文章目录
- 第四章 决策树
- 4.1基本流程
- 4.2划分选择
- 4.2.1信息增益
- 4.2.2增益率
- 4.2.3基尼指数
- 4.3剪枝处理
- 4.3.1预剪枝
- 4.3.2后剪枝
- 4.4连续与缺失值
- 4.4.1连续值处理
- 4.4.2缺失值处理
- 4.5多变量决策树
第四章 决策树
4.1基本流程
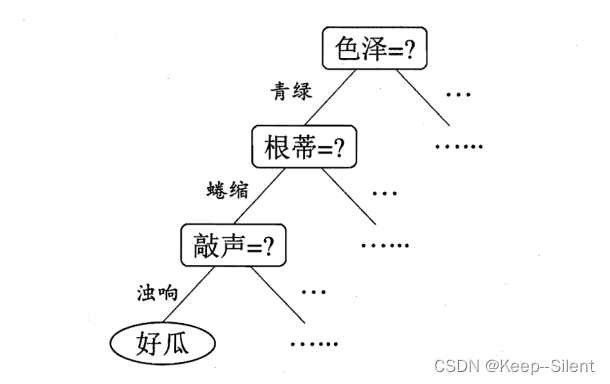
决策过程:
基本算法:

4.2划分选择
4.2.1信息增益
“信息嫡”(information entropy)是度量样本集合纯度最常用的一种指标.假定当前样本集合D中第k类样本所占的比例为 p k ( k = 1 , 2 , … , ∣ Y ∣ ) p_k(k=1,2,\ldots,|\mathcal{Y}|) pk(k=1,2,…,∣Y∣),则D的信息嫡定义为 Ent ( D ) = − ∑ k = 1 ∣ Y ∣ p k log 2 p k \text{Ent}(D)=-\sum\limits_{k=1}^{|\mathcal{Y}|}p_k\log_2p_k Ent(D)=−k=1∑∣Y∣pklog2pkEnt(D)的值越小,则D的纯度越高.
假定离散属性 a a a有 V V V个可能的取值 { a 1 , a 2 , . . . , a V } \{a^1, a^2,... ,a^V\} {a1,a2,...,aV},若使用a来对样本集D进行划分,则会产生 V V V个分支结点,其中第 v v v个分支结点包含了 D D D中所有在属性 a a a上取值为 a v a^v av的样本,记为 D v D^v Dv.我们可根据上式计算出 D v D^v Dv的信息嫡,再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重 ∣ D v ∣ / ∣ D ∣ |D^v|/|D| ∣Dv∣/∣D∣,即样本数越多的分支结点的影响越大,于是可计算出用属性 a a a对样本集D进行划分所获得的“信息增益”(information gain) G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) \mathrm{Gain}(D,a)=\mathrm{Ent}(D)-\sum\limits_{v=1}^V\frac{|D^v|}{|D|}\mathrm{Ent}(D^v) Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
例:
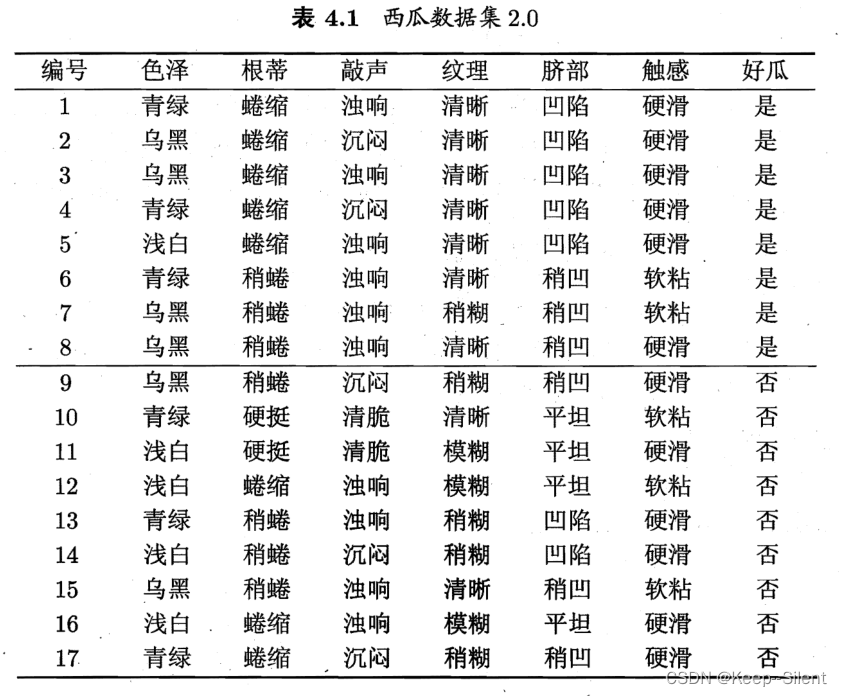
8好瓜,9坏瓜: Ent ( D ) = − ∑ k = 1 2 p k log 2 p k = − ( 8 17 log 2 8 17 + 9 17 log 2 9 17 ) = 0.998 \text{Ent}(D)=-\sum_{k=1}^2p_k\log_2p_k=-\left(\frac8{17}\log_2 \frac8{17}+ \frac9{17}\log_2 \frac9{17}\right)=0.998 Ent(D)=−k=1∑2pklog2pk=−(178log2178+179log2179)=0.998
