文章目录
- 消息队列
- 应用场景
- rocketmq
- 为什么选择RocketMQ消息队列
- RocketMQ所拥有的功能
- rocketmq应用场景
- 应用解耦
- 流量削峰
- 数据分发
- 异步处理
- 日志处理
- 顺序消息
- 分布式事务消息(确保数据的最终一致性,大量引入 MQ 的分布式事务,既可以实现系统之间的解耦,又可以保证最终的数据一致性,减少系统间的交互)
- 项目结构组成
- 常见的MQ产品宏观对比
- RocketMQ优缺点
- rocketmq角色介绍
- Producer
- Consumer
- 消费模式
- Broker
- NameServer
- rocketmq 消费方式
- 一、集群消费
- 消息领域模型
- Message
- Topic
- Tag
- Group
- Queue
- Message Queue
- Offset
- 消息消费模式
- 一次完整的通信流程
- RocketMQ下载及安装
- RocketMQ目录结构
- RocketMQ启动及测试
- NameServer启动
- Broker启动
- 发送与接受消息测试(linux端)
- RocketMQ关闭(linux端)
- mqadmin管理工具
- 集群监控平台搭建
- RocketMQ架构设计
- 集群模式
- 各集群间关系
- Producer集群
- Consumer
- broker master宕机情况是否会丢消息
- 生产者发送消息的三种方式
- 可靠同步发送
- 可靠异步发送
- 单向(Oneway)发送
- msgId生成算法
- rocketmq之Java Class
- DefaultMQProducer类
- DefaultMQPushConsumer类
- Message类
- MessageExt类讲解
- 各个消息发送样例
- 如何保证消息不丢失?
- 负载均衡
- 消息的存储和发送
- 消息去重
- 消息的可用性
- RocketMQ 刷盘实现
- 顺序消息:
- 分布式事务:
- 消息过滤
- 回溯消费
- 消息堆积
- 大量消息堆积怎么处理?
- 定时消息
- Broker的Buffer问题
- 消息过期怎么处理?
- rocketmq-spring-boot-starter 用法简介
- rocketmqTemplate 延时消息
- RocketmqTemplate:发送事务消息
- springboot整合RocketMQ的各种消息类型,生产者,消费者
- 源码分析
消息队列
含义
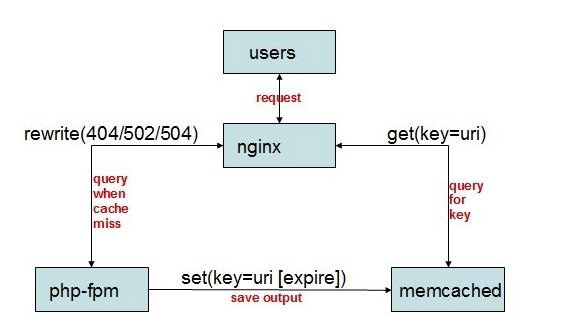
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题。实现高性能,
高可用,可伸缩和最终一致性架构。是大型分布式系统不可缺少的中间件。
目前在生产环境,使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ等。
分析
a.消息队列是一种"先进先出"的数据结构
b.不使用队列的情况下,生产者与消费者之间是通过RPC交互的
应用场景
示例图
a. 电商系统
(1)应用将主干逻辑处理完成后,写入消息队列。消息发送是否成功可以开启消息的确认模式。(消息队列返回消息接收成功状态后,应用再返回,这样保障消息的完整性)
(2)扩展流程(发短信,配送处理)订阅队列消息。采用推或拉的方式获取消息并处理。
(3)消息将应用解耦的同时,带来了数据一致性问题,可以采用最终一致性方式解决。比如主数据写入数据库,扩展应用根据消息队列,并结合数据库方式实现基于消息队列的后续处理。
b. 日志收集系统
1.Zookeeper注册中心,提出负载均衡和地址查找服务;
2.日志收集客户端,用于采集应用系统的日志,并将数据推送到kafka队列;
3.Kafka集群:接收,路由,存储,转发等消息处理;
rocketmq
RocketMQ是一个纯Java、分布式、队列模型的开源消息中间件,前身是MetaQ,是阿里参考Kafka特点研发的一个队列模型的消息中间件,后开源给apache基金会成为了apache的顶级开源项目,具有高性能、高可靠、高实时、分布式特点。
官方说明:
随着使用越来越多的队列和虚拟主题,ActiveMQ IO模块遇到了瓶颈。我们尽力通过节流,断路器或降级来解决此问题,但效果不佳。因此,我们那时开始关注流行的消息传递解决方案Kafka。不幸的是,Kafka不能满足我们的要求,特别是在低延迟和高可靠性方面。
看到这里可以很清楚的知道RcoketMQ 是一款低延迟、高可靠、可伸缩、易于使用的消息中间件。
具有以下特性:
支持发布/订阅(Pub/Sub)和点对点(P2P)消息模型
能够保证严格的消息顺序,在一个队列中可靠的先进先出(FIFO)和严格的顺序传递
提供丰富的消息拉取模式,支持拉(pull)和推(push)两种消息模式
单一队列百万消息的堆积能力,亿级消息堆积能力
支持多种消息协议,如 JMS、MQTT 等
分布式高可用的部署架构,满足至少一次消息传递语义
为什么选择RocketMQ消息队列
- 首先RocketMQ是阿里巴巴自研出来的,也已开源。其性能和稳定性从双11就能看出来,借用阿里的一句官方介绍:历年双 11 购物狂欢节零点千万级 TPS、万亿级数据洪峰,创造了全球最大的业务消息并发以及流转纪录(日志类消息除外);
- 在始终保证高性能前提下,支持亿级消息堆积,不影响集群的正常服务,在削峰填谷(蓄洪)、微服务解耦的场景下尤为重要;这,就能说明RocketMQ的强大。
RocketMQ天生为金融互联网领域而生,追求高可靠、高可用、高并发、低延迟,是一个阿里巴巴由内而外成功孕育的典范,除了阿里集团上千个应用外,根据我们不完全统计,国内至少有上百家单位、科研教育机构在使用。
RocketMQ在阿里集团也被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
RocketMQ所拥有的功能
发布/订阅消息传递模型
财务级交易消息
各种跨语言客户端,例如Java,C / C ++,Python,Go
可插拔的传输协议,例如TCP,SSL,AIO
内置的消息跟踪功能,还支持开放式跟踪
多功能的大数据和流生态系统集成
按时间或偏移量追溯消息
可靠的FIFO和严格的有序消息传递在同一队列中
高效的推拉消费模型
单个队列中的百万级消息累积容量
多种消息传递协议,例如JMS和OpenMessaging
灵活的分布式横向扩展部署架构
快如闪电的批量消息交换系统
各种消息过滤器机制,例如SQL和Tag
用于隔离测试和云隔离群集的Docker映像
功能丰富的管理仪表板,用于配置,指标和监视
认证与授权
rocketmq应用场景
应用解耦
问题描述
系统的耦合性越高,容错性就越低,以电商应用为例,用户创建订单后,
如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障
或者因为升级等原因暂时不可用,都会造成下单操作异常
解耦含义
使用消息队列解耦,系统的耦合性就会下降了,比如物流系统发生故障,
需要几分钟才能修复,在这段时间内,物流系统要处理的数据被缓存到消
息队列中,用户的下单操作正常完成。当物流系统恢复后,补充处理存在
消息队列中的订单消息即可,终端系统感知不到物流系统发生过几分钟故
障
场景
用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口
那么会存在以下缺点
1.假如库存系统无法访问,则订单减库存将失败,从而导致订单失败
2.订单系统与库存系统耦合
解决方案
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户下单成功
库存系统:订单下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行
库存操作
假如:在下单时库存系统不能正常使用,也不影响正常下单,因为下单后,订单系统写入消息
队列就不再关心其他的后续操作了。实现了订单系统与库存系统的应用解耦
流量削峰
问题描述
应用系统如果遇到系统请求流量的瞬间猛增,有可能将系统压垮,有了消
息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以大
大提高系统的稳定性
削峰含义
一般情况,为了保证系统的稳定性,如果系统负载超过阈值,就会阻止用
户请求,而如果使用消息队列将请求缓存起来,等待系统处理完毕后通知
用户下单完毕,这方法虽然会耗时,但出现系统不能下单的情况
场景描述
- 秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为了解决这个问题,一般需要
在应用前端加入消息队列。这样做的好处有
1.可以控制活动的人数
2.可以缓解短时间内高流量压垮应用
3.用户请求,服务器接收后,首先写入消息队列,假如消息队列长度超过最大数量,则直接
抛弃用户请求或跳转到错误页面
4.秒杀业务根据消息队列中的请求信息,再做后续处理
- 有一个点赞业务,不限制用户的点赞数只需进行记录,当每个用户都进行x连击享受数量猛增的快感时如果数据库都需要进行x个点赞数据的插入,数据库毫无疑问会塞死导致崩溃。
于是想到可以尝试下MQ削峰,比如每秒来了5000消息但数据库只能承受2000,那我消费时每次只拉取消费1600就好了,剩下的放在Broker堆积慢慢消费就好。由于之前的消息中心也在用RocketMQ,于是确认使用RocketMQ来进行削峰。
数据分发
数据分发含义
通过消息队列可以让数据在多个系统之间更加方便流通。只需要将数据发
送到消息队列,数据使用方直接在消息队列中获取数据即可
图解
A系统产生数据,发送到MQ
BCD哪个系统需要,自己去MQ消费即可
如果某个系统不需要数据,取消对MQ消息的消费即可
新系统要数据,直接从MQ消费即可
异步处理
场景描述
用户注册后,需要发注册邮件和注册短信。传统的做法有两种
1.串行方式 2. 并行方式
串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信,以上三个任务
完成后,返回给客户端
并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个
任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间
探究
假设三个业务节点每个使用50毫秒,不考虑网络等其他开销,则串行方式的时间是150毫秒
,并行的时间可能是100毫秒
因为cpu在单位时间内处理的请求数是一定的,假设cpu1秒吞吐量是100次,则串行方式1
秒内cpu可处理的请求量是7次(1000/150),并行方式处理的请求量是10次(1000/100)。
小结
根据如上案例,传统的方式系统的性能,如并发量、吞吐量、响应量等会有瓶颈
解决(使用消息队列)
按照以上约定,用户的响应时间相当于是注册消息写入数据库时间,也就是50毫秒。
注册邮件,发送短信写入消息队列后,直接返回,因为写入消息队列的速度很快
基本可以忽略,因此用户响应时间可能是50毫秒。因此架构改变后,系统的吞吐量
提高到每秒20 QPS,比串行提高了3倍,比并行提高了2倍
日志处理
含义
日志处理是指将消息队列用在日志处理中,比如kafka的应用,解决大量日志传输的问题,
架构简化如下
日志采集客户端,负责日志数据采集,定时写入kafka队列
kafka消息队列,负责日志数据的接收,存储和转发
日志处理,订阅并消费kafka队列中的日志数据
顺序消息
顺序消息即保证消息的先进先出,比如证券交易过程时间优先原则,交易系统中的订单创建、支付、退款等流程,航班中的旅客登机消息处理等
分布式事务消息(确保数据的最终一致性,大量引入 MQ 的分布式事务,既可以实现系统之间的解耦,又可以保证最终的数据一致性,减少系统间的交互)
项目结构组成

核心模块:
rocketmq-broker:接受生产者发来的消息并存储(通过调用rocketmq-store),消费者从这里取得消息
rocketmq-client:提供发送、接受消息的客户端API。
rocketmq-namesrv:NameServer,类似于Zookeeper,这里保存着消息的TopicName,队列等运行时的元信息。
rocketmq-common:通用的一些类,方法,数据结构等。
rocketmq-remoting:基于Netty4的client/server + fastjson序列化 + 自定义二进制协议。
rocketmq-store:消息、索引存储等。
rocketmq-filtersrv:消息过滤器Server,需要注意的是,要实现这种过滤,需要上传代码到MQ!(一般而言,我们利用Tag足以满足大部分的过滤需求,如果更灵活更复杂的过滤需求,可以考虑filtersrv组件)。
rocketmq-tools:命令行工具。
他主要有四大核心组成部分:NameServer、Broker、Producer以及Consumer四部分。
RocketMQ啥都是集群部署的,这是他吞吐量大,高可用的原因之一,集群的模式也很花哨,可以支持多master 模式、多master多slave异步复制模式、多 master多slave同步双写模式。
常见的MQ产品宏观对比
| 产品 | 开发语言 | 单机吞吐量 | 时效性 | 可用性 | 特性 |
|---|---|---|---|---|---|
| ActiveMQ | java | 万级 | ms级 | 高(主从架构) | ActiveMQ 成熟的产品,在很多公司得到应用;有较多的文档;各种协议支持较好 |
| RabbitMQ | erlang | 万级 | us级 | 高(主从架构) | RabbitMQ 基于erlang开发,所以并发能力强,性能极其好,延时很低,管理界面较丰富 |
| RocketMQ | java | 10万级 | ms级 | 非常高(分布式架构) | RocketMQ MQ功能比较完备,扩展性佳 |
| Kafka | scala | 10万级 | ms级以内 | 非常高(分布式架构) | Kafka 只支持主要的MQ功能,像一些消息查询,消息回溯等功能没有提供,毕竟是为大数据准备的,在大数据领域应用广 |

ActiveMQ,早期使用的比较多,没经过大规模吞吐量场景的验证,社区也不是很活跃,但是现在确实大家用的不多了,不推荐.
RabbitMQ,开发语言erlang阻止了大量的Java工程师去深入研究和掌控它,对公司而言,几乎处于不可控的状态,但是RabbitMQ是开源的,有比较稳定的支持,社区活跃度也高,如不考虑二次开发,追求性能和稳定性,推荐使用.
RocketMQ,开发语言是Java,在阿里内部经受过高并发业务的考验,稳定性和性能均不错,考虑后期可能二次开发,推荐使用.
kafka,大数据领域的实时计算,日志采集等场景,用kafka是业内标准的,社区活跃度很高,推荐使用.大数据领域日志采集等业务推荐使用.
