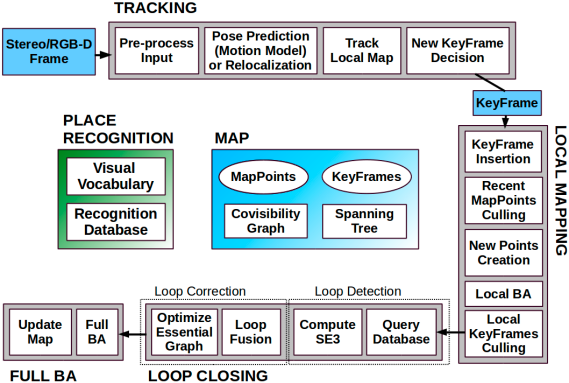
今日课程大纲: 01 上周内容回顾 02 闭包 03 装饰器 04 可迭代对象 与 迭代器 05 生成器 06 生成器表达式 列表推导式 07 匿名函数 08 内置函数
01 上周内容回顾
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 """ 4 深浅copy: 5 浅copy:内存中创建一个新列表,但是列表里面的内容还是沿用之前的指向关系。 6 深copy:内存中创建一个新的列表以及可变的数据类型,不可变的数据类型沿用之前的指向关系。 7 8 文件操作: 9 path,encoding mode 10 读 r rb r+ r+b 11 r: 12 read() 13 read(n) 14 readline() 15 readlines() 16 for 循环 --- 最好的方式 17 18 写 w wb w+ w+b 19 w:没有文件创建文件,有文件清空内容,在写入。 20 21 追加:a a+..... 22 a:没有文件创建文件,有文件在文件末尾追加内容。 23 24 f = open(path,encoding='utf-8',mode='r') 25 f.read() 26 f.close() 27 28 with open(path,encoding='utf-8',mode='r') as f1, open() ... as f2: 29 f1.read() 30 f2.write() 31 32 tell() 33 seek() 34 truncate() --截取原文件,必须可写的模式下 35 readable() 36 writable() 37 f.flush() 38 39 文件的改的操作: -- 一定要会,重点 40 5步 41 42 函数: 43 1,一个函数封装一个功能。 44 45 2,基本结构 46 def func(参数): 47 函数体 48 49 执行:func() 50 51 函数的返回值: 52 return: 53 1,结束函数。 54 2,给函数的执行者func()返回值。 55 return None 56 return 单个值 57 return 多个值 1,2,[1,2,3] 58 func() ---> (1,2,[1,2,3]) --- 返回值是一个元组 59 60 函数的参数: 61 def func(参数): --形参 62 函数体 63 func(参数) --实参 64 65 1,实参: 66 a, 位置参数:从左至右一一对应。 67 b, 关键字参数:name='alex' 一一对应。 68 c, 混合参数。关键字参数一定要在位置参数后面。 69 2,形参: 70 a, 位置参数:从左至右一一对应。 71 b, 默认参数。一定要放在位置参数后面。 72 c, 万能参数。*args,**kwargs。 73 形参角度参数顺序: 74 位置参数,*args,默认参数,**kwargs 75 76 def func(*args,**kwargs): 函数的定义:*代表聚合。 77 print(args) 78 print(kwargs) 79 func(*[1,2,43],**{'name':'alex'}) # 函数的执行:*代表打散。 80 81 名称空间:全局名称空间:变量与值得对应关系。 82 局部名称空间:临时名称空间。 83 内置名称空间:存放的是内置函数等。 84 85 加载顺序:内置名称空间 全局名称空间 临时名称空间 86 取值顺序:就近原则。 87 88 globals() locals() 89 90 函数的嵌套: 91 pass 92 93 函数名的应用: 94 1,函数名是一个特殊的变量。 95 2,函数名可以作为容器类数据类型的元素。 96 3,函数名可以作为函数的参数。 97 4,函数名可以作为函数的返回值。 98 99 global nonlocal 100 """ 101 102 # 函数的嵌套 103 # def func(): 104 # print(123) 105 # 106 # def func1(): 107 # func() 108 # print(222) 109 # 110 # def func2(): 111 # func1() 112 # print(333) 113 # 114 # print(4) 115 # func2() 116 # print(5) 117 # # 4 123 222 333 5 118 119 # def wrapper(): 120 # print(1) 121 # def inner(): 122 # print(2) 123 # print(3) 124 # inner() 125 # print(4) 126 # print(5) 127 # wrapper() 128 # print(6) 129 # # 5 1 3 2 4 6
02 闭包
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 """ 4 # 什么是闭包: 5 # 1,闭包存在于函数中。 6 # 2,闭包就是内层函数对外层函数(非全局变量)的引用。 7 # 3,最内层函数名会被逐层的返回,直至返回给最外层。 8 """ 9 # 不是闭包,name 是全局变量 10 # name = 1 11 # def func(): 12 # print(name) 13 14 # 这才是闭包 15 # def func(): 16 # name = 'alex' 17 # def inner(): 18 # print(name) 19 # return inner 20 # ret = func() 21 # print(ret.__closure__) #如果返回cell,就证明是一个闭包。返回None 就不是闭包 22 # print(ret.__closure__[0].cell_contents) 23 24 # 这也是闭包 25 # def func(name): 26 # # name = 'barry' #name参数 相当于这行代码 27 # def inner(): 28 # print(name) 29 # return inner 30 # n1 = 'barry' 31 # ret = func(n1) 32 # print(ret.__closure__) 33 34 35 #闭包的作用 36 # 解释器遇到闭包,会触发一个机制,这个闭包不会随着函数的结束而释放 37 38 # 不是闭包的情况,函数里面定义的变量会随着函数的结束而释放 39 # def func(step): 40 # num = 1 41 # num += step 42 # print(num) 43 # for i in range(5): 44 # func(2) 45 # # 3 3 3 3 3 46 47 48 # 闭包情况下:不会随着函数的结束而释放 49 # def func(step): 50 # num = 1 51 # def inner(): 52 # nonlocal num 53 # num += step 54 # print(num) 55 # return inner 56 # f = func(2) 57 # for i in range(5): 58 # f() 59 # # 3 5 7 9 11 60 61 62 # 闭包举例 爬虫 63 # from urllib.request import urlopen 64 # def but(): 65 # context = urlopen("http://www.cnblogs.com/jin-xin/articles/8259929.html").read() 66 # def get_content(): 67 # return context 68 # return get_content 69 # fn = but() 70 # content = fn() #获取内容 71 # print(content.decode('utf-8')) #中文显示 72 # content2 = fn() 73 # print(content2.decode('utf-8'))
03 装饰器
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 # 装饰器 5 # 需求:测试其他函数的执行效率 6 7 # 第一版:写一个功能测试其他同事的函数执行效率 8 # import time 9 # def func(): 10 # time.sleep(0.2) 11 # print('非常复杂') 12 # 13 # def func1(): 14 # time.sleep(0.3) 15 # print('超级复杂') 16 # 17 # 如果被测试的函数很多的话,代码不能重用,会冗余 18 # start_time = time.time() 19 # func() 20 # end_time = time.time() 21 # print('此函数耗时秒数 %s' % (end_time - start_time)) 22 23 24 # 第二版:函数实现这个功能 25 # import time 26 # def func(): 27 # time.sleep(0.2) 28 # print('非常复杂') 29 # 30 # def func1(): 31 # time.sleep(0.3) 32 # print('超级复杂') 33 # 34 # def timmer(f): 35 # start_time = time.time() 36 # f() 37 # end_time = time.time() 38 # print('此函数耗时秒数 %s' % (end_time - start_time)) 39 # 40 # timmer(func) 41 # timmer(func1) 42 # 假如函数有1500个,那么你1500个timmer(func),工作量很大 43 # 你要在不改变函数执行的指令下,同时测试效率 44 45 46 # 第三版:在不改变函数的执行方式下,同时测试执行效率 47 # import time 48 # def func(): 49 # time.sleep(0.2) 50 # print('非常复杂') 51 # 52 # def func1(): 53 # time.sleep(0.3) 54 # print('超级复杂') 55 # 56 # def timmer(f): 57 # start_time = time.time() 58 # f() 59 # end_time = time.time() 60 # print('此函数耗时秒数 %s' % (end_time - start_time)) 61 # 62 # f1 = func 63 # func = timmer 64 # func(f1) #timmer(func) 65 66 67 # 第四版:装饰器雏形 68 # import time 69 # def func(): 70 # time.sleep(0.2) 71 # print('非常复杂') 72 # 73 # def func1(): 74 # time.sleep(0.3) 75 # print('超级复杂') 76 # 77 # def timmer(f): #f = func 函数名 78 # def inner(): 79 # start_time = time.time() 80 # f() 81 # end_time = time.time() 82 # print('此函数耗时秒数 %s' % (end_time - start_time)) 83 # return inner 84 # 85 # func = timmer(func) #执行timmer函数,将func函数名传给f。