-
题目描述:给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按任意顺序 返回答案。
-
示例
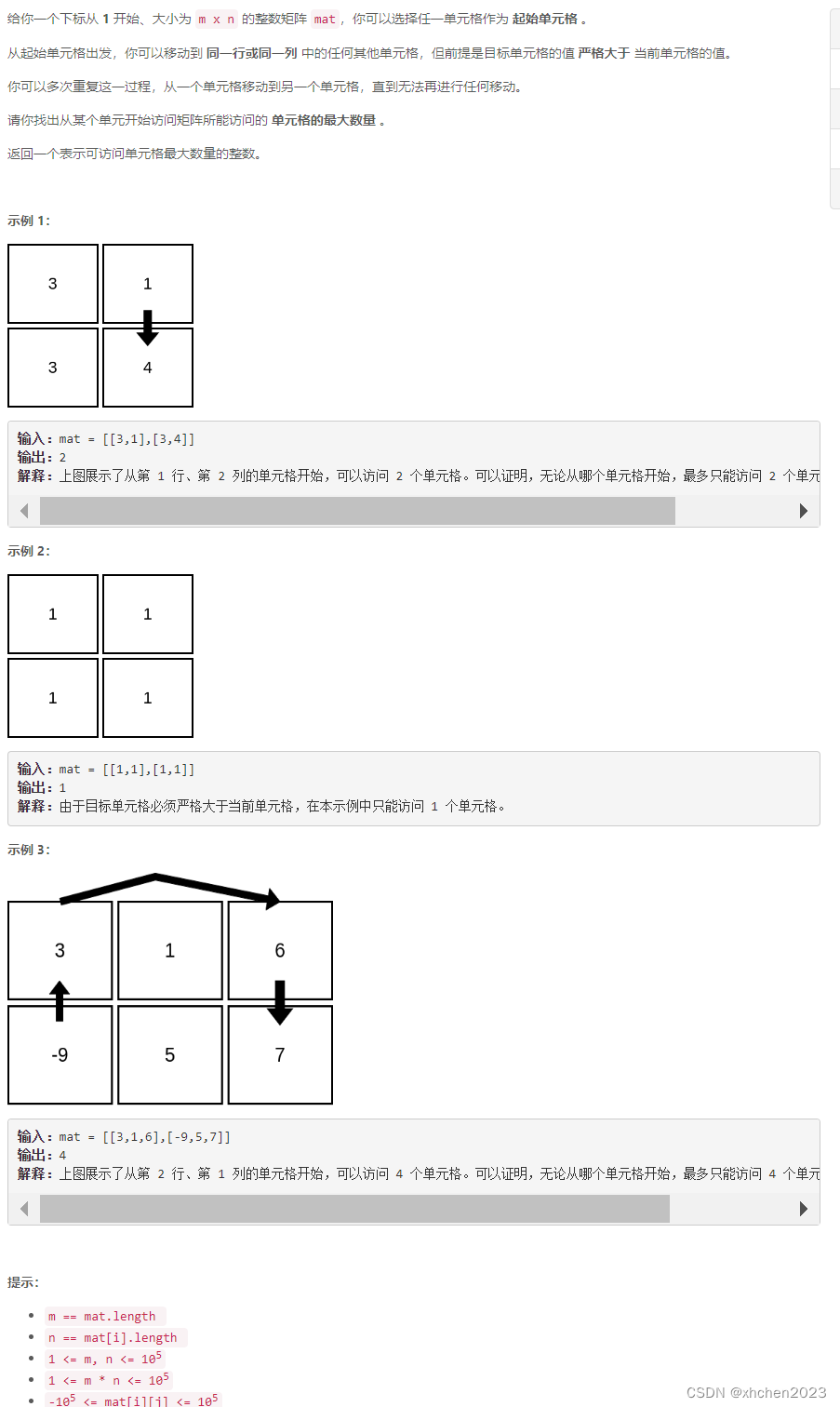
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]输入: nums = [1], k = 1
输出: [1] -
提示
1 <= nums.length <= 105
k 的取值范围是 [1, 数组中不相同的元素的个数],题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的
-
前 K 个高频元素
-
(方法一)解题思路:
(1)将每一个数组nums元素放进哈希表中,以元素值作为键,并为每个元素出现次数计数;
(2)给节点排序,uthash库中包含了哈希表的查询、插入、删除和排序等功能,包含的 HASH_SORT 函数可以根据key或者count值对哈希表的内容进行排序。本题应当依据count值进行从大到小排序,最后依次输出前k个哈希表的key值。 -
(方法一)代码:
/*** Note: The returned array must be malloced, assume caller calls free().*/
struct hash_table {int ikey; // 键值nums[i]int count; // 计数UT_hash_handle hh;
};
struct hash_table *h;
struct hash_table* find(int ikey)
{struct hash_table *s = NULL;HASH_FIND_INT(h,&ikey,s);return s;
}
void insert(int ikey)
{struct hash_table *s = find(ikey);if(s==NULL){s = (struct hash_table*)malloc(sizeof(struct hash_table)); s->ikey = ikey; s->count = 1;HASH_ADD_INT(h, ikey, s);}else{s->count++;}
}
// 类似于qsort函数里的cmp函数,确定排序是从大到小还是从小到大
int count_sort(struct hash_table *a, struct hash_table *b) {return (b->count - a->count);//依据count值从大到小排序
}int* topKFrequent(int* nums, int numsSize, int k, int* returnSize){*returnSize = k;h = NULL;for(int i=0;i<numsSize;i++){insert(nums[i]);}int *ret = (int*)malloc(sizeof(int)*k);// 对哈希表依据count值进行排序HASH_SORT(h, count_sort);struct hash_table *s;int index = 0;for(s = h;index < k; s = s->hh.next) {ret[index++] = s->ikey;}return ret;
}
- 时间复杂度?空间复杂度?
- (方法二)解题思路:
(1)将每一个数组nums元素放进哈希表中,以元素值作为键,并为每个元素出现次数计数;
(2)建立大小为 k 的小顶堆,比较后续元素和堆顶元素count值,如果后续元素比较大,则将堆顶元素替换成新元素值,将替换后的堆进行小顶堆的筛选,保证堆顶元素的最小的(中间元素不一定非要严格按照从小到大排序)。 - (方法二)代码:
