1.L1、L2正则——参数空间
L1范数表达式为: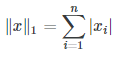
L2范数表达式:
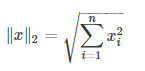
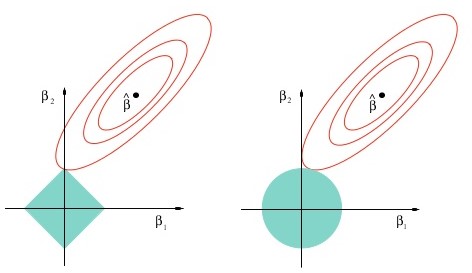
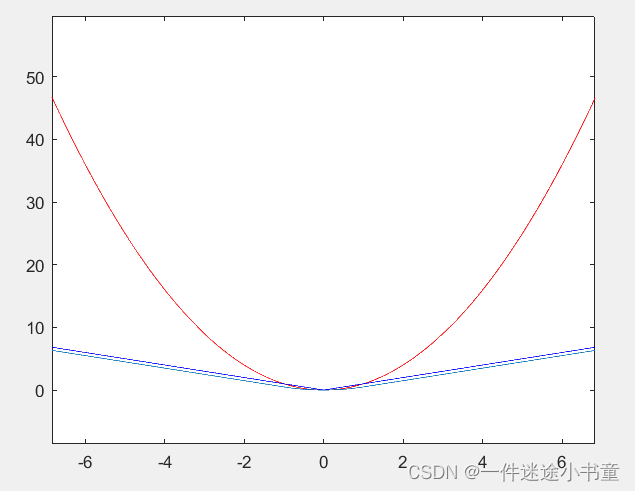
L1正则(上图左),使得某些特征量变为0,因此具有稀疏性,可用于特征选择;
L2正则(上图右),整体压缩特征向量,使用较广。
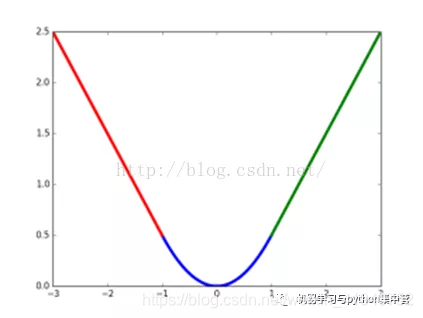
2. L1、L2损失——loss函数
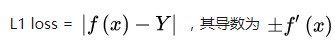

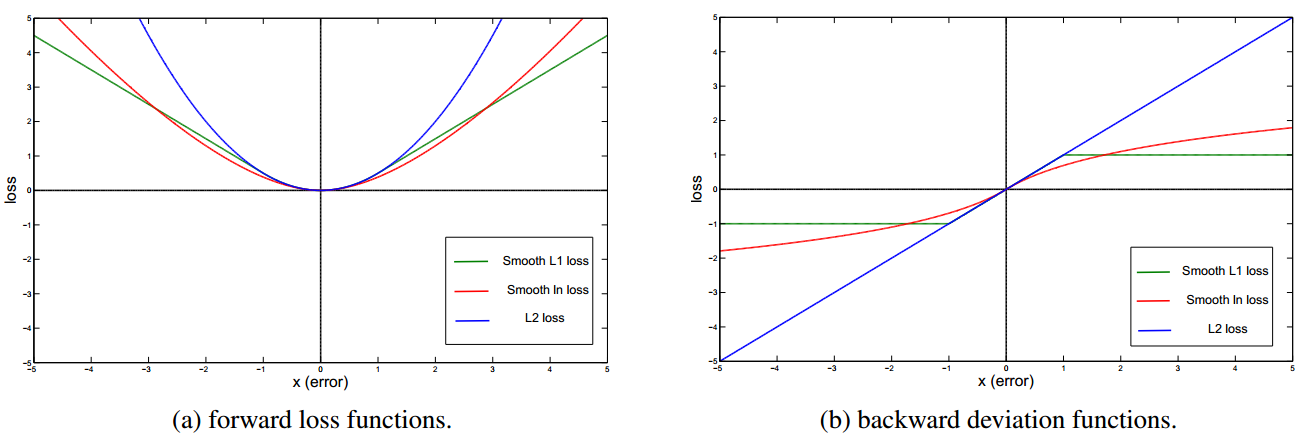
Smooth L1是L1的变形,用于Faster RCNN、SSD等网络计算损失,比较上图绿色曲线和红色曲线,我们可以看到绿色曲线(Smooth L1)的变化相对于蓝色曲线(L2)更缓慢,所以当x发生变化的时候,Smooth L1对x的变化更不敏感,即Smooth L1的抗噪性优于L2。(L1和L2的比较类似,同样L1对于噪声更鲁棒)