拿吞吐量来说,早期比较活跃的ActiveMQ 和RabbitMQ基本上不是后两者的对手了,在现在这样大数据的年代吞吐量是真的很重要。
就部署方式而言前两者也是大不如后面两个天然分布式架构
RocketMQ优缺点
RocketMQ起到解耦、削峰、数据分发的作用,同时也存在着系统可用性降低、系统复杂度提高、一致性问题 这三个方面缺点。
系统可用性降低 : 系统引入的外部依赖越多,系统稳定性越差。一旦MQ宕机,就会对业务造成影响.
系统复杂度提高 : MQ的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过MQ进行异步调用。如何保证
消息没有被重复消费、怎么处理消息丢失情况、如何保证消息传递的顺序性。
一致性问题 : A系统处理完业务,通过MQ给B、C、D三个系统发消息数据,如果B系统、C系统处理完成、D处理失败、如何保证消
息数据处理的一致性。
rocketmq角色介绍
Producer
消息生产者,负责产生消息,一般由业务系统负责产生消息。
失败默认重试2次;sync/async;ProducerGroup,在事务消息机制中,如果发送消息的producer在还未commit/rollback前挂掉了,broker会在一段时间后回查ProducerGroup里的其他实例,确认消息应该commit/rollback
Producer由用户进行分布式部署,消息由Producer通过多种负载均衡模式发送到Broker集群,发送低延时,支持快速失败。
RocketMQ 提供了三种方式发送消息:同步、异步和单向
同步发送:同步发送指消息发送方发出数据后会在收到接收方发回响应之后才发下一个数据包。一般用于重要通知消息,例如重要通知邮件、营销短信。
异步发送:异步发送指发送方发出数据后,不等接收方发回响应,接着发送下个数据包,一般用于可能链路耗时较长而对响应时间敏感的业务场景,例如用户视频上传后通知启动转码服务。
单向发送:单向发送是指只负责发送消息而不等待服务器回应且没有回调函数触发,适用于某些耗时非常短但对可靠性要求并不高的场景,例如日志收集。
含义
消息生产者,负责创建消息发送给Broker,一般由业务系统负责产生消息
RocketMQ默认提供了DefaultMQProducer、TransactionMQProducer用于发送消息。
内含
a.Producer Group:
是一组Producer的名称。通常来说一个业务系统可能会奉陪一个Producer Group。
Producer Group后续可以用于消息发送相关的各项管理监控功能。
b.Message:
RocketMQ中的消息。Message必须设置Topic以及消息体,除此之外还可以配
置一些自定义属性。只要不超过预定义的消息大小,自定义属性可以任意添加。
c.Message Model:
消息投递存在两种不同类别,
d.Tag:
Message可以设置Tag,Tag是系统预定义的属性。Message设置了Tag之后,在消费的时候
可以根据Tag进行过滤。RocketMQ提供了几种过滤方式。可以认为Tag是Message的二级类别
核心参数
producerGroup:组名唯一
createTopicKey:创建主题时需要的密钥
defaultTopicQueueNums:在发送消息时,自动创建服务器不存在的 topic,默认创建的队列数,默认4
sendMsgTimeout:发送消息超时时间
compressMsgBodyOverHowmuch:消息压缩字节,默认4096字节,超过该值,rocketmq就会对消息进行压缩
retryTimesWhenSendFailed:重发策略,同理存在异步的(retryTimesWhenSendAsyncFailed)
retryAnotherBrokerWhenNotStoreOk:默认false
maxMessagerSize:消息最大容量,默认128k
Consumer
消息消费者,负责消费消息,一般是后台系统负责异步消费。
Consumer也由用户部署,支持PUSH和PULL两种消费模式,支持集群消费和广播消息,提供实时的消息订阅机制。
Pull:拉取型消费者(Pull Consumer)主动从消息服务器拉取信息,只要批量拉取到消息,用户应用就会启动消费过程,所以 Pull 称为主动消费型。
Push:推送型消费者(Push Consumer)封装了消息的拉取、消费进度和其他的内部维护工作,将消息到达时执行的回调接口留给用户应用程序来实现。所以 Push 称为被动消费类型,但从实现上看还是从消息服务器中拉取消息,不同于 Pull 的是 Push 首先要注册消费监听器,当监听器处触发后才开始消费消息。
DefaultPushConsumer/DefaultPullConsumer,push也是用pull实现的,采用的是长轮询方式;CLUSTERING模式下,一条消息只会被ConsumerGroup里的一个实例消费,但可以被多个不同的ConsumerGroup消费,BROADCASTING模式下,一条消息会被ConsumerGroup里的所有实例消费。
DefaultPushConsumer: Broker收到新消息请求后,如果队列里没有新消息,并不急于返回,通过一个循环不断查看状态,每次waitForRunning一段时间(5s),然后在check。当一直没有新消息,第三次check时,等待时间超过suspendMaxTimeMills(15s),就返回空结果。在等待的过程中,Broker收到了新的消息后会直接调用notifyMessageArriving返回请求结果。“长轮询”的核心是,Broker端Hold住(挂起)客户端客户端过来的请求一小段时间,在这个时间内有新消息到达,就利用现有的连接立刻返回消息给Consumer。“长轮询”的主动权还是掌握在Consumer手中,Broker即使有大量消息积压,也不会主动推送给Consumer。长轮询方式的局限性,是在Hold住Consumer请求的时候需要占用资源,它适合用在消息队列这种客户端连接数可控的场景中。
DefaultPullConsumer: 需要用户自己处理遍历MessageQueue、保存Offset,所以PullConsumer有更多的自主性和灵活性。
对于集群模式的非顺序消息,消费失败默认重试16次,延迟等级为3~18。(messageDelayLevel = “1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h”)
MQClientInstance是客户端各种类型的Consumer和Producer的底层类,由它与NameServer和Broker打交道。如果创建Consumer或Producer 类型的时候不手动指定instanceName,进程中只会有一个MQClientInstance对象,即当一个Java程序需要连接多个MQ集群时,必须手动指定不同的instanceName。需要一提的是,当消费者(不同jvm实例)都在同一台物理机上时,若指定instanceName,消费负载均衡将失效(每个实例都将消费所有消息)。另外,在一个jvm里模拟集群消费时,必须指定不同的instanceName,否则启动时会提示ConsumerGroup已存在。
消费模式
- 集群模式:
RocketMQ默认采用集群消费模式
同一ComsumerGroup中的消费者只消费一次
- 广播模式:
广播模式下,每个Consumer都会对消息进行消费
含义
消息消费者,用于从消息队列获取消息。常用的Consumer类
内含
a.DefaultMQPushConsumer,
收到消息自动调用传入的处理方法来处理,实时性高。
b.DefaultMQPullConsumer
用户自主控制,灵活度更高。
c.Push Consumer:
服务端向消费端推送消息
d.Pull Consumer:
消费端向服务端定时拉取消息
e.Consumer Group :
是一组Consumer的名称.相同Group下的Consumer需要有同样的订阅关系,且消费逻辑一致
否则消息投递的时候可能会出现一些难以排查的问题。
Consumer Group同样用于分配给不同的业务系统。通过管理工具可以控制Group的消费范围
Broker
消息中转角色,负责存储消息,转发消息。
Broker是具体提供业务的服务器,单个Broker节点与所有的NameServer节点保持长连接及心跳,并会定时将Topic信息注册到NameServer,顺带一提底层的通信和连接都是基于Netty实现的。
Broker负责消息存储,以Topic为纬度支持轻量级的队列,单机可以支撑上万队列规模,支持消息推拉模型。
官网上有数据显示:具有上亿级消息堆积能力,同时可严格保证消息的有序性。
Broker在RocketMQ中是进行处理Producer发送消息请求,Consumer消费消息的请求,并且进行消息的持久化,以及HA策略和服务端过滤,就是集群中很重的工作都是交给了Broker进行处理。
Broker模块是通过BrokerStartup进行启动的,会实例化BrokerController,并且调用其初始化方法
他的初始化流程很冗长,会根据配置创建很多线程池主要用来发送消息、拉取消息、查询消息、客户端管理和消费者管理,也有很多定时任务,同时也注册了很多请求处理器,用来发送拉取消息查询消息的。
每个主题可设置队列个数,自动创建主题时默认4个,需要顺序消费的消息发往同一队列,比如同一订单号相关的几条需要顺序消费的消息发往同一队列, 顺序消费的特点的是,不会有两个消费者共同消费任一队列,且当消费者数量小于队列数时,消费者会消费多个队列。至于消息重复,在消 费端处理。RocketMQ 4.3+支持事务消息,可用于分布式事务场景(最终一致性)。
关于queueNums:
客户端自动创建,Math.min算法决定最多只会创建8个(BrokerConfig)队列,若要超过8个,可通过控制台创建/修改,Topic配置保存在store/config/topics.json
消费负载均衡的最小粒度是队列,Consumer的数量应不大于队列数
读写队列数(writeQueueNums/readQueueNums)是RocketMQ特有的概念,可通过console修改。当readQueueNums不等于writeQueueNums时,会有什么影响呢?
topicRouteData = this.mQClientAPIImpl.getDefaultTopicRouteInfoFromNameServer(defaultMQProducer.getCreateTopicKey(), 1000 * 3);
if (topicRouteData != null) {
for (QueueData data : topicRouteData.getQueueDatas()) {
int queueNums = Math.min(defaultMQProducer.getDefaultTopicQueueNums(), data.getReadQueueNums());
data.setReadQueueNums(queueNums);
data.setWriteQueueNums(queueNums);
}
}
Broker上存Topic信息,Topic由多个队列组成,队列会平均分散在多个Broker上。Producer的发送机制保证消息尽量平均分布到 所有队列中,最终效果就是所有消息都平均落在每个Broker上。
RocketMQ的消息的存储是由ConsumeQueue和CommitLog配合来完成的,ConsumeQueue中只存储很少的数据,消息主体都是通过CommitLog来进行读写。 如果某个消息只在CommitLog中有数据,而ConsumeQueue中没有,则消费者无法消费,RocketMQ的事务消息实现就利用了这一点。
CommitLog:是消息主体以及元数据的存储主体,对CommitLog建立一个ConsumeQueue,每个ConsumeQueue对应一个(概念模型中的)MessageQueue,所以只要有 CommitLog在,ConsumeQueue即使数据丢失,仍然可以恢复出来。
ConsumeQueue:是一个消息的逻辑队列,存储了这个Queue在CommitLog中的起始offset,log大小和MessageTag的hashCode。每个Topic下的每个Queue都有一个对应的 ConsumeQueue文件,例如Topic中有三个队列,每个队列中的消息索引都会有一个编号,编号从0开始,往上递增。并由此一个位点offset的概念,有了这个概念,就可以对 Consumer端的消费情况进行队列定义。
RocketMQ的高性能在于顺序写盘(CommitLog)、零拷贝和跳跃读(尽量命中PageCache),高可靠性在于刷盘和Master/Slave,另外NameServer 全部挂掉不影响已经运行的Broker,Producer,Consumer。
发送消息负载均衡,且发送消息线程安全(可满足多个实例死循环发消息),集群消费模式下消费者端负载均衡,这些特性加上上述的高性能读写, 共同造就了RocketMQ的高并发读写能力。
刷盘和主从同步均为异步(默认)时,broker进程挂掉(例如重启),消息依然不会丢失,因为broker shutdown时会执行persist。 当物理机器宕机时,才有消息丢失的风险。另外,master挂掉后,消费者从slave消费消息,但slave不能写消息。
RocketMQ具有很好动态伸缩能力(非顺序消息),伸缩性体现在Topic和Broker两个维度。
Topic维度:假如一个Topic的消息量特别大,但集群水位压力还是很低,就可以扩大该Topic的队列数,Topic的队列数跟发送、消费速度成正比。
Broker维度:如果集群水位很高了,需要扩容,直接加机器部署Broker就可以。Broker起来后向Namesrv注册,Producer、Consumer通过Namesrv 发现新Broker,立即跟该Broker直连,收发消息。
Broker配置项
| 配置项 | 名称 | 备注 |
|---|---|---|
| brokerClusterName | 所属集群名字 | 默认值DefaultCluster |
| brokerName | broker 名字 | 不同的主节点应配置不同的名称 |
| brokerId | broker Id | 0 表示 Master,>0 表示 Slave |
| namesrvAddr | namesrvAddr地址 | 多个地址用分号分隔 |
| defaultTopicQueueNums | 默认主题队列数,默认4 | 在发送消息时,自动创建服务器不存在的 topic,默认创建的队列数 |
| autoCreateTopicEnable | 自动创建主题状态,默认false | 是否允许 Broker 自动创建 Topic,建议线下开启,线上关闭 |
| autoCreateSubscriptionGroup | 自动创建订阅组状态,默认false | 是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭 |
| listenPort | 监听端口 | Broker 对外服务的监听端口 |
| deleteWhen | 删除文件时间点,默认凌晨 4 点(04) | 与清理机制有关 |
| fileReservedTime | 文件保留时间,默认48小时 | 与清理机制有关 |
| mapedFileSizeCommitLog | commitLog 每个文件的大小默认 1G | 文件超过该值后,会新建一个文件 |
| mapedFileSizeConsumeQueue | ConsumeQueue 每个文件存储个数,默认存 30W 条 | |
| destroyMapedFileIntervalForcibly | 文件拒绝删除后存活的最大时间,毫秒 | 第一次拒绝删除之后能保留的最大时间 |
| deletePhysicFilesInterval | 删除物理文件间隔,毫秒 | 因为在一次清除过程中,可能需要删除的文件不止一个,该值指定两次删除文件的间隔时间。 |
| diskMaxUsedSpaceRatio | 检测物理文件磁盘空间,默认75 | |
| diskSpaceWarningLevelRatio | 磁盘空间警戒大小 | 磁盘空间警戒大小,超过,则停止接收新消息(出于保护自身目的)默认是90 |
| diskSpaceCleanForciblyRatio | 磁盘空间强制删除文件大小。默认是85 | |
| storePathRootDir | 文件存储路径 | |
| storePathCommitLog | commitLog 存储路径 | 存储消息 |
| storePathConsumeQueue | 消费队列存储路径存储路径 | |
| storePathIndex | 消息索引存储路径 | |
| storeCheckpoint | checkpoint 文件存储路径 | 异常恢复时根据checkpoint点来恢复消息 |
| abortFile | abort 文件存储路径 | 临时文件,主要记录是否正常关闭 |
| maxMessageSize | 消息最大大小 | |
