前情回顾
上一周是已经给定了神经网络的最优权重参数,接着直接代到前向传播里面去,算得最终的预测值就可以了。
这周呢,需要搭建整个完整的神经网络,并且需要自己去进行训练,找到最终的这个优化的权重参数。
可能需要的知识点
来自网络
前向传播知识点
-
前向传播 (Forward propagation),也叫正向传播,是神经网络中的一项重要操作,用来将输入数据传递到网络的输出层。
-
在前向传播过程中,输入数据通过神经网络依次传递到每一层的神经元。针对每个神经元,其输入就是它前一层所有神经元的输出乘以对应的权重,然后再加上该神经元的偏置项后经过激活函数处理得到其输出。这个输出被传递到下一层神经元进行计算,最终得到输出层的输出结果。
在多层前向神经网络中,前向传播可概括为以下步骤:
-
1.将输入数据传递到输入层,即第一个全连接层。
-
2.对于每个隐藏层,将前一层的输出乘以其所对应的权重矩阵,并加上该层神经元的偏置项。然后将这个结果输入到激活函数中,经过非线性变换产生该层的输出值,并作为下一层的输入。
-
3.重复步骤2,直到输入数据通过所有隐藏层并到达输出层。输出层将产生最终的输出结果。
-
4.将输出结果和真实标签进行比较,得到网络的误差。
在前向传播过程中,神经网络的所有参数都是固定的,包括权重和偏置项。因此,前向传播的计算速度非常快,而且可以使用矩阵运算进行高效计算。
反向传播
反向传播 (Backpropagation),顾名思义,就是在神经网络中反向传播误差,从而更新权重,使得神经网络能够得到更好的预测结果。
反向传播(Backpropagation)是一种用于训练深度神经网络的监督学习算法。
反向传播算法大致可以分为以下三个步骤:
-
前向传播:通过网络的前向传播,计算输入的逐层转换,并计算每个神经元的输出值,直到输出层得到输出预测结果。在此过程中,也会计算损失函数。
-
反向传播:计算输出层与前一层之间的残差(即误差),并反向传播到前一层,计算前一层与更前一层之间的残差。通过 chain rule(链式法则) 将误差从输出层向前传递,并计算隐藏层中每个神经元的误差信号。计算误差时,也会使用损失函数。
-
权重更新:通过计算误差变化的梯度,计算每个神经元的权重更新量,并使用梯度下降法或其变种,按照预设步长和方向,更新所有权重参数,进一步减小神经网络的损失函数。
总的来说,反向传播算法通过计算神经网络的误差信号并反向传播,来优化神经网络的参数,使其能够更好地适应训练数据,更好地进行分类、预测等任务。
本周案例
神经网络解决多分类问题
案例:手写数字识别
数据集:ex4data1.mat
初始参数:ex4weights.mat
数据在这里:机器学习数据
具体实现
1. 导包
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio
from scipy.optimize import minimize
2. 读取数据
