计算机视觉:场景识别(Scene Recognition)
- 场景识别
- 图像分类
- 特征提取
- 词袋模型
- 集成学习分类器
- 算法设计
- 结果分析
- 总结与展望
- 总结
- 展望
完整程序请移步至此链接下载
场景识别
在这个项目中,我将对15个场景数据库(Bedroom、Coast、Forest、Highway、Industrial、InsideCity、Kitchen、LivingRoom、Mountain、Office、OpenCountry、Store、Street、Suburb、TallBuilding)进行训练和测试,借助HOG特征提取构建词袋模型,并利用集成学习分类器将场景分为15个类别之一。
图像分类
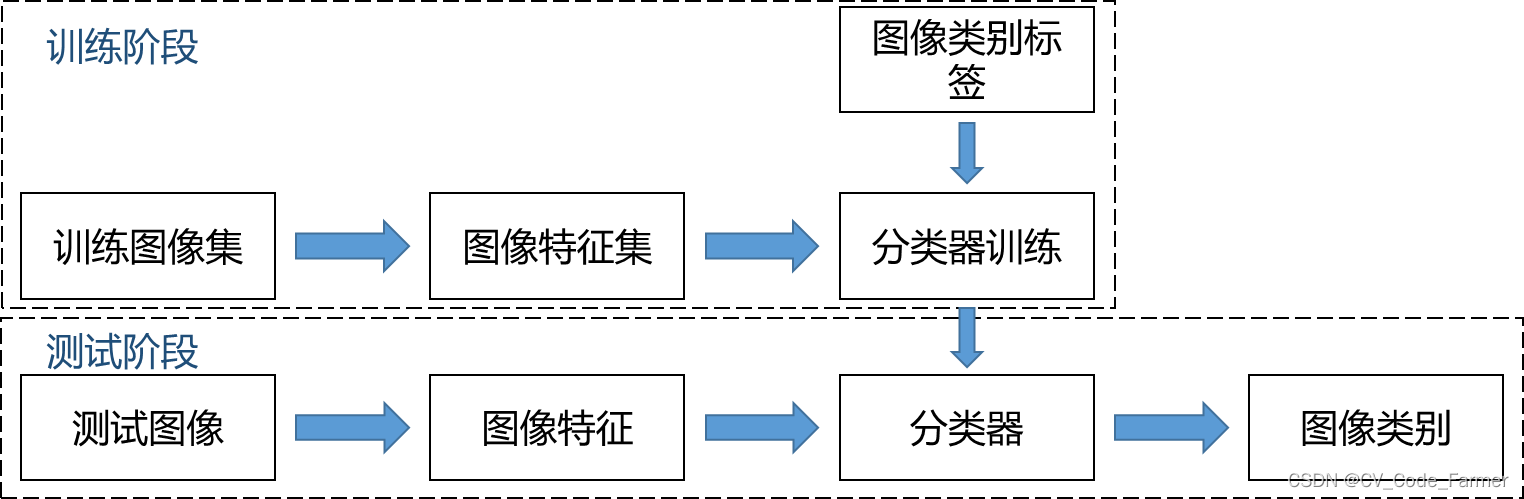
图像分类是机器视觉中一个重要的问题,其基本概念是:通过算法自动把图像划分到特定的概念类别中。图像分类算法一般分为训练和测试两个阶段,其基本流程如下图所示。
特征提取
HOG是Histogram of Oriented Gradient的缩写,是一种在计算机视觉和图像处理中用来进行目标检测的特征描述子,其特征提取的步骤如下:
(1)图像灰度化;
(2)采用Gamma校正法对输入图像进行颜色空间的标准化;
(3)计算图像每个像素的梯度(包括大小和方向);
(4)将图像分割成cell,每个cell由若干个像素组成,统计每个cell的梯度直方图,形成每个cell的特征描述子;
(5)若干个cell组成一个block,将一个block内所有cell的特征串联并归一化梯度直方图,形成block的特征描述子;
(6)设计window通过在block间滑动,组合所有块的特征描述子,生成HOG特征向量。
词袋模型
词袋模型是一种流行的图像分类技术,其灵感来源于自然语言处理对文本的识别与分类。词袋模型将一张图像转化为若干个局部特征,忽略局部特征在图像中的空间信息,并基于视觉单词频率的直方图进行分类。视觉单词的“词汇表”是通过聚类大量的局部特征而建立的,在构建好“词汇表”后利用训练集对分类器进行训练。
集成学习分类器
利用HOG特征提取与SVM分类器进行行人检测的方法是法国研究人员Dalal在2005的CVPR上提出的,已经被广泛应用于图像识别中,如今虽然有很多行人检测算法不断被提出,但基本都是以“HOG+SVM”的思路为主。
在机器学习中,我们可以把多种学习器算法集中起来,让不同算法对同一种问题都进行预测,最终少数服从多数,这种方法称为集成学习。集成学习结合多个基学习器,以获得比单一学习器更加优越的泛化性能。
在设计基于词袋模型的场景识别算法中,为了融合不同分类器,将场景识别准确率较高的线性支持向量机、随机森林和直方图梯度提升分类器三者做投票(voting),设计出一个集成学习分类器。
算法设计
