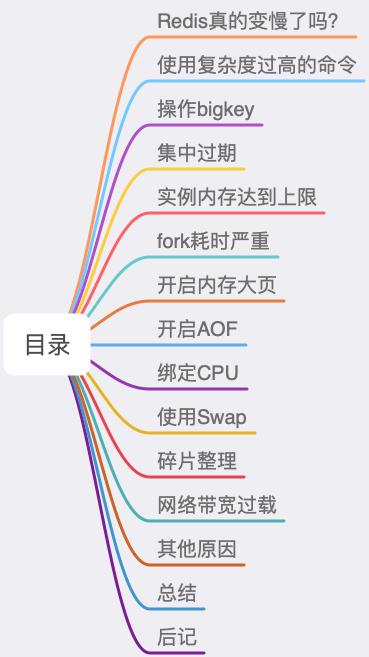
一、Redis为什么变慢了
1.Redis真的变慢了吗?
对 Redis 进行基准性能测试
例如,我的机器配置比较低,当延迟为 2ms 时,我就认为 Redis 变慢了,但是如果你的硬件配置比较高,那么在你的运行环境下,可能延迟是 0.5ms 时就可以认为 Redis 变慢了。
所以,你只有了解了你的 Redis 在生产环境服务器上的基准性能,才能进一步评估,当其延迟达到什么程度时,才认为 Redis 确实变慢了。
为了避免业务服务器到 Redis 服务器之间的网络延迟,你需要直接在 Redis 服务器上测试实例的响应延迟情况。执行以下命令,就可以测试出这个实例 60 秒内的最大响应延迟:
./redis-cli --intrinsic-latency 120
Max latency so far: 17 microseconds.
Max latency so far: 44 microseconds.
Max latency so far: 94 microseconds.
Max latency so far: 110 microseconds.
Max latency so far: 119 microseconds.36481658 total runs (avg latency: 3.2893 microseconds / 3289.32 nanoseconds per run).
Worst run took 36x longer than the average latency.
从输出结果可以看到,这 60 秒内的最大响应延迟为 119 微秒(0.119毫秒)。你还可以使用以下命令,查看一段时间内 Redis 的最小、最大、平均访问延迟
$ redis-cli -h 127.0.0.1 -p 6379 --latency-history -i 1
min: 0, max: 1, avg: 0.13 (100 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.12 (99 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.13 (99 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.10 (99 samples) -- 1.01 seconds range
min: 0, max: 1, avg: 0.13 (98 samples) -- 1.00 seconds range
min: 0, max: 1, avg: 0.08 (99 samples) -- 1.01 seconds range
如果你观察到的 Redis 运行时延迟是其基线性能的 2 倍及以上,就可以认定 Redis 变慢了。
网络对 Redis 性能的影响,一个简单的方法是用 iPerf 这样的工具测试网络极限带宽。
服务器端# iperf -s -p 12345 -i 1 -M
iperf: option requires an argument -- M
------------------------------------------------------------
Server listening on TCP port 12345
TCP window size: 4.00 MByte (default)
------------------------------------------------------------
[ 4] local 172.20.0.113 port 12345 connected with 172.20.0.114 port 56796
[ ID] Interval Transfer Bandwidth
[ 4] 0.0- 1.0 sec 614 MBytes 5.15 Gbits/sec
[ 4] 1.0- 2.0 sec 622 MBytes 5.21 Gbits/sec
[ 4] 2.0- 3.0 sec 647 MBytes 5.42 Gbits/sec
[ 4] 3.0- 4.0 sec 644 MBytes 5.40 Gbits/sec
[ 4] 4.0- 5.0 sec 651 MBytes 5.46 Gbits/sec
[ 4] 5.0- 6.0 sec 652 MBytes 5.47 Gbits/sec
[ 4] 6.0- 7.0 sec 669 MBytes 5.61 Gbits/sec
[ 4] 7.0- 8.0 sec 670 MBytes 5.62 Gbits/sec
[ 4] 8.0- 9.0 sec 667 MBytes 5.59 Gbits/sec
[ 4] 9.0-10.0 sec 667 MBytes 5.60 Gbits/sec
[ 4] 0.0-10.0 sec 6.35 GBytes 5.45 Gbits/sec
客户端# iperf -c 服务器端IP -p 12345 -i 1 -t 10 -w 20K
------------------------------------------------------------
Client connecting to 172.20.0.113, TCP port 12345
TCP window size: 40.0 KByte (WARNING: requested 20.0 KByte)
