转载请注明出处:http://blog.csdn.net/c602273091/article/details/53529384
-
-
-
- Why VM
- VM Translation
- Some tips
-
-
18-600快要考试了,在博客中把学过的东西整理一下思路,写到博客里也好以后自己有空看看,希望对以后的人也有所帮助。至于这门课的Lab的代码,等我考完试就把它放上来。
本次复习的重点如下:

我感觉考试的重点就是都是重点,23333~ 话不多说,今天就开始讲我最不熟悉的部分:虚拟内存(Virtual Memory)。
在鄙人的印象中,CPU和存储器之前是通过总线连接,根据某些协议进行通信,I2C,或者别的什么协议的。在进行数据传递的时候,就需要传递地址。我觉得传递的就是直接的物理地址,如下图:

想起那个时候写HDL的Cache都是这么来的。
但是我在上课的时候,我发现我理解错了。其实CPU发给Memory的是虚拟地址、Memory接到的是物理地址、它们之间有一个叫做MMU的东西。就是把虚拟地址转换成物理地址,再进行数据的传递。如下图所示:

从这里我们可以看出,从VA到PA之间其实是有一个映射函数在这里面,把VA映射到PA。那么这里我们就要提问题了,为什么要加VA呢?怎么映射的呢?
首先回答第一个问题:Why VM?
Why VM?
看解释。

第一个是说可以通过VM,使得DRAM成为VAP的一部分。一般来说呢,VA的地址空间比PA大很多,这里的物理地址是Cache或者是DRAM。
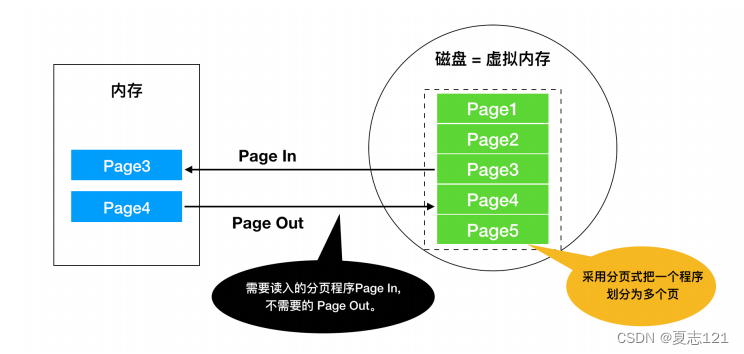
在最早的存储金字塔我们可以知道DRAM不命中的后果是比SRAM严重得多,差不多是4个数量级的差别。所以我们需要尽可能增加DRAM的命中率。在物理级别,DRAM其实可以看做是磁盘的Cache。那么我们在这里采取VM,其实可以看成是磁盘的一种地址映射。从更高的维度去获取DRAM的数据,可以非常灵活,比如VM中的虚拟页可以映射到任何一个DRAM中的物理页。如果调度合理的话,将可以极大降低MISS。
在这里,为了使得VM和PM之间的数据映射更加灵活,采取了一种分页的方法。这种方法把VM和PM分成固定大小的页,这些页形成了一种叫做页表的东西。如果页的大小不一样的话,那么做映射的时候其实会更复杂一些。我觉得如果页的大小可以随机变化的话,一方面是增加了维护成本,复杂度等等;但是另外一方面我觉得如果可以页的大小自己设定的话,那么就可以计算当前运行程序的一个working set,把需要的页面加载进去PM,增加Hit的概率,减小Miss。在这里呢,需要额外说一下工作集:就是程序运行时的较小的活动页面。如果在工作集里运行,那么Hit非常高。否则就会有颠簸,页面会频繁地page in and out。