以色泽划分子集:
- D 1 ( 色泽 = 青绿 ) : { 1 , 4 , 6 , 10 , 13 , 17 } , 好瓜 好瓜 + 坏瓜 = 3 6 D_1(色泽=青绿):\{1,4,6,10,13,17\},\frac{好瓜}{好瓜+坏瓜}=\frac{3}{6} D1(色泽=青绿):{1,4,6,10,13,17},好瓜+坏瓜好瓜=63
- D 2 ( 色泽 = 乌黑 ) : { 2 , 3 , 7 , 8 , 9 , 15 } , 好瓜 好瓜 + 坏瓜 = 3 6 D_2(色泽=乌黑):\{2,3,7,8,9,15\},\frac{好瓜}{好瓜+坏瓜}=\frac{3}{6} D2(色泽=乌黑):{2,3,7,8,9,15},好瓜+坏瓜好瓜=63
- D 3 ( 色泽 = 泽白 ) : { 5 , 11 , 12 , 14 , 16 } , 好瓜 好瓜 + 坏瓜 = 1 5 D_3(色泽=泽白):\{5,11,12,14,16\},\frac{好瓜}{好瓜+坏瓜}=\frac{1}{5} D3(色泽=泽白):{5,11,12,14,16},好瓜+坏瓜好瓜=51
信息熵: Ent ( D 1 ) = − ( 3 6 log 2 3 6 + 3 6 log 2 3 6 ) = 1.000 Ent ( D 2 ) = − ( 4 6 log 2 4 6 + 2 6 log 2 2 6 ) = 0.918 Ent ( D 3 ) = − ( 1 5 log 2 1 5 + 4 5 log 2 4 5 ) = 0.722 \begin{gathered} \text{Ent}(D^{1}) &=&-\left(\frac{3}{6}\log_{2}\frac{3}{6}+\frac{3}{6}\log_{2}\frac{3}{6}\right)&=&1.000 \\ \text{Ent}(D^{2})&=&-\left(\frac{4}{6}\text{log}_{2}\frac{4}{6}+\frac{2}{6}\text{log}_{2}\frac{2}{6}\right)&=&0.918\\ \text{Ent}(D^3)&=&-\left(\frac15\log_2\frac15+\frac45\log_2\frac45\right)&=&0.722 \end{gathered} Ent(D1)Ent(D2)Ent(D3)===−(63log263+63log263)−(64log264+62log262)−(51log251+54log254)===1.0000.9180.722