等到返回值inner函数名,所以func --> inner 86 # func() 87 88 89 # 第五版:装饰器雏形的优化,语法糖@ 90 # import time 91 # def timmer(f): #f = func 函数名 92 # def inner(): 93 # start_time = time.time() 94 # f() 95 # end_time = time.time() 96 # print('此函数耗时秒数 %s' % (end_time - start_time)) 97 # return inner 98 # 99 # @timmer # func = timmer(func) 100 # def func(): 101 # time.sleep(0.2) 102 # print('非常复杂') 103 # 104 # #func = timmer(func) #执行timmer函数,将func函数名传给f。等到返回值inner函数名,所以func --> inner 105 # func() 106 107 108 # 其他:被装饰函数带有参数 109 # import time 110 # def timmer(f): 111 # def inner(*args,**kwargs): # 函数的定义: * 聚合 args = (1,2,3,444,) 112 # start_time = time.time() 113 # f(*args,**kwargs) # 函数执行: * 打散 f(*(1,2,3,4,5,6,)) 114 # end_time = time.time() 115 # print('此函数耗时秒数 %s' % (end_time - start_time)) 116 # return inner 117 # 118 # @timmer # func = timmer(func) 119 # def func(a,b): 120 # time.sleep(0.2) 121 # print('非常复杂 %s %s ' % (a,b)) 122 # 123 # func('aaa','bbb') 124 125 126 # 其他:被装饰的函数要有返回值 127 # import time 128 # def timmer(f): 129 # def inner(*args,**kwargs): 130 # start_time = time.time() 131 # ret = f(*args,**kwargs) 132 # end_time = time.time() 133 # print('此函数耗时秒数 %s' % (end_time - start_time)) 134 # return ret 135 # return inner 136 # 137 # @timmer # func = timmer(func) 138 # def func(a,b): 139 # time.sleep(0.2) 140 # print('非常复杂 %s %s ' % (a,b)) 141 # return 666 142 # 143 # ret = func('aaa','bbb') 144 # print(ret) 145 146 147 # 装饰器常用格式 148 # def wrapper(f): 149 # def inner(*args,**kwargs): 150 # """执行被装饰函数之前的操作""" 151 # ret = f(*args,**kwargs) 152 # """执行被装饰函数之后的操作""" 153 # return ret 154 # return inner 155 # 156 # @wrapper 157 # def func(): 158 # print(333) 159 # 160 # func() 161 162 163 # 装饰器小结 164 # 其实装饰器本质是闭包,他的传参,返回值都是借助内层函数inner, 165 # 他之所以借助内层函数inner 就是为了让被装饰函数 在装饰器装饰前后,没有任何区别。 166 # 看起来没有变化。 167 168 169 # 装饰器用途: 170 # 登录认证,打印日志等等。给函数增加额外的功能,但是不能影响函数的执行方式,返回值等 171 # 172 # 日志 173 # def wrapper(f): 174 # def inner(*args,**kwargs): 175 # print("记录日志开始") 176 # ret = f(*args,**kwargs) 177 # print("记录日志结束") 178 # return ret 179 # return inner 180 # 181 # @wrapper 182 # def func(a,b): 183 # print('我是被装饰的函数') 184 # return a + b 185 # 186 # ret = func(1,2) 187 # print(ret) 188 189 190 # 登录认证 191 # 需求 三个页面需要登录才能访问,只要有一次登录成功就能访问 192 # 193 # flag = False 194 # 195 # def login(): 196 # username = input("账号>>>:") 197 # password = input("密码>>>:") 198 # if username == "alnk" and password == "123": 199 # print('登录成功') 200 # global flag 201 # flag = True 202 # 203 # def auth(f): 204 # def inner(*args,**kwargs): 205 # while 1: 206 # if flag: 207 # ret = f(*args,**kwargs) 208 # return ret 209 # else: 210 # login() 211 # return inner 212 # 213 # @auth 214 # def comment(): 215 # print('评论页面') 216 # 217 # @auth 218 # def artcle(): 219 # print('文章页面') 220 # 221 # @auth 222 # def dairy(): 223 # print('日记页面') 224 # 225 # comment() 226 # artcle() 227 # dairy() 228 229 230 231 # 1.