| brokerRole | Broker 的角色 | ASYNC_MASTER 异步复制主节点 ;SYNC_MASTER 同步双写主节点; SLAVE 从节点 |
| flushDiskType | 刷盘方式 | ASYNC_FLUSH 异步刷盘;SYNC_FLUSH 同步刷盘 |
- 主从同步方式:
同步双写:Master节点收到消息后,同步消息到Slave节点,主备都写成功,再向返回成功
异步复制:Master节点收到消息后,先返回成功,再同步到Slave节点
- 刷盘方式:
同步刷盘:节点收到消息后,将数据持久化到硬盘后,再返回成功
异步刷盘:节点收到消息后,将消息存储在内存中,先返回成功,再持久化到硬盘中
官方提供的配置:
在rocketmq/conf目录下存在3个配置文件示例,分别为:
2m-2s-async 异步复制、异步刷盘
2m-2s-sync 同步双写,异步刷盘
2m-noslave 多主节点、异步刷盘
**推荐使用:**同步双写,异步刷盘
**最稳妥的方式:**同步双写、同步刷盘
含义
Broker是具体提供业务的服务器,
解释一:RocketMQ的核心逻辑是Broker。Broker是实际用于手法消息的功能单元。从RocketMQ
使用者的角度来看,生产者通过接口将消息投递到Broker,消费者从Broker获取消息进行消费。
RocketMQ提供了推拉结合的方式用于获取消息。
解释二:单个Broker节点与所有的NameServer节点保持长连接及心跳,
并会定时将Topic信息注册到NameServer,顺带一提底层的通信和连接都是基于Netty实现的。
Broker中分master和slave两种角色,每个master可以对应多个slave,
但一个slave只能对应一个master,master和slave通过指定相同的Brokername,
不同的BrokerId (master为0)成为一个组。
master和slave之间的同步方式分为同步双写和异步复制,
异步复制方式master和slave之间虽然会存在少量的延迟,
但性能较同步双写方式要高出10%左右
举例:邮局 。它是RocketMQ的核心,用于接收Producer发过来的
消息、以及处理Consumer的消费消息请求、消息的持久化存储、服务端过滤功能等
另外,Broker中还存在一些非常重要的名词需要说明:
内含
a.Topic:
区分消息的种类,一个发送者可以发送消息给一个或者多个Topic,一个消息的接受者可以
订阅一个或者多个Topic消息。对于RokectMQ而言,Topic只是一个逻辑上的概念,
真正的消息存储其实是在Topic中的Queue中。这要设计是为了消息的顺序消费,
b.Message Queue:
相当于是Topic的分区,用于并发发送和接受消息
NameServer
NameServer是一个功能齐全的服务器,其角色类似Dubbo中的Zookeeper,但NameServer与Zookeeper相比更轻量。主要是因为每个NameServer节点互相之间是独立的,没有任何信息交互。
NameServer压力不会太大,平时主要开销是在维持心跳和提供Topic-Broker的关系数据。
但有一点需要注意,Broker向NameServer发心跳时, 会带上当前自己所负责的所有Topic信息,如果Topic个数太多(万级别),会导致一次心跳中,就Topic的数据就几十M,网络情况差的话, 网络传输失败,心跳失败,导致NameServer误认为Broker心跳失败。
NameServer 被设计成几乎无状态的,可以横向扩展,节点之间相互之间无通信,通过部署多台机器来标记自己是一个伪集群。
每个 Broker 在启动的时候会到 NameServer 注册,Producer 在发送消息前会根据 Topic 到 NameServer 获取到 Broker 的路由信息,Consumer 也会定时获取 Topic 的路由信息。
所以从功能上看NameServer应该是和 ZooKeeper 差不多,据说 RocketMQ 的早期版本确实是使用的 ZooKeeper ,后来改为了自己实现的 NameServer 。
- NameServer可以部署多个,相互之间独立,其他角色同时向多个NameServer机器上报状态信息,从而达到热备份的目的。 NameServer本身是无状态的,也就是说NameServer中的Broker、Topic等状态信息不会持久存储,都是由各个角色定时上报并 存储到内存中的(NameServer支持配置参数的持久化,一般用不到)。
- 为何不用ZooKeeper?ZooKeeper的功能很强大,包括自动Master选举等,RocketMQ的架构设计决定了它不需要进行Master选举, 用不到这些复杂的功能,只需要一个轻量级的元数据服务器就足够了。值得注意的是,NameServer并没有提供类似Zookeeper的watcher机制, 而是采用了每30s心跳机制。
- 心跳机制
单个Broker跟所有Namesrv保持心跳请求,心跳间隔为30秒,心跳请求中包括当前Broker所有的Topic信息。Namesrv会反查Broer的心跳信息, 如果某个Broker在2分钟之内都没有心跳,则认为该Broker下线,调整Topic跟Broker的对应关系。但此时Namesrv不会主动通知Producer、Consumer有Broker宕机。
Consumer跟Broker是长连接,会每隔30秒发心跳信息到Broker。Broker端每10秒检查一次当前存活的Consumer,若发现某个Consumer 2分钟内没有心跳, 就断开与该Consumer的连接,并且向该消费组的其他实例发送通知,触发该消费者集群的负载均衡(rebalance)。
生产者每30秒从Namesrv获取Topic跟Broker的映射关系,更新到本地内存中。再跟Topic涉及的所有Broker建立长连接,每隔30秒发一次心跳。 在Broker端也会每10秒扫描一次当前注册的Producer,如果发现某个Producer超过2分钟都没有发心跳,则断开连接。
Namesrv压力不会太大,平时主要开销是在维持心跳和提供Topic-Broker的关系数据。但有一点需要注意,Broker向Namesrv发心跳时, 会带上当前自己所负责的所有Topic信息,如果Topic个数太多(万级别),会导致一次心跳中,就Topic的数据就几十M,网络情况差的话, 网络传输失败,心跳失败,导致Namesrv误认为Broker心跳失败。
NameServer配置项
| 配置项 | 名称 | 备注 |
|---|---|---|
| listenPort | 监昕端口,值默认9876 | |
| serverWorkerThreads | Netty 业务线程池线程个数,默认值为8 | |
| serverCallbackExecutorThreads | Netty public 任务线程池线程个数 | Netty网络设计,根据业务类型会创建不同的线程池,比如处理消息发送、消息消费、心跳检测等 |
| serverSelectorThreads | IO 线程池线程个数,默认为3,主要是 NameServer Broker 端解析请求、返回相应的线程个数 | 这类线程主要是处理网络请求的,解析请求包, 然后转发到各个业务线程池完成具体的业务操作,然后将结果再返回调用方 |
| serverOnewaySemaphoreValue | 单次消息最大并发度,默认256 | 消息请求并发度 |
| serverAsyncSemaphoreValue | 异步消息最大并发度,默认64 | |
| serverChannelMaxIdleTimeSeconds | 网络最大空闲时间,默认120秒 |
含义
解释一:RocketMQ没有引入第三方服务依赖,消息队列内部的服务发现以及配置更新等,都
借由Name Server来完成。从功能上来说,Name Server相当于一个轻量级简化版
的Zookeeper,或者说提供了类似ZK的功能。
Name Server的定位是维护RocketMQ全局相关配置,提供消息路由信息,除此之外
并不包含过多复杂逻辑。因为其相对轻量级,一般一组Name Server集群可以服务多
组Broker集群。
Name Server Cluster是多个Name Server实例的统称,Name Server之间并无关
联,互相也不同步信息。多个Name Server的存在是为了提供高可用服务,不同实例之
间的数据信息同步则实际是在数据写入的时候保证的。一份配置或消息路由信息会写入
所有Name Server实例中。
解释二:相当于配置中心,维护Broker集群、Broker信息、Broker存活信息、主题与
队列信息等。NameServer彼此之间不通信,每个Broker与集群内所有NameServer
保持长连接
通信机制
1.Broker启动后需要完成一次将自己注册到NameServer的操作;随后每隔30秒时间定时向
NameServer更新Topic路由信息
2.Producer发送消息时,需要根据消息的Topic从本地缓存的获取路由信息。如果没有则
更新路由信息,会从NameServer重新拉取,同时Producer会默认每隔30秒向NameServer
拉取一次路由信息
3.Consumer消费消息时,从NameServer获取的路由信息,并再完成客户端的负载均衡后,监听
指定消息队列获取消息并进行消费
rocketmq 消费方式
一、集群消费
RocketMQ-集群消费
其实,对于RocketMQ而言,通过ConsumeGroup的机制,实现了天然的消息负载均衡!通俗点来说,RocketMQ中的消息通过ConsumeGroup实现了将消息分发到C1/C2/C3/…的机制,这意味着我们将非常方便的通过加机器来实现水平扩展!
我们考虑一下这种情况:比如C2发生了重启,一条消息发往C3进行消费,但是这条消息的处理需要0.1S,而此时C2刚好完成重启,那么C2是否可能会收到这条消息呢?答案是肯定的,也就是consume broker的重启,或者水平扩容,或者不遵守先订阅后生产消息,都可能导致消息的重复消费!
至于消息分发到C1/C2/C3,其实也是可以设置策略的:

默认的分配算法是AllocateMessageQueueAveragely
还有另外一种平均的算法是AllocateMessageQueueAveragelyByCircle,也是平均分摊每一条queue,只是以环状轮流分queue的形式
使用哪种策略,只需要实例化对应的对象即可,如:
AllocateMessageQueueStrategy aqs = newAllocateMessageQueueAveragelyByCircle();
consumer.setAllocateMessageQueueStrategy(aqs);
二、广播消费
广播消费,类似于ActiveMQ中的发布订阅模式,消息会发给Consume Group中的每一个消费者进行消费。
RocketMQ-广播消费模式设置
/*** Consumer,订阅消息*/
public classConsumer2 {public static void main(String[] args) throwsInterruptedException, MQClientException {
DefaultMQPushConsumer consumer= new DefaultMQPushConsumer(“group_name”);
consumer.setNamesrvAddr(“192.168.2.222:9876;192.168.2.223:9876”);
consumer.setConsumeMessageBatchMaxSize(10);//设置为广播消费模式
consumer.setMessageModel(MessageModel.BROADCASTING);
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
consumer.subscribe(“TopicTest”, “*”);
consumer.registerMessageListener(newMessageListenerConcurrently() {public ConsumeConcurrentlyStatus consumeMessage(Listmsgs, ConsumeConcurrentlyContext context) {try{for(MessageExt msg : msgs) {undefined
System.out.println(" Receive New Messages: " +msg);
}
}catch(Exception e) {
e.printStackTrace();return ConsumeConcurrentlyStatus.RECONSUME_LATER; //重试
}return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //成功
}
});
consumer.start();
System.out.println(“Consumer Started.”);
}
}
消息领域模型
Message
Message(消息)就是要传输的信息。
一条消息必须有一个主题(Topic),主题可以看做是你的信件要邮寄的地址。
一条消息也可以拥有一个可选的标签(Tag)和额处的键值对,它们可以用于设置一个业务 Key 并在 Broker 上查找此消息以便在开发期间查找问题。
Topic
Topic(主题)可以看做消息的规类,它是消息的第一级类型。比如一个电商系统可以分为:交易消息、物流消息等,一条消息必须有一个 Topic 。
Topic 与生产者和消费者的关系非常松散,一个 Topic 可以有0个、1个、多个生产者向其发送消息,一个生产者也可以同时向不同的 Topic 发送消息。
一个 Topic 也可以被 0个、1个、多个消费者订阅。
Tag
Tag(标签)可以看作子主题,它是消息的第二级类型,用于为用户提供额外的灵活性。使用标签,同一业务模块不同目的的消息就可以用相同 Topic 而不同的 Tag 来标识。比如交易消息又可以分为:交易创建消息、交易完成消息等,一条消息可以没有 Tag 。
标签有助于保持您的代码干净和连贯,并且还可以为 RocketMQ 提供的查询系统提供帮助。
Group
分组,一个组可以订阅多个Topic。
分为ProducerGroup,ConsumerGroup,代表某一类的生产者和消费者,一般来说同一个服务可以作为Group,同一个Group一般来说发送和消费的消息都是一样的
Queue
在Kafka中叫Partition,每个Queue内部是有序的,在RocketMQ中分为读和写两种队列,一般来说读写队列数量一致,如果不一致就会出现很多问题。
Message Queue
Message Queue(消息队列),主题被划分为一个或多个子主题,即消息队列。
一个 Topic 下可以设置多个消息队列,发送消息时执行该消息的 Topic ,RocketMQ 会轮询该 Topic 下的所有队列将消息发出去。
消息的物理管理单位。一个Topic下可以有多个Queue,Queue的引入使得消息的存储可以分布式集群化,具有了水平扩展能力。
Offset
在RocketMQ 中,所有消息队列都是持久化,长度无限的数据结构,所谓长度无限是指队列中的每个存储单元都是定长,访问其中的存储单元使用Offset 来访问,Offset 为 java long 类型,64 位,理论上在 100年内不会溢出,所以认为是长度无限。
也可以认为 Message Queue 是一个长度无限的数组,Offset 就是下标。
消息消费模式
消息消费模式有两种:Clustering(集群消费)和Broadcasting(广播消费)。
默认情况下就是集群消费,该模式下一个消费者集群共同消费一个主题的多个队列,一个队列只会被一个消费者消费,如果某个消费者挂掉,分组内其它消费者会接替挂掉的消费者继续消费。
而广播消费消息会发给消费者组中的每一个消费者进行消费。
Message Order
Message Order(消息顺序)有两种:Orderly(顺序消费)和Concurrently(并行消费)。
顺序消费表示消息消费的顺序同生产者为每个消息队列发送的顺序一致,所以如果正在处理全局顺序是强制性的场景,需要确保使用的主题只有一个消息队列。
并行消费不再保证消息顺序,消费的最大并行数量受每个消费者客户端指定的线程池限制。
一次完整的通信流程
Producer 与 NameServer集群中的其中一个节点(随机选择)建立长连接,定期从 NameServer 获取 Topic 路由信息,并向提供 Topic 服务的 Broker Master 建立长连接,且定时向 Broker 发送心跳。
Producer 只能将消息发送到 Broker master,但是 Consumer 则不一样,它同时和提供 Topic 服务的 Master 和 Slave建立长连接,既可以从 Broker Master 订阅消息,也可以从 Broker Slave 订阅消息。
1.生产者发消息是给Broker发.