信息增益 Gain ( D , 色泽 ) \text{Gain}(D,色泽) Gain(D,色泽): Gain ( D , 色泽 ) = Ent ( D ) − ∑ v = 1 3 ∣ D v ∣ ∣ D ∣ Ent ( D v ) = 0.998 − ( 6 17 × 1.000 + 6 17 × 0.918 + 5 17 × 0.722 ) = 0.109 \begin{aligned} \text{Gain}(D,色泽)& =\text{Ent}(D)-\sum_{v=1}^3\frac{|D^v|}{|D|}\text{Ent}(D^v) \\ &=0.998-\left(\frac{6}{17}\times1.000+\frac{6}{17}\times0.918+\frac{5}{17}\times0.722\right) \\ &=0.109 \end{aligned} Gain(D,色泽)=Ent(D)−v=1∑3∣D∣∣Dv∣Ent(Dv)=0.998−(176×1.000+176×0.918+175×0.722)=0.109
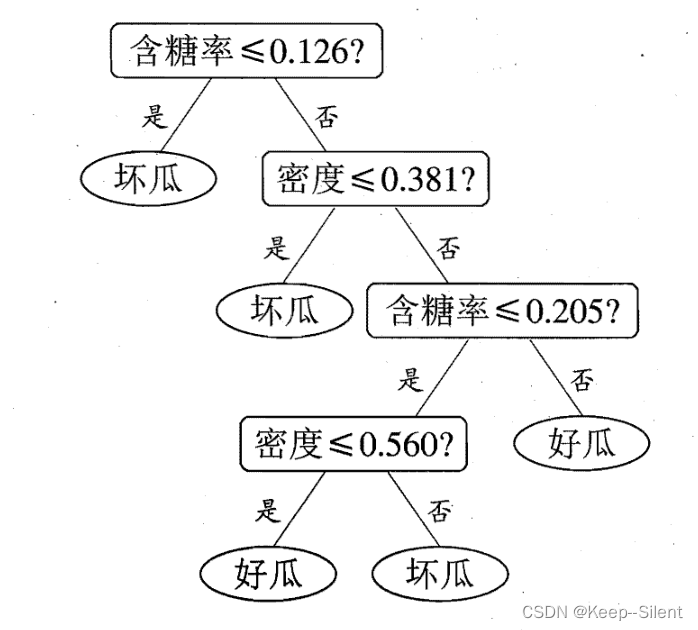
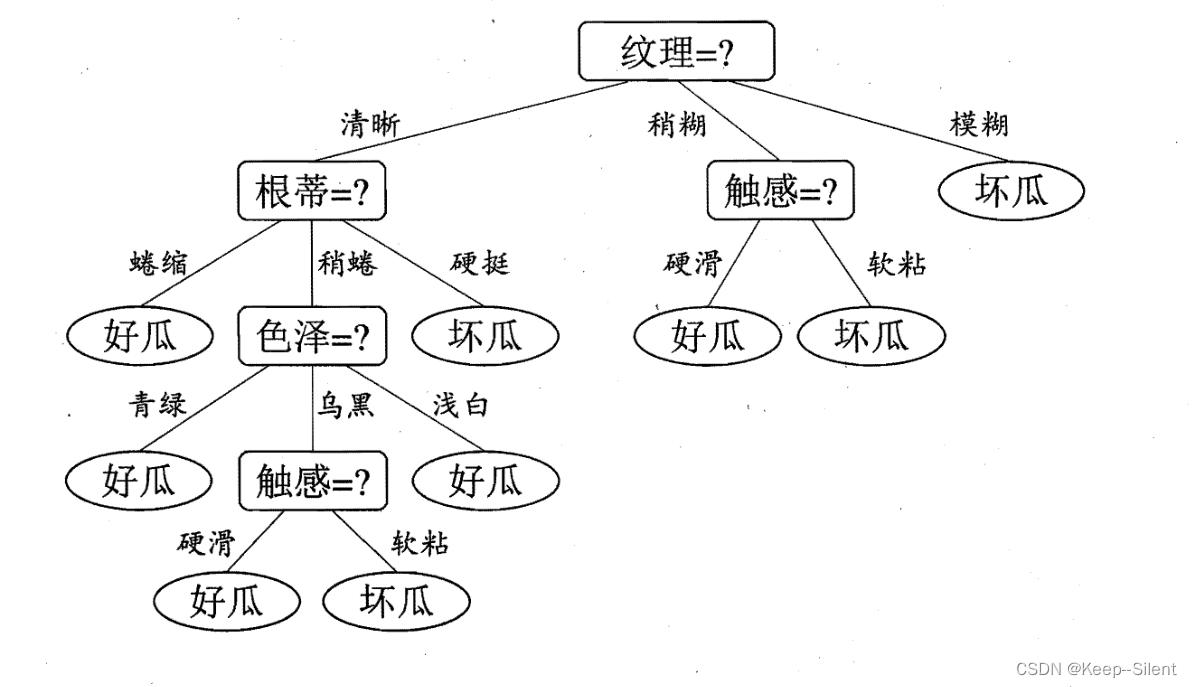
以此算出其他属性后划分决策树如下所示:
4.2.2增益率
增益率: G a i n _ r a t i o ( D , a ) = Gain ( D , a ) IV ( a ) , I V ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ log 2 ∣ D v ∣ ∣ D ∣ \begin{gathered} \mathrm{Gain\_ratio}(D,a) =\frac{\operatorname{Gain}(D,a)}{\operatorname{IV}(a)}, \\ \mathrm{IV}(a) =-\sum_{v=1}^V\frac{|D^v|}{|D|}\log_2\frac{|D^v|}{|D|} \end{gathered} Gain_ratio(D,a)=IV(a)Gain(D,a),IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
4.2.3基尼指数
CART决策树使用“基尼指数”(Gini index)来选择划分属性.数据集D的纯度可用基尼值来度量: Gini ( D ) = ∑ k = 1 ∣ Y ∣ ∑ k ′ ≠ k ∣ Y ∣ p k p k ′ = 1 − ∑ k = 1 ∣ Y ∣ p k 2 \begin{aligned} \operatorname{Gini}(D)& = \sum_{k=1}^{|Y|}\sum_{k'\neq k}^{|Y|}p_k p_{k'} \\ &= 1-\sum_{k=1}^{|{\mathcal{Y}}|}p_{k}^{2} \end{aligned} Gini(D)=k=1∑∣Y∣k′=k∑∣Y∣pkpk′=1−k=1∑∣Y∣pk2
直观来说,Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率.因此, Gini(D)越小,则数据集D的纯度越高.