data = sio.loadmat('ex4data1.mat ')
raw_X = data['X']
raw_y = data['y']
3. 对X与y进行数据处理
3.1 对X进行数据处理
# 插入一列 5000乘以401列
# 将输入数据 X 矩阵中的第一列插入一个值为 1 的向量
# 这个向量代表偏置项(bias term),也就是偏移量或截距
# 添加偏置项1,可以将模型中的截距项权重独立出来,方便模型的求解和表达。
# 同时,添加偏置项也可以使得模型对数据集的拟合能力更强,提高模型的泛化能力。
X = np.insert(raw_X, 0, values=1, axis=1)
# print(X.shape) # (5000, 401)
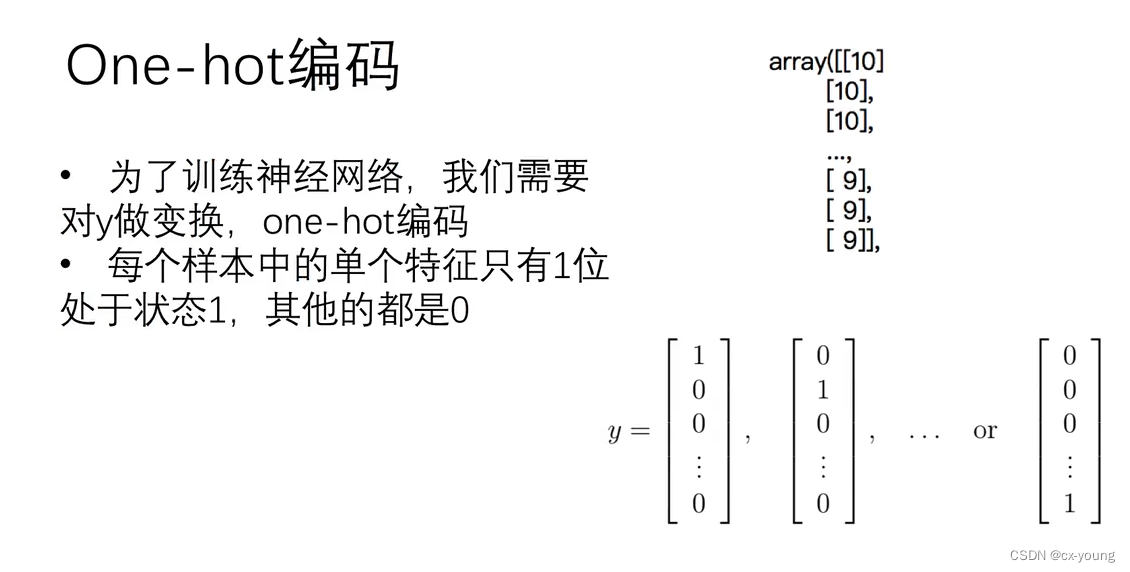
3.2 对y进行one-hot编码
对y的处理和以往不同
-
One-hot编码是一种常用的数据编码方式,用于将离散的数据或类别变量转换为数值型变量。
-
它的基本思想是将每个可能的取值都映射到一个整数,然后将每个整数使用一个二进制位表示,只有其中的一个二进制位为1,其余都为0。这样,每个可能的取值都被表示为一个唯一的二进制码,相当于使用一组布尔型特征表示它们。
-
例如,对于一个三类别的标签变量a,可以使用One-hot编码将其转换为一个三元向量:[1, 0, 0],[0, 1, 0]或[0, 0, 1],分别表示三个类别。
-
One-hot编码有利于更好地利用分类变量信息,便于机器学习或深度学习算法处理。
或如下图所示
# 1.对原始标签数据y进行独热编码处理:one-hot编码,返回一个numpy数组
def one_hot_encoder(raw_y):result = [] # 定义一个空列表 用于存储每个标签的独热编码for i in raw_y: # i的取值:1-10y_temp = np.zeros(10) # 创建大小为10的一维数组,并将其所有元素设为0。y_temp[i - 1] = 1 # 列表下标从0开始,相应位置设为1result.append(y_temp)return np.array(result) # 转换成numpy数组# 测试 需要的话把注释去掉
# print(raw_y) # 原始的
'''
[[10][10][10]...[ 9][ 9][ 9]]
'''
# print(raw_y.shape) # 原始的维度(5000,1)
y = one_hot_encoder(raw_y)
# print(y) # 处理后的
'''
运行结果:
[[0. 0. 0. ... 0. 0. 1.][0. 0. 0. ... 0. 0. 1.][0. 0. 0. ... 0. 0. 1.]...[0. 0. 0. ... 0. 1. 0.][0. 0. 0. ... 0. 1. 0.][0. 0. 0. ... 0. 1. 0.]]
'''
# print(y.shape) # 处理后的维度(5000,10)
4. 序列化与解序列化
当我们使用深度学习模型对手写数字进行识别时,模型训练完成后,我们需要把模型的参数(比如权重和偏置)保存到本地的文件中,以便在之后的使用中可以重用这些参数,而不需要重新进行训练,从而节省时间和计算资源。
通过序列化,我们可以把这些参数以二进制的形式保存到文件中。这个过程就像是把一份复杂而庞大的结构的数据转化成了一份压缩的数据,从而方便地进行存储和传输。
当我们需要重新使用这些参数时,只需要反序列化它们,就能重新得到它们的原始结构和数值。
总结:序列化和反序列化的目的其实是为了方便地把数据保存到本地(即序列化),以及把保存的数据再次读取出来(即反序列化)
一般来说,我们将深度学习模型的参数进行序列化,并将它们保存在本地。而在加载权重参数的时候,就需要将这些一维数组反序列化得到原始的权重矩阵。
使用scipy库中的minimize优化器来调用优化函数时,优化函数的输入参数x0要求是一个向量或数组。因此,如果我们有一个多维数组或张量作为输入,需要先把它序列化并转成向量形式,才能传入minimize优化器中。
4.1 序列化权重参数
# 读取权重参数
theta = sio.loadmat('ex4weights.mat')
theta1, theta2 = theta['Theta1'], theta['Theta2']# print(theta1.shape) # (25, 401)
# print(theta2.shape) # (10, 26)# 序列化是为了传入调用scipy函数库方便,解序列化是为了后续矩阵运算维度保持一致
# 因为minimize优化器的x0初始化参数输入要求是序列化后(只有一列)
# 2.序列化权重参数
# 将权重参数 `a` 和 `b` 序列化为一个一维的数组并返回。# 首先使用 `flatten()` 方法将 `a` 和 `b` 两个多维数组压扁成一维数组
# 然后使用 `np.append()` 函数将这两个一维数组拼接成一个更长的一维数组,并将其作为函数的返回值。
def serialize(a, b):return np.append(a.flatten(), b.flatten())# theta_serialize = serialize(theta1, theta2)
# print(theta_serialize.shape) # (10285,)4.2 解序列化权重参数
这段代码定义了一个 deserialize() 函数,用于将序列化后的权重参数反序列化得到原始的 theta1 和 theta2 参数。
首先使用数组切片操作 theta_serialize[:25 * 401] 提取出前 25 * 401 个元素,也就是 theta1 参数的序列化数据。
然后使用 reshape() 函数将这些元素转化成一个25行401列的二维矩阵,恢复了原始的 theta1 参数的形状。
接着,利用切片操作 theta_serialize[25 * 401:] 提取后 10 * 26 个元素,也即是 theta2 参数的序列化数据,
然后同样通过 reshape() 函数将它们转化成一个10行26列的二维矩阵,恢复了原始的 theta2 参数的形状。
最后将这两个参数以元组的形式返回。
一般来说,我们将深度学习模型的参数进行序列化并保存到本地,以便在需要的时候重新加载它们。而在加载权重参数的时候,就需要将序列化后的参数反序列化得到原始的参数矩阵,以继续进行训练或预测操作。
# 3.解序列化权重参数
def deserialize(theta_serialize):theta1 = theta_serialize[:25 * 401].reshape(25, 401)theta2 = theta_serialize[25 * 401:].reshape(10, 26)return theta1, theta2# theta1, theta2 = deserialize(theta_serialize)
# print(theta1.shape, theta2.shape) # (25, 401) (10, 26)
5.前向传播
5.1 激活函数sigmoid函数
神经网络的激活函数引入了非线性因素,使得神经网络能够适应并学习复杂的模式。如果没有激活函数,无论神经网络有多少层,输出都将是输入的线性函数,这样的网络无法学习和执行更复杂的任务。
常用的激活函数有sigmoid函数,relu函数,tanh函数和ssoftmax函数等,每种函数都有其适用的场景和优缺点
# 激活函数sigmoid
def sigmoid(z):return 1 / (1 + np.exp(-z))
5.2 前向传播
