本文首发微信公众号:码上观世界
网络文件传输的应用场景很多,如网络聊天的点对点传输、文件同步网盘的上传与下载、文件上传到分布式文件存储器等,其传输速度主要受限于网络带宽、存储器大小、CPU处理速度以及磁盘读写速度,尤其是网络带宽。本文主要讨论通常情况下数十GB规模大小的文件传输的优化方式,对于更大规模的文件容量建议考虑人工硬盘运输,毕竟基于公路运输的方式不仅带宽大而且成本低。
文件传输涉及到客户端、中间网络和服务器,常用的传输协议有HTTP(s)、(S)FTP和TCP(UDP)协议等,对于客户端用户来讲,能够起作用的地方不大,所以本文就两种基本的场景来讨论文件传输在客户端的优化方式:基于HTTP协议的非结构化文件传输和基于TCP协议的结构化文件传输。
基于HTTP协议的非结构化文件传输
最常用的文件上传是基于HTTP POST。观察浏览器的请求头数据可知,文件的二进制数据被置于请求body里面,也就是说在上传文件过程中,客户端是一次性将文件内容加载到内存,如果文件过大,浏览器很可能会崩溃,加上HTTP请求连接本身有超时时间限制,所以这种方式不适合传输大文件。
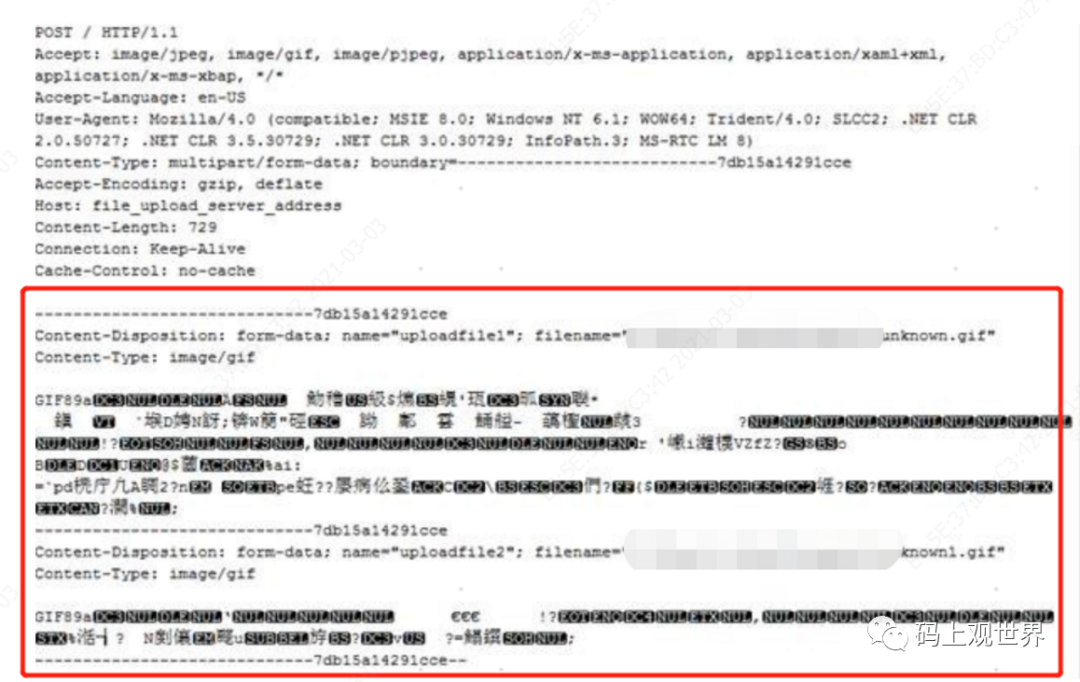
所以一种自然的方式就是手写符合规范的HTTP协议跟服务端通信:
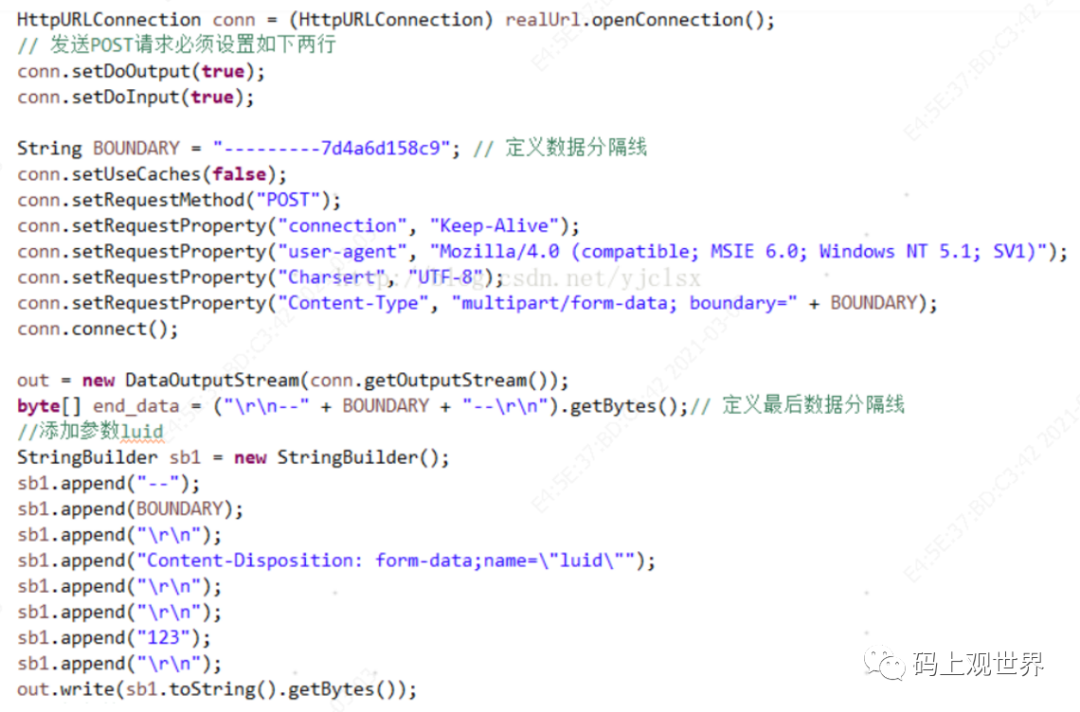
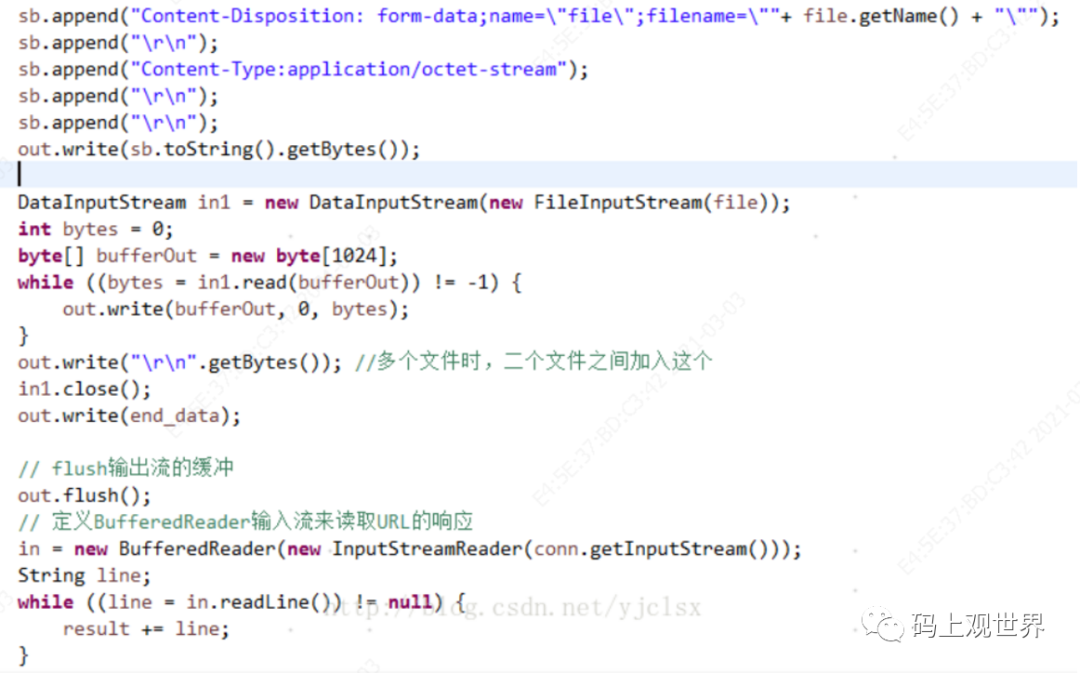
上面的示例代码相比通过浏览器上传文件方式显得自由度更大,但是问题也更多,比如OutputStream将数据写入到PosterOutputStream内部缓冲区,而该缓冲区只有当调用HttpURLConnection的getInputStream方法之后才会发送到Socket流中。所以当文件过大(也许几十MB)就会导致内存溢出,即使通过调用flush方法也无济于事,因为PosterOutputStream的flush方法是空操作,什么都不干!幸运的是HttpURLConnection提供的setFixedLengthStreamingMode方法能够获取到自动刷新流缓存的StreamingOutputStream。虽然这种方式能够解决问题,但是还可能会遇到其他大大小小的坑,而且上述方式还是过于原始,使用Apache HttpClient能够轻易实现上述功能:
HttpClientBuilder httpClientBuilder = HttpClientBuilder.create();
httpClientBuilder.setDefaultCredentialsProvider(credsProvider);