属性a的基尼指数定义为 Gini_index ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ Gini ( D v ) \textrm{Gini\_index}(D,a)=\sum\limits_{v=1}^V\frac{|D^v|}{|D|}\textrm{Gini}(D^v) Gini_index(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
于是,我们在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最优划分属性,即 a ∗ = arg min a ∈ A Gini _index ( D , a ) a_*=\underset{a\in A}{\operatorname{arg}\operatorname*{min}}\operatorname{Gini}\text{\_index}(D,a) a∗=a∈AargminGini_index(D,a).
4.3剪枝处理
剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段.基本策略:“预剪枝”和“后剪枝”。
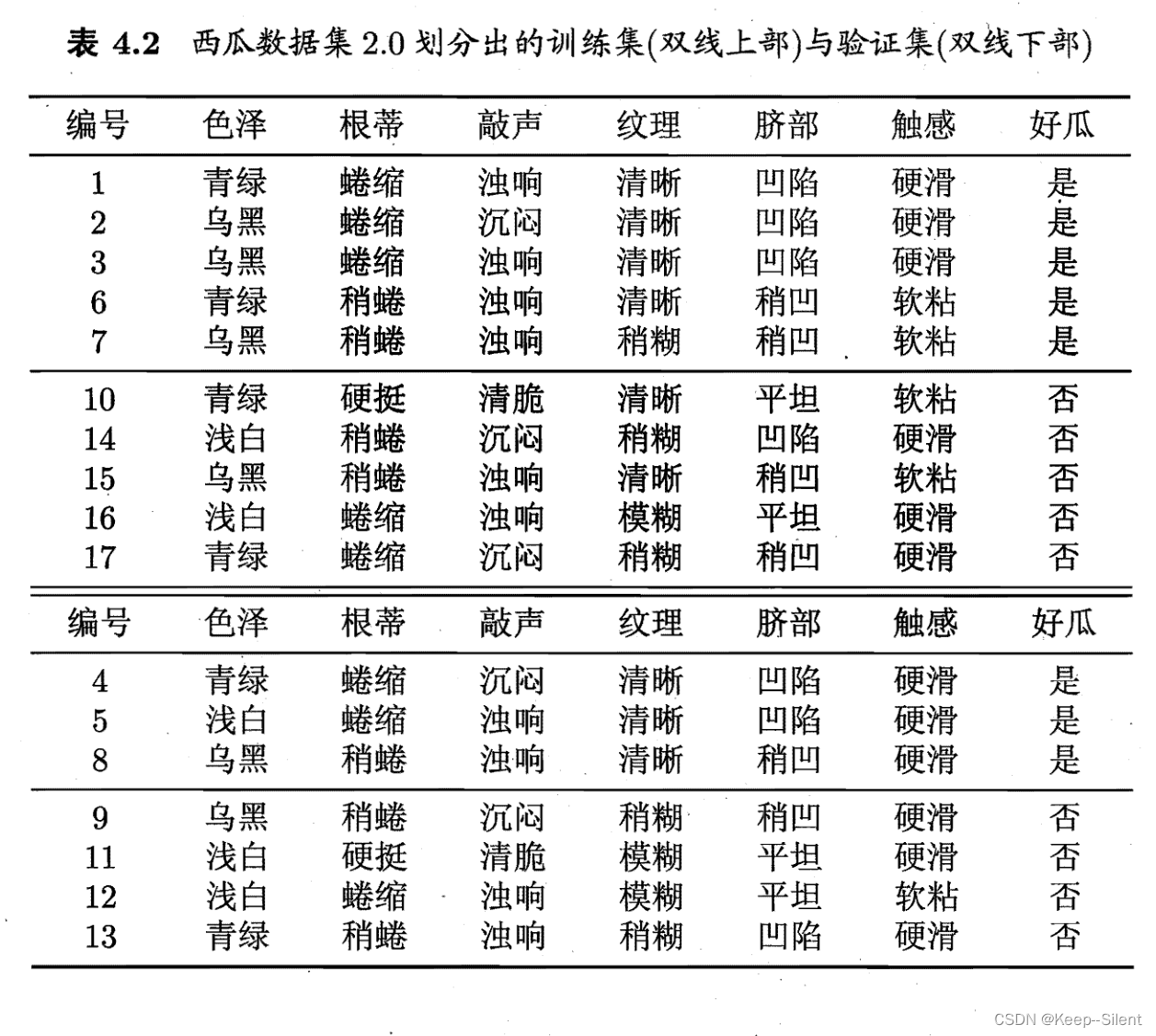
4.3.1预剪枝
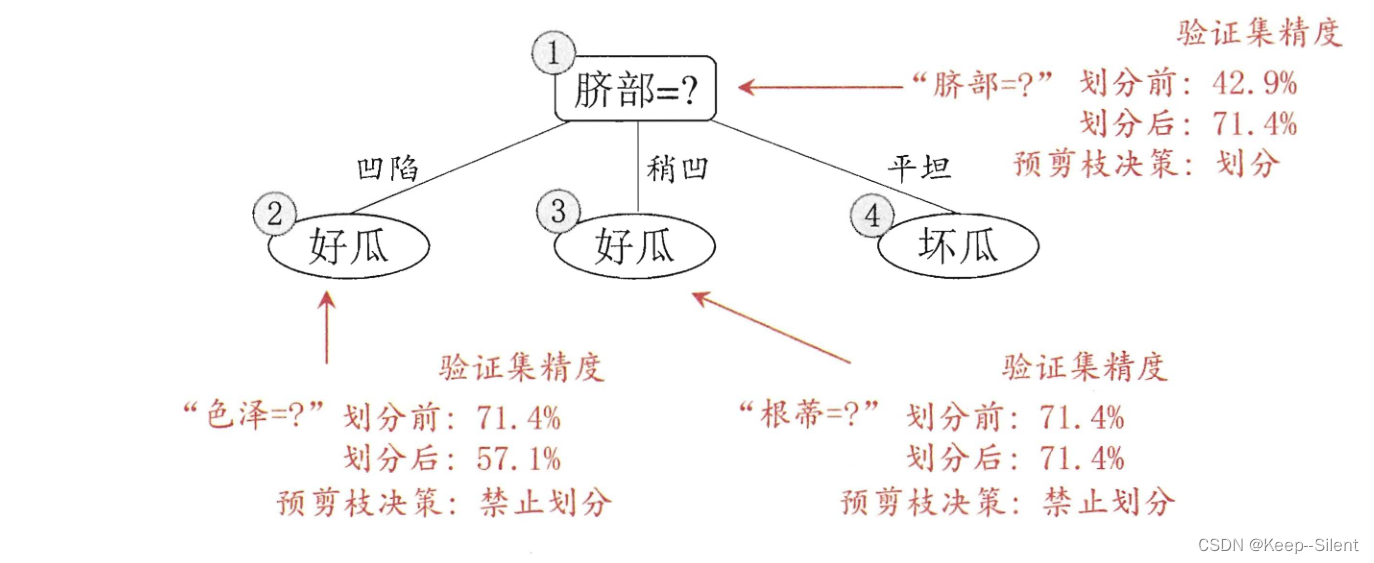
划分前,对划分前后的泛化性能进行估计:如果划分后性能不变或者性能下降,则剪枝。如下图所示
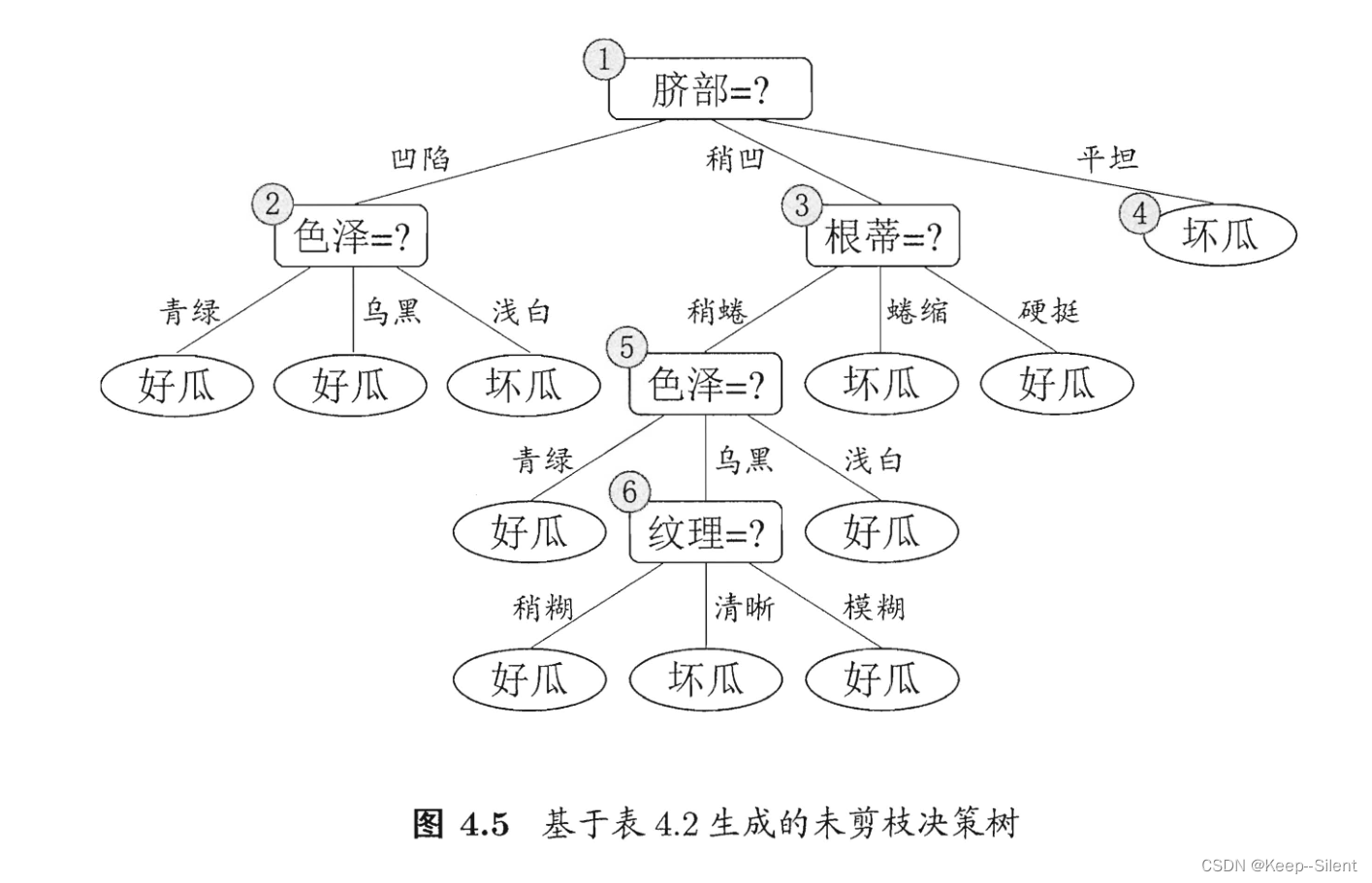
4.3.2后剪枝
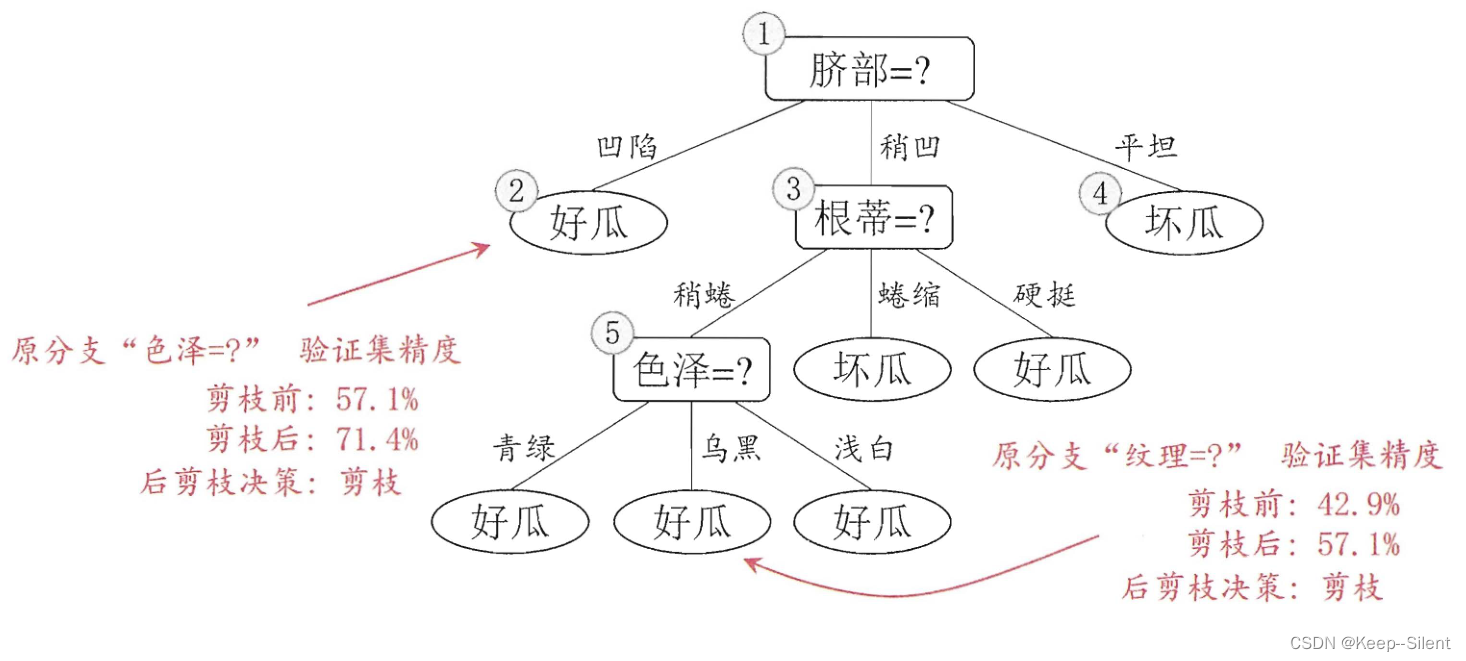
划分后,对结点进行考察:如果将其领衔的子树替换为叶结点,验证集精度提高,则剪枝。如下图所示
4.4连续与缺失值
4.4.1连续值处理
给定样本集D和连续属性 a a a,假定 a a a在D上出现了n个不同的取值,将这些值从小到大进行排序,记为 { a 1 , a 2 , … , a n } \{a^1,a^2,\dots,a^n\} {a1,a2,…,an}.