对扩展是开放的 232 # 为什么要对扩展开放呢? 233 # 我们说,任何一个程序,不可能在设计之初就已经想好了所有的功能并且未来不做任何更新和修改。 234 # 所以我们必须允许代码扩展、添加新功能。 235 # 236 # 2.对修改是封闭的 237 # 为什么要对修改封闭呢? 238 # 就像我们刚刚提到的,因为我们写的一个函数,很有可能已经交付给其他人使用了, 239 # 如果这个时候我们对其进行了修改,很有可能影响其他已经在使用该函数的用户。 240 # 241 # 装饰器完美的遵循了这个开放封闭原则。 242 243 244 # 装饰器的进阶 245 # 246 # 1、正常情况下查看被装饰的函数的信息的方法在此处都会失效 247 # 解决办法 248 # import time 249 # from functools import wraps 250 # 251 # def timmer(func): 252 # @wraps(func) #加在内层函数的正上方 253 # def inner(*args,**kwargs): 254 # start = time.time() 255 # ret = func(*args,**kwargs) 256 # print(time.time() - start) 257 # return ret 258 # return inner 259 # 260 # @timmer 261 # def index(): 262 # """这是一个主页的信息,哈哈哈""" 263 # time.sleep(0.5) 264 # print("from index") 265 # 266 # index() 267 # print(index.__doc__) 268 269 270 # 2、带有参数的装饰器 271 """ 272 假如你有成千上万个函数使用了一个装饰器,现在你想把这些装饰器都取消掉,你要怎么做? 273 一个一个的取消掉? 没日没夜忙活3天。 274 过两天你领导想通了,再让你加上。 275 """ 276 # def outer(flag): 277 # # flag = True 278 # def timmer(func): 279 # def inner(*args,**kwargs): 280 # if flag: 281 # print("""执行函数之前要做的""") 282 # ret = func(*args,**kwargs) 283 # if flag: 284 # print("""执行函数之后要做的""") 285 # return ret 286 # return inner 287 # return timmer 288 # 289 # @outer(False) 290 # def func(): 291 # print(111) 292 # 293 # func() 294 295 296 # 3、多个装饰器,装饰一个函数 297 # def wrapper1(f): 298 # def inner(*args,**kwargs): 299 # print('我是装饰器1') 300 # ret = f(*args,**kwargs) 301 # return ret 302 # return inner 303 # 304 # def wrapper2(f): 305 # def inner(*args,**kwargs): 306 # print('我是装饰器2 开头') 307 # ret = f(*args,**kwargs) 308 # print('我是装饰器2 结束') 309 # return ret 310 # return inner 311 # 312 # @wrapper2 313 # @wrapper1 314 # def func(): 315 # print("in func") 316 # func()
04 可迭代对象 与 迭代器
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 # 可迭代对象:这个对象由多个元素组成,他就是可迭代的 5 # 这个对象内部只要含有"__iter__"方法,他就是可迭代的 6 # 7 # for i in 'abc': 8 # print(i) 9 # 10 # for i in [1,2,3]: 11 # print(i) 12 # 13 # for i in 1234: # 数字是一个不可迭代对象 14 # print(i) 15 # 16 # int bool ---- 不可迭代 17 # str list tuple dict set bytes range 文件句柄 --可以迭代 18 # 19 # 判断一个对象是否是可迭代的 20 # 方法一:内部是否有 "__iter__方法" 21 # s1 = "alex" 22 # print("__iter__" in dir(s1)) 23 # 24 # n = 1 25 # print("__iter__" in dir(n)) 26 # 27 #print("__iter__" in dir(range)) 28 # 29 # f = open('a.txt',encoding='utf-8',mode='w') 30 # print("__iter__" in dir(f)) 31 # 32 #方法二: 33 # from collections import Iterable #判断一个对象是不是可迭代对象 34 # l1 = [1,2,3] 35 # print(isinstance(l1,Iterable)) 36 37 38 # 迭代器:内部含有__iter__方法并且含有__next__方法的就是迭代器 39 # 如何判断此对象是不是迭代器? 