Windows安装HBase2.0.0(单机版)
- 说明
- 准备工作
- 配置windows hosts文件,配置服务器IP和名称
- 查看HBase和hadoop版本对照关系
- 下载安装jdk1.8+
- 下载安装
- 下载安装运行Hadoop-2.7.7
- 下载和解压安装
- 下载winutils,覆盖文件到D:\hadoop-2.7.7\bin
- 添加hadoop环境变量
- 配置JAVA_HOME路径
- 修改hadoop配置文件,初始化节点
- 下载phoenix-5.0.0
- 下载地址
- 下载安装运行HBase2.0.0
- 下载HBase
- 解压安装包
- 拷贝phoenix包里的连接jar包到hbase的lib下
- 修改配置
- 运行HBase
- 下载安装DBeaver7.2.3、连接HBase
- 下载安装
- 配置jdk
- 设置phoenix驱动、连接HBase
- 总结
说明
安装HBase单机版本遇到很多问题,查了很多资料,本文档对安装过程做总结分享,希望对大家有所帮助。
涉及软件环境清单:
JDK1.8、windows server操作系统、hadoop2.7.7、winutils 2.7.7、apache-phoenix-5.0.0-HBase-2.0-bin(HBase连接工具包)、HBase2.0.0、DBeaver7.2.3(数据库连接工具)。
准备工作
配置hosts文件和查看hbase、hadoop版本信息。
配置windows hosts文件,配置服务器IP和名称
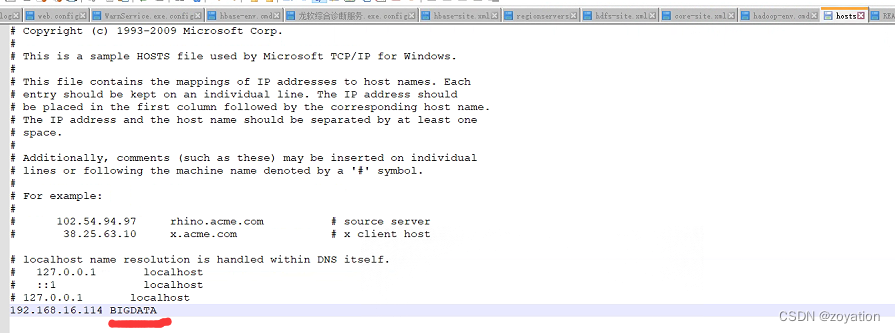
Hosts路径:C:\Windows\System32\drivers\etc\hosts
机器可能有多个IP,配host统一HBase服务器机器名字和IP,后面hadoop和HBase配置文件里host都用配置的名字比如: BIGDATA。
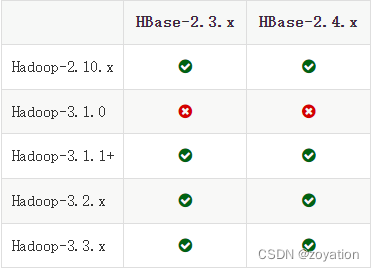
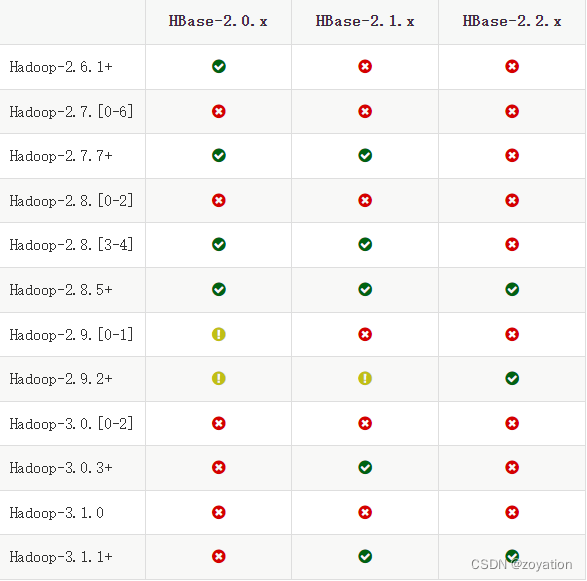
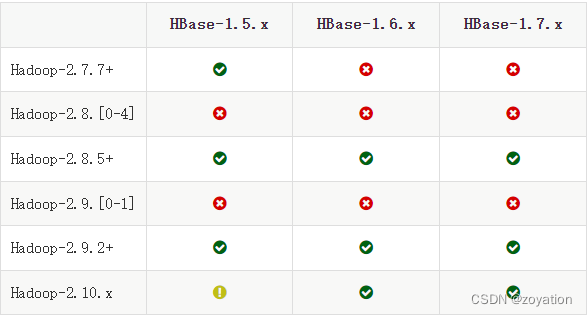
查看HBase和hadoop版本对照关系
按对照关系下载版本对应版本Hadoop和HBase
官网版本对照地址:https://HBase.apache.org/book.html#hadoop
下载安装jdk1.8+
HBase和hadoop运行都需要java支持,需要下载安装jdk或者jre。
下载安装
https://www.oracle.com/java/technologies/downloads/#java8-windows
