实例分割算法BlendMask
论文地址:https://arxiv.org/abs/2001.00309
github代码:https://github.com/aim-uofa/AdelaiDet
我的个人空间:我的个人空间
密集实例分割
密集实例分割主要分为自上而下top-down与自下而上bottom-up两类方法:
Top-down方法
top-down方法主要表现为先检测后分割,先通过一些方法获得box区域,然后对区域内的像素进行mask提取,比如著名的Mask-RCNN就是top-down方法。
这种模型一般有以下问题:
- 特征和mask之间的局部一致性会丢失
- 冗余的特征提取,不同的bbox会重新提取一次mask
- 由于使用了缩小的特征图卷积,位置信息会损失
Bottom-up方法
bottom-up方法将整个图进行逐像素的预测(per-pixel prediction),然后按照聚类等方法,对每个像素做embedding,最后group出不同的instance。虽然保留个更好的低层特征,但是效果一般略差于top-down方法。
这种模型一般存在以下问题:
- 严重依赖逐像素预测的质量,容易导致非最优的分割
- 由于mask在低维度提取,对于复杂场景的分割能力有限
- 需要复杂的后处理方法
混合方法
BlendMask主要结合了top-down与botton-up两种思路,利用t-d方法生成实例级别的高维信息(如bbox),利用b-u方法生成per-pixel的预测进行融合。基于FCOS,融合的方法借鉴FCIS(裁剪)与YOLACT(权重加法)的思想,提出了blender模块,更好的将实例级别的全局信息与提供细节的底层特征融合。
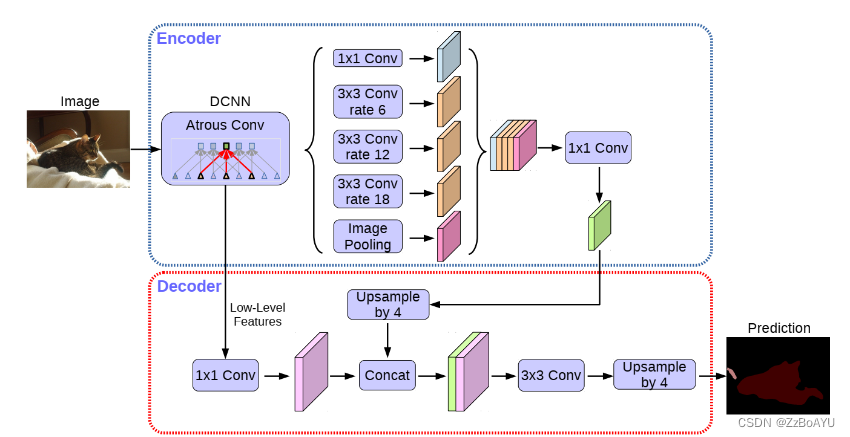
总体思路
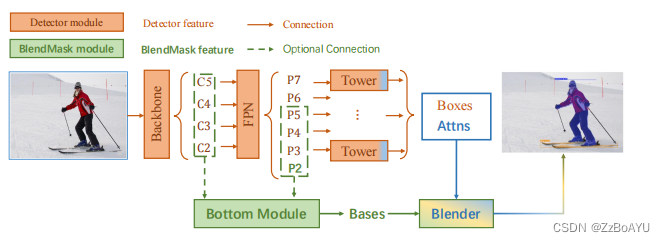
整体架构如上图所示,包含一个detector模块与BlendMask模块。detector模块直接采用的FCOS,BlendMask模块分为三部分:
- Bottom Module:对底层特征进行处理,生成的score map称为Bases
- Top Layer:串联在检测器的box head上,生成Base对应的top level attention
- Blender:将Bases与attention融合
Bottom Module
采用Deelpabv3+的decoder,包含两个输入,一个低层特征一个高层特征,对高层特征进行上采用后与低层特征融合输出,
bottom输出的feature特征为:(N * K * H/s * W/s),N为channel,K为bases的数量,(H,W)为输入的size,s为scroe的步长。
Top Layer
在检测的特征金字塔的每一层后都加了一层卷积,用来预测top-level attentions(A),输出的特征为:(N * (K*M*M)) * H_i * W_i),M*M为attention的分辨率,即对应的base的每个像素点的权重值,包含的粒度更细。
Blender
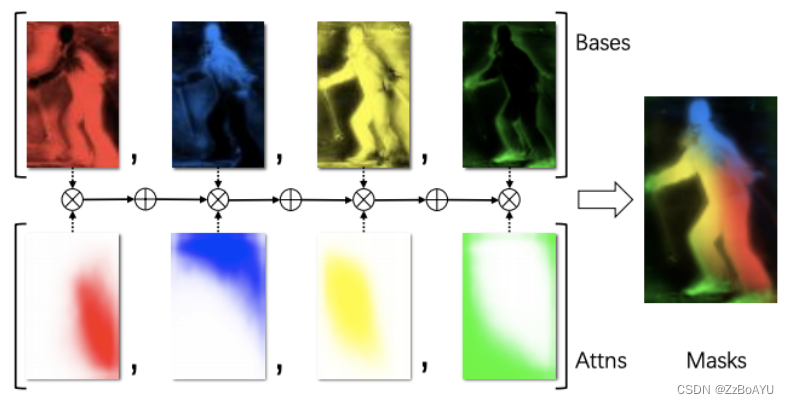
Blender的输入为bottom的输出B、top-level的输出attentions(A)和bbox§,该部分的融合如下:
-
使用RoiPooler来裁取每个bbox对应的区域,并resize成固定的RxR大小的特征图。训练时直接使用ground truth bbox作为propasals,而在推理时直接用FCOS的结果
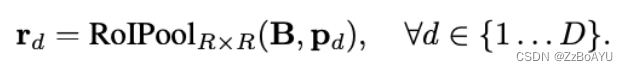
-
attention的大小M是比R小的,因此需要插值,这里采用的双线性插值,从MxM变为RxR
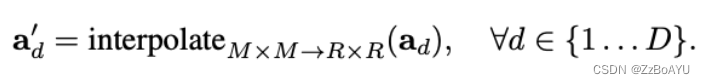
-
接着插值完的attention进行softmax,产生一组score map
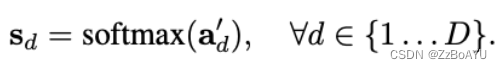
-
对每个r_d和对应的s_d进行逐像素的相加,最后将K个结果相加得到m_d
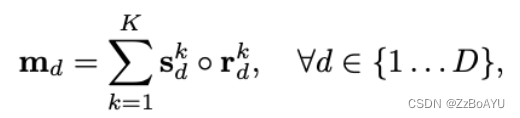
可视化的blender过程: