CMU15213
- datalab
- bomb
- 已搁置
lab地址
datalab
关于位操作,补码,浮点数的,觉得有点无聊,先跳了,我觉得对着抄一抄,能理解就行了,没必要认真研究。
Introduction to CSAPP(八):Datalab
bomb
这个实验是通过看汇编代码,找到每个阶段的密码,我觉得设计的挺有趣的。
背景知识:
objdump -S bomb > bomb.asm # 反汇编结果输出到文件bomb.asm
用asm后缀在vscode可以高亮,更好看一点。gdb
break [function_name] or *[address]
在某个函数或某条指令处下断点
可以使用examine命令(简写是x)来查看内存地址中的值。x命令的语法如下所示:x/<n/f/u> <addr>n:是正整数,表示需要显示的内存单元的个数,即从当前地址向后显示n个内存单元的内容,
一个内存单元的大小由第三个参数u定义。f:表示addr指向的内存内容的输出格式,s对应输出字符串,此处需特别注意输出整型数据的格式:x 按十六进制格式显示变量.d 按十进制格式显示变量。u 按十进制格式显示无符号整型。o 按八进制格式显示变量。t 按二进制格式显示变量。a 按十六进制格式显示变量。c 按字符格式显示变量。f 按浮点数格式显示变量。u:就是指以多少个字节作为一个内存单元-unit,默认为4。u还可以用被一些字符表示:如b=1 byte, h=2 bytes,w=4 bytes,g=8 bytes.<addr>:表示内存地址。LEA是微机8086/8088系列的一条指令,取自英语Load effect address——取有效地址,也就是取偏移地址。在微机8086/8088中有20位物理地址,由16位段基址向左偏移4位再与偏移地址之和得到。地址传送指令之一。
指令格式:LEA 目的,源
指令功能:取源操作数地址的偏移量,并把它传送到目的操作数所在的单元
lea是“load effective address”的缩写,简单的说,lea指令可以用来将一个内存地址直接赋给目的操作数,
例如:lea eax,[ebx+8]就是将ebx+8这个值直接赋给eax,而不是把ebx+8处的内存地址里的数据赋给eax。
而mov指令则恰恰相反,例如:mov eax,[ebx+8]则是把内存地址为ebx+8处的数据赋给eax。注意目的与源的位置可能不一样
windows下汇编和linux下汇编这个参数顺序是反的JE ;等于则跳转
JNE ;不等于则跳转JZ ;为 0 则跳转
JNZ ;不为 0 则跳转JA ;无符号大于则跳转
JNA ;无符号不大于则跳转
JAE ;无符号大于等于则跳转
JNAE ;无符号不大于等于则跳转JG ;有符号大于则跳转
JNG ;有符号不大于则跳转
JGE ;有符号大于等于则跳转
JNGE ;有符号不大于等于则跳转JB ;无符号小于则跳转
JNB ;无符号不小于则跳转
JBE ;无符号小于等于则跳转
JNBE ;无符号不小于等于则跳转cmpl指令将两个操作数相减,但计算结果并不保存,只是根据计算结果改变eflags寄存器中的标志位。SHR(右移)指令使目的操作数逻辑右移一位,最高位用 0 填充。最低位复制到进位标志位,而进位标志位中原来的数值被丢弃
汇编语言中SAR和SHR指令都是右移指令,SAR是算数右移指令(shift arithmetic right),而SHR是逻辑右移指令(shift logical right)。两者的区别在于SAR右移时保留操作数的符号,即用符号位来补足,而SHR右移时总是用0来补足。64位寄存器:rax
32位寄存器:eax
16位寄存器:ax
8位寄存器:ah,almovzbl指令负责拷贝一个字节,并用0填充其目的操作数中的其余各位,这种扩展方式叫“零扩展”。
movsbl指令负责拷贝一个字节,并用源操作数的最高位填充其目的操作数中的其余各位,这种扩展方式叫“符号扩展”FS寄存器指向当前活动线程的TEB结构(线程结构)
偏移 说明
000 指向SEH链指针
004 线程堆栈顶部
008 线程堆栈底部
00C SubSystemTib
010 FiberData
014 ArbitraryUserPointer
018 FS段寄存器在内存中的镜像地址
020 进程PID
