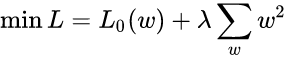文章目录
- 1 正则化
- 1.1 L1正则化
- 1.1.1 为什么L1正则化产生了稀疏矩阵?
- 1.1.2 从导数角度理解为什么L1能产生稀疏矩阵
- 1.2 L2正则化
- 1.2.1 L2为什么就不能产生稀疏矩阵,而是让所有参数的值都相对变小,继而做到权值衰减
- 1.2.2 从导数角度理解L2的权值衰减
- 2 参考
1 正则化
正则化是一种防止过拟合的手段
正则化本质就是在损失函数上加上一个正则项,也称作惩罚项(模型太过复杂,参数过多易过拟合,惩罚参数)。正则化通常有两种方式,分别是L1,L2正则化,对应L1范数,和L2范数
- L1范数(绝对值求和): ∑ i n ∣ w i ∣ \sum_i^n|w_i| ∑in∣wi∣
- L2范数(平方求和): ∑ i n w i 2 \sum_i^nw_i^2 ∑inwi2
正则化的使用一般如下: l o s s = C o s t + R e g u l a r i z a t i o n loss = Cost +Regularization loss=Cost+Regularization
使得loss在正则的约束下最小,其实也是要让正则最小。
1.1 L1正则化
L1正则化可以产生一个稀疏矩阵,从而达到惩罚参数的目的。
稀疏矩阵是指:矩阵中大多参数都是0,其余少数才是非0。
1.1.1 为什么L1正则化产生了稀疏矩阵?
以下,以二维情况为例,只有参数w1,w2。即其L1 = |w1| + |w2|
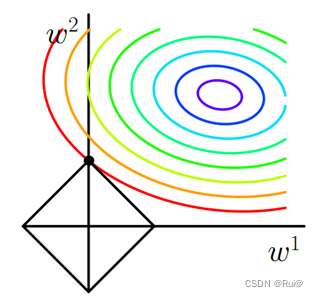
损失函数: l o s s = c o s t + r e g u l a r i z a t i o n loss = cost + regularization loss=cost+regularization
上图中,彩色的曲线圆圈,就是cost的等高线。
所有参数点只要在同一个等高线上,cost就一致。
黑色的矩形,就是L1(regularization)的函数图像
L1正则化的本质是,要让cost在L1惩罚项的约束下(也就是loss),使得cost最小。当cost的等值线与L1图形首次相交的地方就是最优解。
可以看到这个相交的顶点,其中w1=0,w2=w。有0值出现,确实也该如此,当对一组数据求绝对值的和时,想要其值很小,必须有足够多0值。
例如,相交顶点为w1=0,w2=w,若是其他点落在红色等高线上,可以发现 ∣ w 1 + w 2 ∣ > w |w_1 + w_2| > w ∣w1+w2∣>w,只有黑色矩形上的点才 = w =w =w,但是和等高线相交的只有顶点。
上图中是二维的情况,若是多维情况,有多个顶点,并且顶点都在坐标轴上,且离等值线更近,也意味着有参数的值为0,也就是产生了稀疏矩阵。
1.1.2 从导数角度理解为什么L1能产生稀疏矩阵
注:以下推导没有放上学习率
- 损失函数: l o s s = c o s t + α n ∑ i n ∣ w i ∣ loss = cost + \frac{\alpha}{n}\sum_i^n|w_i| loss=cost+nα∑in∣wi∣
- 参数更新: w i + 1 = w i − ∂ c o s t ∂ w i − α s g n ( w i ) n w_{i+1} = w_i - \frac{\partial cost}{\partial w_i} - \frac{\alpha sgn(w_i)}{n} wi+1=wi−∂wi∂cost−nαsgn(wi)
- 当w大于0时,更新的参数w变小;当w小于0时,更新的参数w变大;所以,L1正则化容易使参数变为0,即特征稀疏化。
1.2 L2正则化
L2正则化不能产生一个稀疏矩阵,但是可以使得参数值都比较小。
1.2.1 L2为什么就不能产生稀疏矩阵,而是让所有参数的值都相对变小,继而做到权值衰减
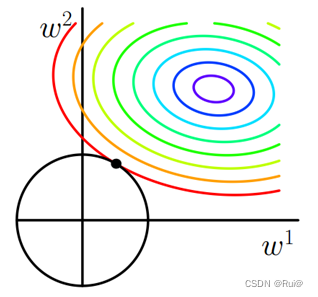
L2正则化的公式是绝对值的平方,也就是圆形的函数公式,如上图所示。同理,相交的点就是 w 1 2 + w 2 2 w_1^2 + w_2^2 w12+w22的最小点。
其余点,若是在等高线上那么比这个相交点的 w 1 2 + w 2 2 w_1^2 + w_2^2 w12+w22大,若是在黑色圆上和相交点的 w 1 2 + w 2 2 w_1^2 + w_2^2 w12+w22相等但又不在等高线上。
1.2.2 从导数角度理解L2的权值衰减
注:以下推导没有放上学习率。
- 损失函数: l o s s = c o s t + α 2 ∑ i n w i 2 loss = cost + \frac{\alpha}{2}\sum_i^nw_i^2 loss=cost+2α∑inwi2
α \alpha α是一个超参数(取 0-1),主要是调和cost和正则项的比列,二分之一,是为了求导后,消除2
- 没有加正则项的参数更新: w i + 1 = w i − ∂ c o s t ∂ w i w_{i+1} = w_i - \frac{\partial cost}{\partial w_i} wi+1=wi−∂wi∂cost
- 加正则项后的参数更新: w i + 1 = w i − ∂ l o s s ∂ w i = w i − ( ∂ c o s t ∂ w i + α ∗ w i ) w_{i+1} = w_i - \frac{\partial loss}{\partial w_i} = w_i -(\frac{\partial cost}{\partial w_i} + \alpha* w_i) wi+1=wi−∂wi∂loss=wi−(∂wi∂cost+α∗wi)
化简之后: = w i ( 1 − α ) − ∂ c o s t ∂ w i =w_i(1 - \alpha) - \frac{\partial cost}{\partial w_i} =wi(1−α)−∂wi∂cost
观察化简之后的公式,可以发现和没加L2的相比, w i w_i wi多了一个衰减 ( 1 − α ) (1 - \alpha) (1−α),让其参数多了一个数值上的衰减,使得模型能够防止过拟合。
2 参考
机器学习中正则化项L1和L2的直观理解
比较全面的L1和L2正则化的解释