------------------------------------------------------------
[ 3] local 172.20.0.114 port 56796 connected with 172.20.0.113 port 12345
[ ID] Interval Transfer Bandwidth
[ 3] 0.0- 1.0 sec 614 MBytes 5.15 Gbits/sec
[ 3] 1.0- 2.0 sec 622 MBytes 5.21 Gbits/sec
[ 3] 2.0- 3.0 sec 646 MBytes 5.42 Gbits/sec
[ 3] 3.0- 4.0 sec 644 MBytes 5.40 Gbits/sec
[ 3] 4.0- 5.0 sec 651 MBytes 5.46 Gbits/sec
[ 3] 5.0- 6.0 sec 652 MBytes 5.47 Gbits/sec
[ 3] 6.0- 7.0 sec 669 MBytes 5.61 Gbits/sec
[ 3] 7.0- 8.0 sec 670 MBytes 5.62 Gbits/sec
[ 3] 8.0- 9.0 sec 667 MBytes 5.59 Gbits/sec
[ 3] 9.0-10.0 sec 668 MBytes 5.60 Gbits/sec
[ 3] 0.0-10.0 sec 6.35 GBytes 5.45 Gbits/sec
2.使用复杂度过高的命令
首先,第一步,你需要去查看一下 Redis 的慢日志(slowlog)。
Redis 提供了慢日志命令的统计功能,它记录了有哪些命令在执行时耗时比较久。
查看 Redis 慢日志之前,你需要设置慢日志的阈值。例如,设置慢日志的阈值为 5 毫秒,并且保留最近 500 条慢日志记录:
# 命令执行耗时超过 5 毫秒,记录慢日志
CONFIG SET slowlog-log-slower-than 5000
# 只保留最近 500 条慢日志
CONFIG SET slowlog-max-len 500
1.经常使用 O(N) 以上复杂度的命令,例如 SORT、SUNION、ZUNIONSTORE 聚合类命令
2.使用 O(N) 复杂度的命令,但 N 的值非常大
第一种情况导致变慢的原因在于,Redis 在操作内存数据时,时间复杂度过高,要花费更多的 CPU 资源。
第二种情况导致变慢的原因在于,Redis 一次需要返回给客户端的数据过多,更多时间花费在数据协议的组装和网络传输过程中。
另外,我们还可以从资源使用率层面来分析,如果你的应用程序操作 Redis 的 OPS 不是很大,但 Redis 实例的 CPU 使用率却很高,那么很有可能是使用了复杂度过高的命令导致的。
3.操作bigkey
如果你查询慢日志发现,并不是复杂度过高的命令导致的,而都是 SET / DEL 这种简单命令出现在慢日志中,那么你就要怀疑你的实例否写入了 bigkey。
redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 1
-------- summary -------
Sampled 829675 keys in the keyspace!
Total key length in bytes is 10059825 (avg len 12.13)
Biggest string found 'key:291880' has 10 bytes
Biggest list found 'mylist:004' has 40 items
Biggest set found 'myset:2386' has 38 members
Biggest hash found 'myhash:3574' has 37 fields
Biggest zset found 'myzset:2704' has 42 members
36313 strings with 363130 bytes (04.38% of keys, avg size 10.00)
787393 lists with 896540 items (94.90% of keys, avg size 1.14)
1994 sets with 40052 members (00.24% of keys, avg size 20.09)
1990 hashs with 39632 fields (00.24% of keys, avg size 19.92)
1985 zsets with 39750 members (00.24% of keys, avg size 20.03)
这里我需要提醒你的是,当执行这个命令时,要注意 2 个问题:
1.对线上实例进行 bigkey 扫描时,Redis 的 OPS 会突增,为了降低扫描过程中对 Redis 的影响,最好控制一下扫描的频率,指定 -i 参数即可,它表示扫描过程中每次扫描后休息的时间间隔,单位是秒
2.扫描结果中,对于容器类型(List、Hash、Set、ZSet)的 key,只能扫描出元素最多的 key。但一个 key 的元素多,不一定表示占用内存也多,你还需要根据业务情况,进一步评估内存占用情况。
4.集中过期
如果你发现,平时在操作 Redis 时,并没有延迟很大的情况发生,但在某个时间点突然出现一波延时,其现象表现为:变慢的时间点很有规律,例如某个整点,或者每间隔多久就会发生一波延迟。
