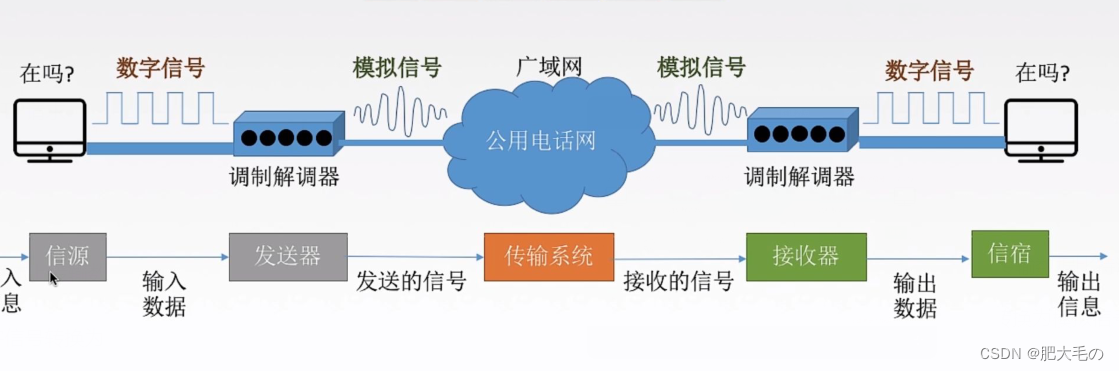
以下是由陈若非博士,在RTC2016 实时互联网大会上的演讲实录
陈若非,现在任职声网Agora.io的音频技术,负责整个音频技术架构。在香港城市大学读博士期间是音频方面的诸多重要会议和期刊的主编。这位同学在以前的工作经验里积累了大量关于音频的降噪、混合、双麦等等这方面的工作经。

大家下午好,很高兴今天有机会和大家分享一下:让我们的APP实现实时语音功能时,我们需要做哪些测试?要怎么样做这些测试才能保证上线后是稳定没有问题的。
有的开发者说,他们自己做了实时语音的功能,在自己的测试中觉得没有问题,在公司测得都很好,也通过了。上线后,收到很多用户反馈:为什么你的语音这么卡,为什么有回声,为什么会有杂音?。他们才发现这些问题其实并不是这么容易定位的,也不能像平时我们解BUG那样快速修复这样的问题。再追溯回来他们发现这背后跟很多网络相关的优化、音频底层的算法都有很大的关系,这一块他们自己也解决不了,所以就会出现比较尴尬的局面。所以,希望在今天的演讲之后可以给大家一些更丰富的手段,帮助大家去评估一下自己手里的音频引擎效果是怎么样的。
首先,我们来讲讲实时语音的发展。我相信大家对实时语音这样的功能应该比较了解。实时语音发展已经有几十年的历史,近几年越来越多的APP提供了这个功能,包括微信、陌陌。越来越多的用户愿意使用实时语音功能,从侧面说明一个问题,实时语音这个功能已经达到可以商业化的地步了。
这背后,我们这两年网络基础设施的升级,智能终端设备的更新换代,包括现在流行的WebRTC技术的快速发展,都为实时语音野蛮省长提供非常肥沃的土壤。我们非常高兴地看到,除了社交之外,游戏、直播、在线医疗、在线教育这些行业对实时语音需求都是非常强烈。
那么问题来了,当我们有一个语音引擎在手里,我们已经调通了,出声了,到上线究竟还有多远?这个问题其实是见仁见智的。我们跟一些开发者打交道下来,听到比较多的两种声音是:我现在就想做视频应用,看脸的世界,出声就可以;还有一种,我觉得音频很重要,但是我不知道怎么测?我要如何来做测试才能保证上线后的稳定?要回答这两个问题我们首先来看一下我们实时语音到底有哪些特征?
实时语音到底有哪些特征?