2.Broker 是接收真正数据的服务器.
3.Name Server 是管理Broker的服务器.
生产者发送消息首先回去找 Name Server 要一个可用的Broker 地址.
生产者会去给 Broker 发送消息,消费者监听到就会去消费.
RocketMQ下载及安装
下载地址:http://rocketmq.apache.org/
安装选择:二进制包安装方式(含有bin的安装包)
安装环境:unzip 安装包名
安装环境:linux64位系统、JDK1.8(64位)、源码安装需要安装maven3.2x
RocketMQ目录结构
bin 启动脚本,包括shell脚本和cmd脚本
conf 实例配置文件,包括broker配置文件、logback配置文件等
lib 依赖jar包,包括netty、commons-lang、FastJSON等
RocketMQ启动及测试
内存修改
Rocketmq默认的虚拟机内存较大,启动broker如果因为内存不足失败,需要编辑如下两个配置文件,去修改JVM内存大小vi runbroker.sh
vi runserver.sh#编辑runbroker.sh和runserver.sh修改默认JVM大小
#参考设置
JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn128m -xx:MetaspaceSize=128m xx:MaxMetaspaceSize=320m"
端口
开启端口:10911 10912 10909 9876
启动位置
bin目录
NameServer启动
位置
RocketMQ目录下的bin目录
本地部署(linux)
nohup sh mqnamesrv & 启动NameServer
tail -f ~/logs/rocketmqlogs/namesrv.log 查看日志
外网部署
nohup sh mqnamesrv -n "192.168.33.100:9876" & 启动NameServer
tail -f ~/logs/rocketmqlogs/namesrv.log 查看日志
Broker启动
位置
RocketMQ目录下的bin目录
本地部署(linux)
nohup sh mqbroker -n localhost:9876 & 启动Broker
tail -f ~/logs/rocketmqlogs/broker.log 查看启动日志
外网部署
echo 'brokerIP1=192.168.33.100' > ../conf/broker.properties
nohup sh mqbroker -n localhost:9876 -c ../conf/broker.properties autoCreateTopicEnable=true &
tail -f ~/logs/rocketmqlogs/broker.log 查看启动日志
发送与接受消息测试(linux端)
含义
在发送或接收消息之前,开发者需要通知客户端name servers 的位置。RocketMQ提供多种实现方式。为了简单起见,下方展示环境变量NAMESRV_ADDR的用法
发送消息(bin目录下)
设置环境变量:export NAMESRV_ADDR=localhost:9876
使用安装包的Demo发送消息: sh tools.sh org.apache.rocketmq.example.quickstart.Producer
接受消息 (bin目录下)
设置环境变量:export NAMESRV_ADDR=localhost:9876
接受消息:sh tools.sh org.apache.rocketmq.example.quickstart.Consumerjps查看进程号
RocketMQ由如下几部分构成
Name Server
Broker
Producer
Consumer
RocketMQ关闭(linux端)
位置
RocketMQ的bin目录
命令
sh mqshutdown namesrv 关闭NameServer
sh mqshutdown broker 关闭Broker
nohup的作用
nohup命令:如果你正在运行一个进程,而且你觉得在退出帐户时或者关闭客户端该进程还不会结束,那么可以使用nohup命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。在缺省情况下该作业的所有输出都被重定向到一个名为nohup.out的文件中。
简单理解:
nohup运行命令可以使命令永久的执行下去,和用户终端没有关系,例如我们断开SSH连接都不会影响他的运行,注意了nohup没有后台运行的意思;
&的作用
&是指在后台运行,但当用户退出(挂起)的时候,命令自动也跟着退出
注意
nohup COMMAND & 这样就能使命令永久的在后台执行
nohup可以使用Ctrl+C结束掉,而&使用Ctrl+C则结束不掉,nohup不受终端关闭,用户退出影响,而&则受终端关闭,用户退出影响
mqadmin管理工具
使用方式
进入RocketMQ安装位置,在bin目录下执行./mqadmin {admin} {args}
命令介绍
updateTopic[创建Topic]类路径[com.alibaba.rocketmq.tools.command.topic.UpdateTopicSubCommand] 参数 是否必填 说明-b 如果-c为空,则必填 broker 地址,表示topic 建在该broker-c 如果-b为空,则必填 cluster 名称,表示topic 建在该集群(集群可通过clusterList 查询)-h 否 打印帮助-n 是 nameserve 服务地址列表,格式ip:port;ip:port;...-r 否 可读队列数(默认为8)-w 否 可写队列数(默认为8)
注意事项
几乎所有命令都需要配置-n 表示NameServer地址,格式为ip:port;几乎所有命令都可以通过-h获取帮助;如果既有Broker地址(-b)配置项又有clusterName(-c)配置项,则优先以Broker地址执行命令;如果不配置Broker地址,则对集群中所有主机执行命令
集群监控平台搭建
含义
RocketMQ有一个对其扩展的开源项目,incubator-rocketmq-externals,这个项目中有一个子模块叫rocketmq-console。这个便是管理控制台项目。步骤是先将incubator-rocketmq-externals从git拉到本地,然后对rocketmq-console进行操作(编译打包运行)
git地址
https://github.com/SummerUnfair/rocketmq-externals.git
使用步骤
1. 在rocketmq-console中配置namesrc集群地址rocketmq.config.namesrvAddr=192.168.33.100:98762. 执行打包命令clean package -Dmaven.test.skip=true3.启动rokcetmq-consolejava -jar rocketmq-console-ng-1.0.0.jar
RocketMQ架构设计
说明
RocketMQ 整体架构设计主要分为四大部分,分别是:Producer、Consumer、Broker、NameServer。
■ Producer:就是消息生产者,可以集群部署。它会先和 NameServer 集群中的随机一台建立长连接,得知当前要发送的 Topic 存在哪台 Broker Master上,然后再与其建立长连接,支持多种负载平衡模式发送消息。
■ Consumer:消息消费者,也可以集群部署。它也会先和 NameServer 集群中的随机一台建立长连接,得知当前要消息的 Topic 存在哪台 Broker Master、Slave上,然后它们建立长连接,支持集群消费和广播消费消息。
■ Broker:主要负责消息的存储、查询消费,支持主从部署,一个 Master 可以对应多个 Slave,Master 支持读写,Slave 只支持读。Broker 会向集群中的每一台 NameServer 注册自己的路由信息。
■ NameServer:是一个很简单的 Topic 路由注册中心,支持 Broker 的动态注册和发现,保存 Topic 和 Borker 之间的关系。通常也是集群部署,但是各 NameServer 之间不会互相通信, 各 NameServer 都有完整的路由信息,即无状态。
再用一段话来概括它们之间的交互
先启动 NameServer 集群,各 NameServer 之间无任何数据交互,Broker 启动之后会向所有 NameServer 定期(每 30s)发送心跳包,包括:IP、Port、TopicInfo,NameServer 会定期扫描 Broker 存活列表,如果超过 120s 没有心跳则移除此 Broker 相关信息,代表下线。
这样每个 NameServer 就知道集群所有 Broker 的相关信息,此时 Producer 上线从 NameServer 就可以得知它要发送的某 Topic 消息在哪个 Broker 上,和对应的 Broker (Master 角色的)建立长连接,发送消息。
Consumer 上线也可以从 NameServer 得知它所要接收的 Topic 是哪个 Broker ,和对应的 Master、Slave 建立连接,接收消息。
集群模式
NameServer
是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
Broker
部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个slave,但是一个
Slave
只能对应一个Master,Master与Slave的对应关系通过指定相同BrokerName,不同的BrokerId来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有NameServerProducer与NameServer集群中的其中一个节点(随机选择)建立长连接,定时从NameServer取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。Consumer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅信息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
单Master模式
这种方式风险较大,一旦Broker重启或者宕机时,会导致整个服务不可用。不建议线上环境使用,可以用于本地测试
多Master模式
一个集群无Slave,全是Master,例如2个Master或者3个Master,这种模式的优缺点是优点:配置简单,单个Master宕机或重启维护对应无影响,在磁盘配置为PAID10时,即时机器宕机不可恢复情况下,由于PAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢),性能最高。缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。
多Master多Slave模式(异步)
每个Master配置一个Slave,有多对Master-Slave,HA采用同步双写方式,即只有主备都写成功,才向应用返回成功,这种模式优缺点如下:优点:数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高缺点:性能比异步复制模式略低(大约低10%左右),发送单个消息的RT会略高,且目前版本在主节点宕机后,备份不能自动切换为主机
各集群间关系
Producer集群
与nameserver的关系
单个Producer和一台nameserver保持长连接,定时查询topic配置信息,如果该nameserver挂掉,
生产者会自动连接下一个nameserver,直到有可用连接为止,并能自动重连。
与nameserver之间没有心跳。
与broker的关系
单个Producer和与其关联的所有broker保持长连接,并维持心跳。
默认情况下消息发送采用轮询方式,会均匀发到对应Topic的所有queue中。
最佳实践
1.一个应用尽可能只使用一个 Topic,消息子类型用 tags 来标识,tags 可以由应用自由设置。
只有发送消息设置了tags,消费方在订阅消息时,才可以利用 tags 在 broker 做消息过滤。
2.每个消息在业务层面的唯一标识码,要设置到 keys 字段,方便将来定位消息丢失问题。
服务器会为每个消息创建索引(哈希索引),应用可以通过 Topic,key 来查询返条消息内容,
以及消息被谁消费。由于是哈希索引,请务必保证 key 尽可能唯一,这样可以避免潜在的哈希冲突。
3.消息发送成功或者失败,要打印消息日志,务必要打印 sendresult 和 key 字段。
4.对于消息不可丢失应用,务必要有消息重发机制。例如:消息发送失败,存储到数据库,能有定
时程序尝试重发或者人工触发重发。
5.某些应用如果不关注消息是否发送成功,请直接使用sendOneWay方法发送消息。
Consumer
与nameserver的关系
单个Consumer和一台nameserver保持长连接,定时查询topic配置信息,如果该nameserver挂掉,
消费者会自动连接下一个nameserver,直到有可用连接为止,并能自动重连。与nameserver之间没有心跳。
与broker的关系
单个Consumer和与其关联的所有broker保持长连接,并维持心跳,失去心跳后,
则关闭连接,并向该消费者分组的所有消费者发出通知,分组内消费者重新分配队列继续消费。
最佳实践
1.Consumer 数量要小于等于queue的总数量,由于Topic下的queue会被相对均匀的分配给
Consumer,如果 Consumer 超过queue的数量,那多余的 Consumer 将没有queue可以消费消息。
2.消费过程要做到幂等(即消费端去重),RocketMQ为了保证性能并不支持严格的消息去重。
3.尽量使用批量方式消费,RocketMQ消费端采用pull方式拉取消息,通过
consumeMessageBatchMaxSize参数可以增加单次拉取的消息数量,可以很大程度上提高消费吞吐量。
另外,提高消费并行度也可以通过增加Consumer处理线程的方式,对应参数
consumeThreadMin和consumeThreadMax。
4.消息发送成功或者失败,要打印消息日志。
线上建议关闭autoCreateTopicEnable配置
该配置用于在Topic不存在时自动创建,会造成的问题是自动新建的Topic只会存在于一台broker上,
后续所有对该Topic的请求都会局限在单台broker上,造成单点压力。
broker master宕机情况是否会丢消息
broker master宕机,虽然理论上来说不能向该broker写入但slave仍然能支持消费,
但受限于rocketmq的网络连接机制,默认情况下最多需要30秒,消费者才会发现该情况,
这个时间可通过修改参数pollNameServerInteval来缩短。这个时间段内,发往该broker的请求都是失败的,
而且该broker的消息无法消费,因为此时消费者不知道该broker已经挂掉。
直到消费者得到master宕机通知后,才会转向slave进行消费,但是slave不能保证master的消息100%都同步过来了,
因此会有少量的消息丢失。但是消息最终不会丢,一旦master恢复,未同步过去的消息仍然会被消费掉。
生产者发送消息的三种方式
可靠同步发送
含义
同步发送是指消息发送方发出数据后,会在收到接收方发回响应之后才发下一个数据包的通讯方式。
示例
(调用DefaultMQProducer的send方法)
应用
重要的通知消息、短信通知、短信营销系统
生产者代码
可靠异步发送
含义
异步发送是指发送方发出数据后,不等接收方发回响应,接着发送下个数据包的通讯方式。
MQ 的异步发送,需要用户实现异步发送回调接口(SendCallback)。
消息发送方在发送了一条消息后,不需要等待服务器响应即可返回,
进行第二条消息发送。发送方通过回调接口接收服务器响应,并对响应结果进行处理。
应用
异步发送通常被用于对响应时间敏感的业务场景
示例
public class AsyncProducer {public static void main(String[] args) throws Exception {//Instantiate with a producer group name.DefaultMQProducer producer = new DefaultMQProducer("example_group_name");//Launch the instance.producer.start();producer.setRetryTimesWhenSendAsyncFailed(0);for (int i = 0; i < 100; i++) {final int index = i;//Create a message instance, specifying topic, tag and message body.Message msg = new Message("TopicTest","TagA","OrderID188","Hello world".getBytes(RemotingHelper.DEFAULT_CHARSET));producer.send(msg, new SendCallback() {public void onSuccess(SendResult sendResult) {System.out.printf("%-10d OK %s %n", index,sendResult.getMsgId());}public void onException(Throwable e) {System.out.printf("%-10d Exception %s %n", index, e);e.printStackTrace();}});}//Shut down once the producer instance is not longer in use.producer.shutdown();}}单向(Oneway)发送
含义