如果是出现这种情况,那么你需要排查一下,业务代码中是否存在设置大量 key 集中过期的情况。
如果有大量的 key 在某个固定时间点集中过期,在这个时间点访问 Redis 时,就有可能导致延时变大。
Redis 的过期数据采用被动过期 + 主动过期两种策略:
1.被动过期:只有当访问某个 key 时,才判断这个 key 是否已过期,如果已过期,则从实例中删除
2.主动过期:Redis 内部维护了一个定时任务,默认每隔 100 毫秒(1秒10次)就会从全局的过期哈希表中随机取出 20 个 key,然后删除其中过期的 key,如果过期 key 的比例超过了 25%,则继续重复此过程,直到过期 key 的比例下降到 25% 以下,或者这次任务的执行耗时超过了 25 毫秒,才会退出循环
注意,这个主动过期 key 的定时任务,是在 Redis 主线程中执行的。
也就是说如果在执行主动过期的过程中,出现了需要大量删除过期 key 的情况,那么此时应用程序在访问 Redis 时,必须要等待这个过期任务执行结束,Redis 才可以服务这个客户端请求。
如果此时需要过期删除的是一个 bigkey,那么这个耗时会更久。而且,这个操作延迟的命令并不会记录在慢日志中。
因为慢日志中只记录一个命令真正操作内存数据的耗时,而 Redis 主动删除过期 key 的逻辑,是在命令真正执行之前执行的。
5.实例内存达到上限
当我们把 Redis 当做纯缓存使用时,通常会给这个实例设置一个内存上限 maxmemory,然后设置一个数据淘汰策略。
当 Redis 内存达到 maxmemory 后,每次写入新的数据之前,Redis 必须先从实例中踢出一部分数据,让整个实例的内存维持在 maxmemory 之下,然后才能把新数据写进来。
这个踢出旧数据的逻辑也是需要消耗时间的,而具体耗时的长短,要取决于你配置的淘汰策略:
- allkeys-lru:不管 key 是否设置了过期,淘汰最近最少访问的 key
- volatile-lru:只淘汰最近最少访问、并设置了过期时间的 key
- allkeys-random:不管 key 是否设置了过期,随机淘汰 key
- volatile-random:只随机淘汰设置了过期时间的 key
- allkeys-ttl:不管 key 是否设置了过期,淘汰即将过期的 key
- noeviction:不淘汰任何 key,实例内存达到 maxmeory 后,再写入新数据直接返回错误
- allkeys-lfu:不管 key 是否设置了过期,淘汰访问频率最低的 key(4.0+版本支持)
- volatile-lfu:只淘汰访问频率最低、并设置了过期时间 key(4.0+版本支持)
一般最常使用的是 allkeys-lru / volatile-lru 淘汰策略,它们的处理逻辑是,每次从实例中随机取出一批 key(这个数量可配置),然后淘汰一个最少访问的 key,之后把剩下的 key 暂存到一个池子中,继续随机取一批 key,并与之前池子中的 key 比较,再淘汰一个最少访问的 key。以此往复,直到实例内存降到 maxmemory 之下。
需要注意的是,Redis 的淘汰数据的逻辑与删除过期 key 的一样,也是在命令真正执行之前执行的,也就是说它也会增加我们操作 Redis 的延迟,而且,写 OPS 越高,延迟也会越明显。

如果此时你的 Redis 实例中还存储了 bigkey,那么在淘汰删除 bigkey 释放内存时,也会耗时比较久。
6.fork耗时严重
当 Redis 开启了后台 RDB 和 AOF rewrite 后,在执行时,它们都需要主进程创建出一个子进程进行数据的持久化。
主进程创建子进程,会调用操作系统提供的 fork 函数。
而 fork 在执行过程中,主进程需要拷贝自己的内存页表给子进程,如果这个实例很大,那么这个拷贝的过程也会比较耗时。
而且这个 fork 过程会消耗大量的 CPU 资源,在完成 fork 之前,整个 Redis 实例会被阻塞住,无法处理任何客户端请求。
如果此时你的 CPU 资源本来就很紧张,那么 fork 的耗时会更长,甚至达到秒级,这会严重影响 Redis 的性能。
那如何确认确实是因为 fork 耗时导致的 Redis 延迟变大呢?
你可以在 Redis 上执行 INFO 命令,查看 latest_fork_usec 项,单位微秒。
# 上一次 fork 耗时,单位微秒
latest_fork_usec:59477
这个时间就是主进程在 fork 子进程期间,整个实例阻塞无法处理客户端请求的时间。
如果你发现这个耗时很久,就要警惕起来了,这意味在这期间,你的整个 Redis 实例都处于不可用的状态。
除了数据持久化会生成 RDB 之外,当主从节点第一次建立数据同步时,主节点也创建子进程生成 RDB,然后发给从节点进行一次全量同步,所以,这个过程也会对 Redis 产生性能影响。
7.开启内存大页
除了上面讲到的子进程 RDB 和 AOF rewrite 期间,fork 耗时导致的延时变大之外,这里还有一个方面也会导致性能问题,这就是操作系统是否开启了内存大页机制。
什么是内存大页?
我们都知道,应用程序向操作系统申请内存时,是按内存页进行申请的,而常规的内存页大小是 4KB。
Linux 内核从 2.6.38 开始,支持了内存大页机制,该机制允许应用程序以 2MB 大小为单位,向操作系统申请内存。
应用程序每次向操作系统申请的内存单位变大了,但这也意味着申请内存的耗时变长。
这对 Redis 会有什么影响呢?