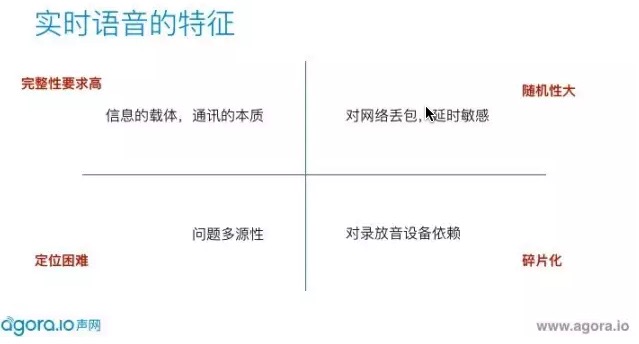
首先,实时语音的完备性要求非常高。我们不可否认语音是沟通的本质,是信息的载体。如果我们在通话中语音信息丢失了,这个对话是根本不能继续下去的。这实际上说明了,我们首先对实时语音的完备性要求是非常高的,而且用户对这部分的音频问题容忍度是非常低的。
第二,实时语音其实是随机性很大。我们要做基于互联网的实时语音,也决定了我们绕不开网络的丢包、延时的问题,所以这部分又决定了实时语音其实是随机性很大的。
第三,问题的多元性。这个问题怎么解释?举个例子,大家平时有人会给你报你的语音卡顿,到底是什么原因?你首先想到的肯定是网络,网络会卡顿。其实还有别的原因会引起卡顿,比如设备CPU负荷很高时,录放音调度有问题,也会导致声音的卡顿。更隐性的问题,比如回声消除,两个人同时说话时,这边开着外放,收回去的时候两个声音混在一起,过程中会有损伤,造成断续。通过这些例子,可以想见,实时语音的问题很难去定位。
最后,对录放音设备的依赖。我们每个人都有自己的嘴和耳朵,设备也一样,有扬声器和麦克风,而且它还有更多的外设。所以,其实最后的听感体验很大程度受到录放音设备的制约,这也决定了音频的问题其实是碎片化的。
我们可以看到,这四个问题其实都是很难搞的问题,这也决定了用喂喂喂或者简单几次测试不可能很好覆盖整个音频测试。
来总结一下,我们这里把影响语音质量的因素分为三类:
网络问题:丢包,或者抖动,都会导致听感滞后或者断续;
设备问题:很突出,在一些低端的安卓机上,声学设计并不理想。扬声器之间的耦合很大,或者扬声器的非线性很大,导致你的算法不能很好贯通在上面,导致听感上有一些卡顿、毛刺的问题。
物理环境:比如我在一个很吵的环境和你打电话,或者我在很小的房间跟你打电话感觉是不一样的;还有远场拾音,比如做电视应用,必须要在2米以外收音,这个时候麦克风的拾音效果决定了音频听到的体验。
这么多复杂的问题,业界一般怎么处理?
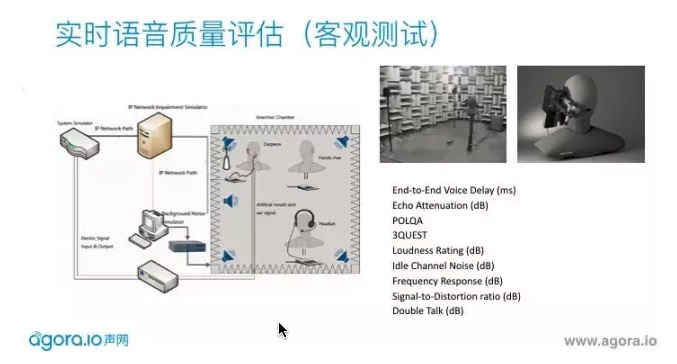
手机公司会有很大的消声室,是用来规避一些不确定外界声源的影响。还需要有人工头、人工嘴和人工耳做高保真的放音和收音,四周有高保真的音响放出自由场的噪声源,模拟不同网络状况。会测试回声,语音在干净或噪声环境下的得分,双降的性能。每个手机出场之前都会做这样的测试。
但这一般开发者来说门槛很高,这样一套设备很贵,我们有没有更经济合理的方法做测试?
我们也总结了一下,声网在实践中觉得比较适合开发者自己去做,在上线前自测的一些方法,这里也按我们之前提到的三个归类,网络、设备和物理环境讲一下。
首先,网络部分。
有TC跟NetEM,都可以模拟,如果具体步骤不清楚的同学,可以查看这个教程。
你还在靠“喂喂喂”来测语音通话质量吗,看完这篇文章你就能掌握正确姿势。
这里面可能不能涵盖所有的丢包,但是基本上也能测到语音在不同丢包下的表现,可以测到引擎的极限在哪里。声网的引擎基本现在做到在TC下,30%的丢包是无感的,70%的丢包可以正常的通话。
还有一个比较重要的是:跨运营商的测试。这一点很多客户是不重视的,自己在公司内用P2P测觉得很好,一上线就有很多问题。在中国,跨运营商的丢包,或者2G、3G、4G移动网络下会有很多问题,建议大家在这方面做足够测试再上线。
其次,设备的问题。
大家在一些平板电脑测试觉得声学很好,调的也很好,底层也有算法。但是,到安卓之后就变得非常的麻烦。很多低端的安卓机,底层录音的通路没有调好,底噪很大。而且,声学设计不够好,有很多非线性的问题需要适配。而这些问题如果只是在一个比较高端的机器上测,可能是不会体现的。所以,如果你的目标用户中有很多这样的机型,那么一定要在测试中把这一块覆盖好。同时,在听筒、耳机、外放、蓝牙,也需要去测,这些都是会影响用户的体验的细节。、
第三,物理场景。