024 线程ID
02C 指向线程局部存储指针
030 PEB结构地址(进程结构)
034 上个错误号fs:0x28:金丝雀,防止栈溢出(gdb) i registers 查看寄存器的值
学 Win32 汇编[28] - 跳转指令: JMP、JECXZ、JA、JB、JG、JL、JE、JZ、JS、JC、JO、JP 等
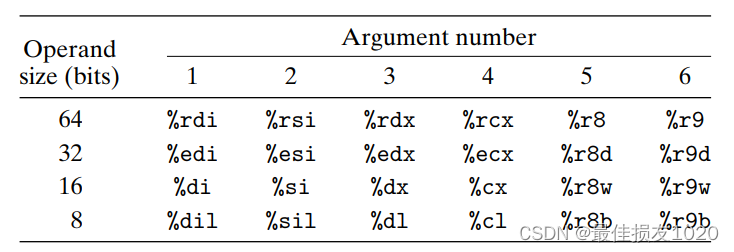
函数参数使用的寄存器
汇编代码指令有一个字符的后缀,表明操作数的大小

AT&T汇编
绝大多数 Linux 程序员以前只接触过DOS/Windows 下的汇编语言,这些汇编代码都是 Intel 风格的。但在 Unix 和 Linux 系统中,更多采用的还是 AT&T 格式,两者在语法格式上有着很大的不同
在 AT&T 汇编格式中,寄存器名要加上 ‘%’ 作为前缀 pushl %eax
在 AT&T 汇编格式中,用 ‘$’ 前缀表示一个立即操作数 pushl $1
目标操作数在源操作数的右边 movl $1,%eax
操作数的字长由操作符的最后一个字母决定 b,w,l
绝对转移和调用指令(jmp/call)的操作数前要加上’*'作为前缀
远程转移指令和远程子调用指令的操作码,在 AT&T 汇编格式中为 “ljmp” 和 “lcall”
内存寻址:section:disp(base, index, scale) ——由于 Linux 工作在保护模式下,用的是 32 位线性地址,所以在计算地址时不用考虑段基址和偏移量,而是采用如下的地址计算方法:
disp + base + index * scale
AT&T汇编
金丝雀
GCC在产生的代码中加人了一种栈保护者机制,来检测缓冲区越界。其思想是在栈帧中任何局部缓冲区与栈状态之间存储一个特殊的金丝雀( canary)值
这个金丝雀值,也称为哨兵值,是在程序每次运行时随机产生的,因此,攻击者很难猜出这个哨兵值。在恢复寄存器状态和从函数返回之前,程序检查这个金丝雀值是否被该函数的某个操作或者该函数调用的某个函数的某个操作改变了。如果是的,那么程序异常中止。
面试官不讲武德,居然让我讲讲蠕虫和金丝雀!
phase 1:
/* Hmm... Six phases must be more secure than one phase! */
input = read_line(); /* Get input */
phase_1(input); /* Run the phase */
phase_defused(); /* Drat! They figured it out!step1:反汇编
objdump -S bomb > bomb.asm # 反汇编结果输出到文件bomb.asm400e32: e8 67 06 00 00 callq 40149e <read_line>400e37: 48 89 c7 mov %rax,%rdi # 将输入字符串的起始地址移入rdi400e3a: e8 a1 00 00 00 callq 400ee0 <phase_1>0000000000400ee0 <phase_1>:400ee0: 48 83 ec 08 sub $0x8,%rsp400ee4: be 00 24 40 00 mov $0x402400,%esi # 对esi赋值 400ee9: e8 4a 04 00 00 callq 401338 <strings_not_equal>400eee: 85 c0 test %eax,%eax400ef0: 74 05 je 400ef7 <phase_1+0x17>400ef2: e8 43 05 00 00 callq 40143a <explode_bomb>400ef7: 48 83 c4 08 add $0x8,%rsp400efb: c3 retq
观察strings_not_equal函数,此时函数有两个参数,分别为输入字符串的起始地址与给点字符串的起始地址,可以看给定字符串的起始地址就是0x402400,在gdb中输出该内存地址的字符串。
(gdb) x/s 0x402400
0x402400: "Border relations with Canada have never been better."