当 Redis 在执行后台 RDB,采用 fork 子进程的方式来处理。但主进程 fork 子进程后,此时的主进程依旧是可以接收写请求的,而进来的写请求,会采用 Copy On Write(写时复制)的方式操作内存数据。
也就是说,主进程一旦有数据需要修改,Redis 并不会直接修改现有内存中的数据,而是先将这块内存数据拷贝出来,再修改这块新内存的数据,这就是所谓的「写时复制」。
写时复制你也可以理解成,谁需要发生写操作,谁就需要先拷贝,再修改。
这样做的好处是,父进程有任何写操作,并不会影响子进程的数据持久化(子进程只持久化 fork 这一瞬间整个实例中的所有数据即可,不关心新的数据变更,因为子进程只需要一份内存快照,然后持久化到磁盘上)。
但是请注意,主进程在拷贝内存数据时,这个阶段就涉及到新内存的申请,如果此时操作系统开启了内存大页,那么在此期间,客户端即便只修改 10B 的数据,Redis 在申请内存时也会以 2MB 为单位向操作系统申请,申请内存的耗时变长,进而导致每个写请求的延迟增加,影响到 Redis 性能。
同样地,如果这个写请求操作的是一个 bigkey,那主进程在拷贝这个 bigkey 内存块时,一次申请的内存会更大,时间也会更久。可见,bigkey 在这里又一次影响到了性能。
8.开启AOF
前面我们分析了 RDB 和 AOF rewrite 对 Redis 性能的影响,主要关注点在 fork 上。
其实,关于数据持久化方面,还有影响 Redis 性能的因素,这次我们重点来看 AOF 数据持久化。
如果你的 AOF 配置不合理,还是有可能会导致性能问题。
当 Redis 开启 AOF 后,其工作原理如下:
1.Redis 执行写命令后,把这个命令写入到 AOF 文件内存中(write 系统调用)
2.Redis 根据配置的 AOF 刷盘策略,把 AOF 内存数据刷到磁盘上(fsync 系统调用)
为了保证 AOF 文件数据的安全性,Redis 提供了 3 种刷盘机制:
1.appendfsync always:主线程每次执行写操作后立即刷盘,此方案会占用比较大的磁盘 IO 资源,但数据安全性最高
2.appendfsync no:主线程每次写操作只写内存就返回,内存数据什么时候刷到磁盘,交由操作系统决定,此方案对性能影响最小,但数据安全性也最低,Redis 宕机时丢失的数据取决于操作系统刷盘时机
3.appendfsync everysec:主线程每次写操作只写内存就返回,然后由后台线程每隔 1 秒执行一次刷盘操作(触发fsync系统调用),此方案对性能影响相对较小,但当 Redis 宕机时会丢失 1 秒的数据
看到这里,我猜你肯定和大多数人的想法一样,选比较折中的方案 appendfsync everysec 就没问题了吧?
这个方案优势在于,Redis 主线程写完内存后就返回,具体的刷盘操作是放到后台线程中执行的,后台线程每隔 1 秒把内存中的数据刷到磁盘中。
这种方案既兼顾了性能,又尽可能地保证了数据安全,是不是觉得很完美?
但是,这里我要给你泼一盆冷水了,采用这种方案你也要警惕一下,因为这种方案还是存在导致 Redis 延迟变大的情况发生,甚至会阻塞整个 Redis。
你试想这样一种情况:当 Redis 后台线程在执行 AOF 文件刷盘时,如果此时磁盘的 IO 负载很高,那这个后台线程在执行刷盘操作(fsync系统调用)时就会被阻塞住。
此时的主线程依旧会接收写请求,紧接着,主线程又需要把数据写到文件内存中(write 系统调用),当主线程使用后台子线程执行了一次 fsync,需要再次把新接收的操作记录写回磁盘时,如果主线程发现上一次的 fsync 还没有执行完,那么它就会阻塞。所以,如果后台子线程执行的 fsync 频繁阻塞的话(比如 AOF 重写占用了大量的磁盘 IO 带宽),主线程也会阻塞,导致 Redis 性能变慢。
看到了么?在这个过程中,主线程依旧有阻塞的风险。
所以,尽管你的 AOF 配置为 appendfsync everysec,也不能掉以轻心,要警惕磁盘压力过大导致的 Redis 有性能问题。
那什么情况下会导致磁盘 IO 负载过大?以及如何解决这个问题呢?
我总结了以下几种情况,你可以参考进行问题排查:
1.子进程正在执行 AOF rewrite,这个过程会占用大量的磁盘 IO 资源
2.有其他应用程序在执行大量的写文件操作,也会占用磁盘 IO 资源
对于情况1,说白了就是,Redis 的 AOF 后台子线程刷盘操作,撞上了子进程 AOF rewrite!
9.绑定CPU
很多时候,我们在部署服务时,为了提高服务性能,降低应用程序在多个 CPU 核心之间的上下文切换带来的性能损耗,通常采用的方案是进程绑定 CPU 的方式提高性能。
我们都知道,一般现代的服务器会有多个 CPU,而每个 CPU 又包含多个物理核心,每个物理核心又分为多个逻辑核心,每个物理核下的逻辑核共用 L1/L2 Cache。
而 Redis Server 除了主线程服务客户端请求之外,还会创建子进程、子线程。
其中子进程用于数据持久化,而子线程用于执行一些比较耗时操作,例如异步释放 fd、异步 AOF 刷盘、异步 lazy-free 等等。
如果你把 Redis 进程只绑定了一个 CPU 逻辑核心上,那么当 Redis 在进行数据持久化时,fork 出的子进程会继承父进程的 CPU 使用偏好。
而此时的子进程会消耗大量的 CPU 资源进行数据持久化(把实例数据全部扫描出来需要耗费CPU),这就会导致子进程会与主进程发生 CPU 争抢,进而影响到主进程服务客户端请求,访问延迟变大。
这就是 Redis 绑定 CPU 带来的性能问题。
10.使用Swap
如果你发现 Redis 突然变得非常慢,每次的操作耗时都达到了几百毫秒甚至秒级,那此时你就需要检查 Redis 是否使用到了 Swap,在这种情况下 Redis 基本上已经无法提供高性能的服务了。
什么是 Swap?为什么使用 Swap 会导致 Redis 的性能下降?
