连结Jasonnor/tf-idf-pythongithub.com
简介
tf-idf(term frequency-inverse document frequency)是一种用於信息检索与文字探勘的常用加权技术,为一种统计方法,评估字词对於「文件集合」或「语料库中的一份文件」的重要程度。详细方法和公式可参见Wikipedia,不再赘述。Figure 1: 输入「笑傲江湖」文件集合,每份文件为小说中的一个章回,输出每章前 K 高的字词和其权重
本项目为实作 tf-idf ,输入给定「一组有特定集合关系的文件」(例如某本小说),输出为每份文件的 tf-idf 权重值结果,具体为显示前 k 高的「字词」和其权重值,如 Figure 1 所示。另外也可以输入某个字词,输出该字词在所有文件中的权重值。
因为中文无法像英文可以藉由空白来区隔字词,我们采用了 jieba 结巴中文分词,将文件集合先进行分词获得语料库,之後使用 tf-idf 演算法取得字词加权值。
预设测试资料位於 data 资料夹底下,每组文件以 01 ~ 99.txt 格式命名,并放置到各别所属集合的资料夹,例如 data/笑傲江湖/01.txt 。测试资料包含笑傲江湖丶创世纪丶出埃及记。
jieba 其实也内建了「基於 TF-IDF 算法的关键词抽取」,不过根据它的文件和 Source Code 所述, jieba 其实只读取一个文件来计算TF,而IDF部分则是读取他们自定的语料库,因此结果不准确(不是基於相关文件集合来计算逆频率)。具体可以试试目录下的src/tf-idf-jieba.py,我写了简单的 jieba 版本 Demo。
预览简易GUI
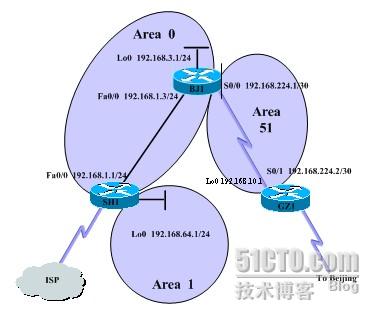
「笑傲江湖」资料集的各章字词权重列表,可以看到各章节的重要关键字排名
字词「任我行」在各章节的权重排名,可以看到他在第28章出场最多,而数值为0的部分就能得知他没有出现
結論
tf-idf 这个统计方法可以应用在许多场合,处理小说只是其中一种。不过 tf-idf 尽管简单有效,却存在部分重大缺陷。以我个人发现的例子来说,笑傲江湖资料集里每章基本上都一定会出现主角的名字「令狐冲」这个字词,然而对 tf-idf 来说,每章都出现的东西代表它是常用字词,逆频率的存在使「令狐冲」的权重反而变为 0,这真是很讽刺的结果。
可以见得 idf 的简单架构不能有效反映常见字词和重要字词的比重,精确度并不是很高。另外位置资讯也是其缺陷一环,不过在小说中这种缺点并不明显,因此不多做讨论。


![烟雨江湖小米鸿蒙,烟雨江湖小米时装怎么拿? 小米衣服获取方法详解[多图]](https://img-blog.csdnimg.cn/img_convert/a97707e537fc14049df9fffcd00fa19e.png)