故phase 1的答案为Border relations with Canada have never been better.
phase 2:
首先看read_six_numbers函数
000000000040145c <read_six_numbers>:40145c: 48 83 ec 18 sub $0x18,%rsp401460: 48 89 f2 mov %rsi,%rdx # num1401463: 48 8d 4e 04 lea 0x4(%rsi),%rcx # num2401467: 48 8d 46 14 lea 0x14(%rsi),%rax 40146b: 48 89 44 24 08 mov %rax,0x8(%rsp) # num6401470: 48 8d 46 10 lea 0x10(%rsi),%rax401474: 48 89 04 24 mov %rax,(%rsp) # num5 在栈顶401478: 4c 8d 4e 0c lea 0xc(%rsi),%r9 # num440147c: 4c 8d 46 08 lea 0x8(%rsi),%r8 # num3401480: be c3 25 40 00 mov $0x4025c3,%esi #格式字符串:"%d %d %d %d %d %d"401485: b8 00 00 00 00 mov $0x0,%eax40148a: e8 61 f7 ff ff callq 400bf0 <__isoc99_sscanf@plt>40148f: 83 f8 05 cmp $0x5,%eax401492: 7f 05 jg 401499 <read_six_numbers+0x3d>401494: e8 a1 ff ff ff callq 40143a <explode_bomb>401499: 48 83 c4 18 add $0x18,%rsp40149d: c3 retq
如果以rsi为基准,则六个输入数字的地址分别为rsi + 0 4 8 12 16 20
不过我不知道第一个寄存器rdi传的是什么?scanf还需要其他的参数吗?
看错了,原来是sscanf函数,rdi就是输入字符串的起始地址
/*C 库函数 int sscanf(const char *str, const char *format, ...) 从字符串读取格式化输入。*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>int main()
{int day, year;char weekday[20], month[20], dtm[100];strcpy( dtm, "Saturday March 25 1989" );sscanf( dtm, "%s %s %d %d", weekday, month, &day, &year );printf("%s %d, %d = %s\n", month, day, year, weekday );return(0);
}
然后回到phase_2函数
全部以rsp为基准,看起来更清晰
0000000000400efc <phase_2>:400efc: 55 push %rbp400efd: 53 push %rbx400efe: 48 83 ec 28 sub $0x28,%rsp400f02: 48 89 e6 mov %rsp,%rsi400f05: e8 52 05 00 00 callq 40145c <read_six_numbers>400f0a: 83 3c 24 01 cmpl $0x1,(%rsp) # 此时[0] = 1400f0e: 74 20 je 400f30 <phase_2+0x34> # 跳转到400f30400f10: e8 25 05 00 00 callq 40143a <explode_bomb>400f15: eb 19 jmp 400f30 <phase_2+0x34>400f17: 8b 43 fc mov -0x4(%rbx),%eax 400f1a: 01 c0 add %eax,%eax400f1c: 39 03 cmp %eax,(%rbx) # 这三行语句表示[addr + 4] = 2 * [addr] 400f1e: 74 05 je 400f25 <phase_2+0x29>400f20: e8 15 05 00 00 callq 40143a <explode_bomb>400f25: 48 83 c3 04 add $0x4,%rbx # 一直加4 ,而后与24对比400f29: 48 39 eb cmp %rbp,%rbx400f2c: 75 e9 jne 400f17 <phase_2+0x1b>400f2e: eb 0c jmp 400f3c <phase_2+0x40>400f30: 48 8d 5c 24 04 lea 0x4(%rsp),%rbx # 将4 与 24 对比400f35: 48 8d 6c 24 18 lea 0x18(%rsp),%rbp400f3a: eb db jmp 400f17 <phase_2+0x1b> # 跳到400f17400f3c: 48 83 c4 28 add $0x28,%rsp400f40: 5b pop %rbx400f41: 5d pop %rbp400f42: c3 retq