如果你对操作系统有些了解,就会知道操作系统为了缓解内存不足对应用程序的影响,允许把一部分内存中的数据换到磁盘上,以达到应用程序对内存使用的缓冲,这些内存数据被换到磁盘上的区域,就是 Swap。
问题就在于,当内存中的数据被换到磁盘上后,Redis 再访问这些数据时,就需要从磁盘上读取,访问磁盘的速度要比访问内存慢几百倍!
尤其是针对 Redis 这种对性能要求极高、性能极其敏感的数据库来说,这个操作延时是无法接受的。
此时,你需要检查 Redis 机器的内存使用情况,确认是否存在使用了 Swap。
你可以通过以下方式来查看 Redis 进程是否使用到了 Swap:
# 先找到 Redis 的进程 ID
$ ps -aux | grep redis-server
# 查看 Redis Swap 使用情况
$ cat /proc/$pid/smaps | egrep '^(Swap|Size)'
输出结果如下:
Size: 1256 kB
Swap: 0 kB
Size: 4 kB
Swap: 0 kB
Size: 132 kB
Swap: 0 kB
Size: 63488 kB
Swap: 0 kB
Size: 132 kB
Swap: 0 kB
Size: 65404 kB
Swap: 0 kB
Size: 1921024 kB
Swap: 0 kB
每一行 Size 表示 Redis 所用的一块内存大小,Size 下面的 Swap 就表示这块 Size 大小的内存,有多少数据已经被换到磁盘上了,如果这两个值相等,说明这块内存的数据都已经完全被换到磁盘上了。
如果只是少量数据被换到磁盘上,例如每一块 Swap 占对应 Size 的比例很小,那影响并不是很大。如果是几百兆甚至上 GB 的内存被换到了磁盘上,那么你就需要警惕了,这种情况 Redis 的性能肯定会急剧下降。
11.碎片整理
Redis 的数据都存储在内存中,当我们的应用程序频繁修改 Redis 中的数据时,就有可能会导致 Redis 产生内存碎片。
内存碎片会降低 Redis 的内存使用率,我们可以通过执行 INFO 命令,得到这个实例的内存碎片率:
# Memory
used_memory:5709194824
used_memory_human:5.32G
used_memory_rss:8264855552
used_memory_rss_human:7.70G
...
mem_fragmentation_ratio:1.45
这个内存碎片率是怎么计算的?
很简单,mem_fragmentation_ratio = used_memory_rss / used_memory。
其中 used_memory 表示 Redis 存储数据的内存大小,而 used_memory_rss 表示操作系统实际分配给 Redis 进程的大小。
如果 mem_fragmentation_ratio > 1.5,说明内存碎片率已经超过了 50%,这时我们就需要采取一些措施来降低内存碎片了。
解决的方案一般如下:
1.如果你使用的是 Redis 4.0 以下版本,只能通过重启实例来解决
2.如果你使用的是 Redis 4.0 版本,它正好提供了自动碎片整理的功能,可以通过配置开启碎片自动整理。
但是,开启内存碎片整理,它也有可能会导致 Redis 性能下降。
原因在于,Redis 的碎片整理工作是也在主线程中执行的,当其进行碎片整理时,必然会消耗 CPU 资源,产生更多的耗时,从而影响到客户端的请求。
所以,当你需要开启这个功能时,最好提前测试评估它对 Redis 的影响。
Redis 碎片整理的参数配置如下:
# 开启自动内存碎片整理(总开关)
activedefrag yes# 内存使用 100MB 以下,不进行碎片整理
active-defrag-ignore-bytes 100mb# 内存碎片率超过 10%,开始碎片整理
active-defrag-threshold-lower 10
# 内存碎片率超过 100%,尽最大努力碎片整理
active-defrag-threshold-upper 100# 内存碎片整理占用 CPU 资源最小百分比
active-defrag-cycle-min 1