单向(Oneway)发送特点为发送方只负责发送消息,不等待服务器回应且没有回调函数触发,
即只发送请求不等待应答。 此方式发送消息的过程耗时非常短,一般在微秒级别。
应用
单向发送用于要求一定可靠性的场景,例如日志收集
示例
(调用DefaultMQProducer的sendOneway方法)
public class OnewayProducer {public static void main(String[] args) throws Exception{//Instantiate with a producer group name.DefaultMQProducer producer = new DefaultMQProducer("example_group_name");//Launch the instance.producer.start();for (int i = 0; i < 100; i++) {//Create a message instance, specifying topic, tag and message body.Message msg = new Message("TopicTest" /* Topic */,"TagA" /* Tag */,("Hello RocketMQ " +i).getBytes(RemotingHelper.DEFAULT_CHARSET) /* Message body */);//Call send message to deliver message to one of brokers.producer.sendOneway(msg);}//Shut down once the producer instance is not longer in use.producer.shutdown();}}msgId生成算法
含义
当开发者用rocketmq发送消息的时候通常都会返回如下消息
SendResult [sendStatus=SEND_OK, msgId=00000000000000000000000000000001000118B4AAC2088BEB070000, offsetMsgId=C0A8216400002A9F00000000001A3D34, messageQueue=MessageQueue [topic=TopicTest, brokerName=192.168.33.100, queueId=1], queueOffset=2025]
对于客户端来说msgId是由客户端producer自己生成的,offsetMsgId是由broker生成的,
其中offsetMsgId就是我们在rocketMQ控制台直接输入查询的那个messageId。
概念
msgId
该ID 是消息发送者在消息发送时会首先在客户端生成,全局唯一,
在 RocketMQ 中该 ID 还有另外的一个叫法:uniqId,无不体现其全局唯一性。
offsetMsgId
消息偏移ID,该 ID 记录了消息所在集群的物理地址,
主要包含所存储 Broker 服务器的地址( IP 与端口号)以及所在commitlog 文件的物理偏移量。
两者ID的生成算法
msgId
生成步骤
1.初始化参数LEN,FIX_STRING,COUNTER
2.初始化buffer
3.设置开始时间
4.字节转string工具方法
5.最终生成msgId
细节
其中createUniqId就是最终生成msgId方法。除些之外的方法者是createUniqId调
用或者被间接调用的方法,这些方法实现也比较简单。
StringBuilder sb = new StringBuilder(LEN * 2);
由此可知msgId的长度是LEN * 2 = 16 * 2 = 32;
设time = 当前时间 - 本月开始时间(ms);
从代码得到 FIX_STRING = ip + 进程pid + MessageClientIDSetter.class.getClassLoader().hashCode();
createUniqIDBuffer 加入time 和 counter 因子。
最终得到msgId的生成因子是: ip + 进程pid + MessageClientIDSetter.class.getClassLoader().hashCode() + time + counter(AtomicInteger自增变量)
最后调用bytes2string进行十六进制的移位和编码就产生了我们的msgId。
分析算法
对于每个producer实例来说ip都是唯一的,所以不同producer生成的msgId是不会重复的。
对于producer单个实例来说的区分因子是:time + counter。
首先应用不重启的情况下msgId是保证唯一性的,
应用重启了只要系统的时钟不变msgId也是唯一的。
所以只要系统的时钟不回拨我们就可以保证msgId的全局唯一。
offsetMsgId
生成步骤
broker端生成的offsetMsgId就比较简单了,直接就是主机ip + 物理分区的offset,
再调用UtilAll.bytes2string进行移位转码就完成了
rocketmq之Java Class
DefaultMQProducer类
概述
DefaultMQProducer类是应用发送消息使用的基类,封装一些通用的方法方便开发者在更多场景中使用。属于线程安全类,在配置并启动后可在多个线程间共享此对象。
其可以通过无参构造方法快速创建一个生产者,通过getter/setter方法,调整发送者的参数。主要负责消息的发送,支持同步/异步/oneway的发送方式,这些发送方式均支持批量发送。
方法
| 属性 | 内容 |
|---|---|
| DefaultMQProducerImpl defaultMQProducerImpl; | 生产者内部默认实现类 |
| String producerGroup; | Producer组名, 默认值为DEFAULT_PRODUCER。多个Producer如果属于一个应用,发送同样的消息,则应该将它们归为同一组。 |
| String createTopicKey; | 自动创建测试的topic名称, 默认值为TBW102;在发送消息时,自动创建服务器不存在的topic,需要指定Key。broker必须开启isAutoCreateTopicEnable |
| int defaultTopicQueueNums; | 创建默认topic的queue数量。默认4 |
| int sendMsgTimeout; | 发送消息超时时间,默认值10000,单位毫秒 |
| int compressMsgBodyOverHowmuch; | 消息体压缩阈值,默认为4k(Consumer收到消息会自动解压缩) |
| int retryTimesWhenSendFailed; | 同步模式,返回发送消息失败前内部重试发送的最大次数。可能导致消息重复。默认2 |
| int retryTimesWhenSendAsyncFailed; | 异步模式,返回发送消息失败前内部重试发送的最大次数。可能导致消息重复。默认2 |
| boolean retryAnotherBrokerWhenNotStoreOK; | 声明发送失败时,下次是否投递给其他Broker,默认false |
| int maxMessageSize; | 最大消息大小。默认4M; 客户端限制的消息大小,超过报错,同时服务端也会限制 |
| TraceDispatcher traceDispatcher | 消息追踪器,定义了异步传输数据接口。使用rcpHook来追踪消息 |
DefaultMQPushConsumer类
概述
DefaultMQPushConsumer类是rocketmq客户端消费者的实现,从名字上已经可以看出其消息获取方式为broker往消费端推送数据,其内部实现了流控,消费位置上报等等。DefaultMQPushConsumer是Push消费模式下的默认配置。
| 字段 | 内容 |
|---|---|
| DefaultMQPushConsumerImpl defaultMQPushConsumerImpl; | 消费者实现类,所有的功能都委托给DefaultMQPushConsumerImpl来实现 |
| String consumerGroup; | 消费者组名,必须设置,参数默认值是:DEFAULT_CONSUMER (需要注意的是,多个消费者如果具有同样的组名,那么这些消费者必须只消费同一个topic) |
| MessageModel messageModel; | 消费的方式,支持以下两种 1、集群消费 2、广播消费。BROADCASTING 广播模式,即所有的消费者可以消费同样的消息CLUSTERING 集群模式,即所有的消费者平均来消费一组消息 |
| ConsumeFromWhere consumeFromWhere; | 消费者从那个位置消费,分别为:CONSUME_FROM_LAST_OFFSET:第一次启动从队列最后位置消费,后续再启动接着上次消费的进度开始消费 ;CONSUME_FROM_FIRST_OFFSET:第一次启动从队列初始位置消费,后续再启动接着上次消费的进度开始消费;CONSUME_FROM_TIMESTAMP:第一次启动从指定时间点位置消费,后续再启动接着上次消费的进度开始消费(以上所说的第一次启动是指从来没有消费过的消费者,如果该消费者消费过,那么会在broker端记录该消费者的消费位置,如果该消费者挂了再启动,那么自动从上次消费的进度开始) |
| AllocateMessageQueueStrategy allocateMessageQueueStrategy; | 消息分配策略,用于集群模式下,消息平均分配给所有客户端;默认实现为AllocateMessageQueueAveragely |
| Map<String, String> subscription; | topic对应的订阅tag |
| MessageListener messageListener; | 消息监听器 ,处理消息的业务就在监听里面。目前支持的监听模式包括:MessageListenerConcurrently,对应的处理逻辑类是MessageListener messageListener ;ConsumeMessageConcurrentlyService MessageListenerOrderly 对应的处理逻辑类是ConsumeMessageOrderlyService;两者使用不同的ACK机制。RocketMQ提供了ack机制,以保证消息能够被正常消费。发送者为了保证消息肯定消费成功,只有使用方明确表示消费成功,RocketMQ才会认为消息消费成功。中途断电,抛出异常等都不会认为成功——即都会重新投递。上面两个不同的监听模式使用的ACK机制是不一样的。 |
| OffsetStore offsetStore; | offset存储实现,分为本地存储或远程存储 。集群消费:从远程Broker获取。广播消费:从本地文件获取。 |
重要字段
int consumeThreadMin = 20 线程池自动调整
int consumeThreadMax = 64 线程池自动调整
long adjustThreadPoolNumsThreshold = 100000 int consumeConcurrentlyMaxSpan = 2000单队列并行消费最大跨度,用于流控 int pullThresholdForQueue = 1000一个queue最大消费的消息个数,用于流控 long pullInterval = 0 检查拉取消息的间隔时间,由于是长轮询,所以为 0,但是如果应用为了流控,也可以设置大于 0 的值,单位毫秒,取值范围: [0, 65535]consumeMessageBatchMaxSize = 1 并发消费时,一次消费消息的数量,默认为1,假如修改为50,此时若有100条消息,那么会创建两个线程,每个线程分配50条消息。换句话说,批量消费最大消息条数,取值范围: [1, 1024]。默认是1pullBatchSize = 32 消费者去broker拉取消息时,一次拉取多少条。取值范围: [1, 1024]。默认是32 。可选配置boolean postSubscriptionWhenPull = false boolean unitMode = false
重要方法
subscribe(String topic, String subExpression) 订阅某个topic,subExpression传*为订阅该topic所有消息 registerMessageListener(MessageListenerConcurrently messageListener) 注册消息回调,如果需要顺序消费,需要注册MessageListenerOrderly的实现 start 启动消息消费
Message类
含义Producer发送的消息定义为Message类位置org.apache.rocketmq.common.message字段定义如图字段详解topicMessage都有Topic这一属性,Producer发送指定Topic的消息,Consumer订阅Topic下的消息。通过Topic字段,Producer会获取消息投递的路由信息,决定发送给哪个Broker。flag网络通信层标记。bodyProducer要发送的实际消息内容,以字节数组形式进行存储。Message消息有一定大小限制。transactionIdRocketMQ 4.3.0引入的事务消息相关的事务编号。properties该字段为一个HashMap,存储了Message其余各项参数,比如tag、key等关键的消息属性。RocketMQ预定义了一组内置属性,除了内置属性之外,还可以设置任意自定义属性。当然属性的数量也是有限的,消息序列化之后的大小不能超过预设的最大消息大小。系统内置属性定义于org.apache.rocketmq.common.message.MessageConst (如图)对于一些关键属性,Message类提供了一组set接口来进行设置,class Message {public void setTags(String tags) {...}public void setKeys(Collection<String> keys) {...}public void setDelayTimeLevel(int level) {...}public void setWaitStoreMsgOK(boolean waitStoreMsgOK) {...}public void setBuyerId(String buyerId) {...}}这几个set接口对应的作用分别为为,属性 接口 用途MessageConst.PROPERTY_TAGS setTags 在消费消息时可以通过tag进行消息过滤判定MessageConst.PROPERTY_KEYS setKeys 可以设置业务相关标识,用于消费处理判定,或消息追踪查询MessageConst.PROPERTY_DELAY_TIME_LEVEL setDelayTimeLevel 消息延迟处理级别,不同级别对应不同延迟时间MessageConst.PROPERTY_WAIT_STORE_MSG_OK setWaitStoreMsgOK 在同步刷盘情况下是否需要等待数据落地才认为消息发送成功`MessageConst.PROPERTY_BUYER_ID setBuyerId 没有在代码中找到使用的地方,所以暂不明白其用处 这几个字段为什么用属性定义,而不是单独用一个字段进行表示?方便之处可能在于消息数据存盘结构早早定义,一些后期添加上的字段功能为了适应之前的存储结构,以属性形式存储在一个动态字段更为方便,自然兼容。MessageExt类讲解
含义
对于发送方来说,上述Message的定义以足够。但对于RocketMQ的整个处理流程来说,
还需要更多的字段信息用以记录一些必要内容,比如消息的id、创建时间、存储时间等
等。在同package下可以找到与之相关的其余类定义。首先就是MessageExt,
字段
字段 用途queueId 记录MessageQueue编号,消息会被发送到Topic下的MessageQueuestoreSize 记录消息在Broker存盘大小queueOffset 记录在ConsumeQueue中的偏移sysFlag 记录一些系统标志的开关状态,MessageSysFlag中定义了系统标识bornTimestamp 消息创建时间,在Producer发送消息时设置storeHost 记录存储该消息的Broker地址msgId 消息IdcommitLogOffset 记录在Broker中存储便宜bodyCRC 消息内容CRC校验值reconsumeTimes 消息重试消费次数preparedTransactionOffset 事务详细相关字段
注意
Message还有一个名为MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX的属性,
在消息发送时由Producer生成创建。
上面的msgId则是消息在Broker端进行存储时通过MessageDecoder.createMessageId方法生成
的,其构成为(如图)这个MsgId是在Broker生成的,Producer在发送消息时没有该信息,Consumer在消费消息时则能
获取到该值。RocketMQ也提供了相关命令,命令 实现类 描述queryMsgById QueryMsgByIdSubCommand 根据MsgId查询消息
各个消息发送样例
同步消息异步消息单向消息顺序消息批量消息过滤消息事务消息
如何保证消息不丢失?
消息丢失的原因:
情况1 : 消息没有成功发送到MQ Broker.
情况2 : 消息发送到MQ Broker后,Broker宕机导致内存中消息数据段丢失.
情况3 : 消费者消费到了消息,但是没有处理完毕就出现异常导致消息丢失.
- 生产者发送消息到MQ过程中,出现了网络断开或者MQ挂了,那么MQ接收不到数据,造成消息丢失.
2.MQ接收到了消息之后挂了,消息还在内存当中,内存中的数据存储是暂时性的.如果软件重启之后,内存中的数据就会丢失,还没来得及持久化.
3.消费者从MQ拿到消息进行消费,在处理数据过程中挂了,没有成功处理.既然已经从MQ中成功取到了数据,MQ就认为已经消费过了,就不再保存数据了.如果数据删除了,但是消费者并没成功消费,对于业务来讲这个数据还是丢失.