这代码逻辑用c语言表示就是这样
[0] = 1
addr = 4;
while(addr < 24){[addr] = [addr - 4] + [addr - 4];addr += 4
}
也就是说6个数字分别是1 2 4 8 16 32
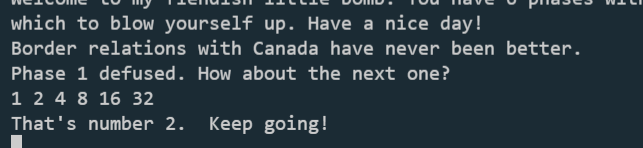
phase 3:
400e65: e8 a6 fc ff ff callq 400b10 <puts@plt>400e6a: e8 2f 06 00 00 callq 40149e <read_line>400e6f: 48 89 c7 mov %rax,%rdi 400e72: e8 cc 00 00 00 callq 400f43 <phase_3>0000000000400f43 <phase_3>:400f43: 48 83 ec 18 sub $0x18,%rsp400f47: 48 8d 4c 24 0c lea 0xc(%rsp),%rcx # num2 400f4c: 48 8d 54 24 08 lea 0x8(%rsp),%rdx # num1400f51: be cf 25 40 00 mov $0x4025cf,%esi # x/s:"%d %d"400f56: b8 00 00 00 00 mov $0x0,%eax400f5b: e8 90 fc ff ff callq 400bf0 <__isoc99_sscanf@plt>400f60: 83 f8 01 cmp $0x1,%eax # 输入的个数大于1才可以400f63: 7f 05 jg 400f6a <phase_3+0x27>400f65: e8 d0 04 00 00 callq 40143a <explode_bomb>400f6a: 83 7c 24 08 07 cmpl $0x7,0x8(%rsp) # num1 <= 7 400f6f: 77 3c ja 400fad <phase_3+0x6a>400f71: 8b 44 24 08 mov 0x8(%rsp),%eax400f75: ff 24 c5 70 24 40 00 jmpq *0x402470(,%rax,8) # 跳转表400f7c: b8 cf 00 00 00 mov $0xcf,%eax # 207400f81: eb 3b jmp 400fbe <phase_3+0x7b>400f83: b8 c3 02 00 00 mov $0x2c3,%eax400f88: eb 34 jmp 400fbe <phase_3+0x7b>400f8a: b8 00 01 00 00 mov $0x100,%eax400f8f: eb 2d jmp 400fbe <phase_3+0x7b>400f91: b8 85 01 00 00 mov $0x185,%eax400f96: eb 26 jmp 400fbe <phase_3+0x7b>400f98: b8 ce 00 00 00 mov $0xce,%eax400f9d: eb 1f jmp 400fbe <phase_3+0x7b>400f9f: b8 aa 02 00 00 mov $0x2aa,%eax400fa4: eb 18 jmp 400fbe <phase_3+0x7b>400fa6: b8 47 01 00 00 mov $0x147,%eax400fab: eb 11 jmp 400fbe <phase_3+0x7b>400fad: e8 88 04 00 00 callq 40143a <explode_bomb>400fb2: b8 00 00 00 00 mov $0x0,%eax400fb7: eb 05 jmp 400fbe <phase_3+0x7b>400fb9: b8 37 01 00 00 mov $0x137,%eax 400fbe: 3b 44 24 0c cmp 0xc(%rsp),%eax # num2需等于400fc2: 74 05 je 400fc9 <phase_3+0x86>400fc4: e8 71 04 00 00 callq 40143a <explode_bomb>400fc9: 48 83 c4 18 add $0x18,%rsp400fcd: c3 retq
phase 3最关键的部分便是在jmpq语句,q表示后面操作数为8个字节。按我的理解rax寄存器中应该存储的为字符串的起始地址,也就是num1的地址,但0x402470(,%rax,8)能猜到是0x402470 + num1 * 8,为啥变成了num1的值了呢?
更新: 没看到前面一行mov 0x8(%rsp),%eax,对64位寄存器的低32位赋值会使高32位清零吗?