# 内存碎片整理占用 CPU 资源最大百分比
active-defrag-cycle-max 25# 碎片整理期间,对于 List/Set/Hash/ZSet 类型元素一次 Scan 的数量
active-defrag-max-scan-fields 1000
二、Redis如何优化
1.慢查询优化
1.尽量不使用 O(N) 以上复杂度过高的命令,对于数据的聚合操作,放在客户端做
2.执行 O(N) 命令,保证 N 尽量的小(推荐 N <= 300),每次获取尽量少的数据,让 Redis 可以及时处理返回
2.集中过期优化
一般有两种方案来规避这个问题:
1.集中过期 key 增加一个随机过期时间,把集中过期的时间打散,降低 Redis 清理过期 key 的压力
2.如果你使用的 Redis 是 4.0 以上版本,可以开启 lazy-free 机制,当删除过期 key 时,把释放内存的操作放到后台线程中执行,避免阻塞主线程。
第一种方案,在设置 key 的过期时间时,增加一个随机时间,伪代码可以这么写:
# 在过期时间点之后的 5 分钟内随机过期掉
redis.expireat(key, expire_time + random(300))
第二种方案,Redis 4.0 以上版本,开启 lazy-free 机制:
# 释放过期 key 的内存,放到后台线程执行
lazyfree-lazy-expire yes
运维层面,你需要把 Redis 的各项运行状态数据监控起来,在 Redis 上执行 INFO 命令就可以拿到这个实例所有的运行状态数据。
在这里我们需要重点关注 expired_keys 这一项,它代表整个实例到目前为止,累计删除过期 key 的数量。
你需要把这个指标监控起来,当这个指标在很短时间内出现了突增,需要及时报警出来,然后与业务应用报慢的时间点进行对比分析,确认时间是否一致,如果一致,则可以确认确实是因为集中过期 key 导致的延迟变大。
3.实例内存达到上限优化
1.避免存储 bigkey,降低释放内存的耗时
2.淘汰策略改为随机淘汰,随机淘汰比 LRU 要快很多(视业务情况调整)
3.拆分实例,把淘汰 key 的压力分摊到多个实例上
4.如果使用的是 Redis 4.0 以上版本,开启 layz-free 机制,把淘汰 key 释放内存的操作放到后台线程中执行(配置 lazyfree-lazy-eviction = yes)
4.fork耗时严重优化
1.控制 Redis 实例的内存:尽量在 10G 以下,执行 fork 的耗时与实例大小有关,实例越大,耗时越久。
2.合理配置数据持久化策略:在 slave 节点执行 RDB 备份,推荐在低峰期执行,而对于丢失数据不敏感的业务(例如把 Redis 当做纯缓存使用),可以关闭 AOF 和 AOF rewrite。
3.Redis 实例不要部署在虚拟机上:fork 的耗时也与系统也有关,虚拟机比物理机耗时更久。
4.降低主从库全量同步的概率:适当调大 repl-backlog-size 参数,避免主从全量同步。
从建立同步时,优先检测是否可以尝试只同步部分数据,这种情况就是针对于之前已经建立好了复制链路,只是因为故障导致临时断开,故障恢复后重新建立同步时,为了避免全量同步的资源消耗,Redis会优先尝试部分数据同步,如果条件不符合,才会触发全量同步。这个判断依据就是在master上维护的复制缓冲区大小,如果这个缓冲区配置的过小,很有可能在主从断开复制的这段时间内,master产生的写入导致复制缓冲区的数据被覆盖,重新建立同步时的slave需要同步的offset位置在master的缓冲区中找不到,那么此时就会触发全量同步。如何避免这种情况?解决方案就是适当调大复制缓冲区repl-backlog-size的大小,这个缓冲区的大小默认为1MB,如果实例写入量比较大,可以针对性调大此配置。5.多核CPU优化
那如何解决这个问题呢?
如果你确实想要绑定 CPU,可以优化的方案是,不要让 Redis 进程只绑定在一个 CPU 逻辑核上,而是绑定在多个逻辑核心上,而且,绑定的多个逻辑核心最好是同一个物理核心,这样它们还可以共用 L1/L2 Cache。
当然,即便我们把 Redis 绑定在多个逻辑核心上,也只能在一定程度上缓解主线程、子进程、后台线程在 CPU 资源上的竞争。
因为这些子进程、子线程还是会在这多个逻辑核心上进行切换,存在性能损耗。
如何再进一步优化?