RequestConfig requestConfig = RequestConfig.custom().setCookieSpec(CookieSpecs.DEFAULT).build();
CloseableHttpClient httpClient = httpClientBuilder.build();
File file = new File(filePath);
HttpPut httpPut = new HttpPut(url);
FileEntity fileEntity = new FileEntity(file);
httpPut.setEntity(fileEntity);
FileInputStream fileInputStream = new FileInputStream(file);
InputStreamEntity reqEntity = new InputStreamEntity(fileInputStream, file.length());
//post.setEntity(reqEntity);
HttpResponse response = httpClient.execute(httpPut);
String content = EntityUtils.toString(response.getEntity());
示例代码中,HttpClient帮我们封装了协议相关的所有内容。对于文件传输FileEntity 和InputStreamEntity 都可以使用,不同的是,InputStreamEntity 用了流传输的方式,我们需要做的是就是验证这两种方式是否存在文件过大导致的内存溢出问题。先看FileEntity ,直接翻到代码DefaultBHttpClientConnection :
class DefaultBHttpClientConnection extends BHttpConnectionBase{
......
public void sendRequestEntity(final HttpEntityEnclosingRequest request)
throws HttpException, IOException {Args.notNull(request, "HTTP request");ensureOpen();final HttpEntity entity = request.getEntity();if (entity == null) {return;}final OutputStream outstream = prepareOutput(request);entity.writeTo(outstream);outstream.close();}
......
}
class FileEntity{
......
public void writeTo(final OutputStream outstream) throws IOException {
Args.notNull(outstream, "Output stream");final InputStream instream = new FileInputStream(this.file);try {final byte[] tmp = new byte[OUTPUT_BUFFER_SIZE];int l;while ((l = instream.read(tmp)) != -1) {outstream.write(tmp, 0, l);}outstream.flush();} finally {instream.close();}
}
......
}
再看看InputStreamEntity:
class InputStreamEntity{
......
public void writeTo(final OutputStream outstream) throws IOException {
Args.notNull(outstream, "Output stream");final InputStream instream = this.content;try {final byte[] buffer = new byte[OUTPUT_BUFFER_SIZE];int l;if (this.length < 0) {// consume until EOFwhile ((l = instream.read(buffer)) != -1) {outstream.write(buffer, 0, l);}} else {// consume no more than lengthlong remaining = this.length;while (remaining > 0) {l = instream.read(buffer, 0, (int)Math.min(OUTPUT_BUFFER_SIZE, remaining));if (l == -1) {break;}outstream.write(buffer, 0, l);remaining -= l;}}} finally {instream.close();}
}
......