40 # 方法1 41 # l1 = [1,2,3] # 不是迭代器 42 # print('__iter__' in dir(l1)) 43 # print('__next__' in dir(l1)) 44 # 45 #方法2 46 # from collections import Iterator 47 # f = open('a.txt',encoding='utf-8',mode='w') # 文件句柄是一个迭代器 48 # print(isinstance(f,Iterator)) 49 50 51 #迭代器和可迭代对象的区别 52 # 53 # 1、可迭代对象不能直接取值,必须转化成迭代器进行取值。把索引这个方法除外哈 54 # l1 = [1,2,3] 55 # for i in l1: #for循环内部会把可迭代对象转化为迭代器,用__next__ 进行取值 56 # print(i) 57 # 58 # 将一个可迭代对象转化为迭代器 iter() 59 # l1 = [1,2,3] 60 # obj = iter(l1) 61 # print(obj) 62 # print(next(obj)) 63 # print(next(obj)) 64 # print(next(obj)) 65 66 67 # 迭代器有什么作用? 68 # 1,节省内存。 69 # 2,一条路走到底,不反复。 70 # 3,不易看出。 71 # 72 # while 模拟for循环循环可迭代对象的机制。 73 # 1,将可迭代对象转化成迭代器。 74 # 2,利用next进行取值。 75 # 3,利用异常处理停止循环。 76 # l1 = [1,2,3,4,5,6,] 77 # # obj = l1.__iter__() # 不建议用这种方法把可迭代对象转化为迭代器 78 # obj = iter(l1) 79 # while 1: 80 # # print(obj.__next__()) # 不建议用这种方法去取值 81 # try: 82 # print(next(obj)) 83 # except StopIteration: 84 # break
05 生成器
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 # 生成器:本质就是迭代器,自己可以通过代码写出来的迭代器。 5 # 生成器的生成方式: 6 #1 ,函数式生成器。 7 #2,生成器表达式。 8 9 # 函数式生成器 10 # def func(): 11 # # print(111) 12 # yield 5 13 # yield 6 14 # yield 7 15 # yield 8 16 # 17 # g = func() # 生成器对象 18 # # 一个next对应一个 yield 19 # print(next(g)) 20 # print(next(g)) 21 # print(next(g)) 22 # print(next(g)) 23 24 25 # 举例 26 # def book(): 27 # for i in range(1,501): 28 # print("python书籍 编号%s" % i) 29 # # book() 30 # 31 # def book_niu(): 32 # for i in range(1,501): 33 # yield "python书籍 编号%s" % i 34 # gen = book_niu() 35 # 36 # for i in range(50): 37 # print(next(gen)) 38 # 39 # 函数中只要有yield 他就不是函数了,他是生成器函数 40 # 41 # yield 与 return的区别 42 # return直接终止函数,yield不会终止函数。 43 # return给函数的执行者返回值,yield是给next(生成器对象)返回值。 44 45 46 # send:不仅可以取值,还可以给上一个yield发送一个值 47 # def f(): 48 # a = 1 49 # b = 2 50 # count = yield a + b 51 # print(count) 52 # yield 5 53 # yield 6 54 # yield 7 55 # 56 # g = f() 57 # send 与 next的区别 58 # 59 # 1、第一个yield 不能用 send 取值 60 # print(g.send(1)) 61 # print(next(g)) 62 # print(next(g)) 63 # print(next(g)) 64 # print(next(g)) 65 # 66 # print(next(g)) 67 # print(g.send(None)) 68 # print(g.send(None)) 69 # print(g.send(None)) 70 71 # 2、最后一个yield 永远不会得到 send 发送的值 72 # print(next(g)) 73 # print(g.send('a')) 74 75 76 # yield from:将一个可迭代对象转化成了生成器返回 77 # def func(): 78 # l1 = ['barry', 'alex', 'wusir', '日天'] 79 # yield l1 80 # g = func() 81 # print(next(g)) 82 83 84 # yield from 85 # def func(): 86 # l1 = ['barry', 'alex', 'wusir', '日天'] 87 # yield from l1 # 将一个可迭代对象转化成了生成器返回 88 # g = func() 89 # print(next(g)) 90 # print(next(g)) 91 # print(next(g)) 92 # print(next(g))