可能你已经想到了,我们是否可以让主线程、子进程、后台线程,分别绑定在固定的 CPU 核心上,不让它们来回切换,这样一来,他们各自使用的 CPU 资源互不影响。
其实,这个方案 Redis 官方已经想到了。
Redis 在 6.0 版本已经推出了这个功能,我们可以通过以下配置,对主线程、后台线程、后台 RDB 进程、AOF rewrite 进程,绑定固定的 CPU 逻辑核心:
Redis6.0 前绑定CPU核
taskset -c 0 ./redis-server
Redis6.0 后绑定CPU核
# Redis Server 和 IO 线程绑定到 CPU核心 0,2,4,6
server_cpulist 0-7:2
# 后台子线程绑定到 CPU核心 1,3
bio_cpulist 1,3
# 后台 AOF rewrite 进程绑定到 CPU 核心 8,9,10,11
aof_rewrite_cpulist 8-11
# 后台 RDB 进程绑定到 CPU 核心 1,10,11
# bgsave_cpulist 1,10-1
如果你使用的正好是 Redis 6.0 版本,就可以通过以上配置,来进一步提高 Redis 性能。
这里我需要提醒你的是,一般来说,Redis 的性能已经足够优秀,除非你对 Redis 的性能有更加严苛的要求,否则不建议你绑定 CPU。
6.查看Redis内存是否发生Swap
$ redis-cli info | grep process_idprocess_id: 5332
然后,进入 Redis 所在机器的 /proc 目录下的该进程目录中:
$ cd /proc/5332
最后,运行下面的命令,查看该 Redis 进程的使用情况。在这儿,我只截取了部分结果:
$cat smaps | egrep '^(Swap|Size)'
Size: 584 kB
Swap: 0 kB
Size: 4 kB
Swap: 4 kB
Size: 4 kB
Swap: 0 kB
Size: 462044 kB
Swap: 462008 kB
Size: 21392 kB
Swap: 0 kB
一旦发生内存 swap,最直接的解决方法就是增加机器内存。如果该实例在一个 Redis 切片集群中,可以增加 Redis 集群的实例个数,来分摊每个实例服务的数据量,进而减少每个实例所需的内存量。
7.内存大页
如果采用了内存大页,那么,即使客户端请求只修改 100B 的数据,Redis 也需要拷贝 2MB 的大页。相反,如果是常规内存页机制,只用拷贝 4KB。两者相比,你可以看到,当客户端请求修改或新写入数据较多时,内存大页机制将导致大量的拷贝,这就会影响 Redis 正常的访存操作,最终导致性能变慢。
首先,我们要先排查下内存大页。方法是:在 Redis 实例运行的机器上执行如下命令:
$ cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
如果执行结果是 always,就表明内存大页机制被启动了;如果是 never,就表示,内存大页机制被禁止。
在实际生产环境中部署时,我建议你不要使用内存大页机制,操作也很简单,只需要执行下面的命令就可以了:
echo never /sys/kernel/mm/transparent_hugepage/enabled
其实,操作系统提供的内存大页机制,其优势是,可以在一定程序上降低应用程序申请内存的次数。
但是对于 Redis 这种对性能和延迟极其敏感的数据库来说,我们希望 Redis 在每次申请内存时,耗时尽量短,所以我不建议你在 Redis 机器上开启这个机制。
8.删除使用Lazy Free
支持版本:Redis 4.0+
8.1 主动删除键使用lazy free
UNLINK命令
127.0.0.1:7000> LLEN mylist
(integer) 2000000
127.0.0.1:7000> UNLINK mylist
(integer) 1
127.0.0.1:7000> SLOWLOG get
1) 1) (integer) 12) (integer) 15054651883) (integer) 304) 1) "UNLINK"2) "mylist"5) "127.0.0.1:17015"6) ""
注意:DEL命令,还是并发阻塞的删除操作
FLUSHALL/FLUSHDB ASYNC
127.0.0.1:7000> DBSIZE
(integer) 1812295
127.0.0.1:7000> flushall //同步清理实例数据,180万个key耗时1020毫秒
OK
(1.02s)
127.0.0.1:7000> DBSIZE
(integer) 1812637
127.0.0.1:7000> flushall async //异步清理实例数据,180万个key耗时约9毫秒
OK
127.0.0.1:7000> SLOWLOG get1) 1) (integer) 29961092) (integer) 15054659893) (integer) 9274 //指令运行耗时9.2毫秒4) 1) "flushall"2) "async"5) "127.0.0.1:20110"6) ""
8.2 被动删除键使用lazy free
lazy free应用于被动删除中,目前有4种场景,每种场景对应一个配置参数;默认都是关闭。
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
slave-lazy-flush no
lazyfree-lazy-eviction
针对redis内存使用达到maxmeory,并设置有淘汰策略时;在被动淘汰键时,是否采用lazy free机制;因为此场景开启lazy free, 可能使用淘汰键的内存释放不及时,导致redis内存超用,超过maxmemory的限制。此场景使用时,请结合业务测试。(生产环境不建议设置yes)
lazyfree-lazy-expire
针对设置有TTL的键,达到过期后,被redis清理删除时是否采用lazy free机制;此场景建议开启,因TTL本身是自适应调整的速度。
lazyfree-lazy-server-del
针对有些指令在处理已存在的键时,会带有一个隐式的DEL键的操作。如rename命令,当目标键已存在,redis会先删除目标键,如果这些目标键是一个big key,那就会引入阻塞删除的性能问题。此参数设置就是解决这类问题,建议可开启。
slave-lazy-flush
针对slave进行全量数据同步,slave在加载master的RDB文件前,会运行flushall来清理自己的数据场景, 参数设置决定是否采用异常flush机制。如果内存变动不大,建议可开启。可减少全量同步耗时,从而减少主库因输出缓冲区爆涨引起的内存使用增长。
8.3 lazy free的监控
lazy free能监控的数据指标,只有一个值:lazyfree_pending_objects,表示redis执行lazy free操作,在等待被实际回收内容的键个数。并不能体现单个大键的元素个数或等待lazy free回收的内存大小。所以此值有一定参考值,可监测redis lazy free的效率或堆积键数量;比如在flushall async场景下会有少量的堆积。
# info memory
# Memorylazy
free_pending_objects:0**注意事项:**unlink命令入口函数unlinkCommand()和del调用相同函数delGenericCommand()进行删除KEY操作,使用lazy标识是否为lazyfree调用。如果是lazyfree,则调用dbAsyncDelete()函数。
但并非每次unlink命令就一定启用lazy free,redis会先判断释放KEY的代价(cost),当cost大于LAZYFREE_THRESHOLD(64)才进行lazy free.