针对本项目,我基于HOG对图像进行特征提取,利用词袋模型构建词汇表和由随机森林分类器、直方图梯度提升分类器和线性支持向量机分类器组合而成的集成学习分类器设计了场景识别算法。
该场景识别算法主要分为以下五步:
第一步,对图像进行局部特征向量(HOG)的提取。为了取得很好的分类效果,提取的特征向量需要具备不同程度的不变性,如旋转,缩放,平移,光照等不变性;
第二步,利用上一步得到的特征向量集,通过Mini Batch K-Means聚类算法(一种能尽量保持聚类准确性下但能大幅度降低计算时间的聚类模型,由于训练样本大,特征数目较多,采用传统的K-means进行聚类会导致计算时间过长,而Mini Batch K-Means算法是在K-means的基础上对数据进行了小批量的采样)抽取其中有代表性的向量,作为单词,形成“词汇表”;
第三步,对图像进行视觉单词的统计,一般判断图像的局部区域和某一单词的相似性是否超过某一阈值。这样即可将图像表示成单词的分布,即完成了图像的表示。
第四步,设计集成学习分类器并训练,利用图像中单词的分布进行图像分类。
第五步,建立混淆矩阵,并对识别算法进行评分并可视化。
结果分析
将多个分类器用于模型的训练,并在测试集上检测其准确率。经过对比,我所设计的分类器具有最高的准确率。
最邻近分类器:准确率(55.0%)
随机森林分类器:准确率(69.1%)
直方图梯度提升分类器:准确率(72.1%)
线性支持向量机分类器:准确率(72.7%)
Ours:准确率(74.2%)
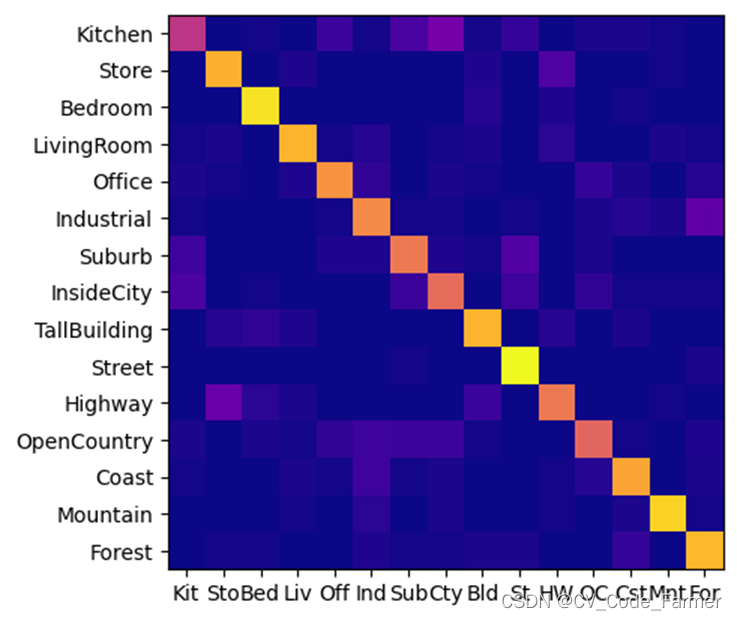
混淆矩阵是衡量分类模型准确性的最基本、最直观和最简单的方法,它是分别统计分类模型的错误类别和正确类别中的观察数量,然后将结果显示在表格中。下图为ours模型分类结果的混淆矩阵图,混淆矩阵对角线上的方格颜色越亮,其他方格颜色越暗,说明分类的结果越好。由图可以看出,Street识别准确率最高,Kitchen识别准确率最低。
将模型用于测试集,可视化其分类结果如下图所示,它总结了每个类别的准确性,并通过显示具有正确和错误识别结果的示例(包括真正例TP、假正例FP和假负例FN)来可视化结果。

总结与展望
总结
针对15个场景数据库(Bedroom、Coast、Forest、Highway、Industrial、InsideCity、Kitchen、LivingRoom、Mountain、Office、OpenCountry、Store、Street、Suburb、TallBuilding),我基于HOG对图像进行特征提取,利用词袋模型构建词汇表和由随机森林分类器、直方图梯度提升分类器和线性支持向量机分类器组合而成的集成学习分类器设计了场景识别算法,最终算法的准确率达到了74.2%。
展望
为了提高算法的准确性,可以考虑以下方面:
(1)在特征方面,考虑添加空间位置信息或提取多个特征来构建视觉单词的词汇表。
(2)在模型改进方面,考虑进一步增大数据集,并使用深度学习方法进行场景识别。