生产者发送一个消息给MQ,MQ要告诉(confirm确认)生产者已经接收到了数据,要进行confirm确认,然后MQ接收到这个数据之后要立马把这个数据进行持久化,这样就会把这个数据持久化到磁盘中.重启之后数据还能从磁盘之中重新加载到MQ中,保证了消息不会的丢失.
消费者拿到数据之后,消费者处理数据,如果没有成功消费,就不要手动给MQ进行ACK确认.因为MQ一旦收到ACK确认就会认为已经成功消费了,就会把这条数据删除.如果MQ没有收到消费方的ACK确认,这条数据还会在MQ队列之中保留着,这样就保证了消费方能功能的去处理这个数据.
总结: 如何保证消息不丢失.
生产者投递可靠消息,MQ持久化,消费方进行ACK确认.
负载均衡
Producer负载均衡Consumer负载均衡
消息的存储和发送
消息存储结构刷盘机制消息的同步复制和异步复制
消息去重
重复消息产生的原因?
重复消息的根本原因是网络不可达.
- 发送时消息重复
当一条消息已被成功发送到服务器,此时出现了网络闪断,导致服务端对客户端应答失败,如果此时生产者意识到消息发送失败并尝试再次发送消息,消费者后续就会收到两条内容相同的消息.
生产者成功发送了一个消息给MQ,在消息发送的时候,由于网络波动等不确定的因素.导致MQ没有给生产者确认,生产者就认为MQ没有收到消息,生产者就会再发送一条重复的消息给服务器.
- 消费时消息重复
消息消费的场景下,消息已经投递到消费方并完成业务处理,当消费方给MQ服务端反馈应答的时候发生了网络闪断,导致ACK确认失败.为了保证消息至少被消费一次(MQ内部的可靠性),MQ服务端会在网络恢复后再次尝试投递之前被消费方处理过的消息,此时消费者就会收到两条内容相同的消息.
消费者要保证它能够绝对成功的把消息消费了,要进行ACK的确认,拿到了第一次消息进行消费之后,应答的时候,出现了网络波动,应答失败了.MQ没有收到ACK确认会再把这个消息发送一遍,这个时候就会导致消费方手打了两条重复的消息.
重复消息的根本原因是网络原因,因此我们无法避免重复消息的产生.
去重原则:使用业务端逻辑保持幂等性
幂等性:就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用,数据库的结果都是唯一的,不可变的。
只要保持幂等性,不管来多少条重复消息,最后处理的结果都一样,需要业务端来实现。
去重策略:保证每条消息都有唯一编号(比如唯一流水号),且保证消息处理成功与去重表的日志同时出现。
建立一个消息表,拿到这个消息做数据库的insert操作。给这个消息做一个唯一主键(primary key)或者唯一约束,那么就算出现重复消费的情况,就会导致主键冲突,那么就不再处理这条消息。
消息重复
消息领域有一个对消息投递的QoS定义,分为:
最多一次(At most once)
至少一次(At least once)
仅一次( Exactly once)
QoS:Quality of Service,服务质量
几乎所有的MQ产品都声称自己做到了At least once。
既然是至少一次,那避免不了消息重复,尤其是在分布式网络环境下。
比如:网络原因闪断,ACK返回失败等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将该消息分发给其他的消费者。
不同的消息队列发送的确认信息形式不同,例如RabbitMQ是发送一个ACK确认消息,RocketMQ是返回一个CONSUME_SUCCESS成功标志,Kafka实际上有个offset的概念。
RocketMQ没有内置消息去重的解决方案,最新版本是否支持还需确认。
消息的可用性
当我们选择好了集群模式之后,那么我们需要关心的就是怎么去存储和复制这个数据,RocketMQ对消息的刷盘提供了同步和异步的策略来满足我们的,当我们选择同步刷盘之后,如果刷盘超时会给返回FLUSH_DISK_TIMEOUT,如果是异步刷盘不会返回刷盘相关信息,选择同步刷盘可以尽最大程度满足我们的消息不会丢失。
除了存储有选择之后,我们的主从同步提供了同步和异步两种模式来进行复制,当然选择同步可以提升可用性,但是消息的发送RT时间会下降10%左右。
RocketMQ采用的是混合型的存储结构,即为Broker单个实例下所有的队列共用一个日志数据文件(即为CommitLog)来存储。
而Kafka采用的是独立型的存储结构,每个队列一个文件。
RocketMQ 刷盘实现
Broker 在消息的存取时直接操作的是内存(内存映射文件),这可以提供系统的吞吐量,但是无法避免机器掉电时数据丢失,所以需要持久化到磁盘中。
刷盘的最终实现都是使用NIO中的 MappedByteBuffer.force() 将映射区的数据写入到磁盘,如果是同步刷盘的话,在Broker把消息写到CommitLog映射区后,就会等待写入完成。
异步而言,只是唤醒对应的线程,不保证执行的时机
顺序消息:
生产者消费者一般需要保证顺序消息的话,可能就是一个业务场景下的,比如订单的创建、支付、发货、收货。
那这些东西是不是一个订单号呢?一个订单的肯定是一个订单号。
一个topic下有多个队列,为了保证发送有序,RocketMQ提供了MessageQueueSelector队列选择机制,他有三种实现:
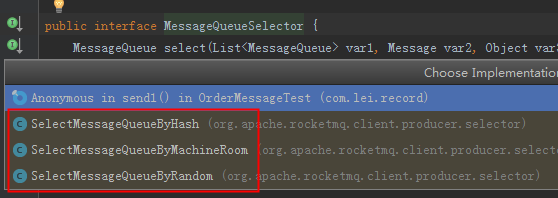
我们可使用Hash取模法,让同一个订单发送到同一个队列中,再使用同步发送,只有同个订单的创建消息发送成功,再发送支付消息。这样,我们保证了发送有序。
RocketMQ的topic内的队列机制,可以保证存储满足FIFO(First Input First Output 简单说就是指先进先出),剩下的只需要消费者顺序消费即可。
消费者去消费的时候,让多个消费者并发消费,提高了消息费的效率和吞吐量.两个消费者都可以去队列1进行消费.这样无法保证消费者之间的顺序,所以MQ提供了解决方案,分段锁.它会把队列锁住,当消费者1拿了M1之后没有处理完,就不对MQ进行ACK确认,如果没有去人Q1就被锁住可,M2就不能被获取,直到M1成功消费并提交了ACK确认了才会释放锁.消费者2蔡能拿到M2进行消费,这样就可以保证了顺序性,还保证了消息消费的吞吐量.
RocketMQ仅保证顺序发送,顺序消费由消费者业务保证!!!
总结:
顺序消息:指的是消息的消费顺序与生存顺序相同
全局顺序:在某个topic下,所有消息都要保证顺序,设置一个队列
局部顺序:只要保证每一组消息被顺序消费即可,根据消息特性,投放到指定队列
public class Producer {public static void main(String[] args) throws MQClientException, InterruptedException {DefaultMQProducer producer = new DefaultMQProducer("test_producer_group");producer.setNamesrvAddr(MessageConstants.NAMESRV_ADDR);producer.start();Map<Integer, Book> bookMap = new HashMap<>();bookMap.put(1, new Book(1, "语文"));bookMap.put(2, new Book(2, "数学"));bookMap.put(3, new Book(3, "英语"));bookMap.put(4, new Book(4, "物理"));for (int i = 1; i <= 8; i++) {try {int bookId = i % 4;if (bookId == 0) {bookId = 4;}Book book = bookMap.get(bookId);Message msg = new Message("test_book", "TagA",JSON.toJSONString(book).getBytes(RemotingHelper.DEFAULT_CHARSET));msg.setKeys("book_id_" + book.getId());SendResult sendResult = producer.send(msg, new MessageQueueSelector() {@Overridepublic MessageQueue select(List<MessageQueue> list, Message message, Object o) {Integer id = (Integer)o;int index = id % list.size();return list.get(index);}}, book.getId());System.out.printf("%s%n", sendResult);} catch (Exception e) {e.printStackTrace();Thread.sleep(1000);}}producer.shutdown();}
}
class Book {private int id;private String name;public Book(int id, String name) {this.id = id;this.name = name;}public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}
}public class Consumer {public static void main(String[] args) throws MQClientException {DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("test_consumer_group");consumer.setNamesrvAddr(MessageConstants.NAMESRV_ADDR);consumer.subscribe("test_book", "TagA");consumer.registerMessageListener(new MyMessageListenerConcurrently());consumer.start();System.out.printf("Consumer Started.%n");}
}分布式事务:
Half Message(半消息)
是指暂不能被Consumer消费的消息。Producer 已经把消息成功发送到了 Broker 端,但此消息被标记为暂不能投递状态,处于该种状态下的消息称为半消息。需要 Producer
对消息的二次确认后,Consumer才能去消费它。
消息回查
由于网络闪段,生产者应用重启等原因。导致 Producer 端一直没有对 Half Message(半消息) 进行 二次确认。这是Brock服务器会定时扫描长期处于半消息的消息,会
主动询问 Producer端 该消息的最终状态(Commit或者Rollback),该消息即为 消息回查。

A服务先发送个Half Message给Brock端,消息中携带 B服务 即将要+100元的信息。
当A服务知道Half Message发送成功后,那么开始第3步执行本地事务。
执行本地事务(会有三种情况1、执行成功。2、执行失败。3、网络等原因导致没有响应)
如果本地事务成功,那么Product像Brock服务器发送Commit,这样B服务就可以消费该message。
如果本地事务失败,那么Product像Brock服务器发送Rollback,那么就会直接删除上面这条半消息。
如果因为网络等原因迟迟没有返回失败还是成功,那么会执行RocketMQ的回调接口,来进行事务的回查。
public class MyTransactionListener implements TransactionListener {@Overridepublic LocalTransactionState executeLocalTransaction(Message message, Object o) {System.out.printf("executeLocalTransaction,Obejct:%s%n", JSON.toJSONString(o));try {Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();}// 该方法主要是设置本地事务状态,与业务方代码在一个事务中,只要本地事务提交成功,该方法也会提交成功return LocalTransactionState.COMMIT_MESSAGE;}@Overridepublic LocalTransactionState checkLocalTransaction(MessageExt messageExt) {// 告知RocketMQ是提交还是回滚// 新版本将该方法与executeLocalTransaction进行合并return null;}
}public class Producer {public static void main(String[] args) throws MQClientException {TransactionMQProducer producer = new TransactionMQProducer("test_trans_group");producer.setNamesrvAddr(MessageConstants.NAMESRV_ADDR);ExecutorService executorService = new ThreadPoolExecutor(2, 5, 100, TimeUnit.SECONDS,new ArrayBlockingQueue<Runnable>(2000), new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r);thread.setName("TransactionMQProducer-CheckThread");return thread;}});producer.setExecutorService(executorService);producer.setTransactionListener(new MyTransactionListener());producer.start();ArgBean arg = new ArgBean();arg.setA("testa");arg.setB("testb");Message message= new Message("test_trans", "TagA", ("test trans messsage!!obj:" + JSON.toJSONString(arg)).getBytes());producer.sendMessageInTransaction(message, arg);}
}
class ArgBean {private String a;private String b;public String getA() {return a;}public void setA(String a) {this.a = a;}public String getB() {return b;}public void setB(String b) {this.b = b;}
}public class Consumer {public static void main(String[] args) throws MQClientException {DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("test_consumer_group");consumer.setNamesrvAddr(MessageConstants.NAMESRV_ADDR);consumer.subscribe("test_trans", "TagA");consumer.registerMessageListener(new MyMessageListenerConcurrently());consumer.start();System.out.printf("Consumer Started.%n");}
}消息过滤
Broker端消息过滤 在Broker中,按照Consumer的要求做过滤,优点是减少了对于Consumer无用消息的网络传输。缺点是增加了Broker的负担,实现相对复杂。
Consumer端消息过滤 这种过滤方式可由应用完全自定义实现,但是缺点是很多无用的消息要传输到Consumer端。
回溯消费
回溯消费是指Consumer已经消费成功的消息,由于业务上的需求需要重新消费,要支持此功能,Broker在向Consumer投递成功消息后,消息仍然需要保留。并且重新消费一般是按照时间维度。
例如由于Consumer系统故障,恢复后需要重新消费1小时前的数据,那么Broker要提供一种机制,可以按照时间维度来回退消费进度。
RocketMQ支持按照时间回溯消费,时间维度精确到毫秒,可以向前回溯,也可以向后回溯。
消息堆积
消息中间件的主要功能是异步解耦,还有个重要功能是挡住前端的数据洪峰,保证后端系统的稳定性,这就要求消息中间件具有一定的消息堆积能力,消息堆积分以下两种情况:
消息堆积在内存Buffer,一旦超过内存Buffer,可以根据一定的丢弃策略来丢弃消息,如CORBA Notification规范中描述。适合能容忍丢弃消息的业务,这种情况消息的堆积能力主要在于内存Buffer大小,而且消息堆积后,性能下降不会太大,因为内存中数据多少对于对外提供的访问能力影响有限。
消息堆积到持久化存储系统中,例如DB,KV存储,文件记录形式。 当消息不能在内存Cache命中时,要不可避免的访问磁盘,会产生大量读IO,读IO的吞吐量直接决定了消息堆积后的访问能力。
评估消息堆积能力主要有以下四点:
消息能堆积多少条,多少字节?即消息的堆积容量。
消息堆积后,发消息的吞吐量大小,是否会受堆积影响?
消息堆积后,正常消费的Consumer是否会受影响?
消息堆积后,访问堆积在磁盘的消息时,吞吐量有多大?
大量消息堆积怎么处理?
消息堆积的原因?
消费方出现了故障导致消息没有被正常消费.
1.网路故障.
2.消费方消费消息后没有给MQServer正常应答.
1.网络断了没人消费,消息源源不断堆积在MQ.
2.消费方消费了,忘记ACK确认消息,所以MQ没有删除消费过消息,造成消息堆积.
消息堆积的处理方案
1.检查并修复消费方的正常消费速度.
2.将堆积消息转存到容量更大的MQ集群中.
3.增加多个消费者节点并行消费堆积消息.
4.消费完毕后,恢复原始架构.