释放key代价计算函数lazyfreeGetFreeEffort(),集合类型键,且满足对应编码,cost就是集合键的元数个数,否则cost就是1.
举例:
1 一个包含100元素的list key, 它的free cost就是100
2 一个512MB的string key, 它的free cost是1 所以可以看出,redis的lazy free的cost计算主要时间复杂度相关。
9.AOF优化
Redis 提供了一个配置项,当子进程在 AOF rewrite 期间,可以让后台子线程不执行刷盘(不触发 fsync 系统调用)操作。
这相当于在 AOF rewrite 期间,临时把 appendfsync 设置为了 none,配置如下:
# AOF rewrite 期间,AOF 后台子线程不进行刷盘操作
# 相当于在这期间,临时把 appendfsync 设置为了 none
no-appendfsync-on-rewrite yes
当然,开启这个配置项,在 AOF rewrite 期间,如果实例发生宕机,那么此时会丢失更多的数据,性能和数据安全性,你需要权衡后进行选择。
如果占用磁盘资源的是其他应用程序,那就比较简单了,你需要定位到是哪个应用程序在大量写磁盘,然后把这个应用程序迁移到其他机器上执行就好了,避免对 Redis 产生影响。
当然,如果你对 Redis 的性能和数据安全都有很高的要求,那么建议从硬件层面来优化,更换为 SSD 磁盘,提高磁盘的 IO 能力,保证 AOF 期间有充足的磁盘资源可以使用。同时尽可能让Redis运行在独立的机器上。
10.Swap优化
1.增加机器的内存,让 Redis 有足够的内存可以使用
2.整理内存空间,释放出足够的内存供 Redis 使用,然后释放 Redis 的 Swap,让 Redis 重新使用内存
释放 Redis 的 Swap 过程通常要重启实例,为了避免重启实例对业务的影响,一般会先进行主从切换,然后释放旧主节点的 Swap,重启旧主节点实例,待从库数据同步完成后,再进行主从切换即可。
预防的办法就是,你需要对 Redis 机器的内存和 Swap 使用情况进行监控,在内存不足或使用到 Swap 时报警出来,及时处理。
三、Redis变慢了排查步骤
1、获取 Redis 实例在当前环境下的基线性能。
2、是否用了慢查询命令?如果是的话,就使用其他命令替代慢查询命令,或者把聚合计算命令放在客户端做。
3、是否对过期 key 设置了相同的过期时间?对于批量删除的 key,可以在每个 key 的过期时间上加一个随机数,避免同时删除。
4、是否存在 bigkey?对于 bigkey 的删除操作,如果你的 Redis 是 4.0 及以上的版本,可以直接利用异步线程机制减少主线程阻塞;如果是 Redis 4.0 以前的版本,可以使用 SCAN 命令迭代删除;对于 bigkey 的集合查询和聚合操作,可以使用 SCAN 命令在客户端完成。
5、Redis AOF 配置级别是什么?业务层面是否的确需要这一可靠性级别?如果我们需要高性能,同时也允许数据丢失,可以将配置项 no-appendfsync-on-rewrite 设置为 yes,避免 AOF 重写和 fsync 竞争磁盘 IO 资源,导致 Redis 延迟增加。当然, 如果既需要高性能又需要高可靠性,最好使用高速固态盘作为 AOF 日志的写入盘。
6、Redis 实例的内存使用是否过大?发生 swap 了吗?如果是的话,就增加机器内存,或者是使用 Redis 集群,分摊单机 Redis 的键值对数量和内存压力。同时,要避免出现 Redis 和其他内存需求大的应用共享机器的情况。
7、在 Redis 实例的运行环境中,是否启用了透明大页机制?如果是的话,直接关闭内存大页机制就行了。
8、是否运行了 Redis 主从集群?如果是的话,把主库实例的数据量大小控制在 2~4GB,以免主从复制时,从库因加载大的 RDB 文件而阻塞。
9、是否使用了多核 CPU 或 NUMA 架构的机器运行 Redis 实例?使用多核 CPU 时,可以给 Redis 实例绑定物理核;使用 NUMA 架构时,注意把 Redis 实例和网络中断处理程序运行在同一个 CPU Socket 上。