基于划分点t可将D分为子集 D t − D^-_t Dt−和 D t + D^+_t Dt+,其中 D t − D^-_t Dt−,包含那些在属性 a a a上取值不大于t的样本,而 D t − D^-_t Dt−则包含那些在属性a上取值大于t的样本.显然,对相邻的属性取值 a i a^i ai与 a i + 1 a^{i+1} ai+1来说, 在区间 [ a , a i + 1 ) [a, a^{i+1}) [a,ai+1) 中取任意值所产生的划分结果相同.因此,对连续属性 a a a,我们可考察包含 n − 1 n -1 n−1个元素的候选划分点集合(把中位点作为划分) T a = { a i + a i + 1 2 ∣ 1 ⩽ i ⩽ n − 1 } T_a=\left\{\frac{a^i+a^{i+1}}{2}\mid1\leqslant i\leqslant n-1\right\} Ta={2ai+ai+1∣1⩽i⩽n−1} 划分点为: Gain ( D , a ) = max t ∈ T a Gain ( D , a , t ) = max t ∈ T a Ent ( D ) − ∑ λ ∈ { − , + } ∣ D t λ ∣ ∣ D ∣ Ent ( D t λ ) \begin{aligned} \text{Gain}(D,a)=& \max\limits_{t\in T_a} \text{Gain}(D,a,t) \\ =& \max\limits_{t\in T_a}\text{Ent}(D)-\sum\limits_{\lambda\in\{-,+\}}\frac{|D_t^\lambda|}{|D|}\text{Ent}(D_t^\lambda) \end{aligned} Gain(D,a)==t∈TamaxGain(D,a,t)t∈TamaxEnt(D)−λ∈{−,+}∑∣D∣∣Dtλ∣Ent(Dtλ)
4.4.2缺失值处理
我们需解决两个问题:
- 如何在属性值缺失的情况下进行划分属性选择?
取没有缺失值的样本子集去计算后选取
- 给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?