# “forward propagation” 或 “feedforward” 给定序列化后的权重参数 `theta_serialize` 和输入数据 `X`,函数使用权重参数计算出神经网络的输出结果
def feed_forward(theta_serialize, X):# 将 `theta_serialize` 反序列化得到原始的参数矩阵 `theta1` 和 `theta2`theta1, theta2 = deserialize(theta_serialize)# 输入数据 `X` 作为初始值a1 = Xz2 = a1 @ theta1.Ta2 = sigmoid(z2)a2 = np.insert(a2, 0, values=1, axis=1) # `a2` 在第0列插入一个全为1的列向量,这样可以使得后续的计算更方便,并将结果存储在变量 `a2` 中。z3 = a2 @ theta2.Th = sigmoid(z3)return a1, z2, a2, z3, h # 返回了中间变量 `a1`、`z2`、`a2`、`z3` 和输出结果 `h`
6. 损失函数
思路和逻辑回归存在某些相似的地方
6.1 无正则化的损失函数
使用前向传播算法来计算模型预测结果,并将预测结果与真实结果进行比较,从而得到损失函数J的值。损失函数越小,则模型的准确性就越高。

# 不带正则化的损失函数。
def cost(theta_serialize, X, y):# 调用 `feed_forward()` 函数,利用输入数据 `X` 和当前的权重参数 `theta_serialize` 计算出神经网络的输出结果 `h`。a1, z2, a2, z3, h = feed_forward(theta_serialize, X)# 使用交叉熵损失函数计算 `h` 和真实标签 `y` 之间的误差,误差越小,损失函数的值就越小。最后,函数将损失函数值除以样本量,得到平均损失函数。J = -np.sum(y * np.log(h) + (1 - y) * np.log(1 - h)) / len(X)return J# J = cost(theta_serialize, X, y)# print(J) # 0.2876291651613189
6.2 正则化的损失函数
正则化逻辑回归损失函数是一种有效避免过拟合的方法,它不仅能使模型具有更强的泛化能力,还能帮助我们在训练模型时不断提高权重参数的质量。

# 5.2带正则化的损失函数
def reg_cost(theta_serialize, X, y, lamda):# `theta1[:,1:]` 和 `theta2[:,1:]` 分别表示 `theta1` 和 `theta2` 中除了第一列以外的其他列sum1 = np.sum(np.power(theta1[:, 1:], 2))sum2 = np.sum(np.power(theta2[:, 1:], 2))reg = (sum1 + sum2) * lamda / (2 * len(X))return reg + cost(theta_serialize, X, y)lamda = 1
reg_cost_res = reg_cost(theta_serialize, X, y, lamda)# print(reg_cost_res) # 0.38376985909092365
7. 梯度
7.1 无正则化

# 不带正则化的梯度
def gradient(theta_serialize, X, y):theta1, theta2 = deserialize(theta_serialize)# 调用 `feed_forward()` 函数来计算神经网络的输出结果 也就是预测结果ha1, z2, a2, z3, h = feed_forward(theta_serialize, X)# 根据实际预测结果 `h` 与真实值 `y` 的差异计算出误差 `d3`d3 = h - y# 函数使用链式求导法则将误差 `d3` 反向传播回隐藏层,从而求解 `d2` 的值。# `d2` 计算方式为:`d3` 乘上 `theta2` 除去第一列后的矩阵,再乘上 sigmoid 函数的梯度值得到的向量。d2 = d3 @ theta2[:, 1:] * sigmoid_gradient(z2)# 使用误差项 `d3` 和隐藏层的输出值 `a2`# 计算出输入层与隐藏层间的权重参数的梯度 `D2`D2 = (d3.T @ a2) / len(X)# 使用误差项 `d2` 和输入向量 `a1` 计算出偏置项和系数项的梯度 `D1`D1 = (d2.T @ a1) / len(X)# 将 `D1` 和 `D2` 按列连接起来,将得到的梯度值序列化后返回return serialize(D1, D2)