下载地址:
https://download.oracle.com/otn/java/jdk/8u341-b10/424b9da4b48848379167015dcc250d8d/jdk-8u341-windows-x64.exe
下载后双击安装。
下载安装运行Hadoop-2.7.7
Haoop在windows运行需要winutils支持,下载解压后用winutils里bin下文件覆盖hadoop bin目录下的文件,配置hadoop环境变量,配置JAVA_HOME路径,修改hadoop配置文件,初始化节点信息,运行启动服务。
下载和解压安装
所有版本:https://archive.apache.org/dist/hadoop/common
2.7.7版本:https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
下载后解压放到指定目录比如:D:\hadoop-2.7.7
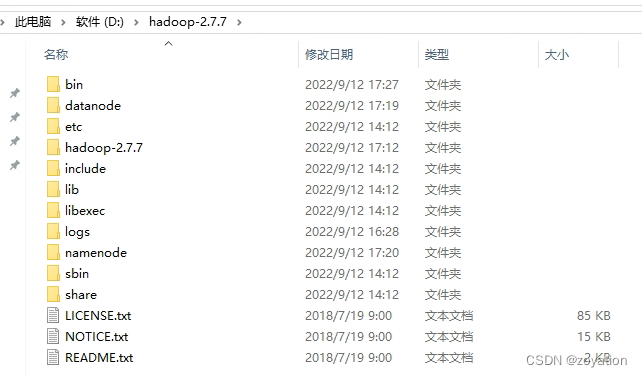
下载winutils,覆盖文件到D:\hadoop-2.7.7\bin
Windows下运行hadoop需要winutils适配文件
winutils下载地址:https://github.com/cdarlint/winutils
https://github.com/cdarlint/winutils/archive/refs/heads/master.zip
下载后,winutils对应hadoop版本bin下面的文件拷贝到hadoop的bin目录,比如:
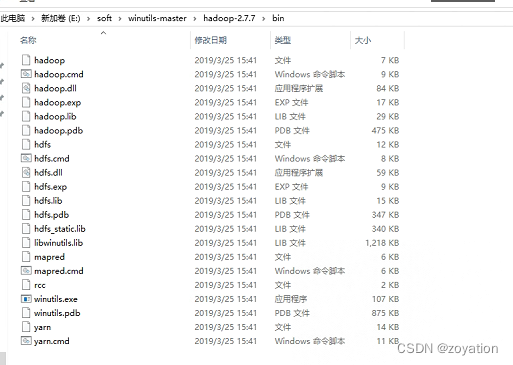
拷贝覆盖到:D:\hadoop-2.7.7\bin
添加hadoop环境变量
HADOOP_HOME,HADOOP_CONF_DIR
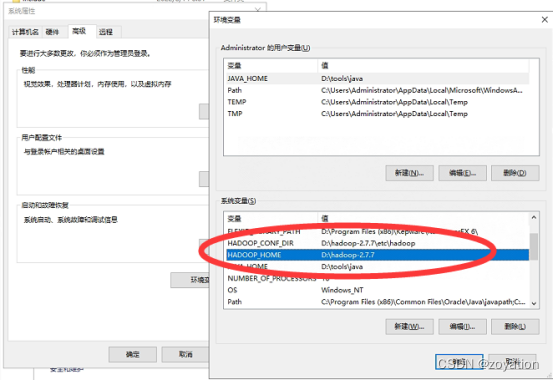
配置JAVA_HOME路径
如果自带JAVA_HOME路径里带空格, hadoop运行会报JAVA_HOME的错
原因:hadoop运行需要java的支持,我们需要把本地的JAVA_HOME重新和hadoop关联一下。
方式1:
用~1方式在hadoop_env.cmd 里配置
set JAVA_HOME=D:\PROGRAM~1\Java\jdk1.8.0_271
方式2:
Java路径有空格创建软链接
cmd里执行:mklink /J D:\tools\java “D:\Program Files\Java\jdk1.8.0_271”
在hadoop_env.cmd 里配置
set JAVA_HOME=D:\tools\java