同一个样本以不同的概率划分到不同的子节点去
为每个样本 x x x赋予权重 w x w_x wx: ρ = ∑ x ∈ D ~ w x ∑ x ∈ D w x p ~ k = ∑ x ∈ D ~ k w x ∑ x ∈ D ~ w x r ~ v = ∑ x ∈ D ~ v w x ∑ x ∈ D ~ w x \begin{gathered} \rho= \frac{\sum_{x\in\tilde{D}}w_x}{\sum_{x\in D}w_x} \\ \widetilde{p}_k= \frac{\sum_{x\in\tilde{D}_k}w_x}{\sum_{x\in\tilde{D}}w_x} \\ \widetilde{r}_v= \frac{\sum_{x\in\tilde{D}^v}w_x}{\sum_{x\in\tilde{D}}w_x} \end{gathered} ρ=∑x∈Dwx∑x∈D~wxp k=∑x∈D~wx∑x∈D~kwxr v=∑x∈D~wx∑x∈D~vwx
信息增益为: Gain ( D , a ) = ρ × Gain ( D ~ , a ) = ρ × ( Ent ( D ~ ) − ∑ v = 1 V r ~ v Ent ( D ~ v ) ) Ent ( D ~ ) = − ∑ k = 1 ∣ Y ∣ p ~ k log 2 p ~ k \begin{aligned} \text{Gain}(D,a)& =\rho\times\text{Gain}(\tilde{D},a) \\ &=\rho\times\left(\text{Ent}\left(\tilde{D}\right)-\sum_{v=1}^{V}\tilde{r}_v\text{Ent}\left(\tilde{D}^v\right)\right) \end{aligned}\\ \text{Ent}(\tilde{D}) = -\sum^{|{Y}|} _{k=1} \tilde{p}_k\log_2\tilde{p}_k Gain(D,a)=ρ×Gain(D~,a)=ρ×(Ent(D~)−v=1∑Vr~vEnt(D~v))Ent(D~)=−k=1∑∣Y∣p~klog2p~k
4.5多变量决策树
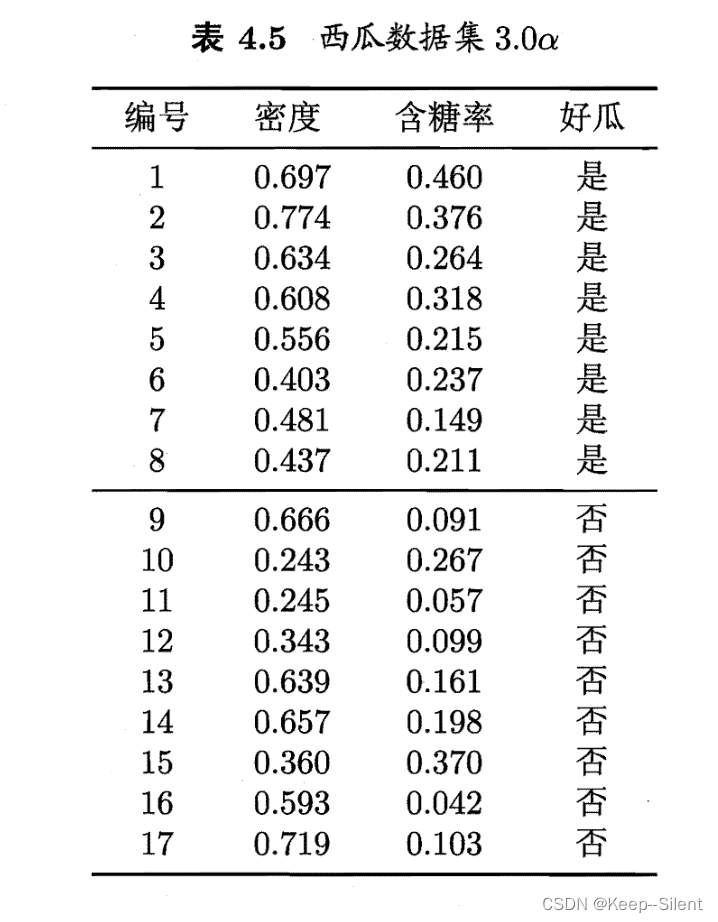
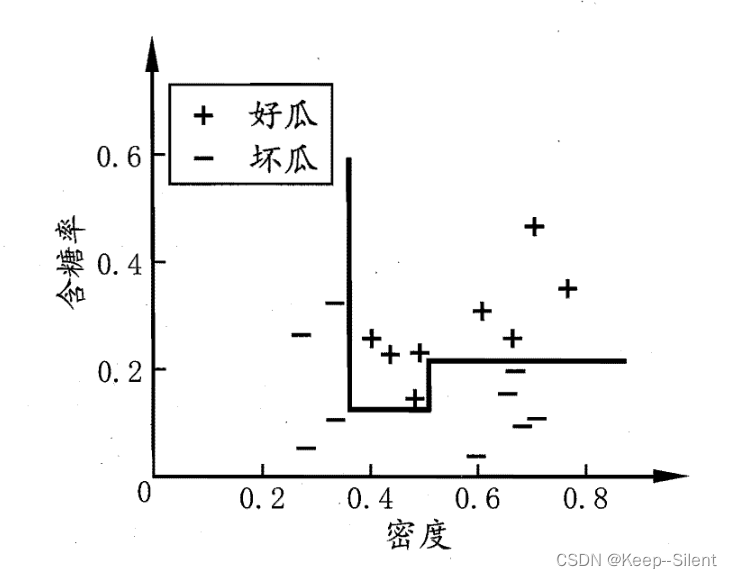
学习任务的真实分类边界比较复杂时,必须使用很多段划分才能获得较好的近似。