网络爬虫
网络爬虫是什么?是一种按照一定规则,自动抓取网页信息的脚本。对于获取公开数据,是一个效率很高的工具。本篇文章先介绍HttpClient,Jsoup这两个开源工具。
HttpClient
官方文档http://hc.apache.org/httpcomponents-client-ga/index.html
HttpClient不是浏览器,一个apache开源的库。它是一个HTTP通信库,因此它只提供了一个通用浏览器应用程序所需的功能子集。最基本的区别是HttpClient中缺少用户界面。浏览器需要一个渲染引擎来显示页面,并在显示的页面上某处解释用户输入,例如鼠标点击。
环境准备
jdk1.8
Intellij IDEA
maven
入门小Demo
创建maven工程,并导入坐标,坐标可以在https://mvnrepository.com/查找
<dependencies><!--HttpClient是apache用于处理HTTP请求和相应的开源工具。--><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.2</version></dependency><!--日志,暂时可以不要--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version></dependency></dependencies>- 带参数的的get请求
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.URIBuilder;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;import java.io.IOException;
import java.net.URISyntaxException;public class CrawcleTest {public static void main(String[] args) throws URISyntaxException {//1`.打开浏览器,创建CloseableHttpClient对象CloseableHttpClient httpClient = HttpClients.createDefault();//2.输入网址,获取execute参数HttpUriRequest,HttpGet是子类//带参数的uri,可以用URIBuilder.源路径https://so.csdn.net/so/search/s.do?q=javaURIBuilder uriBuilder = new URIBuilder("https://so.csdn.net/so/search/s.do");uriBuilder.setParameter("q","java");HttpGet httpGet = new HttpGet(uriBuilder.build());//3.按回车,发起请求,响应CloseableHttpResponse response = null;try {response = httpClient.execute(httpGet);//4.解析响应,打印数据if (response.getStatusLine().getStatusCode() == 200) {String content = EntityUtils.toString(response.getEntity(), "utf8");System.out.println(content);}} catch (IOException e) {e.printStackTrace();} finally {//关闭资源try {response.close();httpClient.close();} catch (IOException e) {e.printStackTrace();}}}
}
- post请求
HttpPost httpPost = new HttpPost("https://www.csdn.net/");- 带参数的post请求
因为post请求不能用uri传递参赛,查找api,可以使用setEntiry方法携带参数,需要一个HttpEntity 对象保存参数。......
public class CrawcleTest {public static void main(String[] args) throws URISyntaxException, UnsupportedEncodingException {//1`.打开浏览器,创建CloseableHttpClient对象CloseableHttpClient httpClient = HttpClients.createDefault();//2.输入网址,获取execute参数HttpUriRequest,HttpGet是子类HttpPost httpPost = new HttpPost("https://so.csdn.net/so/search/s.do");List<NameValuePair> list = new ArrayList<NameValuePair>();list.add(new BasicNameValuePair("q","java"));//UrlEncodedFormEntity是HttpEntity的子类httpPost.setEntity(new UrlEncodedFormEntity(list,"utf8"));//3.按回车,发起请求,响应CloseableHttpResponse response = null;......}
}运行后,控制台提示:HTTP/1.1 405 Method Not Allowed ,说明CSDN是不支持post查询的
连接池
HttpClient相当于一个浏览器,平时我们请求完链接后,并不需要关闭浏览器,相当于数据库操作,没不需要每次都关闭,数据库有连接池的概念,那么HttpClient工具也是有这个概念的。
public class CrawcleTest {public static void main(String[] args) throws URISyntaxException {//创建连接池管理器PoolingHttpClientConnectionManager manager = new PoolingHttpClientConnectionManager();//1`.打开浏览器,创建CloseableHttpClient对象,获取连接池中的对象CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(manager).build();//2.输入网址,获取execute参数HttpUriRequest,HttpGet是子类HttpGet httpGet = new HttpGet("https://www.csdn.net/");//3.按回车,发起请求,响应CloseableHttpResponse response = null;......//不用关闭ClosableHttpClient对象了,连接池进行管理了}
}- HttpClient的参数(配置浏览器参数)
- HttpGet信息(配置请求信息)
//2.输入网址,获取execute参数HttpUriRequest,HttpGet是子类
HttpGet httpGet = new HttpGet("https://www.csdn.net/");
RequestConfig config = RequestConfig.custom().setCookieSpec("uuid_tt_dd=xx_2xx8607240-15601760xx950-4600xx")//设置Cookie.setConnectTimeout(1000)//设置连接的最长时间,单位毫秒.build();