由于num1 <= 7,故地址也在0x402470 ~ 0x402470 + 7 * 8之间,我也不知道是否大于0,看下面语句使用的为ja,是无符号跳转,觉得应该大于0(实际上就算可以小于0也无所谓,选一个值通过就行)
jmpq *0x402470(,%rax,8) # 跳转表
故输出0x402470 ~ 0x402470 + 7 * 8地址存储的地址
(gdb) x/8xg 0x402470 # 8表示显示内存单元的个数,x表示内容输出格式为16进制,g指8个字节作为一个内存单元
0x402470: 0x0000000000400f7c 0x0000000000400fb9
0x402480: 0x0000000000400f83 0x0000000000400f8a
0x402490: 0x0000000000400f91 0x0000000000400f98
0x4024a0: 0x0000000000400f9f 0x0000000000400fa6
选择最简单的num1 = 0,则跳到0x400f7c处,eax = 207,num2 = 207。通过!

phase 4
000000000040100c <phase_4>:40100c: 48 83 ec 18 sub $0x18,%rsp401010: 48 8d 4c 24 0c lea 0xc(%rsp),%rcx # num2401015: 48 8d 54 24 08 lea 0x8(%rsp),%rdx # num140101a: be cf 25 40 00 mov $0x4025cf,%esi # 0x4025cf: "%d %d"40101f: b8 00 00 00 00 mov $0x0,%eax401024: e8 c7 fb ff ff callq 400bf0 <__isoc99_sscanf@plt>401029: 83 f8 02 cmp $0x2,%eax # 输入两个数40102c: 75 07 jne 401035 <phase_4+0x29>40102e: 83 7c 24 08 0e cmpl $0xe,0x8(%rsp) # num1 <= 14401033: 76 05 jbe 40103a <phase_4+0x2e>401035: e8 00 04 00 00 callq 40143a <explode_bomb># 3个32位参数,arg1:num1 arg2:0 arg3:1440103a: ba 0e 00 00 00 mov $0xe,%edx 40103f: be 00 00 00 00 mov $0x0,%esi 401044: 8b 7c 24 08 mov 0x8(%rsp),%edi # num1401048: e8 81 ff ff ff callq 400fce <func4>40104d: 85 c0 test %eax,%eax40104f: 75 07 jne 401058 <phase_4+0x4c>401051: 83 7c 24 0c 00 cmpl $0x0,0xc(%rsp) # num2 =0401056: 74 05 je 40105d <phase_4+0x51>401058: e8 dd 03 00 00 callq 40143a <explode_bomb>40105d: 48 83 c4 18 add $0x18,%rsp401061: c3 retq
0000000000400fce <func4>:400fce: 48 83 ec 08 sub $0x8,%rsp 400fd2: 89 d0 mov %edx,%eax # eax = 14400fd4: 29 f0 sub %esi,%eax # eax = 14 - 0 400fd6: 89 c1 mov %eax,%ecx # ecx = 14 400fd8: c1 e9 1f shr $0x1f,%ecx # ecx = 14 / 2^31 = 0400fdb: 01 c8 add %ecx,%eax # eax = 14 + 0400fdd: d1 f8 sar %eax # eax = 14 / 2 = 7#ecx = rax(eax) + 1 * rsi(esi) = 7 + 1 * 0 = 7400fdf: 8d 0c 30 lea (%rax,%rsi,1),%ecx 400fe2: 39 f9 cmp %edi,%ecx # 比较num1 和 7400fe4: 7e 0c jle 400ff2 <func4+0x24>400fe6: 8d 51 ff lea -0x1(%rcx),%edx400fe9: e8 e0 ff ff ff callq 400fce <func4>400fee: 01 c0 add %eax,%eax400ff0: eb 15 jmp 401007 <func4+0x39>400ff2: b8 00 00 00 00 mov $0x0,%eax400ff7: 39 f9 cmp %edi,%ecx # 比较num1 和 7 400ff9: 7d 0c jge 401007 <func4+0x39>400ffb: 8d 71 01 lea 0x1(%rcx),%esi400ffe: e8 cb ff ff ff callq 400fce <func4>401003: 8d 44 00 01 lea 0x1(%rax,%rax,1),%eax401007: 48 83 c4 08 add $0x8,%rsp40100b: c3 retq