06 生成器表达式 列表推导式
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 # 生成器表达式 与 列表推导式非常类似 5 # 列表推导式 [ ] 6 # 生成器表达式 ( ) 7 8 9 # 列表推导式: 用一行代码构建一个列表,列表推导式只能构建简单的或者比较复杂的列表 10 # 11 # 构建一个列表,[100以内所有的偶数],[0,2,4,6,8....100] 12 # 方法1 13 # l1 = [] 14 # for i in range(0,101,2): 15 # l1.append(i) 16 # print(l1) 17 # 18 # 列表推导式分为两种模式: 19 # 1,循环模式。 [变量(加工后的变量) for 变量 in iterable] 20 # 构建一个列表,[100以内所有的偶数] 21 # print( [ i for i in range(0,1001,2) ] ) 22 # 23 # [1,4,9,16,25,36,49] 24 # print([ i**2 for i in range(1,8)]) 25 # 26 # ['python1期', 'python2期', .....'python20期'] 27 # print(['python%s期'% i for i in range(1,21)]) 28 29 # 2,筛选模式。[变量(加工后的变量) for 变量 in iterable if 条件] 30 # 30以内能被2整除的数的平方 31 # print([ i**2 for i in range(1,31) if i % 2 == 0]) 32 # 33 # [1,2,3,4,6,7,8] 34 # print([i for i in range(1,9) if i != 5]) 35 # 36 # l1 = ['wusir','ba', 'aa' ,'alex'] 37 # 过滤掉长度小于3的字符串列表,并将剩下的转换成大写字母 38 # print([i.upper() for i in l1 if len(i) > 3]) 39 # 40 #names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']] 41 # 将列表中的至少含有两个'e'的人名留下来。 42 # 方法1 43 # l1 = [] 44 # for l in names: 45 # for name in l: 46 # if name.count('e') >= 2: 47 # l1.append(name) 48 # print(l1) 49 # 50 #print([name for l in names for name in l if name.count('e') >= 2]) 51 52 53 # 生成器表达式: 54 # 优势: 55 # 1,一行搞定。 56 # 2,节省内存。 57 # 58 # 两种模式: 59 # 1,循环模式。 (变量(加工后的变量) for 变量 in iterable) 60 # (变量(加工后的变量) for 变量 in iterable if 条件) 61 # 62 #2,筛选模式。(变量(加工后的变量) for 变量 in iterable if 条件)
07 匿名函数
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 # 匿名函数: 一句话函数 lambda 5 # 6 # 两个数相加 7 # def func(a,b): 8 # return a + b 9 # print(func(1,3)) 10 # func(1,3) 11 12 # 两个书相加 13 # func1 = lambda x,y: x + y 14 # print(func1(1,2)) 15 16 # 将 x, y 较大者返回 17 # func2 = lambda x,y: x if x > y else y 18 # print(func2(100,200))
08 内置函数
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 # 重要的*** 5 # sum 求和 6 # print(sum([i for i in range(101)])) 7 # print(sum([i for i in range(101)],100)) 8 9 # min 可以加 key=函数 最小值 10 # max 可以加 key=函数 最大值 11 # l1 = [3,4,1,2,7,-5] 12 # print(min(l1)) 13 # print(max(l1)) 14 # l2 = [('a',3),('b',2),('c',1)] 15 # def func(x): 16 # return x[1] 17 # print(min(l2,key=func)) # 注意这里min 会先把l2列表中的每个元素传递到func函数中去,然后在取最小的 18 # print(max(l2,key=func)) 19 # 改成lambda 20 # print(min(l2,key=lambda x:x[1])) 21 22 # reversed 翻转。