外的高频加锁逻辑。
通过进一步 System Trace 验证,当并发 I/O 遍历的文件目录是同一个时,Instruments 报告里的 will wait for lock xxx 会显示为同一个,大概率证明了 APFS 内部存在某种目录锁的结构,当对同一个目录的文件进行遍历 I/O 操作时,都会先请求加解锁。而在超大目录遍历时这个加锁导致的等待问题会急剧扩大,导致锁等待超时,最终可能导致了并发 I/O 速度骤降的问题。
对比 HFS+
我们在同一台电脑上构造了两个不同的磁盘分区:APFS 和 HFS+,分别在各自分区下的同一路径下写入了相同数据的10万个文件,接着开始跑同样的测试程序,又发现了更出人意料的结论:
HFS+ 测试如下:
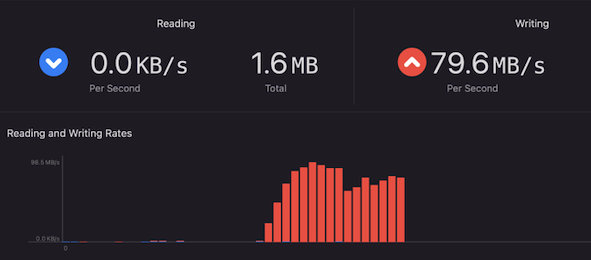
APFS 测试如下:
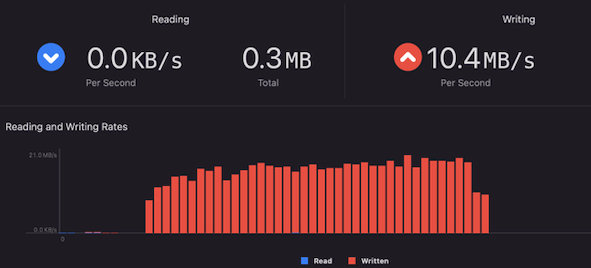
通过多次对比测试,发现在这种超大目录文件遍历的并发 I/O 情况下,HFS+ 的平均读写速度要比 APFS 快 8~20 倍,想不到 APFS 竟然反而比 HFS+ 要慢那么多。 这个问题在 macOS 12.3 和 iOS 15.4 上都可以稳定构造出必现测试用例。
二、解决问题
回到开始的卡顿问题,通过构造 demo 我们稳定复现了该问题,同时继续分析用户的相关数据,确认了用户遇到问题时的情况的确和我们最终 demo 构造的基本一致,至此又一个奇怪的卡顿问题终于找到原因了:超大目录导致了并发 I/O 时性能急剧下降。
既然我们已经明白了问题的根因超大目录结构导致的锁等待超时问题,那解决问题的办法就简单多了,将目录拆分为二级目录即可。
通过部分统计分析发现的确有很大一批老用户也存在这个超大目录结构的问题,目前微信已经将大部分超大目录逐步拆分为二级目录了。通过每级1000 个文件/夹,二级目录可以存储100万个文件,绰绰有余了。
经过测试,将该目录拆分为二级目录并缓解单目录文件过多的情况后,再也没有遇到类似的并发 I/O 卡顿的情况了。另外,该问题已经反馈给苹果,苹果内部也开了 radar ,希望可以进一步提升 APFS 性能。
一些坑
结合已有数据分析,发现苹果的文件操作里还存在一些坑,如下:
tmp
苹果在 File System Programming Guide 里建议 app 用 tmp/ 目录来存储临时文件,并且说系统会在 app 不运行时自动删除 tmp/ 目录的数据,但是实测,大概率不会,因为文档写的是 may purge。极端情况下该目录可能会存在 >90G 的占用。
WebKit
WebKit 的网络缓存默认在 /Library/Caches/WebKit/NetworkCache/ ,按照 WebKit 源码 NetworkCacheStorage 里的实现,WebKit 会采取一定随机+权重的方式删除网络缓存,但是极端情况下,个别用户会因此而占用 10G 或更多的存储空间。也就是这个随机删除存在很大的随机性。
NSURLCache
NSURLCache 自定义磁盘缓存路径时,如果 diskCapacity 设置过大,会导致占用超大存储空间,同时也会导致网络请求因为 I/O 读写慢而变慢。
删除文件
实测部分情况下删文件的 I/O 量基本等于写文件的 I/O 量,而且密集删文件时会容易导致 I/O 性能下降过快。因此业务应尽量避免短时间大量密集 I/O。
三、结论
System Trace 数据表明:当并发 I/O 遍历的文件目录是同一个时,Instruments 报告里的 will wait for lock xxx 会显示为同一个,也就进一步证明了 APFS 内部存在某种目录锁的结构,当对同一个目录的文件进行遍历 I/O 操作时,都会先请求加解锁。而在超大目录遍历时这个加锁导致的等待问题会急剧扩大,导致锁等待超时,最终可能导致了并发 I/O 速度骤降的问题。
为了避免这种极端情况导致的 I/O 性能骤降问题, 移动端 app 也需要合理的设计存储结构。例如需要分层分级管理文件,尽量不要将单个文件夹或单个文件搞的过大,同时也需要定时清理临时缓存目录,来进一步优化存储空间占用和优化 I/O 效率。
四、附录
苹果从 iOS10.3 开始引入了 APFS,而在此之前 HFS+ 一直是作为 iOS 和 macOS 的文件系统。
应用程序是如何从 ssd 等存储介质上读写文件的呢?如下图:

VFS
