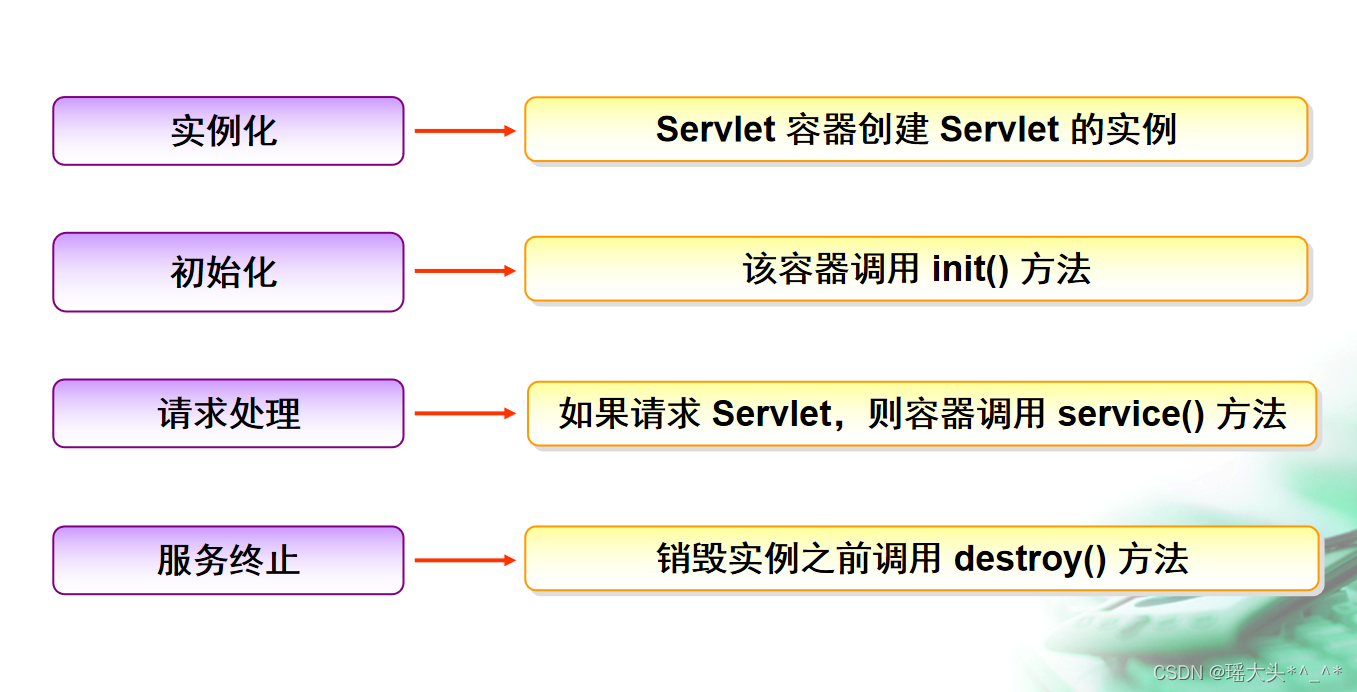
Python与大数据
随着互联网和物联网的快速发展,数据已经成为了一个非常重要的资源。人们需要对这些数据进行采集、存储、处理和分析,从而获取有价值的信息和洞见。而这些数据往往是非常大的,需要使用一些特殊的技术和工具来处理。这就是大数据技术的应用场景。
Python是一种非常适合用于大数据处理的编程语言。它具有简单易学、开发效率高、生态系统完善等优点,同时还有很多专门用于大数据处理的库和框架。在这篇文章中,我们将介绍Python与大数据的相关内容,包括Python在大数据处理中的应用、Python与Hadoop、Spark等大数据框架的集成、以及Python与人工智能的结合等。
一、Python在大数据处理中的应用
Python在大数据处理中的应用非常广泛。它可以用于数据的采集、存储、处理和分析等方面。下面我们将分别介绍Python在这些方面的应用。
1. 数据采集
Python可以用于各种类型的数据采集。它可以通过爬虫技术从网页上抓取数据,也可以通过API接口从各种数据源中获取数据。Python中的Requests库和BeautifulSoup库等工具可以帮助我们进行网页的访问和数据的解析,而Scrapy框架则可以帮助我们进行更加复杂的网页采集任务。
2. 数据存储
Python可以使用各种类型的数据库来存储数据。它支持关系型数据库、NoSQL数据库以及文件系统等多种存储方式。例如,Python中的SQLite库可以用于轻量级的关系型数据库,MongoDB库可以用于NoSQL数据库,而Hadoop库可以用于分布式文件系统。此外,Python还支持各种类型的数据格式,包括CSV、JSON、XML等,方便我们进行数据的导入和导出。
3. 数据处理和分析
Python中有很多用于数据处理和分析的库和工具。例如,NumPy库和SciPy库可以用于科学计算和数据分析,Pandas库可以用于数据的清洗、切片和统计分析,Matplotlib库和Seaborn库可以用于数据的可视化等。此外,Python还可以使用一些机器学习库和框架,例如Scikit-learn库、TensorFlow库和PyTorch库等,来进行更加复杂的数据分析和机器学习任务。
二、Python与Hadoop、Spark等大数据框架的集成
Hadoop和Spark是两种非常流行的大数据框架。它们可以用于分布式数据的处理和分析。Python也可以和这些框架集成,从而实现更加高效的大数据处理。