由于phase 3的经验,我默认对32位寄存器赋值时会使高32位清零,所以rax 与eax等价,rsi与esi等价。从格式字符串可以看出这一关又是两个数,func4是一个有3个32位参数的函数
func4(num1,0,14)
400fe2和400ff7两次分别拿num1与7对比,要求其大于大于7,小于等于7,否则就再次进入函数func4,也就是说这是一个递归函数,那最简单的值便是7了,直接跳过递归调用过程。
故num1 = 7,而cmpl $0x0,0xc(%rsp)表示num2=0。故最终答案为7 0

递归函数有点复杂,抄了一个代码过来
void func4(int x,int y,int z)
{//x in %rdi,y in %rsi,z in %rdx,t in %rax,k in %ecx//y的初始值为0,z的初始值为14int t=z-y;int k=t>>31;t=(t+k)>>1;k=t+y;if(k>x){z=k-1;func4(x,y,z);t=2t;return;}else{t=0;if(k<x){y=k+1;func4(x,y,z);t=2*t+1;return;}else{return;}}
}
CSAPP: Bomb Lab 实验解析
phase 5
0000000000401062 <phase_5>:401062: 53 push %rbx401063: 48 83 ec 20 sub $0x20,%rsp401067: 48 89 fb mov %rdi,%rbx # rbx寄存器存储字符串起始地址40106a: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax401071: 00 00 401073: 48 89 44 24 18 mov %rax,0x18(%rsp)401078: 31 c0 xor %eax,%eax40107a: e8 9c 02 00 00 callq 40131b <string_length>40107f: 83 f8 06 cmp $0x6,%eax # 代表字符串长度为6401082: 74 4e je 4010d2 <phase_5+0x70>401084: e8 b1 03 00 00 callq 40143a <explode_bomb>401089: eb 47 jmp 4010d2 <phase_5+0x70>40108b: 0f b6 0c 03 movzbl (%rbx,%rax,1),%ecx #只取一字节,将其他为清零40108f: 88 0c 24 mov %cl,(%rsp) 401092: 48 8b 14 24 mov (%rsp),%rdx 401096: 83 e2 0f and $0xf,%edx # 只保留低四位!!!401099: 0f b6 92 b0 24 40 00 movzbl 0x4024b0(%rdx),%edx # 得到0x4024b0 + rdx位置的值4010a0: 88 54 04 10 mov %dl,0x10(%rsp,%rax,1) # 存入堆栈中 4010a4: 48 83 c0 01 add $0x1,%rax4010a8: 48 83 f8 06 cmp $0x6,%rax # 执行六次这种操作4010ac: 75 dd jne 40108b <phase_5+0x29>4010ae: c6 44 24 16 00 movb $0x0,0x16(%rsp) # 加上‘/0’结束字符4010b3: be 5e 24 40 00 mov $0x40245e,%esi # 0x40245e: "flyers"4010b8: 48 8d 7c 24 10 lea 0x10(%rsp),%rdi4010bd: e8 76 02 00 00 callq 401338 <strings_not_equal> 4010c2: 85 c0 test %eax,%eax4010c4: 74 13 je 4010d9 <phase_5+0x77>4010c6: e8 6f 03 00 00 callq 40143a <explode_bomb>4010cb: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)4010d0: eb 07 jmp 4010d9 <phase_5+0x77>4010d2: b8 00 00 00 00 mov $0x0,%eax # 将eax置为0后跳转4010d7: eb b2 jmp 40108b <phase_5+0x29>4010d9: 48 8b 44 24 18 mov 0x18(%rsp),%rax4010de: 64 48 33 04 25 28 00 xor %fs:0x28,%rax4010e5: 00 00 4010e7: 74 05 je 4010ee <phase_5+0x8c>4010e9: e8 42 fa ff ff callq 400b30 <__stack_chk_fail@plt>4010ee: 48 83 c4 20 add $0x20,%rsp4010f2: 5b pop %rbx4010f3: c3 retq