页表包含了VP和PP的映射关系。通过页表这样的一个映射,那么VM和PM就联系了起来。页表中每一项都有一个地址和它的值。它的地址当然就是对应VP(虚拟页面),存储的值就是PPN。
比如现在CPU传了一个虚拟地址,然后虚拟地址就找到对应页表中的PPN(物理页号),然后在由虚拟地址和物理页号找到最终的物理地址。如果没有找到的话,就需要在PM加载所需要的页,再增加到PT。再运行一次刚才的请求。怎么样确定所需要的页呢?(等我学了神课Operating System再说)在这里,我只是一笔带过地址翻译,具体的涉及到了MMU、TLB的细节的请看下面的VM Translation。
现在我们来说说VM的第二个作用:存储器管理。
每个进程都有自己的虚拟地址空间,它们自己的虚拟地址空间可以任意映射到物理地址空间。那么这样你可以发现不少好处,比如简化链接,在我们的进行链接的时候,每个进程都可以从自己空间的同一个地址开始加载,当然它们外面有一个基地址作为区别。这样的话,进程加载就可以从自己的虚拟地址空间的同一个起始地址开始,大大降低了链接的难度。另外呢,我们进行数据共享的时候更方便,想想如果没有VM,所有的数据直接引用DRAM里面,然后好几个进程引用同一个物理页,那么引用的时侯地址都是不连续的。不像VM一样,在程序员角度看来地址都是连续的。不连续的话就会导致跳转增加,而且容易导致程序混乱,不方便管理。还有就是采用分页呢可以方便内存管理,写过Malloc的同学应该都了解外部碎片,那么采用了分页呢,可以减少外部碎片。然后使用VM呢,可以使得Malloc内存的时候,不一定需要连续的内存,可以映射到K个任意页面。这样也是减少了外部碎片。
第三个作用就是作为存储器保护工具。具体的就是在每个虚拟页之前加入访问权限,其实就是加入了几个bits(SUP、READ、WRITE、EXEC)。其实我觉得这个功能说起来有点儿牵强,其实在PM里同样也可以这么加。我看不出在VM加如这个就能有这个特殊性。

通过以上介绍,VM确实有很多好处,当然也必须看到它所带来的一些Memory的cost,以及为了维护PT、地址翻译等等需要不少的额外。
其实VM我觉得还有一个好处,它可以使得一个很大的存储器(比如很多磁盘的组合)协同工作。通过VM可以使得很多的细节被掩藏了起来,我们不需要知道背后的内存系统。我们只需要对于VM进行操作即可。
虽然刚刚说我们编程不需要对VM背后的内存系统进行了解,但是对于地址翻译这个,我觉得说一下还是有好处的。
VM Translation
地址翻译:把虚拟地址映射成物理地址。也就是给你一个虚拟地址,映射关系(页表),你得知道它的物理地址。
首先,了解一些基本概念。

然后我来说一下地址翻译的过程。
首先是逻辑层面。

上图中就是说给了一个虚拟地址(VPN+VPO),根据VPN,去找到页表的相应PPN。如果invalid,那么就先加载这一页到PM,再更新PTE。
在硬件层面,CPU发虚拟地址给MMU,MMU解析出虚拟页号,然后发送给Cache/DRAM。然后在Cache中存着页表,找到之后发回给MMU。如果没找到,就从磁盘中加载。在这之后,MMU把虚拟地址的offset和Cache发给MMU的物理页号合并之后发给Cache,Cache把数据取出,发给了CPU。
命中->

缺页->

聪明的你应该发现了MMU为了获取物理页号和Cache/memory有一个通信,这是比较消耗cycle的。所以就有了TLB(Translation lookaside buffer),是由VPN、PPN、valid bit组成。其实我觉得它就是page table的一个cache。TLB和VPN、PTE的关系:把虚拟地址的虚拟页号分成TLBT、TLBI。VPO就是PPO。

在增加了TLB之后的page hit和page fault的情况。
page hit->

page fault->

在使用了TLB之后,我们可以加速Address Translation。但是我们遇到了另外一个问题:采取单级PT会使得PT的大小就非常大。那么就有了MPT。这种思路就可以让我们把需要的大页面加载到内存中,这里已经有了partition的思想在里面。

接下来举一个具体的例子,看一下虚拟地址是如何从VA、TLB、PT、PA这个心路历程。
1、虚拟地址和物理地址的表示:14位的虚拟地址,12位的物理地址。页大小是64bytes。那么计算得出offset就需要6个bits。那么剩下的VPN就是8bits。

2、TLB的组成:4组4路的Cache。因为是4组,那么就需要2bit做索引。剩下的6个bits那么就是tag了。

3、页表:因为虚拟页号是8 bits,那么就可以用256个页。我们只看前16个页(主要是为了做题)

4、PM中的Cache:

以上的PPT里面就有一个例子,给出了VPN,它是如何从TLB取出所需的值。然后如果TLB miss的话,就从PT取出值。如果PT miss的话,就从Cache/DRAM调入新的页面。更新PT、TLB。
Some tips
1、寻址方式:字节寻址
2、在换页的时候采用的是write back的方式。
3、page fault的情况:invalid和access deny

以上PPT的截图来自于课程CMU15-213的主页:CMU 15-213主要是这门课还是CSAPP的作者讲的。
其实我在上的是CMU 18-600,如果你想了解更多关于处理器比如Superscala的东西的话,请看:CMU 18-600 其中讲课的人还有一个是我的导师,在做处理器方面很牛逼的老师。