}
可见FileEntity 和InputStreamEntity使用了相同的outstream,其生成方式为:
class BHttpConnectionBase{
......protected OutputStream prepareOutput(final HttpMessage message) throws HttpException {final long len = this.outgoingContentStrategy.determineLength(message);return createOutputStream(len, this.outbuffer);}protected OutputStream createOutputStream(final long len,final SessionOutputBuffer outbuffer) {if (len == ContentLengthStrategy.CHUNKED) {return new ChunkedOutputStream(2048, outbuffer);} else if (len == ContentLengthStrategy.IDENTITY) {return new IdentityOutputStream(outbuffer);} else {return new ContentLengthOutputStream(outbuffer, len);}}
......
}
这里以ContentLengthOutputStream为例来看数据是如何发送到Socket流中的:
class ContentLengthOutputStream{private final SessionOutputBuffer out;
......public void write(final byte[] b, final int off, final int len) throws IOException {if (this.closed) {throw new IOException("Attempted write to closed stream.");}if (this.total < this.contentLength) {final long max = this.contentLength - this.total;int chunk = len;if (chunk > max) {chunk = (int) max;}this.out.write(b, off, chunk);this.total += chunk;}
}
......
}
class SessionOutputBufferImpl{private OutputStream outstream;
......public void write(final byte[] b, final int off, final int len) throws IOException {if (b == null) {return;}// Do not want to buffer large-ish chunks// if the byte array is larger then MIN_CHUNK_LIMIT// write it directly to the output streamif (len > this.fragementSizeHint || len > this.buffer.capacity()) {// flush the bufferflushBuffer();// write directly to the out streamstreamWrite(b, off, len);this.metrics.incrementBytesTransferred(len);} else {// Do not let the buffer grow unnecessarilyfinal int freecapacity = this.buffer.capacity() - this.buffer.length();if (len > freecapacity) {// flush the bufferflushBuffer();}// bufferthis.buffer.append(b, off, len);}
}
private void flushBuffer() throws IOException {final int len = this.buffer.length();if (len > 0) {streamWrite(this.buffer.buffer(), 0, len);this.buffer.clear();this.metrics.incrementBytesTransferred(len);}
}
private void streamWrite(final byte[] b, final int off, final int len) throws IOException {Asserts.notNull(outstream, "Output stream");this.outstream.write(b, off, len);
}
......
}
class SocketOutputStream {
......public void write(byte b[], int off, int len) throws IOException {socketWrite(b, off, len);}
......