/*** Note: The returned array must be malloced, assume caller calls free().*/// 时间复杂度:O(Nlogk)// 空间复杂度:O(N)
struct hash_table {int ikey; // 键值nums[i]int count; // 计数UT_hash_handle hh;
};
struct pairs{int val;int count;
};
struct pairs *heap;
struct hash_table *h;
// 哈希表的插入函数
void insert(int ikey)
{struct hash_table *s = NULL;HASH_FIND_INT(h,&ikey,s);if(s==NULL){s = (struct hash_table*)malloc(sizeof(struct hash_table)); s->ikey = ikey; s->count = 1;HASH_ADD_INT(h, ikey, s);}else{s->count++;}
}
// 交换
void swap(struct pairs* i, struct pairs* j)
{struct pairs temp = *i;*i = *j;*j = temp;
}
// 建立小顶堆的过程,最顶上的元素一定是最小的
void build_little_heap(int start,int end)
{for (int index = 2 * start + 1;index <= end;index=2* index+1){if (index < end && heap[index].count > heap[index + 1].count){index++;}if (heap[start].count <= heap[index].count){break;}swap(heap + start, heap + index);start = index;}
}int* topKFrequent(int* nums, int numsSize, int k, int* returnSize){*returnSize = k;h = NULL;for(int i=0;i<numsSize;i++){insert(nums[i]);}heap = (struct pairs*)malloc(sizeof(struct pairs)*(k+1));int *heapSize = malloc(sizeof(int));*heapSize = 0;struct hash_table *s,*tmp;// HASH_ITER(hh, h, s, tmp)for (s = h; s != NULL; s = s->hh.next){if(*heapSize >= k) // 元素数目超过小顶堆元素数目,需要将堆顶元素弹出,替换成要加进去的元素{struct pairs tmp = heap[0];if(tmp.count < s->count){heap[0].val = s->ikey;heap[0].count = s->count;for(int i=*heapSize/2-1;i>=0;i--)//重复建立小顶堆的过程,保证堆顶元素最小{build_little_heap(i,*heapSize-1);}}}else// 元素数目不超过小顶堆元素数目,将元素 放入堆底{heap[*heapSize].val = s->ikey;heap[(*heapSize)++].count = s->count;for(int i=*heapSize/2-1;i>=0;i--){build_little_heap(i,*heapSize-1);//重复建立小顶堆的过程,保证堆顶元素最小}}}int* ret = (int*)malloc(sizeof(int)*k);for(int i=0;i<k;i++){ret[i] = heap[i].val;}return ret;
}