我们其实没有办法覆盖非常多的场景,建议去下载一些语音降噪的序列、噪声的序列,是免费的,可以在不同的信噪比情况下用来测试。远场拾音,只要测一下不同的说话距离就能感觉到不同的体验。
我相信通过这三步的测试,你的语音引擎是基本可用的。
另外,稍微讲一下一些技术细节。

我们常说的3A引擎是指:回声消除、降噪和自动增益控制,这是所有音频引擎中必须有的模块。在测回声时,需要留意降完回声之后残留的程度;双讲透明度,就是两个人同时说话的时候会有多少声音可以透过去;稳定性是指在安卓上这些CPU比较高的情况之下可以稳定运行的一个时间,收敛时间。 降噪,我降噪完声音的残留噪声的程度和收敛时间。自动增益控制关注两个点,第一收音距离多远,第二,你把声音推大,杂音也会推大,这个部分有没有做特殊的处理?不然有人会说,你的这个声音是很大,但是背景音一起推起来了,这时需要一些算法来做的更好。如果在1米、2米情况下不用AGC声音已经非常小,这里面必须有算法支持它。

上图的三个算法也是比较特殊场景下的算法,声网在这三块也做了比较多的工作。
可懂度增强:如果我在很噪杂的环境,对方传过来的声音是不吵的,但是我听着还是很累,因为我旁边有很多让我分心的声音。这个时候,我们需要去评估现在的环境下的有多噪杂,从而调整下行的信号让你听得更清楚。
盲源分离:指的是我们刚才的降噪说得是平稳噪声,对应在数学上也是用统计模型来做。但是在非平稳信号下,可能需要有多麦技术来定位主讲人声源在哪,主要收主讲人的声音,其他的声音屏蔽。
啸叫抑制:真实环境中并不是很多。在做音频测试时,如果两个手机开着外放,你就会听到很尖锐的杂音一直响。这怎么办?其实很简单,只要把一台插上耳机,把回环的通路打断就不会叫。声网自己做了啸叫抑制的模块,两个手机都外放,即使不插耳机,我们也会把检测到的尖锐杂音自动压下来。
如果做的应用是比较特殊的场景,比如直播、游戏,我们还有特殊的点需要注意。
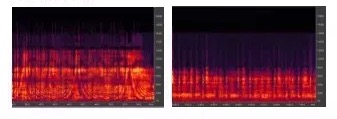
做直播,推流基本用44.1K,但声音有效采样取到多少才是真正重要的。左图是32K的采样,右图那个虽然是44.1K的声源,但其实有效频率是8K,实际听到的声音会变闷的。
ASMR,就是用立体声录音去给听众听到空间感的音频。那声网在手机平台上,第一个做到立体声录音和播放。这意味着,主播可以现在拿着这个立体声的设备走到街上,一辆车开过去,其实直播的听众戴了耳机就能感觉到从左到右的效果。
再讲一下游戏,很特殊的场景。拿一个枪战类的游戏举例,在3D环境里可以听到周围有队友开枪,可以听到哪边交火。如果玩家开了实时语音,自己开着外放。那么玩家开枪的声音通过他的外放再被收回去,这部分回声消除由于没有参考信号就做不了。这个声音传过去会影响对方的判断,直接降低玩家的游戏体验。
上线只是一个开始,上线之后,语音的碎片化问题还会不断出现。那么就需要做两方面的统计。
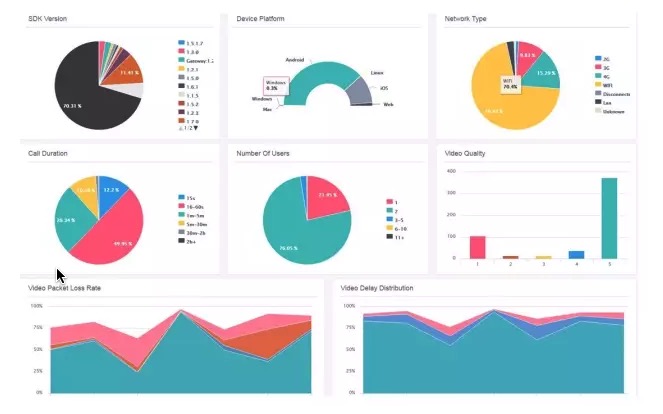
全局监控。来反馈全局质量,是不是大部分用户都比较好?上图是声网做的一个统计,反应每天使用用户大概比例,用什么网络什么系统,音频视频打分如何,丢包率如何?如果你不是使用声网的服务,你自己也需要做这样一套系统,来改进服质量 。
个例分析。全局反馈良好,但依然有用户报问题,我的声音听不到怎么办?声网在实践当中做了这样一套系统,可以根据用户ID去查详细的通话信息:包括一些码率、CPU的情、音频录音大小可以自己看得到,这样子就能定位问题。
以下是现场提问
提问:我问一个关于降噪的问题,你刚才的演示PPT里面没有很清楚,降噪之后背景噪声是消除越干净越好?还是应该是有一定的率?
陈若非:降噪有一个很大的问题,你压得越多噪声越低,语音失真也越大,这是必然的。如果你有一个噪音,失真率很小,如果压得很多,非常干净,这个声音频率上会特别高,听起来尖尖的,不是很舒服。所以这需要你在实践中自己去调到一个你认为最好的点,没有绝对,我不知道这样回答有没有回答你的问题?