}
通过上面关键代码可见,不管用哪一种Entity,当缓冲区满了就自动flush到Socket,理论上都可以进行大文件传输,只要超时时间允许,两者并没有什么特别的不同。
基于TCP协议的结构化文件传输
基于HTTP协议的文件传输,虽然通过流的方式能解决大文件传输问题,但是基于应用层协议毕竟效率不到,时间消耗仍是个大问题,尽管可以通过文件拆分,并行处理,但需要服务器端的配合才能完成(比如将小文件还原,断点续传等)。这里讨论的多文件传输到分布式系统不需要对服务端再做改造就能直接使用,天然具备并行处理能力。对于结构化文件传输的使用场景多用于数据迁移,比如从数据库系统或者文件系统传输到大数据存储计算平台。这里以将本地的CSV文件上传到HDFS为例,需要解决的是如何对文件拆分。虽然对非结构化,半结构化文件因为涉及到分隔符问题,对于文件拆分有点儿难度,但对规范化格式的文件,问题倒不大,但考虑让问题描述更简洁,这里不考虑文件拆分,只考虑一个文件(比如文件夹下已经拆分后的某个文件)的传输问题。该问题模型可以描述为:
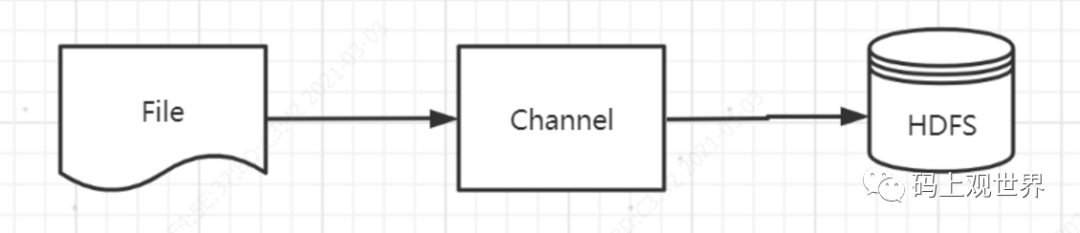
引入Channel是为了解决File和HDFS存取速率不匹配的问题,通过Channel连接File读过程和HDFS写过程:当Channel缓存满的时候,File等待HDFS读取之后再开始写入Channel,HDFS读取之后File再写入Channel,两者通过信号量机制协调,HDFS每次写入都是一个独立的文件。关键代码实现如下:
File端读取数据到Channel:
public void readCSV(String filePath, String fieldDelimiter) {
......BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream, "UTF-8"), 8192);CsvReader csvReader = new CsvReader(reader);csvReader.setDelimiter(fieldDelimiter.charAt(0));String[] parseRows;while ((parseRows = splitBufferedReader(csvReader)) != null) {//Record 为文件中一行数据记录,由Column组成Record record = createRecord(parseRows);this.buffer.add(record);if (this.buffer.size() >= MemoryChannel.bufferSize) {this.channel.pushAll(this.buffer);this.buffer.clear();}}this.channel.pushAll(this.buffer);this.buffer.clear();
......}
//基于内存的Channel实现
class MemoryChannel{private ArrayBlockingQueue<Record> queue;private ReentrantLock lock;private Condition notInsufficient, notEmpty;
......//将File读取端将记录push到Channelpublic void pushAll(final Collection<Record> rs) {Validate.notNull(rs);Validate.noNullElements(rs);try {lock.lockInterruptibly();while (!this.queue.isEmpty()) {notInsufficient.await(200L, TimeUnit.MILLISECONDS);}this.queue.addAll(rs);notEmpty.signalAll();} catch (InterruptedException e) {throw new RuntimeException("pushAll", e);} finally {lock.unlock();}}......
}
class HdfsWriteService{
......
public void writeFile(String fieldDelimiter) {FileOutputFormat outFormat = new TextOutputFormat();outFormat.setOutputPath(jobConf, outputPath);outFormat.setWorkOutputPath(jobConf, outputPath);List<Record> recordList= new ArrayList(MemoryChannel.bufferSize);this.channel.pullAll(recordList);RecordWriter writer = outFormat.getRecordWriter(fileSystem, jobConf, outputPath.toString(), Reporter.NULL);for (Record record : recordList) {//将Record记录组装成HDFS的TEXT行记录,列分隔符可自定义Text recordResult = new Text(StringUtils.join(mergeColumn(record), fieldDelimiter));writer.write(NullWritable.get(), recordResult);}writer.close(Reporter.NULL);
}
......
//基于内存的Channel实现
class MemoryChannel{
......//HDFS写入端从Channel中Pull记录public void pullAll(Collection<Record> rs) {assert rs != null;rs.clear();try {lock.lockInterruptibly();while (this.queue.drainTo(rs, bufferSize) <= 0) {notEmpty.await(200L, TimeUnit.MILLISECONDS);}notInsufficient.signalAll();} catch (InterruptedException e) {throw new RuntimeException("pullAll", e);} finally {lock.unlock();}
}
......
}
上述方式是实现多文件并行传输的基础,每个独立Channel的传输过程互不影响,即使当前Chanel过程失败,也可以独立重跑恢复。
END