


数据智能产业创新服务媒体
——聚焦数智 · 改变商业
首个基于图数据库的大肠杆菌调控代谢关系知识图谱,云原生Serverless应用架构......近日,中国科学院天津工业生物技术研究所与亚马逊云科技联合在天津举办“生物计算设计”沟通会,就 BT+IT 助力合成生物学发展的现状和未来进行沟通。
中国科学院天津工业生物技术研究所(以下简称天津工业生物所)是中国合成生物学领域的核心力量,由中国科学院和天津市人民政府共建,牵头组织承担了多项合成生物学、绿色生物制造等重点研发计划任务。
数据猿了解到,中国科学院天津工业生物技术研究所与亚马逊云科技在生物计算设计领域合作已经长达四年之久。2019年,天津工业生物所成立了生物设计中心平台实验室,并围绕生物计算设计,开始与亚马逊云科技共同探索生物技术和信息技术相结合(BT+IT)技术体系,以进一步推动合成生物学发展,以期能够为在健康、能源、农业和环境等领域的科学研究提供技术支撑。
如今,中科院天津工业生物技术研究所与亚马逊云科技携手,通过突破传统开发模式提升科研效率,加速成果转化,在核心数据库和专业应用工具设计两大研发方向上实现技术突破,有效推动了合成生物学发展。
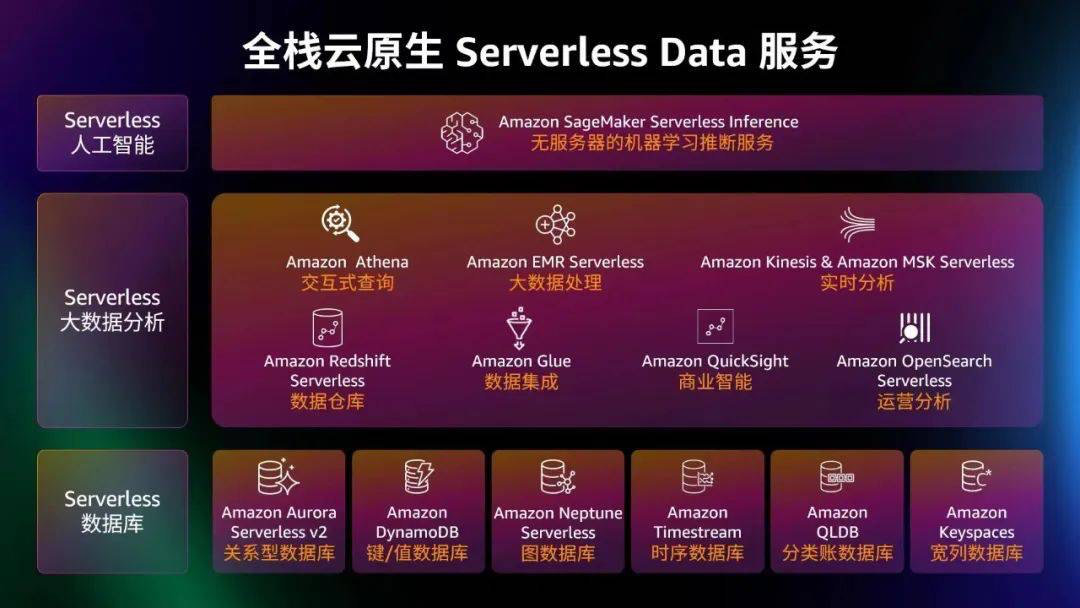
基于Amazon Neptune图数据库 构建首个大肠杆菌调控代谢知识图谱
细胞中的代谢调控非常复杂,一个特定的细胞功能往往由一系列不同类型的代谢途径调控相互作用决定。通常不同类型的调控数据散落在各个不同的数据库,生物学家很难通过仅关注与所研究的代谢物/蛋白质密切相关的一两类相互作用来识别这种复杂调控级联关系。因此,将这些不同类型的调控相互作用汇集在一起,并提供方便的交互方式,将极大的方便生物学家挖掘和理解生物体内的复杂调控关系。

天津工业生物所生物设计中心团队联合亚马逊云科技团队,在计算生物学国际期刊《Nucleic Acids Research》(《核酸研究》)上发表文章,发布了首个基于图数据库Amazon Neptune的大肠杆菌调控代谢关系知识图谱ERMer,首次提供了全局的代谢调控图谱,并通过可视化框架实现了丰富的搜索功能,如多步查询、最短路径查询等。ERMer采用专门为高度关联的复杂数据集的高效存储和查询设计图数据库架构,这打破了传统的低效数据检索方式,有效增强用户和图谱的人机交互,大大降低了使用门槛。
为充分发挥知识图谱的价值,生物设计中心团队还进一步采用基于图神经网络技术进行推理,成功实现了转录因子预测和转录因子靶点预测等功能,这将有助于挖掘潜在的关键调控因子和调控靶点,构建新的调控代谢网络,能够为研究人员提供新的思路和方向。
云原生Serverless应用架构 加速生物计算设计工具研发
模块化、标准化,是所有工程学科的基础,也是合成生物学区别于传统发酵行业的革命。工程学的可控性,意味着其将能够与各种软硬件进行结合,从而走向自动化与高通量,摆脱过往劳动密集型的研究模式,获得更高的技术迭代能力。而对于这个过程,除了针对元件工具以外,将合成生物学的相关实验流程进行模块化、标准化,也是自动化研究当中不可或缺的一环。
Amazon Serverless技术栈,使得科研人员不再需要在重复的低价值IT工作上花费精力,而是通过现代化应用这种理念去实现云原生构建,提高整体IT的敏捷性。不必管理基础设施,可以更加关注业务逻辑,集中精力于核心业务场景,加速创新。同时在技术上,也让开发更加灵活、更加快速的研发交付模式。不需要管理服务器,所有的服务器的弹性都是由亚马逊云科技来做托管,在任何规模下都有很好的性能的表现。还可以更细粒度的做应用的计费,以毫秒级计费。在没有业务使用的情况下不收费。整个过程数据安全,无论是数据传输过程中还是数据存储落地过程中,都可以使用密钥来对数据做安全性管控。
云平台AutoESD并行处理数百个设计任务
面向微生物遗传操作,天津工业生物所生物设计中心团队开发了第一个能够在所有操作类型、任何基因组位点和跨物种上进行精确、自动化和高通量编辑序列设计的云平台AutoESD。AutoESD 的开发采用了基于云端的无服务器架构,确保了高可靠性、稳健性和可扩展性,能够在几分钟内并行处理包含上千个编辑序列设计目标的数百个设计任务。