定时消息
定时消息是指消息发到Broker后,不能立刻被Consumer消费,要到特定的时间点或者等待特定的时间后才能被消费。
如果要支持任意的时间精度,在Broker层面,必须要做消息排序,如果再涉及到持久化,那么消息排序要不可避免的产生巨大性能开销。
RocketMQ支持定时消息,但是不支持任意时间精度,支持特定的level,例如定时5s,10s,1m等。
其精度如下:
| 延迟级别 | 时间 | 延迟级别 | 时间 |
|---|---|---|---|
| 1 | 1s | 2 | 5s |
| 3 | 10s | 4 | 30s |
| 5 | 1m | 6 | 2m |
| 7 | 3m | 8 | 4m |
| 9 | 5m | 10 | 6m |
| 11 | 7m | 12 | 8m |
| 13 | 9m | 14 | 10m |
| 15 | 20m | 16 | 30m |
| 17 | 1h | 18 | 2h |
producer代码:
public class Producer {public static void main(String[] args) throws Exception {DefaultMQProducer producer = new DefaultMQProducer("test_producer_group");producer.setNamesrvAddr(MessageConstants.NAMESRV_ADDR);producer.start();int totalMessagesToSend = 100;for (int i = 0; i < totalMessagesToSend; i++) {Message message = new Message("schedule_message_test_topic", ("Hello scheduled message " + i).getBytes());//设置级别为3,延迟10smessage.setDelayTimeLevel(3);producer.send(message);}producer.shutdown();}
}public class Consumer {public static void main(String[] args) throws MQClientException {DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("test_consumer_group");consumer.setNamesrvAddr(MessageConstants.NAMESRV_ADDR);consumer.subscribe("test_scheduled", "*");consumer.registerMessageListener(new MyMessageListenerConcurrently());consumer.start();System.out.printf("Consumer Started.%n");}
}Broker的Buffer问题
Broker的Buffer通常指的是Broker中一个队列的内存Buffer大小,这类Buffer通常大小有限。
另外,RocketMQ没有内存Buffer概念,RocketMQ的队列都是持久化磁盘,数据定期清除。
RocketMQ同其他MQ有非常显著的区别,RocketMQ的内存Buffer抽象成一个无限长度的队列,不管有多少数据进来都能装得下,这个无限是有前提的,Broker会定期删除过期的数据。
例如Broker只保存3天的消息,那么这个Buffer虽然长度无限,但是3天前的数据会被从队尾删除。
消息过期怎么处理?
消息过期的原因?
消息设置了过期时间,如果超时还没被消费,则视为过期消息.
过期消息可以转存到死信队列.
没配置死信队列,消息会被直接删除.
这么做的目的是保证MQ消息不积压.
消息被直接删除并不好,因为业务没有正常的处理,通常会启动一个死信队列,死信队列会去接收没有被正常消费的消息.
流程:
1.过期消息进入到死信队列.
2.启动专门的消费者消费死信队里中中的消息,并写入到数据库并记录日志.
3.查询数据库消息日志,重新发送消息到MQ.
开启死信队列的消费节点,去把死信队列的消息进行消费,存到数据库之后,再重复查询出来扔到正常队列里等待消费即可.
rocketmq-spring-boot-starter 用法简介
当开发中需要快速集成RocketMQ时可以考虑使用 rocketmq-spring-boot-starter 搭建RocketMQ的集成环境,但该框架并不完全具备RocketMQ所有的配置简化,如需批量消费消息便需要自定义一个DefaultMQPushConsumer bean去消费了。
个人在开发中常用的rocketmq-spring-boot-starter相关类:
RocketMQListener接口:消费者都需实现该接口的消费方法onMessage(msg)。
RocketMQPushConsumerLifecycleListener接口:当@RocketMQMessageListener中的配置不足以满足我们的需求时,可以实现该接口直接更改消费者类DefaultMQPushConsumer配置
@RocketMQMessageListener:被该注解标注并实现了接口RocketMQListener的bean为一个消费者并监听指定topic队列中的消息,该注解中包含消费者的一些常用配置(大部分按默认即可),一般只需更改consumerGroup(消费组)与topic。
RocketMQMessageListener中的属性配置是可以使用Placeholder(占位符)从配置文件或配置中心获取的
rocketmq:name-server: 192.168.126.100:9876;192.168.64.152:9876producer:#生产者组名,规定在一个应用里面必须唯一group: group-1#消息发送的超时时间,默认为3000mssend-message-timeout: 3000#消息达到4096字节的时候,消息就会被压缩。默认4096compress-message-body-threshold: 4096#最大的消息限制 默认为128Kmax-message-size: 4194304#同步消息发送失败重试次数retry-times-when-send-failed: 3#在内部发送失败时是否重试其他代理,这个参数在有多个broker才生效。retry-next-server: true#异步消息发送失败重试的次数retry-times-when-send-async-failed: 3业务案例
有一个点赞业务,不限制用户的点赞数只需进行记录(产品需求,开发提议无效),当每个用户都进行x连击享受数量猛增的快感时如果数据库都需要进行x个点赞数据的插入,数据库毫无疑问会塞死导致崩溃。
于是想到可以尝试下MQ削峰,比如每秒来了5000消息但数据库只能承受2000,那我消费时每次只拉取消费1600就好了,剩下的放在Broker堆积慢慢消费就好。由于之前的消息中心也在用RocketMQ,于是确认使用RocketMQ来进行削峰。
rocketmq:name-server: 127.0.0.1:9876producer:group: praise-group
server:port: 10000spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: tigerurl: jdbc:mysql://localhost:3306/wilson
swagger:docket:base-package: io.rocket.consumer.controllerPraiseRecord(点赞记录):
@Data
public class PraiseRecord implements Serializable {private Long id;private Long uid;private Long liveId;private LocalDateTime createTime;
}RestController
@RequestMapping("/message")
public class MessageController {@Resourceprivate RocketMQTemplate rocketMQTemplate;@PostMapping("/praise")public ServerResponse praise(@RequestBody PraiseRecordVO vo) {rocketMQTemplate.sendOneWay(RocketConstant.Topic.PRAISE_TOPIC, MessageBuilder.withPayload(vo).build());return ServerResponse.success();}// ......}由于用户可以连续点赞,所以考虑可以在点赞消息的处理上宽松一点(容许消息丢失)以追求更高的性能,因此选择使用sendOneyWay()进行消息发送。
RocketMQ的消息发送方式主要含syncSend()同步发送、asyncSend()异步发送、sendOneWay()三种方式,sendOneWay()也是异步发送,区别在于不需等待Broker返回确认,所以可能会存在信息丢失的状况,但吞吐量更高,具体需根据业务情况选用。
性能:sendOneWay > asyncSend > syncSend
RocketMQTemplate的send()方法默认是同步(syncSend)的
PraiseListener:点赞消息消费者
@Service
@RocketMQMessageListener(topic = RocketConstant.Topic.PRAISE_TOPIC, consumerGroup = RocketConstant.ConsumerGroup.PRAISE_CONSUMER)
@Slf4j
public class PraiseListener implements RocketMQListener<PraiseRecordVO>, RocketMQPushConsumerLifecycleListener {@Resourceprivate PraiseRecordService praiseRecordService;@Overridepublic void onMessage(PraiseRecordVO vo) {praiseRecordService.insert(vo.copyProperties(PraiseRecord::new));}@Overridepublic void prepareStart(DefaultMQPushConsumer consumer) {// 每次拉取的间隔,单位为毫秒consumer.setPullInterval(2000);// 设置每次从队列中拉取的消息数为16consumer.setPullBatchSize(16);}
}单次pull消息的最大数目受broker存储的MessageStoreConfig.maxTransferCountOnMessageInMemory(默认为32)值限制,即若想要消费者从队列拉取的消息数大于32有效(pullBatchSize>32)则需更改Broker的启动参数maxTransferCountOnMessageInMemory值。
在MQ削峰的配置参数里,以下几个DefaultMQPushConsumer的参数是需要注意一下的:
pullInterval:每次从Broker拉取消息的间隔,单位为毫秒
pullBatchSize:每次从Broker队列拉取到的消息数,该参数很容易让人误解,一开始我以为是每次拉取的消息总数,但测试过几次后确认了实质上是从每个队列的拉取数(源码上的注释文档真的很差,跟没有一样),即Consume每次拉取的消息总数如下:
EachPullTotal=所有Broker上的写队列数和(writeQueueNums=readQueueNums) * pullBatchSize
consumeMessageBatchMaxSize:每次消费(即将多条消息合并为List消费)的最大消息数目,默认值为1,rocketmq-spring-boot-starter 目前不支持批量消费(2.1.0版本)
在消费者开始消息消费时会先从各队列中拉取一条消息进行消费,消费成功后再以每次pullBatchSize的数目进行拉取。
PraiseListener中设置了每次拉取的间隔为2s,每次从队列拉取的消息数为16,在搭建了2master broker且broker上writeQueueNums=readQueueNums=4的环境下每次拉取的消息理论数值为16 * 2 * 4 = 128,在第一次从各队列拉取1条消息(即共8条)后消费成功后会每次就会拉取最多128条消息进行消费,想验证下的可以把onMessage()的insert()改为log.info(“1”)然后统计单位秒内打印的日志数是否为128。
如何使用RocketMQ批量消费 ?
虽然点赞业务使用MQ单条插入后TPS已经达到当前业务指标要求了,但考虑到如果后续要求在不添加机器数的情况下增加TPS,且数据量还没到分库分表的程度,个人就打算从批量消费下手,由一次插入一条点赞记录改为一次性插入多条(insertBatch)。
当然能满足现有需求能不做肯定不做的,过度优化过分碍事,但想多点方案不会坏事。rocketmq-spring-boot-starter并没有提供批量消费的功能,所以要批量消费消息需要自定义DefaultMQPushConsumer并配置其consumeMessageBatchMaxSize属性。
consumeMessageBatchMaxSize属性默认值为1,即每次只消费一条消息,需要注意的是该属性也会受pullBatchSize影响,如果consumeMessageBatchMaxSize为32但pullBatchSize只为12,那么每次批量消费的最大消息数也就只有12。
如下为个人测试批量消费Consumer的测试bean:
@Bean
public DefaultMQPushConsumer userMQPushConsumer() throws MQClientException {DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(RocketConstant.ConsumerGroup.SPRING_BOOT_USER_CONSUMER);consumer.setNamesrvAddr(nameServer);consumer.subscribe(RocketConstant.Topic.SPRING_BOOT_USER_TOPIC, "*");// 设置每次消息拉取的时间间隔,单位毫秒consumer.setPullInterval(1000);// 设置每个队列每次拉取的最大消息数consumer.setPullBatchSize(24);// 设置消费者单次批量消费的消息数目上限consumer.setConsumeMessageBatchMaxSize(12);consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context)-> {List<UserInfo> userInfos = new ArrayList<>(msgs.size());Map<Integer, Integer> queueMsgMap = new HashMap<>(8);msgs.forEach(msg -> {userInfos.add(JSONObject.parseObject(msg.getBody(), UserInfo.class));queueMsgMap.compute(msg.getQueueId(), (key, val) -> val == null ? 1 : ++val);});log.info("userInfo size: {}, content: {}", userInfos.size(), userInfos);/*处理批量消息,如批量插入:userInfoMapper.insertBatch(userInfos);*/return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;});consumer.start();return consumer;
}如果默认配置情况下log打印出的userInfo size恒为1,但由于设置了consumeMessageBatchMaxSize与pullBatchSize,且pullBatchSize较小,所以每次消费的消息数最大值为12
/验证RocketMQ顺序消费*/
@RequestMapping("/send/ordered")
public String sendOrderedMsg(){undefined
/**
- hashKey: 为了保证报到同一个队列中,将消息发送到orderTopic主题上
*/
rocketMQTemplate.syncSendOrderly(“orderTopic”,“no1”,“order”);
rocketMQTemplate.syncSendOrderly(“orderTopic”,“no2”,“order”);
rocketMQTemplate.syncSendOrderly(“orderTopic”,“no3”,“order”);
rocketMQTemplate.syncSendOrderly(“orderTopic”,“no4”,“order”);
rocketMQTemplate.syncSendOrderly(“orderTopic”,“no5”,“order”);
return “success”;
}
}
消费者:消费者在消费的时候,默认是异步多线程消费的,所以无法保证顺序,需要指定同步消费。指定 consumeMode = ConsumeMode.ORDERLY。默认值是 consumeMode = ConsumeMode.CONCURRENT。
@Service
@RocketMQMessageListener(topic = “orderTopic”, consumerGroup = “ordered-consumer”, consumeMode = ConsumeMode.ORDERLY)
public class OrderedConsumer implements RocketMQListener {undefined
@Override
public void onMessage(String message) {undefined
System.out.println(“顺序消费,收到消息:” + message);
}
}
rocketmqTemplate 延时消息
public class RocketMQTemplate extends AbstractMessageSendingTemplate<String> implements InitializingBean, DisposableBean {public SendResult syncSend(String destination, Message<?> message, long timeout, int delayLevel) {//同步延时发送public void asyncSend(String destination, Message<?> message, SendCallback sendCallback, long timeout, int delayLevel) {//异步延时发送。。。。}
@Service
public class ProducerService {@Resourceprivate RocketMQTemplate rocketMQTemplate;public void sendDelay(){SendResult result=rocketMQTemplate.syncSend("topic-1:delay",MessageBuilder.withPayload("瓜田李下 delay").build(),2000,2);System.out.println("发送时间:"+System.currentTimeMillis());System.out.println(result);}}
@Service
@RocketMQMessageListener(consumerGroup = "consumerGroup",topic = "topic-1",selectorExpression = "*")
public class ConsumerService implements RocketMQListener<String> {@Overridepublic void onMessage(String s) {System.out.println("消费时间:"+System.currentTimeMillis());System.out.println(s);}
}
RocketmqTemplate:发送事务消息
public class RocketMQTemplate extends AbstractMessageSendingTemplate implements InitializingBean, DisposableBean {
发送事务消息
public TransactionSendResult sendMessageInTransaction(String txProducerGroup, String destination, Message<?> message, Object arg) throws MessagingException {
//txProducerGroup为发送组,destination为消息发送的topic,message为消息体,arg为传递给本地函数参数
事务消息接口:创建本地方法、本地事务状态回调函数
public interface RocketMQLocalTransactionListener {
RocketMQLocalTransactionState executeLocalTransaction(Message var1, Object var2);
RocketMQLocalTransactionState checkLocalTransaction(Message var1);
}
本地事务执行状态
public enum RocketMQLocalTransactionState {
COMMIT,
ROLLBACK,
UNKNOWN;
private RocketMQLocalTransactionState() {
}
}
事务消息注解:标注在RocketMQLocalTransactionListener接口的实现类上,发送事务消息时会自动调用本地方法
@Target({ElementType.TYPE, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface RocketMQTransactionListener {String txProducerGroup() default "rocketmq_transaction_default_global_name";int corePoolSize() default 1;int maximumPoolSize() default 1;long keepAliveTime() default 60000L;int blockingQueueSize() default 2000;String accessKey() default "${rocketmq.producer.access-key}";String secretKey() default "${rocketmq.producer.secret-key}";