7.2 正则化

# 带正则化的梯度 考虑了惩罚项,从而避免了过拟合的问题,并提高了模型的泛化能力
def reg_gradient(theta_serialize, X, y, lamda):# 计算不带正则化的梯度向量 `D`D = gradient(theta_serialize, X, y)# 将 `D` 分解为两个梯度矩阵:`D1` 和 `D2`D1, D2 = deserialize(D)theta1, theta2 = deserialize(theta_serialize)D1[:, 1:] = D1[:, 1:] + theta1[:, 1:] * lamda / len(X)D2[:, 1:] = D2[:, 1:] + theta2[:, 1:] * lamda / len(X)return serialize(D1, D2)
8. 优化
# 7.神经网络优化 使用优化算法使得损失函数达到最小化
from scipy.optimize import minimizedef nn_training(X, y):# 随机初始化的权重参数 `init_theta` 作为神经网络的初始值init_theta = np.random.uniform(-0.5, 0.5, 10285)# 调用 Scipy 的 `minimize()` 函数,利用 TNC 方法来进行神经网络的训练res = minimize(fun=reg_cost, # `fun` 参数传递的是损失函数x0=init_theta, # `x0` 参数传递的是神经网络的初始权重参数# `args` 参数传递的是需要传递给损失函数的其他参数 此处为数据集 `X` 和标签集 `y`,同时还有一个正则化参数 `lamda`args=(X, y, lamda),method='TNC',jac=reg_gradient, # `jac` 参数传递的是损失函数的梯度函数,用于计算权重参数的调整值options={'maxiter': 300} # `options` 参数中设置了最大迭代次数为 300)return res# 测试
lamda = 10
res = nn_training(X, y)
raw_y = data['y'].reshape(5000, )
_, _, _, _, h = feed_forward(res.x, X)
y_pred = np.argmax(h, axis=1) + 1
acc = np.mean(y_pred == raw_y)
print(acc) # 0.93849. 可视化隐藏层
- 这个函数的主要目的是帮助我们理解神经网络中隐藏层的作用。
- 隐藏层主要用于提取输入数据的高级特征,并通过向后传递这些特征来完成模型的训练。
- 因此,我们可以通过查看隐藏层的权重矩阵,来了解神经网络是如何学习这些特征的。
# 8.可视化隐藏层 绘制神经网络隐藏层
def plot_hidden_layer(theta):# 使用训练好的损失函数参数 `theta`,调用 `deserialize()` 函数将其解码为两个权重矩阵 `theta1` 和 `theta2`,然后获取第一层与第二层之间的权重参数矩阵 `theta1`theta1, _ = deserialize(theta)# 将 `theta1` 中的每个隐藏节点的权重系数可视化成一个矩阵,从而揭示出每个隐藏节点所学习的特征# 将 `theta1` 中的第二列到最后一列切片出来,偏置项不参与权重参数的更新# 矩阵的形状为 (25, 400) 其中 25 表示隐藏节点的个数,400 表示每个隐藏节点所连接的输入节点的个数。hidden_layer = theta1[:, 1:]# 创建一个大小为 5x5 的图像子网格布局fig, ax = plt.subplots(ncols=5, nrows=5, figsize=(8, 8), sharex=True, sharey=True)# 双重循环对矩阵中的每个隐藏节点进行处理for r in range(5):for c in range(5):# 因为每个隐藏节点的权重矩阵有 400 个元素,所以我们将其转换为 20x20 的矩阵,并将其转置,最后以灰度图的形式显示出来ax[r, c].imshow(hidden_layer[5 * r + c].reshape(20, 20).T, cmap='gray_r')plt.xticks([])plt.yticks([])plt.show()# 并将训练好的模型参数 `res.x` 作为参数传递给该函数,最终实现可视化神经网络隐藏层中每个节点所学习的特征
plot_hidden_layer(res.x)