这一段理解起来倒并不难,输入一个长度为6的字符串,对字符串的每一个字符(同时也是一个8位整数),取其低四位,设为off,取0x4024b0 + off地址的值。将该值存入堆栈中,最终也得到一个字符串。
故首先输出0x4024b0后16字节的内容:
(gdb) x /16cb 0x4024b0
0x4024b0: 109 'm' 97 'a' 100 'd' 117 'u' 105 'i' 101 'e' 114 'r' 115 's'
0x4024b8: 110 'n' 102 'f' 111 'o' 116 't' 118 'v' 98 'b' 121 'y' 108 'l'
目标字符串为"flyers",则输入字符串低四位的值依次为9 f e 5 6 7,查看ascii码,选取相应的字符即可。
我选择的字符为yonefg

我刚开始没注意到与操作,看到cl寄存器以为直接按8位计算,故我输出了后面126位的字符,在其中找对应字符

最终对应起来结果是"P;CLJK"。。。。
phase 6
前面几个阶段的密码难度让我对这个实验的难度产生了误判,这第六阶段的汇编代码给我看麻了都没看出来。
我只分析出前面几个约束条件,实在看麻了就去网上找博客才知道的答案。
我推出来的部分
401100: 49 89 e5 mov %rsp,%r13401103: 48 89 e6 mov %rsp,%rsi401106: e8 51 03 00 00 callq 40145c <read_six_numbers>40110b: 49 89 e6 mov %rsp,%r1440110e: 41 bc 00 00 00 00 mov $0x0,%r12d401114: 4c 89 ed mov %r13,%rbp401117: 41 8b 45 00 mov 0x0(%r13),%eax40111b: 83 e8 01 sub $0x1,%eax40111e: 83 f8 05 cmp $0x5,%eax # x-1 <5401121: 76 05 jbe 401128 <phase_6+0x34>401123: e8 12 03 00 00 callq 40143a <explode_bomb>401128: 41 83 c4 01 add $0x1,%r12d40112c: 41 83 fc 06 cmp $0x6,%r12d # 外层循环401130: 74 21 je 401153 <phase_6+0x5f>401132: 44 89 e3 mov %r12d,%ebx401135: 48 63 c3 movslq %ebx,%rax401138: 8b 04 84 mov (%rsp,%rax,4),%eax 40113b: 39 45 00 cmp %eax,0x0(%rbp) 40113e: 75 05 jne 401145 <phase_6+0x51>401140: e8 f5 02 00 00 callq 40143a <explode_bomb>401145: 83 c3 01 add $0x1,%ebx401148: 83 fb 05 cmp $0x5,%ebx # 内层循环40114b: 7e e8 jle 401135 <phase_6+0x41>40114d: 49 83 c5 04 add $0x4,%r13401151: eb c1 jmp 401114 <phase_6+0x20>
把jmp语句跳转的语句分割开来比较好看,这段代码中有两层循环,外层循环用以表示6个数字皆小于7,内层循环表示6个数字都不同
401153: 48 8d 74 24 18 lea 0x18(%rsp),%rsi401158: 4c 89 f0 mov %r14,%rax40115b: b9 07 00 00 00 mov $0x7,%ecx401160: 89 ca mov %ecx,%edx401162: 2b 10 sub (%rax),%edx401164: 89 10 mov %edx,(%rax) # 赋值为7-x 401166: 48 83 c0 04 add $0x4,%rax40116a: 48 39 f0 cmp %rsi,%rax40116d: 75 f1 jne 401160 <phase_6+0x6c>
这段代码表示堆栈上的6个数字都替换成了7-x。
之后的代码就是跳来跳去,完全看不懂了。
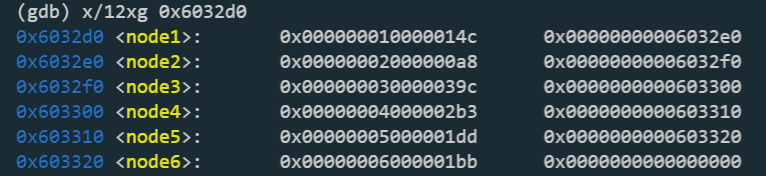
即使我随便输出了0x6032d0地址的值,也没发现node这一点,实际上我也不知道node的含义。

在看了博客1和博客2后,才知道后面是链表排序过程(但我是完全没看出来),按照博客的思路,输出0x6032d0地址的值,按它们的排定顺序得到序列{3 4 5 6 1 2},最后7-x即得到答案{4 3 2 1 6 5}

虽然知道还有秘密阶段,我还是不尝试了,下次一定。。。