修改hadoop配置文件,初始化节点
配置文件里的BIGDATA为windows hosts文件里配置的机器名称,同时设置namenode和datanode文件路径。
1.修改/etc/hadoop下面的配置文件
hdfs-site.xml、core-site.xml
配置hdfs-site.xml:
<configuration><property><name>dfs.namenode.http-address</name><value>BIGDATA:50070</value></property><property> <name>dfs.namenode.name.dir</name> <value>/D:/hadoop-2.7.7/namenode/namenode</value></property><property> <name>dfs.datanode.data.dir</name> <value>/D:/hadoop-2.7.7/datanode/datanode</value> </property>
</configuration>
配置core-site.xml:
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>fs.defaultFS</name><value>hdfs://BIGDATA:8020</value></property><property><name>hadoop.registry.zk.quorum</name><value>BIGDATA:2181</value></property>
</configuration>
2.初始化节点
cmd命令行执行如下命令初始化hadoop节点信息:
hadoop datanode -format
启动服务
命令行sbin目录下执行命令:start-hdfs.cmd
启动好后访问http://BIGDATA:50070
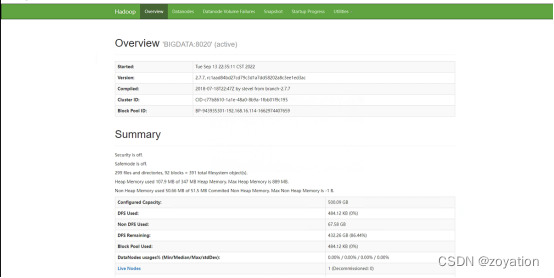
下载phoenix-5.0.0
phoenix支持以SQL的方式查询HBase数据库,后面会将对应jar包放到HBase的lib目录下,DBeaver数据库连接工具配置连接HBase也需要。
注意事项:需要下载和HBase对应的版本。
下载地址
官网:https://phoenix.apache.org/download.html

所有版本:http://archive.apache.org/dist/phoenix/
5.0.0版本:
http://archive.apache.org/dist/phoenix/apache-phoenix-5.0.0-HBase-2.0/bin/apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz
下载安装运行HBase2.0.0
下载和hadoop匹配的HBase版本。
下载HBase
所有版本:https://archive.apache.org/dist/HBase/
2.0.0版本:http://archive.apache.org/dist/HBase/2.0.0/HBase-2.0.0-bin.tar.gz
解压安装包
解压到D盘,比如:D:\hbase-2.0.0
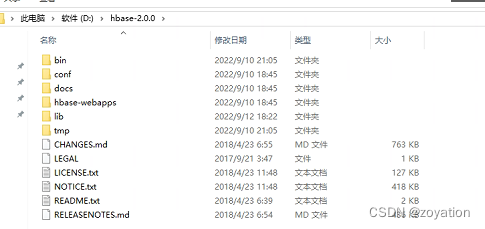
拷贝phoenix包里的连接jar包到hbase的lib下
拷贝phoenix-core-5.0.0-HBase-2.0.jar,phoenix-5.0.0-HBase-2.0-server.jar到hbase的lib目录
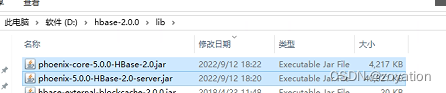
修改配置
修改HBase配置文件conf/hbase-env.cmd:
#设置java目录
set JAVA_HOME=E:\tools\java
#设置默认使用HBase自带的zookeeper
set HBase_MANAGES_ZK=true
修改HBase配置文件hbase-site.xml:
<configuration><property><name>hbase.rootdir</name><value>hdfs://BIGDATA:8020/hbase</value></property><property><name>hbase.cluster.distributed</name><value>false</value></property><property><name>phoenix.schema.isNamespaceMappingEnabled</name><value>true</value></property><property><name>phoenix.schema.mapSystemTablesToNamespace</name><value>true</value>
</property>
</configuration>
配置说明:
1.其中BIGDATA为hosts文件里配置的服务器名称
2.hbase.cluster.distributed:配置为非集群方式
3.如下参数设置启用schema方式存储和查询数据
phoenix.schema.isNamespaceMappingEnabled
phoenix.schema.mapSystemTablesToNamespace
运行HBase