开发人员利用Amazon Step Functions实现可视化的工作流管理,实现了编辑序列设计工作流的串联,从而实现应用的快速构建和更新,同时快速查询处理异常任务;利用Amazon Lambda将不同的引物设计、同源臂设计等编辑序列设计模块封装打包,满足了具体功能的模块化开发要求,并方便地对功能模块进行管理和共享;利用Amazon DynamoDB提供毫秒级的动态资源响应性能,并自动扩展所需资源以应对增加的业务需求。这些Serverless服务帮助天津工业生物所团队进一步简化运维,使得开发人员可以专注于业务代码和创新,与传统开发方式相比,开发时间缩短了75%,总体拥有成本降低50%。
Amazon Neptune图数据库实现业务创新,解决异质数据问题
利用AI能力实现进化。一方面可以将所有的复杂的高度关联的数据存储在图数据库里面,通过优化的图查询的语句来解决复杂的多步查询、最短路径检索等问题。另一方面使用Amazon Neptune ML这种高度封装的图深度学习的框架服务,实现在低代码或者无代码情况下生成机器学习模型。Amazon Neptune ML应用在三类预测任务当中,转录因子预测,转录因子调控关系预测以及预测蛋白质相互作用的关联预测。
亚马逊云科技认为,数据和数据之间的关系一样重要,并且这些关系的强度和权重对解决实际问题会有更多的帮助。Amazon Neptune图数据库可以存储这些信息,自动化地去做一些数据的关联,并且可以通过图算法解决路径、图的优化问题。
“中国科学院天津工业生物技术研究所肩负着国家工业生物技术发展的重任,并正在加速利用云计算推动相关技术的研发和成果落地。亚马逊云科技提供的图数据库和Serverless服务,突破传统的开发模式、提升研发效率、不断优化云上成本,生物技术和信息技术相结合的技术体系将进一步推动合成生物领域的发展和创新。”天津工业生物技术研究所生物设计中心主任马红武表示,未来,天津工业生物所团队希望基于亚马逊云科技先进的服务技术和能力,开展更多“BT+IT”的研发工作,进一步助力研究所在合成生物领域的科研探索。
亚马逊云科技:合作中简化创新 释放云原生力量
亚马逊云科技的云原生架构能够帮助企业充分利用按需交付、快速拓展部署、弹性和更高级别的服务。可以大大提高了开发人员的工作效率、业务敏捷性、可扩展性、可用性、资源利用率和成本节约。
四年来,亚马逊云科技与天津工业生物所合作中从最初的数字中心到现在的所有IT架构、开发理念、开发模式都以云原生的方式实现,合作分为三个阶段:
第一阶段,学习云计算术,利用亚马逊的新型工具进行初步尝试,在云上做构建。凭借亚马逊云科技的行业经验和云计算的技术实力,获取专属的云计算的解决方案和思路,解决基于具体场景的技术需求。
第二阶段,合作进入快速发展,增加10多个软件应用的云上部署,尝试构建云原生现代化应用,探索出更适合生物设计中心业务模式的最佳实践。
第三阶段,使用托管服务和创新服务进行云原生创新,加大对云计算优势的利用,如按需交付、快速扩展、弹性等,大大提升了开发效率、业务敏捷性、可扩展性和可用性,同时实现成本节约。
在此基础上,亚马逊云科技总结出合作的最佳实践,对于前端来说,使用亚马逊云科技提供的对象存储来做静态页的托管,同样无需去管理服务器。对于后端来说,针对于不同的场景,例如小规模的计算任务可以通过Amazon Lambda来做更灵活的调度、更精细化的计费,按照毫秒计费来降低成本。对于一些大规模的、复杂的生物设计的流程,亚马逊云科技通过Amazon Step Function去管理复杂任务的逻辑关系,来实现自动化的任务调度、编排。对于大算力需求,有一些生物的计算过程需要大量的算力,可能需要数百台或者更多,再通过Amazon Batch计算服务去承载更大规模的计算任务。除此之外,提供的很多监控、管理、部署的服务,可快速地扩展部署到其他业务场景中,代码也可以更好地复用。
亚马逊云科技中国区商用与公共市场事业部总经理李晓芒表示,“亚马逊云科技为全球数千家生命科学领域客户提供云服务和行业解决方案,助力从实验室到真实世界,全面加速生命科学数字化创新。我们很高兴能够与天津工业生物所一道,通过云技术和深厚的行业实践推动合成生物学领域的技术进步,开拓生物制造产业的数字化创新路径。”
文:沐清漪 / 数据猿