会生成一个迭代器 23 # l1 = [i for i in range(10)] 24 # print(l1) 25 # from collections import Iterator 26 # g = reversed(l1) 27 # print(isinstance(g,Iterator)) 28 # print(next(g)) 29 # print(next(g)) 30 # print(next(g)) 31 # print(next(g)) 32 33 # sorted 排序 34 # l1 = [1,2,8,7,5] 35 # print(sorted(l1)) 36 # l2 = [('c',2),('b',3),('a',1)] 37 # print( sorted(l2, key=lambda x:x[1]) ) # 这个和min max 有点类似 38 39 # zip 拉链方法,会以最短的那个列表或其他的 去组合。生成一个迭代器 40 # l1 = [1,2,3,4] 41 # tu1 = ('a','b','c') 42 # g = zip(l1,tu1) 43 # print(next(g)) 44 # print(next(g)) 45 # print(next(g)) 46 # l1 = [1,2,3,4] 47 # tu1 = ('a','b','c') 48 # tu2 = ('a1','b1','c1') 49 # g1 = zip(l1,tu1,tu2) # 也可以多个元素组合 50 # for i in g1: 51 # print(i) 52 53 # enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标, 54 # 一般用在 for 循环当中。 55 # l1 = ['a','b','c','d'] 56 # for index,i in enumerate(l1): 57 # print(index,i) 58 59 60 # 其他 61 # abs() 函数返回数字的绝对值 62 # print(abs(-1)) 63 # print(abs(1)) 64 65 # all() 函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。 66 # 元素除了是 0、空、FALSE 外都算 TRUE 67 # print( all('a') ) 68 # print( all([1,2,3,'',5,]) ) 69 70 # any() 函数用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。 71 # 元素除了是 0、空、FALSE 外都算 TRUE 72 # print( any(['',0,False]) ) 73 # print( any([1,0,False]) ) 74 75 # bin() 返回一个整数 int 或者长整数 long int 的二进制表示 只能是数字 76 # print(bin(100)) 77 78 # bool() 函数用于将给定参数转换为布尔类型,如果没有参数,返回 False 79 # print( bool(0) ) 80 # print( bool(1) ) 81 # print( bool('') ) 82 83 # callable() 函数用于检查一个对象是否是可调用的。如果返回 True,object 仍然可能调用失败; 84 # 但如果返回 False,调用对象 object 绝对不会成功 85 # print( callable(0) ) 86 # a = 1 87 # print( callable(a) ) 88 # def f(): 89 # pass 90 # print( callable(f) ) 91 92 # chr() 用一个整数作参数,返回一个对应的字符 。对应的ascii码 。可以用于验证码 93 # print( chr(97) ) 94 95 # compile() 函数将一个字符串编译为字节代码。 慎用 96 # s1 = "for i in range(10):print(i)" 97 # f = compile(s1,'','exec') 98 # exec(f) 99 100 # dict() 函数用于创建一个字典 101 102 # dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表 103 # 带参数时,返回参数的属性、方法列表 104 # print(dir()) 105 # print(dir(str)) 106 107 # divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b) 108 # print( divmod(7,3) ) 109 110 # eval() 函数用来执行一个字符串表达式,并返回表达式的值。 111 # print( eval("3*7") ) 112 113 # exec 执行储存在字符串或文件中的 Python 语句,相比于 eval,exec可以执行更复杂的 Python 代码。 114 # exec( 'print("hello world")' ) 115 116 # filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换 117 # 该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判, 118 # 然后返回 True 或 False,最后将返回 True 的元素放到新列表中 119 # l1 = [1,2,3,4,5,6,7,8,9,10,] 120 # def is_odd(n): 121 # return n % 2 == 1 122 # g = filter(is_odd, l1) 123 # for i in g: 124 # print(i) 125 126 # float() 函数用于将整数和字符串转换成浮点数 127 # print( float(1) ) 128 # print( float("100") ) 129 130 # format() 格式化输出函数 131 132 # frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素 133 # a = frozenset(range(10)) 134 # print(a) 135 136 # globals() 函数会以字典类型返回全部全局变量 137 # def f(): 138 # name = 'alex' 139 # print(globals()) 140 # print(globals()) 141 # f() 142 143 # hash() 用于获取取一个对象(字符串或者数值等)的哈希值 144 # print( hash('abc') ) 145 146 # help() 函数用于查看函数或模块用途的详细说明 147 # print(help('sys')) 148 # print(help('str')) 149 150 # hex() 函数用于将一个指定数字转换为 16 进制数 151 # print( hex(10) ) 152 153 # id() 函数用于获取对象的内存地址 154 # s = 'a' 155 # print( id(s) ) 156 157 # input() 函数接受一个标准输入数据,返回为 string 类型 158 159 # int() 函数用于将一个字符串或数字转换为整型 160 # print( int("10") ) 161 # print( int(10.1) ) 162 163 # isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type() 164 # a = 2 165 # print( isinstance(a,int) ) 166 # s = 'alnk' 167 # print( isinstance(s, str)) 168 169 # iter() 函数用来生成迭代器 170 # l1 = [1,2,3,4,] 171 # print( type(l1) ) 172 # g1 = iter(l1) 173 # print( type(g1) ) 174 175 # len() 方法返回对象(字符、列表、元组等)长度或项目个数 176 # print( len('abc')) 177 178 # list() 方法用于将元组或字符串转换为列表 179 # t1 = (1,2,3,) 180 # print( list(t1)) 181 182 # locals() 函数会以字典类型返回当前位置的全部局部变量 183 # name = 'alnk' 184 # def f(): 185 # age = 12 186 # print(locals()) 187 # f() 188 # print(locals()) 189 190 # map() 会根据提供的函数对指定序列做映射 191 # def squ(x): 192 # return x ** 2 193 # l1 = [1,2,3,4,5] 194 # g = map(squ,l1) 195 # for i in g: 196 # print(i) 197 198 # next() 返回迭代器的下一个项目 199 200 # oct() 函数将一个整数转换成8进制字符串 201 # print( oct(10)) 202 203 # open() 方法用于打开一个文件,并返回文件对象 204 205 # ord() 函数是 chr() 函数(对于 8 位的 ASCII 字符串)的配对函数, 206 # 它以一个字符串(Unicode 字符)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值 207 # print( ord('a')) 208 # print( chr(97)) 209 210 # pow() 方法返回 xy(x的y次方) 的值。 211 # print( pow(2,3)) 212 213 # print() 方法用于打印输出,最常见的一个函数 214 # print('abcd',end='|') 215 # print(1234) 216 # print('ABCD',end='') 217 # print('efgh') 218 219 # range() 函数返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表 220 221 # repr() 函数将对象转化为供解释器读取的形式 222 # s = "abcd" 223 # print( repr(s)) 224 # dic = {'runoob': 'runoob.com', 'google': 'google.com'} 225 # print(repr(dic)) 226 227 # round() 方法返回浮点数x的四舍五入值 228 # print( round(70.23456,4)) 229 # print( round(70.23456)) 230 231 # set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等 232 233 # str() 函数将对象转化为适于人阅读的形式 234 235 # tuple 函数将列表转换为元组 236 237 # type() 函数如果你只有第一个参数则返回对象的类型 238 239 240 # 和类相关的内置函数 241 # classmethod() 学习类以后再来补充 242 # delattr() 学习类以后再来补充 243 # getattr() 学习类以后再来补充 244 # hasattr() 学习类以后再来补充 245 # issubclass() 学习类以后再来补充 246 # property() 学习类以后再来补充 247 # setattr() 学习类以后再来补充 248 # staticmethod() 学习类以后再来补充 249 # super() 学习类以后再来补充