确定hadoop启动好后,到hbase的bin目录执行start-hbase.cmd启动hbase
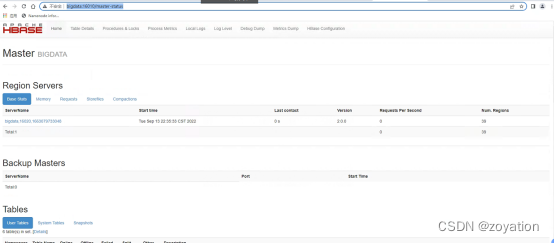
web界面:
http://bigdata:16010/master-status
下载安装DBeaver7.2.3、连接HBase
DBeaver数据库连接工具,通过phoenix连接HBase。
下载安装
所有版本:https://dbeaver.io/files/
下载7.2.3版本:https://dbeaver.io/files/7.2.3/dbeaver-ce-7.2.3-x86_64-setup.exe
双击安装
配置jdk
DBeaver通过phoenix连接HBase时需要配置之前安装的JDK1.8。
修改安装目录配置文件dbeaver.ini
最前面增加:
-vm
C:\\Program Files\\Java\\jdk1.8.0_271\\bin
设置phoenix驱动、连接HBase
1.设置好JDK后启动DBeaver,在工具栏“数据库-驱动管理器”里面编辑phoenix驱动如下图:
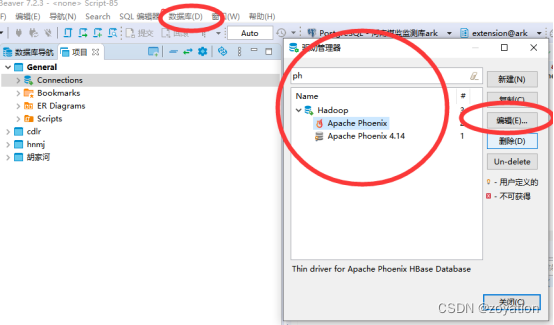
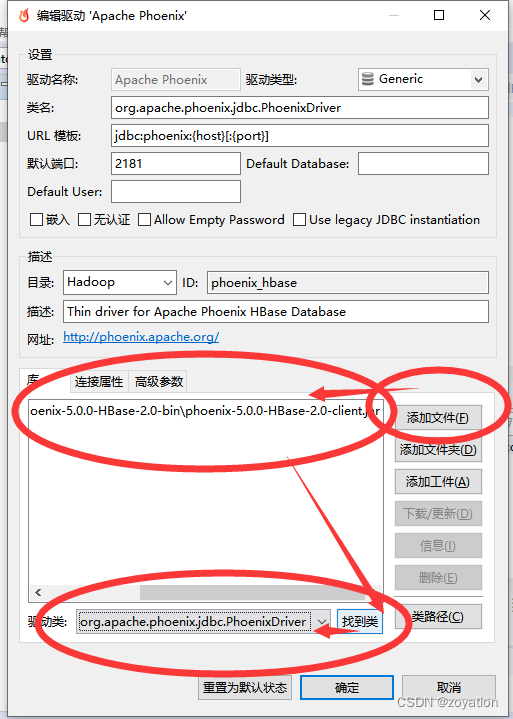
2.编辑窗口删除原来的驱动,通过添加文件方式指定前面下载的驱动包、找到驱动类、点击确定完成配置:
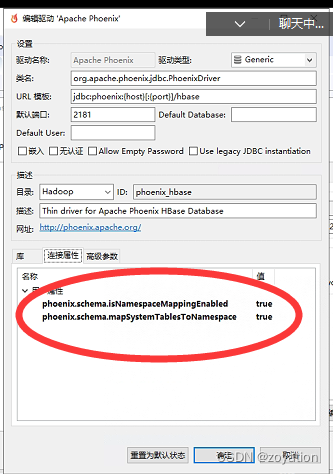
3.如果开启了schema,连接属性里启用schema,高级参数设置schema方式过滤数据:
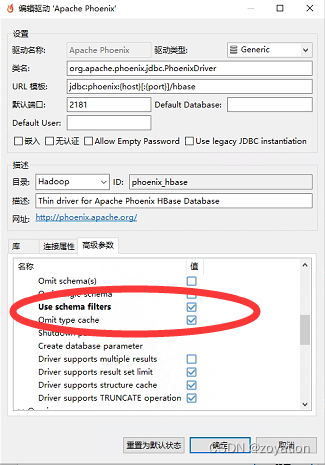
高级参数设置schema方式过滤数据勾选use schema filters:
4.添加连接,点击添加phoenix连接:
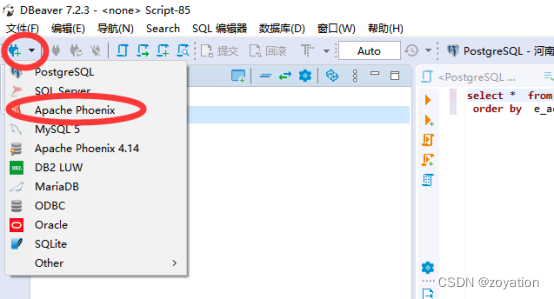
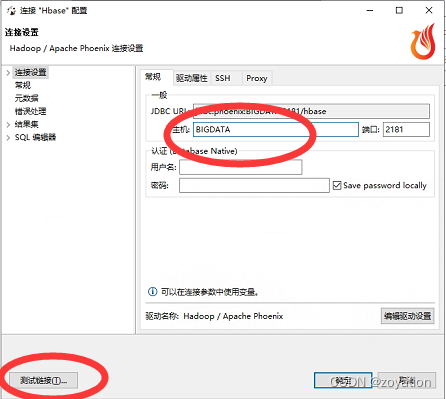
测试成功后,确定完成:
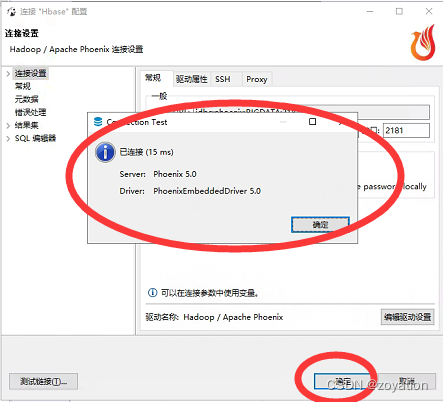
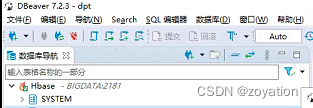
最后就可以再DBeaver里维护HBase数据表、查询HBase数据了:
总结
本文结合实际安装经验介绍了如何一步一步安装windows单机版本HBase,安装涉及软件和步骤比较多,需要注意版本匹配信息,需要按步骤安装配置,单机版HBase主要用于开发、测试用,正式环境一般需要用linux系统做集群,这样才能发挥HBase的海量数据储存和可动态扩展等能力。