1. Python与Hadoop的集成
Hadoop是一个分布式文件系统和分布式计算框架。它可以用于存储和处理非常大的数据集。Python可以通过Hadoop的Java API来访问Hadoop文件系统和MapReduce计算框架。此外,Python中还有一些专门用于Hadoop的库和框架,例如Pydoop库和mrjob框架等。
2. Python与Spark的集成
Spark是一个快速、通用、内存计算引擎。它可以用于数据的处理、机器学习、图形计算等方面。Python可以与Spark集成,从而实现更加高效的大数据处理和机器学习。Python中的PySpark库可以用于与Spark的交互,将Python代码转换为Spark的任务。此外,Python还可以使用一些专门用于Spark的库和框架,例如SparkSQL和MLlib等。
三、Python与人工智能的结合
人工智能是一个非常热门的领域。Python可以用于实现各种类型的人工智能应用,包括机器学习、自然语言处理、计算机视觉等方面。下面我们将分别介绍Python在这些方面的应用。
1. 机器学习
Python中有很多用于机器学习的库和框架。例如,Scikit-learn库可以用于各种类型的机器学习任务,包括分类、回归、聚类等。TensorFlow库和PyTorch库则可以用于深度学习任务。此外,Python还可以使用一些专门用于机器学习的框架,例如Keras和MXNet等。
2. 自然语言处理
自然语言处理是一个将人工智能和语言学相结合的领域。Python中有很多用于自然语言处理的库和工具。例如,NLTK库可以用于自然语言处理的各种任务,包括分词、词性标注、命名实体识别等。SpaCy库则可以用于更加高效的自然语言处理任务。
3. 计算机视觉
计算机视觉是一个将人工智能和图像处理相结合的领域。Python中有很多用于计算机视觉的库和工具。例如,OpenCV库可以用于图像处理和计算机视觉任务,包括图像的读取、处理、特征提取等。此外,Python还可以使用一些专门用于计算机视觉的库和框架,例如TensorFlow Object Detection API和Detectron2等。
总结
Python是一个非常适合用于大数据处理和人工智能的编程语言。它具有简单易学、开发效率高、生态系统完善等优点,同时还有很多专门用于大数据处理和人工智能的库和框架。在未来,Python将会继续发挥其在数据科学和人工智能领域的优势,为人们带来更加高效和智能的数据处理和分析体验。