httpGet.setConfig(config);Jsoup
jsoup 是一个开源库,用于HTML解析,可直接解析某个URL地址、HTML文本内容。可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据,DOM操作特别方便。
//maven坐标
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.10.3</version>
</dependency>
Jsoup入门dome
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;import java.net.URL;public class jsoupTest {public static void main(String[] args) throws Exception {//1.解析uri地址Document document = Jsoup.parse(new URL("https://www.csdn.net/"), 1000);//2.使用标签选择器,获取title标签中的内容String title = document.getElementsByTag("title").first().text();System.out.println(title);//CSDN-专业IT技术社区}
}
我们可以看见,jsoup也可以直接获取网页信息的,跟HttpClient类似,那我们为什么还要使用HttpClient呢?模拟用户方面,设置浏览器信息方面,多线程方面。
- Jsoup解析html文件
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;import java.io.File;
public class jsoupTest {public static void main(String[] args) throws Exception {//1.获得html文件File file = new File("C:\\Users\\yingqi\\Desktop\\test.html");//2.解析文件Document document = Jsoup.parse(file,"utf8");//3.使用标签选择器,获取title标签中的内容String title = document.getElementsByTag("title").first().text();System.out.println(title);//CSDN-专业IT技术社区}
}使用DOM方式遍历文件,查找元素,例如CSDN首页:
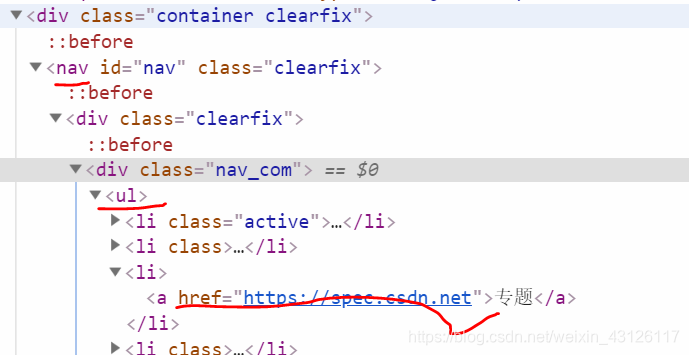
提取CSND首页信息Demo
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;public class jsoupTest {public static void main(String[] args) throws Exception {//1.解析uri地址Document document = Jsoup.parse(new URL("https://www.csdn.net/"), 1000);//元素获取Element element = document.getElementById("nav")//根据id查询元素getElementById.getElementsByTag("ul").first()//根据标签获取元素getElementsByTag.getElementsByAttributeValue("href","https://spec.csdn.net").first();//根据属性获取元素getElementsByAttributeValueSystem.out.println(element.toString());//<a href="https://spec.csdn.net">专题</a>//元素中获取数据List<String> lists = new ArrayList<String>();lists.add(element.id());//1. 从元素中获取id nulllists.add(element.className());//2. 从元素中获取className nulllists.add(element.attr("href"));//3. 从元素中获取属性的值attr https://spec.csdn.netlists.add(element.attributes().toString());//4. 从元素中获取所有属性attributes href="https://spec.csdn.net"lists.add(element.text());//5. 从元素中获取文本内容text 专题for (String list :lists) {System.out.println(list);}}
}
- 使用CSS/JQuery选择器查找元素
public class jsoupTest {public static void main(String[] args) throws Exception {//1.解析uri地址Document document = Jsoup.parse(new URL("https://www.csdn.net/"), 1000);//使用选择器查找元素Element element = document.select("#nav")//#id: 通过ID查找元素.select("ul")//tagname: 通过标签查找元素.select("[href=https://spec.csdn.net]").first();//[attr=value]: 利用属性值来查找元素System.out.println(element.toString());//<a href="https://spec.csdn.net">专题</a>//使用选择器组合查找元素Element element2 = document.select("#nav > div > div > ul > li:nth-child(3) > a").first();//查找某个父元素下的直接子元素System.out.println(element2.toString());//<a href="https://spec.csdn.net">专题</a>Element element3 = document.select("#nav ul [href=https://spec.csdn.net]").first();//任意组合System.out.println(element3.toString());//<a href="https://spec.csdn.net">专题</a>}
}总结
HttpClient、Jsoup这两个工具是绝大多数爬虫框架的基础,包括Spring中,也引入了HttpClient。so,看文档,多敲多连呗!找几个自己感兴趣的点,爬数据下来看看,后面会讲一下爬虫多线程、爬虫模拟点击、模拟登陆、代理Ip设置、去重。。。
把文章补一下,这篇文章是上个星期写的了,这几天有一件事“格力举报奥克斯空调质量",我看了一下京东这两家店铺,感觉很有意思,但是尝试爬了一下,jd页面数据绝大多数是通过Ajax请求获取的,我用浏览器调试工具(F12),发现这些Ajax很负责,并且多关键数据做了些混淆,就是直接去请求Ajax链接返回的数据还需要通过特定JS处理,得到原有数据。一直被卡住了,最后通过一个HttpUnit(带JS解析器,可以爬取动态页面),最后就把这个小Demo解决了。