}
producer 端
TransactionProducerService
@Service
public class TransactionProducerService {@Resourceprivate RocketMQTemplate rocketMQTemplate;public void sendInTransaction(){for(int i=0;i<100;i++){TransactionSendResult result=rocketMQTemplate.sendMessageInTransaction("transaction","topic-3", MessageBuilder.withPayload("瓜田李下 事务消息"+i).build(), i);System.out.println(result);}}
}@Component
@RocketMQTransactionListener(txProducerGroup = "transaction")
class LocalExecutor implements RocketMQLocalTransactionListener {private ConcurrentHashMap<Integer, RocketMQLocalTransactionState> map=new ConcurrentHashMap<>();@Overridepublic RocketMQLocalTransactionState executeLocalTransaction(Message message, Object o) {map.put(message.hashCode(),RocketMQLocalTransactionState.UNKNOWN);int i=Integer.parseInt(o.toString());if(i==2){System.out.println("本地事务出错,回滚事务消息");map.put(message.hashCode(),RocketMQLocalTransactionState.ROLLBACK);}else {map.put(message.hashCode(),RocketMQLocalTransactionState.COMMIT);}return map.get(message.hashCode());}@Overridepublic RocketMQLocalTransactionState checkLocalTransaction(Message message) {return map.get(message.hashCode());}
}
consumer 端
ConsumerService3
@Service
@RocketMQMessageListener(consumerGroup = "consumerGroup-3",topic = "topic-3",selectorExpression = "*")
public class ConsumerService3 implements RocketMQListener<String> {@Overridepublic void onMessage(String s) {System.out.println("消费时间:"+System.currentTimeMillis());System.out.println(s);}
}
springboot整合RocketMQ的各种消息类型,生产者,消费者
import org.apache.rocketmq.client.producer.*;
import org.apache.rocketmq.spring.core.RocketMQTemplate;
import org.apache.rocketmq.spring.support.RocketMQHeaders;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.PayloadApplicationEvent;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;@Service
public class MQServiceImpl implements MQService{Logger log= LoggerFactory.getLogger(MQServiceImpl.class);@Autowiredprivate RocketMQTemplate mqTemplate;/*** 同步消息* 消息发送方发出数据后,会在收到接收方发回响应之后才发下一个数据包的通讯方式*/@Overridepublic void syncMQMessageSend() {mqTemplate.syncSend("topic1:tag1", "hello1");mqTemplate.syncSend("topic1:tag1", "hello2");SendResult s2=mqTemplate.syncSend("topic1:tag1", "hello3");log.info("3条同步消息String类型已发送:topic:topic1,tag:tag1:{}",s2);User user=new User("tom",100);SendResult result=mqTemplate.syncSend("topic2:tag1", MessageBuilder.withPayload(user).build());//可以简写成以下,直接传入pojo对象SendResult result2=mqTemplate.syncSend("topic2:tag1", user.setName("lily").setAge(200));log.info("object类型同步消息发送结果:{},{}",result,result2);}/*** 异步消息* 指发送方发出数据后,不等接收方发回响应,接着发送下个数据包* 关键实现异步发送回调接口(SendCallback)* 在执行消息的异步发送时应用不需要等待服务器响应即可直接返回,通过回调接口接收务器响应,并对服务器的响应结果进行处理* 这种方式任然需要返回发送消息任务的执行结果,异步不影响后续任务,不会造成阻塞*/@Overridepublic void asyncMQMessageSend() {User user=new User("tom",100);mqTemplate.asyncSend("topic3:tag1", user, new SendCallback() {@Overridepublic void onSuccess(SendResult sendResult) {log.info("异步消息发送成功:{}",sendResult);}@Overridepublic void onException(Throwable throwable) {log.info("异步消息发送失败:{}",throwable.getMessage());}});}/*** 单向消息* 特点为只负责发送消息,不等待服务器回应且没有回调函数触发,即只发送请求不等待应答* 此方式发送消息的过程耗时非常短,一般在微秒级别* 应用场景:适用于某些耗时非常短,但对可靠性要求并不高的场景,例如日志收集*/@Overridepublic void oneWaySendMQMessageSend() {User user=new User("tom",100);mqTemplate.sendOneWay("topic4:tag1", user);log.info("单向消息已发送");}/*** 延迟消息* rocketMQ的延迟消息发送其实是已发送就已经到broker端了,然后消费端会延迟收到消息。* RocketMQ 目前只支持固定精度的定时消息。* 固定等级:1到18分别对应1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h* 延迟的底层方法是用定时任务实现的。*/@Overridepublic void delayedSendMQMessageSend() {User user=new User("tom",100);SendCallback sc=new SendCallback() {@Overridepublic void onSuccess(SendResult sendResult) {log.info("发送异步延时消息成功");}@Overridepublic void onException(Throwable throwable) {log.info("发送异步延时消息失败:{}",throwable.getMessage());}};Message<User> message=MessageBuilder.withPayload(user).build();//异步延时mqTemplate.asyncSend("topic5:tag1", message, sc, 3000, 3);//同步延时(少一个sendCallback)SendResult result=mqTemplate.syncSend("topic5:tag1", message, 3000, 3);log.info("发送同步延时消息成功:{}",result);}/*** 顺序消息*使用hashcode对topic队列数量取模得到对应队列* 使消息按照顺序被消费,顺序与生产出来的顺序一致* 比如同一个订单生成,付费顺序需要一致,可以按照订单id来当作hashkey*/@Overridepublic void orderlyMQMessageSend() {String s1[]={"tom","1"};String s2[]={"klee我和tom在同一个消费者被消费,而且在tom之后","1"};String s3[]={"lily我可能不会和tom在同一个消费者被消费","2"};//同步顺序,也可以是其他类型比如异步顺序,单向顺序mqTemplate.syncSendOrderly("topic6:tag1", s1[0],s1[1]);mqTemplate.syncSendOrderly("topic6:tag1", s2[0],s2[1]);mqTemplate.syncSendOrderly("topic6:tag1", s3[0],s3[1]);log.info("单向消息已发送");}/*** 过滤消息* Tag 过滤* Sql 过滤* Sql类型语法:* 数值比较,比如:>,>=,<,<=,BETWEEN,=;* 字符比较,比如:=,<>,IN;* IS NULL 或者 IS NOT NULL;* 逻辑符号 AND,OR,NOT;*/@Overridepublic void selectorMQSend() {//Tag过滤就是在发送参数上指定,比如topic1:tag1就指定了tag1,这种光topic1不指定就是所有tag//这里使用sql92User user=new User("tom",16);User user2=new User("klee",9);Message<User> message=MessageBuilder.withPayload(user).setHeader("age", user.getAge()).build();Message<User> message2=MessageBuilder.withPayload(user).setHeader("age", user2.getAge()).build();mqTemplate.syncSend("topic10", message);//age=16,消费者设置sql92过滤(header)头数据age=9mqTemplate.syncSend("topic10", message2);//age=9log.info("添加age头信息的过滤消息发送完毕");}/*** 分布式事物消息*生产者需要一个监听自己的类*/@Overridepublic void transactionMQSend() {User user=new User("klee",9);Message<User> message=MessageBuilder.withPayload(user).setHeader(RocketMQHeaders.TRANSACTION_ID, UUID.randomUUID()).build();TransactionSendResult result=mqTemplate.sendMessageInTransaction("topic15:tag1", message, null);if(result.getLocalTransactionState().equals(LocalTransactionState.COMMIT_MESSAGE)&&result.getSendStatus().equals(SendStatus.SEND_OK)){log.info("事物消息发送成功");}log.info("事物消息发送结果:{}",result);}
}
import org.apache.rocketmq.spring.annotation.RocketMQMessageListener;
import org.apache.rocketmq.spring.core.RocketMQListener;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;@Component
@RocketMQMessageListener(consumerGroup = "consumer-group-1",topic = "topic1",selectorExpression = "tag1")
public class MQConsumer implements RocketMQListener<String> {Logger log= LoggerFactory.getLogger(MQConsumer.class);@Overridepublic void onMessage(String s) {log.info("consumer-1 收到string类型消息:{}",s);}
}
import com.ro.pojo.User;
import org.apache.rocketmq.spring.annotation.ConsumeMode;
import org.apache.rocketmq.spring.annotation.RocketMQMessageListener;
import org.apache.rocketmq.spring.core.RocketMQListener;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;@Component
@RocketMQMessageListener(consumeMode = ConsumeMode.ORDERLY,consumerGroup = "consumer-orderly",topic = "topic6",selectorExpression = "tag1")
public class MQConsumerOrderly implements RocketMQListener<String> {Logger log= LoggerFactory.getLogger(MQConsumerOrderly.class);@Overridepublic void onMessage(String s) {log.info("接收到顺序消息了:{}",s);}
}事物消息消费者
发送方向 MQ 服务端发送消息。
MQ Server 将消息持久化成功之后,向发送方 ACK 确认消息已经发送成功,此时消息为半消息。
发送方开始执行本地事务逻辑。
发送方根据本地事务执行结果向 MQ Server 提交二次确认(Commit 或是 Rollback),MQ Server 收到 Commit 状态则将半消息标记为可投递,订阅方最终将收到该消息;MQ Server 收到 Rollback 状态则删除半 消息,订阅方将不会接受该消息。
在断网或者是应用重启的特殊情况下,上述步骤4提交的二次确认最终未到达 MQ Server,经过固定时间后 MQ Server 将对该消息发起消息回查。
发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
发送方根据检查得到的本地事务的最终状态再次提交二次确认,MQ Server 仍按照步骤4对半消息进行操作。
producer需要一个监听类
import org.apache.rocketmq.spring.annotation.RocketMQTransactionListener;
import org.apache.rocketmq.spring.core.RocketMQLocalTransactionListener;
import org.apache.rocketmq.spring.core.RocketMQLocalTransactionState;
import org.apache.rocketmq.spring.support.RocketMQHeaders;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.messaging.Message;
import org.springframework.stereotype.Component;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;@RocketMQTransactionListener
public class TransactionListner implements RocketMQLocalTransactionListener {Logger log= LoggerFactory.getLogger(TransactionListner.class);//保障线程安全且保证高性能的hashmap,用来记录执行结果private static Map<String,RocketMQLocalTransactionState> transStateMap=new ConcurrentHashMap<>();//执行本地事物@Overridepublic RocketMQLocalTransactionState executeLocalTransaction(Message message, Object o) {//方法里的object o这个对象是生产者发送消息方法最后一个参数的值String transId=(String)message.getHeaders().get(RocketMQHeaders.TRANSACTION_ID);log.info("事物id:{}",transId);try {//模拟执行任务Thread.sleep(10000);//执行成功后记录执行结果transStateMap.put(transId, RocketMQLocalTransactionState.COMMIT);return RocketMQLocalTransactionState.COMMIT;} catch (InterruptedException e) {e.printStackTrace();}//try以外执行失败后transStateMap.put(transId, RocketMQLocalTransactionState.ROLLBACK);return RocketMQLocalTransactionState.ROLLBACK;}//回查@Overridepublic RocketMQLocalTransactionState checkLocalTransaction(Message message) {String transId = (String)message.getHeaders().get(RocketMQHeaders.TRANSACTION_ID);System.out.println("回查消息");return transStateMap.get(transId);}
}
import org.apache.rocketmq.spring.annotation.RocketMQMessageListener;
import org.apache.rocketmq.spring.annotation.RocketMQTransactionListener;
import org.apache.rocketmq.spring.annotation.SelectorType;
import org.apache.rocketmq.spring.core.RocketMQListener;
import org.apache.rocketmq.spring.core.RocketMQLocalTransactionListener;
import org.apache.rocketmq.spring.core.RocketMQLocalTransactionState;
import org.apache.rocketmq.spring.support.RocketMQHeaders;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.messaging.Message;
import org.springframework.stereotype.Component;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;@Component
@RocketMQMessageListener(selectorType = SelectorType.TAG,consumerGroup = "consumer-transaction",topic = "topic15",selectorExpression = "tag1")
public class MQConsumerTransaction implements RocketMQListener<User> {Logger log= LoggerFactory.getLogger(MQConsumerTransaction.class);@Overridepublic void onMessage(User user) {log.info("接收到事物消息:{}",user);}
}@RocketMQMessageListener参数解释
selectorType
过滤标签
SelectorType.TAG ----->selectorExpression = “tagName”
SelectorType.SQL92 --------->selectorExpression =“sql语法条件”
consumerGroup
指定消费者组名称,通常对应一个topic
topic
指定主题
consumeMode
消费类型
ConsumeMode.ORDERLY ------>顺序消息必用
ConsumeMode.CONCURRENTLY--------->其他消息
源码分析
路由中心NameServerNameServer架构设计NameServer启动流程NameServer路由注册和故障剔除消息生产者Producer生产者启动流程生产者发送消息流程批量发送消息存储消息存储流程存储文件与内存映射存储文件实时更新消息消费队列和存储文件消息队列与索引文件恢复刷盘机制过期文件删除机制消息消费Consumer消费者启动流程消息拉取消息队列负载均衡和重新分布机制消息消费过程定时消息机制顺序消费