VFS 统一并抽象了不同文件系统的接口,使得用户可以通过统一的系统调用接口去访问不同文件系统不同存储介质上的文件。 VFS 主要可以被抽象为3层,vfstbllist 用于管理不同的文件系统,mount 管理文件系统的挂载,vnode 则抽象代表了文件和文件夹等对象。
- vfstbllist
XNU 中主要使用 vfstbllist 来注册管理多个文件系统,典型的 vfstlblist 如下:
/** Set up the filesystem operations for vnodes.*/
static struct vfstable vfstbllist[] = {/* HFS/HFS+ Filesystem */
#if HFS{ &hfs_vfsops, "hfs", 17, 0, (MNT_LOCAL | MNT_DOVOLFS), hfs_mountroot, NULL, 0, 0, VFC_VFSLOCALARGS | VFC_VFSREADDIR_EXTENDED | VFS_THREAD_SAFE_FLAG | VFC_VFS64BITREADY | VFC_VFSVNOP_PAGEOUTV2 | VFC_VFSVNOP_PAGEINV2, NULL, 0},
#endif/* Sun-compatible Network Filesystem */
#if NFSCLIENT{ &nfs_vfsops, "nfs", 2, 0, 0, NULL, NULL, 0, 0, VFC_VFSGENERICARGS | VFC_VFSPREFLIGHT | VFS_THREAD_SAFE_FLAG | VFC_VFS64BITREADY | VFC_VFSREADDIR_EXTENDED, NULL, 0},
#endif#ifndef __LP64__
#endif /* __LP64__ */... ...{NULL, "<unassigned>", 0, 0, 0, NULL, NULL, 0, 0, 0, NULL, 0},{NULL, "<unassigned>", 0, 0, 0, NULL, NULL, 0, 0, 0, NULL, 0}
};
内核可以动态的通过 vfs_fsadd 等接口来加载不同的内核扩展,以启用并支持新的文件系统。
- mount
文件系统只有被 mount 挂载后才可以被访问。对于内核支持的文件系统,macOS 会自动 从 /System/Library/FileSystems 里找到对应的内核扩展并挂载,而对于内核不支持的文件系统,则需要触发一次 kext 加载操作以支持对应的文件系统。 macOS 上常见的 mount 操作如下图:

- vnode
vnode 是 VFS 中最主要的组成。一个 vnode 可以代表一个文件或特定的一个文件系统对象。一个 vnode 一般对应实际的文件系统的对应 inode。
HFS+
HFS+(Hierarchical File System Plus) 是 Mac OS 8.1(1998年) 开始引入的文件系统,同时也是 iOS 10.3 以前默认的文件系统。HFS+ 能更好的利用磁盘空间,使用 unicode 存储文件编码,提供了更多当时来说更现代的文件系统支持。 HFS+ 使用了 Catalog File 来存储目录结构。Catalog File 的引入极大的提升了文件系统的查找速度,但也导致了所有 I/O 都会因为频繁访问 Catalog File 而被迫串行等待,导致超大并发性能会有较大下降。
APFS
APFS(Apple File System) 是苹果推出的最新文件系统,它是 HFS+ 的接任者,解决了 HFS+ 在更现代的文件系统上所缺失的能力。 APFS 为 ssd 而设计和优化,新增了 cloning, snapshots, space sharing, fast directory sizing, atomic safe-save, sparse files等特性,并补齐了苹果在现代文件系统能力上的缺失。
苹果的 APFS 和安卓设备的 F2FS 类似,都是专门为移动设备而优化的文件系统。二者设计上有很多异曲同工之处。
以 rename 调用为例,开发者通过触发 rename 系统调用向 VFS 请求文件操作,VFS 触发 vn_rename 调用,如果当前目录使用的分区是 APFS,则最终会触发 apfs_vnop_renamex,而如果是 HFS+ 分区,则会触发 hfs_vnop_rename 调用,最终完成 rename 操作。